







目录
3.2.1 Keras、TensorFlow、Theano和CNTK
3.3.1 Jupyter笔记本:运行深度学习实验的首选方法
第3章 神经网络入门
3.1 神经网络剖析
训练神经网络主要围绕以下四个方面:
1.层,多个层组成网络(或模型);
2.输入数据和相应的目标;
3.损失函数,即用于学习的反馈信号;
4.优化器,决定学习过程如何进行。
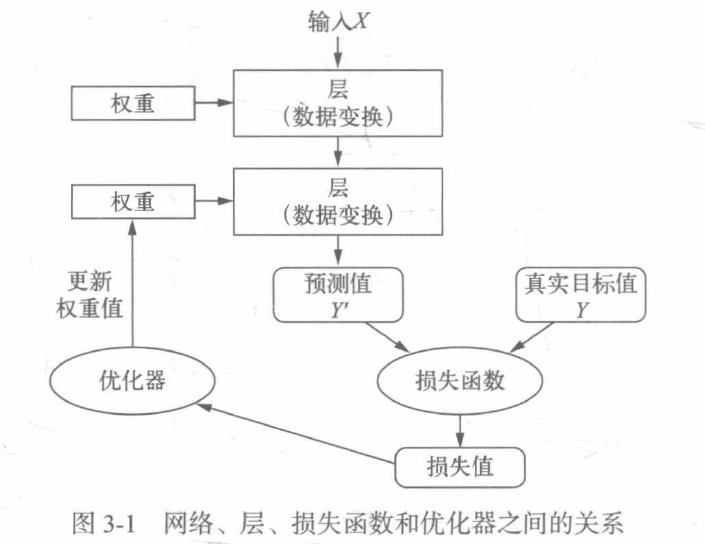
多个层链接在一起组成了网络,将输入数据映射为预测值,然后损失函数将这些预测值与目标进行比较,得到损失值,用于衡量网络预测值与预期结果的匹配程度,优化器使用这个损失值来更新网络的权重。
3.1.1 层:深度学习的基础组件
神经网络的基本数据结构是层,层是一个数据处理模块,将一个或多个输入张量转换为一个或多个输出张量。有些层是无状态的,但大多数的层是有状态的,即层的权重。权重是利用随机梯度下降学到的一个或多个张量,其中包含网络的知识。
不同的张量格式与不同的数据处理类型需要用到不同的层。简单的向量数据保存在2D张量中,通常用密集连接层(也叫全连接层或密集层)来处理。序列数据保存在3D张量中,通常用循环层来处理。图像数据保存在4D张量中,通常用二维卷积层来处理。
在Keras中,构建深度学习模型就是将互相兼容的多个层拼接在一起,以建立有用的数据变化流程。这里层兼容性具体指的是每一层只接受特定形状的输入张量,并返回特定形状的输出张量。
from keras import layers
from keras import models
layer = layers.Dense(32, input_shape=(784,))
model = models.Sequential()
model.add(layers.Dense(32, input_shape=(784)))
model.add(layers.Dense(32))
其中第二层没有输入形状(input_shape)的参数,相反,它可以自动推导出输入形状等于上一层的输出形状。
3.1.2 模型:层构成的网络
深度学习模型是层构成的有向无环图,最常见的例子就是层的线性堆叠,将单一输入映射为单一输出。
网络的拓扑结构定义了一个假设空间,选定了网络拓扑结构,意味着将可能性空间(假设空间)限定为一系列特定的张量运算,将输入数据映射为输出数据,然后,你需要为这些张量运算的权重张量找到一组合适的值。
3.1.3 损失函数与优化器:配置学习过程的关键
一旦确定了网络架构,你还需要选择一下两个参数:
1.损失函数(目标函数)——在训练过程中需要将其最小化,它能够衡量当前任务是否已成功完成;
2.优化器——决定如何基于损失函数对网络进行更新,它执行的是随机梯度下降(SGD)的某个变体。
具有多个输出的神经网络可能具有多个损失函数(每个输出对应一个损失函数)。但是,梯度下降过程必须基于单个标量损失值,因此,对于具有多个损失函数的网络,需要将所有损失函数取平均,变为一个标量值。
选择正确的目标函数对解决问题是非常重要的,网络的目的是使损失尽可能最小化,因此,如果目标函数与成功完成当前任务不完全相关,那么网络最终得到的结果可能会不符合你的预期。
幸运的是,对于分类、回归、序列预测等常见问题,可以遵循一些简单的指导原则来选择正确的损失函数。对于二分类问题,你可以使用二元交叉熵损失函数;对于多分类问题,可以用分类交叉熵损失函数;对于回归问题,可以用均方误差损失函数;对于序列学习问题,可以用联结主义时序分类损失函数等。
3.2 Keras简介
Keras是一个Python深度学习框架,可以方便地定义和训练几乎所有类型的深度学习模型。
Keras具有以下重要特性:
1.相同的代码可以在CPU或GPU上无缝切换运行;
2.具有用户友好的API,便于快速开发深度学习模型的原型;
3.内置支持卷积网络(用于计算机视觉)、循环网络(用于序列处理)以及二者的任意组合;
4.支持任意网络架构:多输入或多输出模型、层共享、模型共享等。这也就是说,Keras能够构建任意深度学习模型,无论是生成式对抗网络还是神经图灵机。
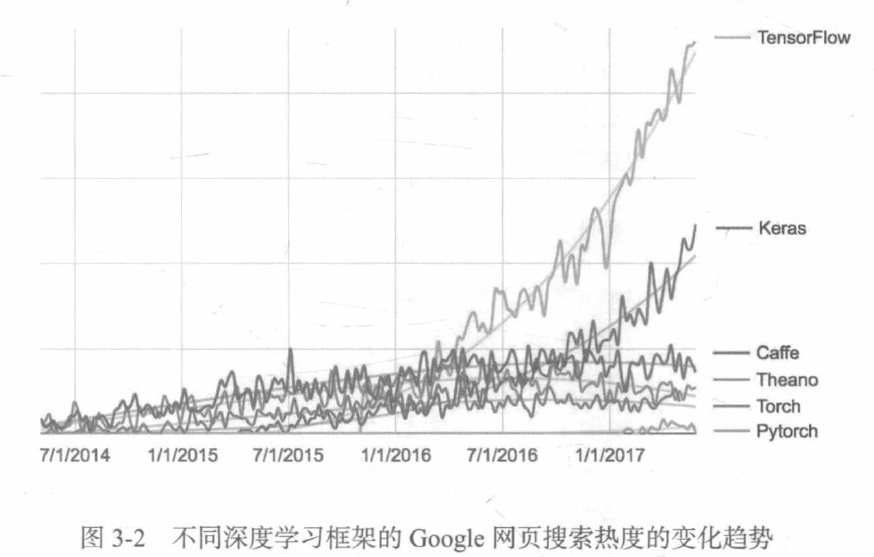
3.2.1 Keras、TensorFlow、Theano和CNTK
Keras是一个模型级的库,为开发深度学习模型提供了高层次的构建模块。 它不处理张量操作、求微分等低层次的运算,相反,它依赖于一个专门的、高度优化的张量库来完成这些运算,这个张量库就是Keras的后端引擎。

通过TensorFlow(或Theano、CNTK),Keras可以在CPU和GPU上无缝运行。在CPU上运行时,TensorFlow本身封装了一个低层次的张量运算库,较多Eigen;在GPU上运行时,TensorFlow封装了一个高度优化的深度学习运算库,叫做NVIDIA CUDA深度神经网络库(cuDNN)。
3.2.2 使用Keras开发:概述
定义模型由两种方法:一种是使用Sequential类(仅用于层的线性堆叠,这是目前最常见党的网络架构),另一种是函数式API(用于层组成的有向无环图,让你可以构建任意形式的架构)。
利用Sequential类定义的两层模型:
from keras import models
from keras import layers
model = models.Sequential()
model.add(layers.Dense(32, activation='relu', input_shape=(784,)))
model.add(layers.Dense(10, activation='softmax'))下面是用函数式API定义的相同模型:
input_tensor = layers.Input(shape=(784,))
x = layers.Dense(32, activation='relu')(input_tensor)
output_tensor = layers.Dense(10, activation='softmax')(x)
model = models.Model(inputs=input_tensor, outputs=output_tensor)配置学习过程是在编译这一步,你需要指定模型使用的优化器和损失函数,以及训练过程中想要监控的指标。
from keras import optimizers
model.compile(optimizer=optimizers.RMSprop(lr=0.001),
loss='mse',
metrics=['accuracy'])3.3 建立深度学习工作站
在开始开发深度学习应用之前,你需要建立自己的深度学习工作站,虽然并非绝对必要,但强烈推荐你在现代NVIDIA GPU上运行深度学习实验。
3.3.1 Jupyter笔记本:运行深度学习实验的首选方法
Jupyter笔记本是运行深度学习实验的好方法,它广泛用于数据科学和机器学习领域。
3.3.2 运行Keras:两种选择
想要在实践中使用Keras,我们推荐以下两种方式:
1.使用官方的EC2深度学习Amazon系统映像(AMI);
2.在本地UNIX工作站上从头安装。
3.3.3 在云端运行深度学习任务:优点和缺点
如果你还没有可用于深度学习的GPU,那么在云端运行深度学习实验是一种简单又低成本的方法。
3.3.4 深度学习的最佳GPU
如果你准备买一块GPU,应该选择哪一款呢?首先要注意,一定要买NVIDIA GPU。NVIDIA是目前唯一一家在深度学习方面大规模投资的图形计算公司,现代深度学习框架只能在NVIDIA显卡上运行。(注:此处是作者原文,非笔者当托)
3.4 电影评论分类:二分类问题
3.4.1 IMDB数据集
为什么要将训练集和测试集分开?因为你不应该将训练机器学习模型的同一批数据再用于测试模型。模型在训练数据上的表现很好,并不意味着它在前所未见的数据上也会表现得很好,而且你真正关系的是模型在新数据上的性能(因为你已经知道了训练数据对应的标签,显然不再需要模型来进行预测)。例如,你的模型最终可能只是记住了训练样本和目标值之间的映射关系,但这对在前所未见的数据上进行预测毫无用处。
与MNIST数据集一样,IMDB数据集也内置于Keras库。它已经过预处理:评论(单词序列)已经被转换为整数序列,其中每个整数代表字典中的某个单词。
from keras.datasets import imdb
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=10000)
print(train_data[0])
print(train_labels[0])
print(max([max(sequence) for sequence in train_data]))[1, 14, 22, 16, 43, 530, 973, 1622, 1385, 65, 458, 4468, 66, 3941, 4, 173, 36, 256, 5, 25, 100, 43, 838, 112, 50, 670, 2, 9, 35, 480, 284, 5, 150, 4, 172, 112, 167, 2, 336, 385, 39, 4, 172, 4536, 1111, 17, 546, 38, 13, 447, 4, 192, 50, 16, 6, 147, 2025, 19, 14, 22, 4, 1920, 4613, 469, 4, 22, 71, 87, 12, 16, 43, 530, 38, 76, 15, 13, 1247, 4, 22, 17, 515, 17, 12, 16, 626, 18, 2, 5, 62, 386, 12, 8, 316, 8, 106, 5, 4, 2223, 5244, 16, 480, 66, 3785, 33, 4, 130, 12, 16, 38, 619, 5, 25, 124, 51, 36, 135, 48, 25, 1415, 33, 6, 22, 12, 215, 28, 77, 52, 5, 14, 407, 16, 82, 2, 8, 4, 107, 117, 5952, 15, 256, 4, 2, 7, 3766, 5, 723, 36, 71, 43, 530, 476, 26, 400, 317, 46, 7, 4, 2, 1029, 13, 104, 88, 4, 381, 15, 297, 98, 32, 2071, 56, 26, 141, 6, 194, 7486, 18, 4, 226, 22, 21, 134, 476, 26, 480, 5, 144, 30, 5535, 18, 51, 36, 28, 224, 92, 25, 104, 4, 226, 65, 16, 38, 1334, 88, 12, 16, 283, 5, 16, 4472, 113, 103, 32, 15, 16, 5345, 19, 178, 32]
1
9999下面这段代码可以让你将某条评论迅速解码为英文单词:
word_index = imdb.get_word_index()
reverse_word_index = dict(
[(value, key) for (key, value) in word_index.items()])
decoded_review = ' '.join(
[reverse_word_index.get(i - 3, '?') for i in train_data[0]])
print(decoded_review)? this film was just brilliant casting location scenery story direction everyone's really suited the part they played and you could just imagine being there robert ? is an amazing actor and now the same being director ? father came from the same scottish island as myself so i loved the fact there was a real connection with this film the witty remarks throughout the film were great it was just brilliant so much that i bought the film as soon as it was released for ? and would recommend it to everyone to watch and the fly fishing was amazing really cried at the end it was so sad and you know what they say if you cry at a film it must have been good and this definitely was also ? to the two little boy's that played the ? of norman and paul they were just brilliant children are often left out of the ? list i think because the stars that play them all grown up are such a big profile for the whole film but these children are amazing and should be praised for what they have done don't you think the whole story was so lovely because it was true and was someone's life after all that was shared with us all
3.4.2 准备数据
你不能将整数序列直接输入神经网络,你需要将列表转换为张量。转换方法有以下两种:
1.填充列表,使其具有相同的长度,再将列表转换成形状为(sample, word_indices)的整数张量,然后网络第一层使用能处理这种整数张量的层。
2.对列表进行one-hot编码,将其转换为0和1组成的向量。
下面我们采用后一种方法将数据向量化。
import numpy as np
from keras.datasets import imdb
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=10000)
def vectorize_sequence(sequences, dimension=10000):
results = np.zeros((len(sequences), dimension))
for i, sequence in enumerate(sequences):
results[i, sequence] = 1.
return results
x_train = vectorize_sequence(train_data)
x_test = vectorize_sequence(test_data)
y_train = np.asarray(train_labels).astype('float32')
y_test = np.asarray(test_labels).astype('float32')
print(x_train[0])[0. 1. 1. ... 0. 0. 0.]3.4.3 构建网络
输入数据是向量,而标签是标量(1和0),有一类网络在这种问题上表现很好,就是带有relu激活的全连接层的简单堆叠,比如Dense(16, activation='relu')。
传入Dense层的参数(16)是该层隐藏单元的个数,一个隐藏单元是该层表示空间的一个维度。你可以将表示空间的维度直观地理解为“网络学习内部表示时所拥有的自由度”。隐藏单元越多(即更高维的表示空间),网络越能学到更加复杂的表示,但网络的计算代价也变得更大,而且可能会导致学到不好的模式(这种模式会提高训练数据上的性能,但不会提高测试数据上的性能)。
对于这种Dense层的堆叠,你需要确定以下两个关键架构:
1.网络有多少层;
2.每层有多少个隐藏单元。
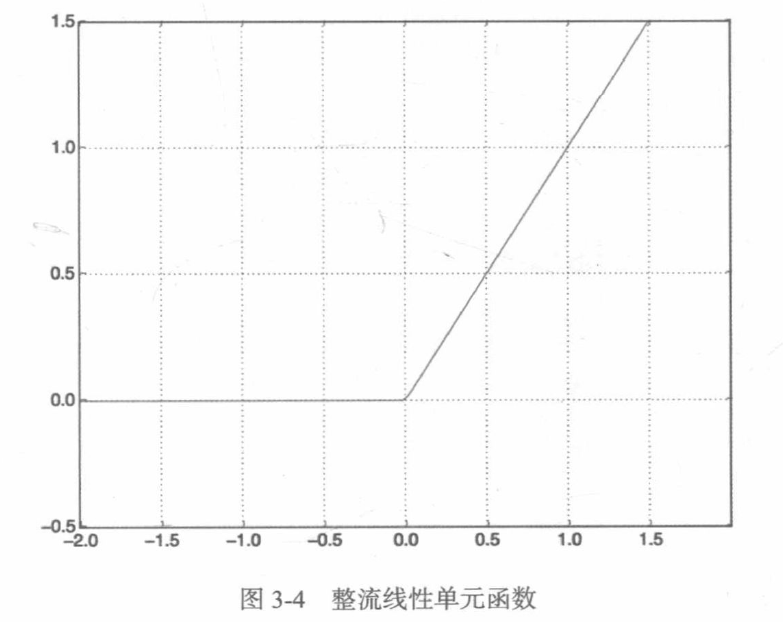
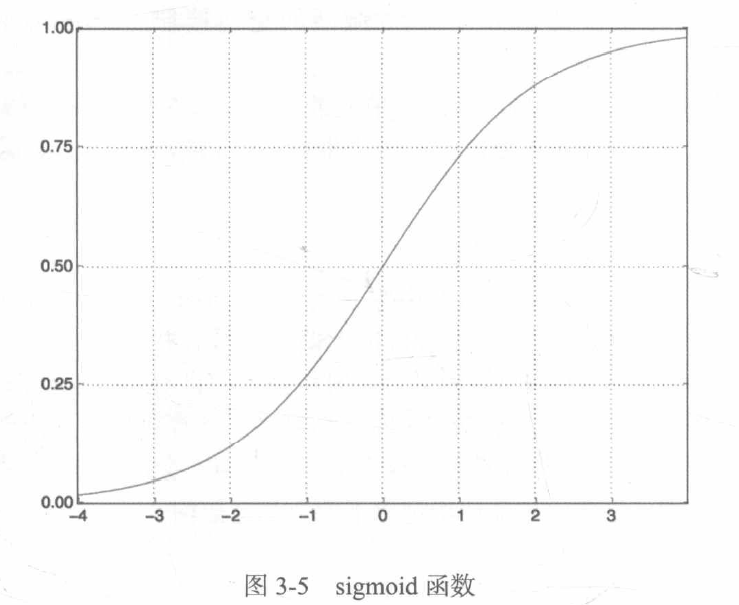
relu(整流线性单元)函数将所有负值归零,而sigmoid函数则将任意值“压缩”到[0,1]区间内,其输出值可以看作概率值。
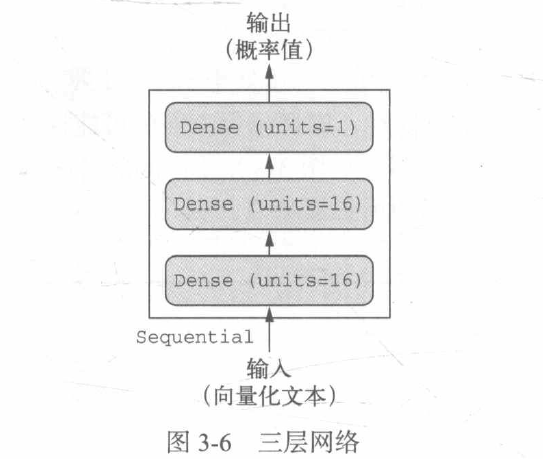
模型定义:
from keras import models
from keras import layers
model = models.Sequential()
model.add(layers.Dense(16, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(16, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))如果没有relu等激活函数(也叫非线性),Dense层将只包含两个线性运算——点积和加法,这样Dense层就只能学习输入数据的线性变换(仿射变换):该层的假设空间是从输入数据到16位空间所有可能的线性变换集合。这种假设空间非常有限,无法利用多个表示层的优势,因为多个线性层堆叠实现的仍是线性运算,添加层数并不会扩展假设空间。为了得到更丰富的假设空间,从而充分利用多层表示的优势,你需要添加非线性或激活函数。
最后,你需要选择损失函数和优化器。对于输出概率值的模型,交叉熵往往是最好的选择,交叉熵是来自于信息论领域的概念,用于衡量概率分布之间的距离。
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['accuracy'])上述代码是用rmsprop优化器和binary_crossentropy损失函数来配置模型。
配置优化器:
model.compile(optimizer=optimizers.RMSprop(lr=0.001),
loss='binary_crossentropy',
metrics=['accuracy'])使用自定义的损失和指标:
model.compile(optimizer=optimizers.RMSprop(lr=0.001),
loss=losses.binary_crossentropy,
metrics=[metrics.binary_accuracy])3.4.4 验证你的方法
为了在训练过程中监控模型在前所未见的数据上的精度,你需要将原始训练数据留出10000个样本作为验证集。
留出验证集:
x_val = x_train[:10000]
partial_x_train = x_train[10000:]
y_val = y_train[:10000]
partial_y_train = y_train[10000:]训练模型:
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['acc'])
history = model.fit(partial_x_train,
partial_y_train,
epochs=20,
batch_size=512,
validation_data=(x_val, y_val))
history_dict = history.history
print(history_dict.keys())
Epoch 1/20
30/30 [==============================] - 5s 105ms/step - loss: 0.5327 - acc: 0.7923 - val_loss: 0.4140 - val_acc: 0.8702
Epoch 2/20
30/30 [==============================] - 1s 47ms/step - loss: 0.3339 - acc: 0.9019 - val_loss: 0.3261 - val_acc: 0.8776
Epoch 3/20
30/30 [==============================] - 2s 56ms/step - loss: 0.2402 - acc: 0.9248 - val_loss: 0.2848 - val_acc: 0.8886
Epoch 4/20
30/30 [==============================] - 2s 55ms/step - loss: 0.1869 - acc: 0.9405 - val_loss: 0.3050 - val_acc: 0.8741
Epoch 5/20
30/30 [==============================] - 2s 52ms/step - loss: 0.1499 - acc: 0.9525 - val_loss: 0.3058 - val_acc: 0.8784
Epoch 6/20
30/30 [==============================] - 2s 53ms/step - loss: 0.1263 - acc: 0.9591 - val_loss: 0.2857 - val_acc: 0.8875
Epoch 7/20
30/30 [==============================] - 2s 60ms/step - loss: 0.1018 - acc: 0.9709 - val_loss: 0.3109 - val_acc: 0.8842
Epoch 8/20
30/30 [==============================] - 1s 50ms/step - loss: 0.0846 - acc: 0.9763 - val_loss: 0.3275 - val_acc: 0.8834
Epoch 9/20
30/30 [==============================] - 1s 43ms/step - loss: 0.0691 - acc: 0.9812 - val_loss: 0.3575 - val_acc: 0.8788
Epoch 10/20
30/30 [==============================] - 1s 48ms/step - loss: 0.0567 - acc: 0.9861 - val_loss: 0.4133 - val_acc: 0.8705
Epoch 11/20
30/30 [==============================] - 1s 43ms/step - loss: 0.0451 - acc: 0.9896 - val_loss: 0.4002 - val_acc: 0.8773
Epoch 12/20
30/30 [==============================] - 1s 43ms/step - loss: 0.0345 - acc: 0.9929 - val_loss: 0.4354 - val_acc: 0.8747
Epoch 13/20
30/30 [==============================] - 2s 60ms/step - loss: 0.0307 - acc: 0.9936 - val_loss: 0.4633 - val_acc: 0.8729
Epoch 14/20
30/30 [==============================] - 2s 56ms/step - loss: 0.0217 - acc: 0.9963 - val_loss: 0.5703 - val_acc: 0.8573
Epoch 15/20
30/30 [==============================] - 2s 55ms/step - loss: 0.0155 - acc: 0.9984 - val_loss: 0.5336 - val_acc: 0.8727
Epoch 16/20
30/30 [==============================] - 2s 58ms/step - loss: 0.0140 - acc: 0.9981 - val_loss: 0.5628 - val_acc: 0.8692
Epoch 17/20
30/30 [==============================] - 1s 48ms/step - loss: 0.0128 - acc: 0.9980 - val_loss: 0.5976 - val_acc: 0.8686
Epoch 18/20
30/30 [==============================] - 1s 49ms/step - loss: 0.0061 - acc: 0.9999 - val_loss: 0.6327 - val_acc: 0.8672
Epoch 19/20
30/30 [==============================] - 1s 47ms/step - loss: 0.0063 - acc: 0.9995 - val_loss: 0.6751 - val_acc: 0.8667
Epoch 20/20
30/30 [==============================] - 1s 43ms/step - loss: 0.0064 - acc: 0.9990 - val_loss: 0.7061 - val_acc: 0.8672
dict_keys(['loss', 'acc', 'val_loss', 'val_acc'])绘制训练损失和验证损失:
loss_values = history_dict['loss']
val_loss_values = history_dict['val_loss']
epochs = range(1, len(loss_values) + 1)
plt.plot(epochs, loss_values, 'bo', label='Training loss')
plt.plot(epochs, val_loss_values, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()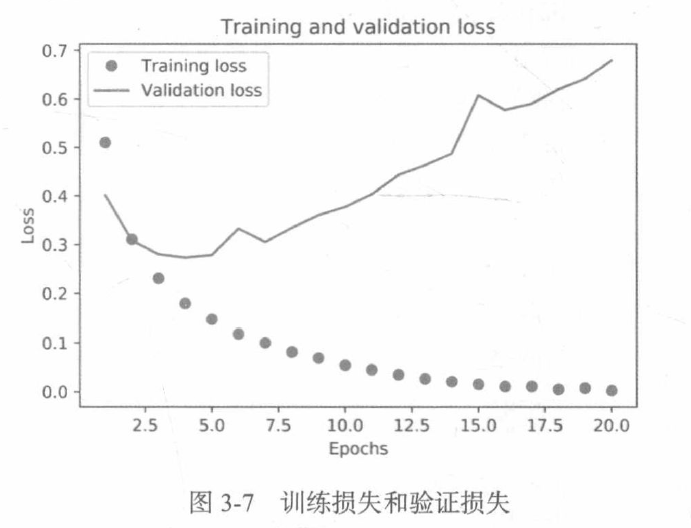
绘制训练精度和验证精度:
plt.clf()
acc = history_dict['acc']
val_acc = history_dict['val_acc']
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and Validaition accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()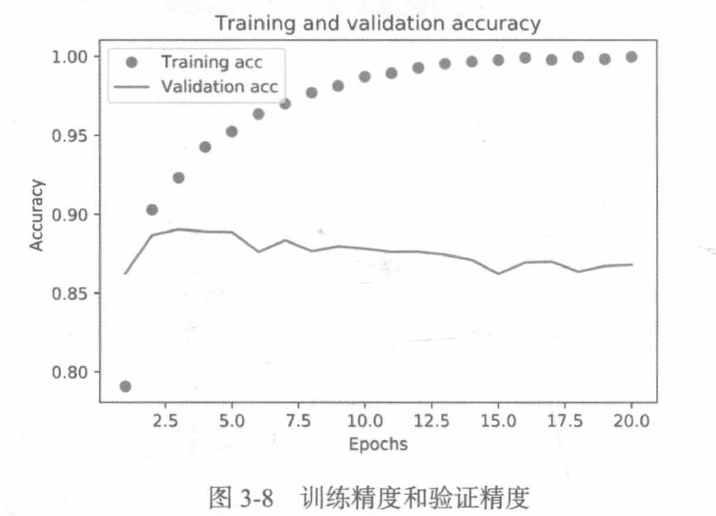
如图所示,训练损失每轮都在降低,训练精度每轮都在提升。这就是梯度下降优化的预期结果——你想要最小化的量随着每次迭代越来越小。但验证损失和验证精度并非如此:它们似乎在第5轮达到最佳值。这就是我们之前警告过的一种情况:模型在训练数据上的表现越来越好,但在前所未见的数据上不一定表现得越来越好。准确地说,你看到的是过拟合:在第二轮之后,你对训练数据过度优化,最终学到的表示仅针对于训练数据,无法泛化到训练集之外的数据。
Epoch 1/20
30/30 [==============================] - 5s 107ms/step - loss: 0.5342 - acc: 0.7893 - val_loss: 0.4165 - val_acc: 0.8618
Epoch 2/20
30/30 [==============================] - 2s 57ms/step - loss: 0.3338 - acc: 0.8971 - val_loss: 0.3211 - val_acc: 0.8839
Epoch 3/20
30/30 [==============================] - 2s 58ms/step - loss: 0.2421 - acc: 0.9235 - val_loss: 0.2843 - val_acc: 0.8904
Epoch 4/20
30/30 [==============================] - 2s 53ms/step - loss: 0.1922 - acc: 0.9387 - val_loss: 0.2758 - val_acc: 0.8891
Epoch 5/20
30/30 [==============================] - 2s 61ms/step - loss: 0.1559 - acc: 0.9512 - val_loss: 0.2753 - val_acc: 0.8903
Epoch 6/20
30/30 [==============================] - 1s 50ms/step - loss: 0.1290 - acc: 0.9593 - val_loss: 0.2834 - val_acc: 0.8889
Epoch 7/20
30/30 [==============================] - 1s 46ms/step - loss: 0.1047 - acc: 0.9704 - val_loss: 0.3048 - val_acc: 0.8825
Epoch 8/20
30/30 [==============================] - 2s 56ms/step - loss: 0.0887 - acc: 0.9747 - val_loss: 0.3146 - val_acc: 0.8856
Epoch 9/20
30/30 [==============================] - 2s 56ms/step - loss: 0.0724 - acc: 0.9796 - val_loss: 0.3344 - val_acc: 0.8826
Epoch 10/20
30/30 [==============================] - 2s 55ms/step - loss: 0.0577 - acc: 0.9867 - val_loss: 0.3591 - val_acc: 0.8826
Epoch 11/20
30/30 [==============================] - 2s 52ms/step - loss: 0.0487 - acc: 0.9891 - val_loss: 0.3930 - val_acc: 0.8744
Epoch 12/20
30/30 [==============================] - 2s 52ms/step - loss: 0.0370 - acc: 0.9925 - val_loss: 0.4143 - val_acc: 0.8786
Epoch 13/20
30/30 [==============================] - 2s 52ms/step - loss: 0.0309 - acc: 0.9939 - val_loss: 0.4380 - val_acc: 0.8767
Epoch 14/20
30/30 [==============================] - 1s 43ms/step - loss: 0.0229 - acc: 0.9961 - val_loss: 0.4716 - val_acc: 0.8747
Epoch 15/20
30/30 [==============================] - 2s 58ms/step - loss: 0.0178 - acc: 0.9973 - val_loss: 0.5159 - val_acc: 0.8736
Epoch 16/20
30/30 [==============================] - 2s 53ms/step - loss: 0.0148 - acc: 0.9982 - val_loss: 0.5391 - val_acc: 0.8710
Epoch 17/20
30/30 [==============================] - 2s 56ms/step - loss: 0.0086 - acc: 0.9997 - val_loss: 0.6091 - val_acc: 0.8638
Epoch 18/20
30/30 [==============================] - 2s 55ms/step - loss: 0.0073 - acc: 0.9997 - val_loss: 0.6203 - val_acc: 0.8702
Epoch 19/20
30/30 [==============================] - 2s 57ms/step - loss: 0.0050 - acc: 0.9997 - val_loss: 0.6715 - val_acc: 0.8690
Epoch 20/20
30/30 [==============================] - 2s 54ms/step - loss: 0.0062 - acc: 0.9991 - val_loss: 0.6978 - val_acc: 0.8687
以下是完整代码:
import numpy as np
import matplotlib.pyplot as plt
from keras.datasets import imdb
from keras import models
from keras import layers
from keras import optimizers
from keras import losses
from keras import metrics
from tensorflow import optimizers
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=10000)
def vectorize_sequence(sequences, dimension=10000):
results = np.zeros((len(sequences), dimension))
for i, sequence in enumerate(sequences):
results[i, sequence] = 1.
return results
x_train = vectorize_sequence(train_data)
x_test = vectorize_sequence(test_data)
y_train = np.asarray(train_labels).astype('float32')
y_test = np.asarray(test_labels).astype('float32')
# print(x_train[0])
model = models.Sequential()
model.add(layers.Dense(16, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(16, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
model.compile(optimizer=optimizers.RMSprop(lr=0.001),
loss='binary_crossentropy',
metrics=['accuracy'])
model.compile(optimizer=optimizers.RMSprop(lr=0.001),
loss=losses.binary_crossentropy,
metrics=[metrics.binary_accuracy])
x_val = x_train[:10000]
partial_x_train = x_train[10000:]
y_val = y_train[:10000]
partial_y_train = y_train[10000:]
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['acc'])
history = model.fit(partial_x_train,
partial_y_train,
epochs=20,
batch_size=512,
validation_data=(x_val, y_val))
history_dict = history.history
# print(history_dict.keys())
loss_values = history_dict['loss']
val_loss_values = history_dict['val_loss']
epochs = range(1, len(loss_values) + 1)
plt.plot(epochs, loss_values, 'bo', label='Training loss')
plt.plot(epochs, val_loss_values, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
plt.clf()
acc = history_dict['acc']
val_acc = history_dict['val_acc']
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and Validaition accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
从头开始重新训练一个模型:
model = models.Sequential()
model.add(layers.Dense(16, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(16, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
model.fit(x_train, y_train, epochs=4, batch_size=512)
results = model.evaluate(x_test, y_test)
print(results)3.4.5 使用训练好的网络在新数据上生成预测结果
你可以用predict方法来得到评论为正面的可能性大小。
print((model.predict(x_test)))3.4.6 进一步的实验
通过以下实验,你可以却行前面选择的网络架构是非常合理的,虽然仍有改进的空间。
1.前面使用了两个隐藏层,你可以尝试使用一个或三个隐藏层,然后观察对验证精度和测试精度的影响;
2.尝试使用更多或更少的隐藏单元,比如32个、64个等;
3.尝试使用mse损失函数代替binary_crossentropy;
4.尝试使用tanh激活(这种激活在神经网络早期非常流行)代替relu。
3.4.7 小结
下面是你应该从这个例子中学到的要点。
1.通常需要对原始数据进行大量预处理,以便将其转换为张量输入到神经网络中,单词序列可以编码为二进制向量,但也有其他编码方式;
2.带有relu激活的Dense层堆叠,可以解决很多种问题(包括情感分类),你可能会经常用到这种模型;
3.对于二分类问题(两个输出类别),网络的最后一层应该是只有一个单元并使用sigmoid激活的Dense层,网络输出应该是0~1范围内的标量,表示概率值;
4.对于二分类问题的sigmoid标量输出,你应该使用binary_crossentropy损失函数;
5.无论你的问题是什么,rmsprop优化器通常都是足够好的选择;
6.随着神经网络在训练数据上的表现越来越好,模型最终会过拟合,并在前所未见的数据上得到越来越差的结果,一定要一直监控模型在训练集之外的数据上的性能。
3.5 新闻分类:多分类问题
本节将构建一个网络,将路透社新闻划分为46个互斥的主题。因为有多个类别,所以这是多分类问题的一个例子,因为每个数据点只能划分到一个类别,所以更具体地说,这是单标签、多分类问题的一个例子。如果每个数据点可以划分到多个类别(主题),那它就是一个多标签、多分类问题。
3.5.1 路透社数据集
加载路透社数据集:
from keras.datasets import reuters
(train_data, train_labels), (test_data, test_labels) = reuters.load_data(num_words=10000)
print(len(train_data))
print(len(test_data))
print(train_data[10])8982
2246
[1, 245, 273, 207, 156, 53, 74, 160, 26, 14, 46, 296, 26, 39, 74, 2979, 3554, 14, 46, 4689, 4329, 86, 61, 3499, 4795, 14, 61, 451, 4329, 17, 12]将索引解码为新闻文本:
word_index = reuters.get_word_index()
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])
decoded_newswire = ' '.join([reverse_word_index.get(i - 3, '?') for i in train_data[0]])
print(decoded_newswire)
3.5.2 准备数据
编码数据:
import numpy as np
def vectorize_sequences(sequences, dimension=10000):
results = np.zeros((len(sequences),dimension))
for i, sequence in enumerate(sequences):
results[i, sequence] = 1.
return results
x_train = vectorize_sequences(train_data)
x_test = vectorize_sequences(test_data)将标签向量化有两种方法:你可以将标签列表转换为整数张量,或者使用one-hot编码。one-hot编码是分类数据广泛使用的一种格式,也叫分类编码。
def to_one_hot(labels, dimension=46):
results = np.zeros((len(labels), dimension))
for i, label in enumerate(labels):
results[i, label] = 1.
return results
one_hot_train_labels = to_one_hot(train_labels)
one_hot_test_labels = to_one_hot(test_labels)Keras内置方法可以实现这个操作:
from keras.utils.np_utils import to_categorical
one_hot_train_labels = to_categorical(train_labels)
one_hot_test_labels = to_categorical(test_labels)3.5.3 构建网络
模型定义:
from keras import models
from keras import layers
model = models.Sequential
model.add(layers.Dense(64, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(46, activation='softmax'))编译模型:
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])3.5.4 验证你的方法
留出验证集:
x_val = x_train[:1000]
partial_x_train = x_train[1000:]
y_val = one_hot_train_labels[:1000]
partial_y_train = one_hot_train_labels[1000:]训练模型:
history = model.fit(partial_x_train,
partial_y_train,
epochs=20,
batch_size=512,
validation_data=(x_val, y_val))绘制训练损失和验证损失:
import matplotlib.pyplot as plt
history_dict = history.history
loss_values = history_dict
val_loss_values = history_dict['val_loss']
epochs = range(1, len(loss_values) + 1)
plt.plot(epochs, loss_values, 'bo', label='Training loss')
plt.plot(epochs, val_loss_values, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
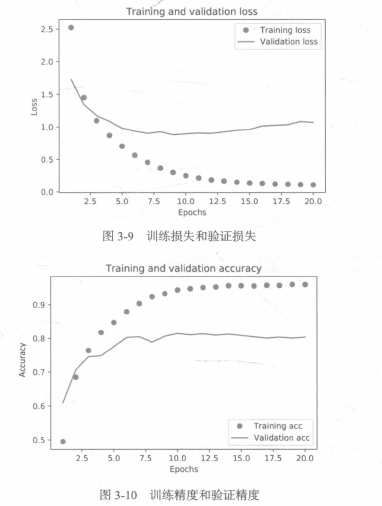
网络在训练9轮后开始过拟合,我们从头开始训练一个新网络,共9个轮次,然后在测试集上评估模型:
model = models.Sequential()
model.add(layers.Dense(64, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(46, activation='softmax'))
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
model.fit(partial_x_train,
partial_y_train,
epochs=9,
batch_size=512,
validation_data=(x_val, y_val))
results = model.evaluate(x_test, one_hot_test_labels)
print(results)Epoch 1/9
16/16 [==============================] - 2s 59ms/step - loss: 2.5878 - accuracy: 0.4693 - val_loss: 1.7429 - val_accuracy: 0.6250
Epoch 2/9
16/16 [==============================] - 1s 44ms/step - loss: 1.4614 - accuracy: 0.6931 - val_loss: 1.3173 - val_accuracy: 0.7170
Epoch 3/9
16/16 [==============================] - 1s 42ms/step - loss: 1.0919 - accuracy: 0.7636 - val_loss: 1.1552 - val_accuracy: 0.7640
Epoch 4/9
16/16 [==============================] - 1s 37ms/step - loss: 0.8592 - accuracy: 0.8183 - val_loss: 1.0541 - val_accuracy: 0.7750
Epoch 5/9
16/16 [==============================] - 1s 34ms/step - loss: 0.6909 - accuracy: 0.8544 - val_loss: 0.9933 - val_accuracy: 0.7840
Epoch 6/9
16/16 [==============================] - 1s 36ms/step - loss: 0.5526 - accuracy: 0.8879 - val_loss: 0.9267 - val_accuracy: 0.8070
Epoch 7/9
16/16 [==============================] - 1s 35ms/step - loss: 0.4411 - accuracy: 0.9104 - val_loss: 0.9337 - val_accuracy: 0.7960
Epoch 8/9
16/16 [==============================] - 1s 41ms/step - loss: 0.3606 - accuracy: 0.9252 - val_loss: 0.8962 - val_accuracy: 0.8170
Epoch 9/9
16/16 [==============================] - 1s 41ms/step - loss: 0.3010 - accuracy: 0.9356 - val_loss: 0.9052 - val_accuracy: 0.8110
71/71 [==============================] - 1s 8ms/step - loss: 0.9926 - accuracy: 0.7832
[0.9926372170448303, 0.7831701040267944]这种方法可以得到约80%的精度,对于平衡的二分类问题,完全随机的分类器能够得到50%的精度。但在这个例子中,完全随机的精度约为19%,所以上述结果相当不错,至少和随机的基准比起来还不错。
import copy
test_labels_copy = copy.copy(test_labels)
np.random.shuffle(test_labels_copy)
hits_array = np.array(test_labels) == np.array(test_labels_copy)
acc = float(np.sum(hits_array) / len(test_labels))
print(acc)0.18566340160284953.5.5 在新数据上生成预测结果
在新数据上生成预测结果:
predictions = model.predict(x_test)
print(predictions[0].shape)
print(np.sum(predictions[0]))
print(np.argmax(predictions[0]))(46,)
1.0000001
33.5.6 处理标签和损失的另一种方法
前面提到了另一种编码标签的方法,就是将其转换为整数张量:
y_train = np.array(train_labels)
y_test = np.array(test_labels)对于这种编码方法,唯一需要改变的是损失函数的选择。对于损失函数categorical_crossentropy,标签应该遵循分类编码,对于整数标签,你应该使用sparse_categorical_crossentropy。
model.compile(optimizer='rmsprop',
loss='sparse_categorical_crossentropy',
metrics=['acc'])这个新的损失函数在数学上与categorical_crossentropy完全相同,二者只是接口不同。
3.5.7 中间层维度足够大的重要性
具有信息瓶颈的模型:
model = models.Sequential()
model.add(layers.Dense(64, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(4, activaiton='relu'))
model.add(layers.Dense(46, activation='softmax'))
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
model.fit(partial_x_train,
partial_y_train,
epochs=20,
batch_size=128,
validation_data=(x_val, y_val))
results = model.evaluate(x_test, one_hot_test_labels)
print(results)现在网络的验证精度最大约71%,比前面下降了8%。导致这一下降的主要原因在于,你试图将大量信息(这些信息足够恢复46个类别的分割超平面)压缩到维度很小的中间空间,网络能够将大部分必要信息塞入这个四维表示中,但并不是全部信息。
3.5.8 进一步的实验
1.尝试使用更多或更少的隐藏单元,比如32个、128个等;
2.前面使用了两个隐藏层,现在尝试使用一个或三个隐藏层。
3.5.9 小结
1.如果要对N个类别的数据点进行分类,网络的最后一层应该是大小为N的Dense层;
2.对于单标签、多分类问题,网络的最后一层应该使用softmax激活,这样可以输出在N个输出类别上的概率分布;
3.这种问题的损失函数几乎总是应该使用分类交叉熵,它将网络输出的概率分布于目标的真实分布之间的距离最小化;
4.处理多分类的问题的标签也有两种方法:
(1)通过分类编码(也叫one-hot编码)对标签进行编码,然后使用categorical_crossentropy作为损失函数;
(2)将标签编码为整数,然后使用sparse_categorical_crossentropy损失函数。
5.如果你需要将数据划分到许多类别中,应该避免使用太小的中间层,以免在网络中造成信息瓶颈。
3.6 预测房价:回归问题
前面两个例子都是分类问题,其目标是预测输入数据点所对应的单一离散的标签,另一种常见的机器学习问题是回归问题,它预测一个连续值而不是离散的标签。
3.6.1 波士顿房价数据集
加载波士顿房价数据:
from keras.datasets import boston_housing
(train_data, train_targets), (test_data, test_targets) = boston_housing.load_data()
print(train_data.shape)
print(test_data.shape)(404, 13)
(102, 13)3.6.2 准备数据
将取值范围差异很大的数据输入到神经网络中,这是有问题的。网络可能会自动适应这种取值范围不同的数据,但学习肯定变得更加困难。对于这种数据,普遍采用的最佳实践是对每个特征做标准化,即对于输入数据的每个特征(输入数据矩阵中的列),减去特征平均值,再除以标准差,这样得到的特征平均值为0,标准差为1.
数据标准化:
mean = train_data.mean(axis=0)
train_data -= mean
std = train_data.std(axis=0)
train_data /= std
test_data -= mean
test_data /= std用于测试数据标准化的均值和标准差都是在训练数据上计算得到的,在工作流程中,你不能使用在测试数据上计算得到的任何结果,即使是像数据标准化这么简单的事情也不行。
3.6.3 构建网络
由于样本数量很少,我们将使用一个非常小的网络,其中包含两个隐藏层,每层有64个单元。一般来说,训练数据越少,过拟合会越严重,而较小的网络可以降低过拟合。
from keras import models
from keras import layers
def build_model():
model = models.Sequential()
model.add(layers.Dense(64, activaiton='relu', input_shape=(train_data.shape[1],)))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(1))
model.compile(optimizer='rmsprop', loss='mse', metrics=['mae'])
return model网络的最后一层只有一个单元,没有激活,是一个线性层,这是标量回归(标量回归是预测单一连续值的回归)的典型设置,添加激活函数将会限制输出范围。如果向最后一层添加sigmoid激活函数,网络只能学会预测0~1范围内的值,这里最后一层是纯线性的,所以网络可以学会预测任意范围内的值。
编译网络用的是mse损失函数,即均方误差,预测值与目标值之差的平方,这是回归问题常用的损失函数。
平均绝对误差是预测值与目标值之差的绝对值。
3.6.4 利用K折验证来验证你的方法
为了在调节网络参数(比如训练的轮数)的同时对网络进行评估,可以将数据划分为训练集和验证集。但由于数据点很少,验证集会非常小,因此,验证分数可能会有很大波动,这取决于你所选择的验证集和训练集,也就是说,验证集的划分方式可能会造成验证分数上有很大的方差,这样就无法对模型进行可靠的评估。
在这种情况下,最佳做法是使用K折交叉验证,将可用数据划分为K个分区(K通常取4或5),实例化K个相同的模型,将每个模型在K-1个分区上训练,并在剩下的一个分区上进行评估。模型的验证分数等于K个验证分数的平均值。
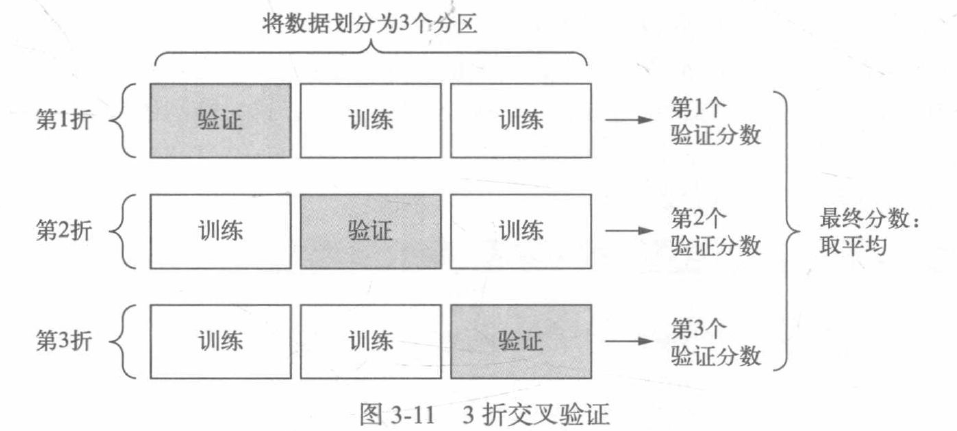
K折验证:
import numpy as np
k = 4
num_val_samples = len(train_data) // k
num_epochs = 100
all_scores = []
for i in range(k):
print('processing fold #', i)
val_data = train_data[i * num_val_samples: (i + 1) * num_val_samples]
val_targets = train_targets[i * num_val_samples: (i + 1) * num_val_samples]
partial_train_data = np.concatenate(
[train_data[:i * num_val_samples],
train_data[(i + 1) * num_val_samples:]],
axis=0
)
partial_train_targets = np.concatenate(
[train_targets[:i * num_val_samples],
train_targets[(i + 1) * num_val_samples:]],
axis=0
)
model = build_model()
model.fit(partial_train_data, partial_train_targets, epochs=num_epochs, batch_size=1, verbose=0)
val_mse, val_mae = model.evaluate(val_data, val_targets, verbose=0)
all_scores.append(val_mae)
print(all_scores)processing fold # 1
processing fold # 2
processing fold # 3
[2.192124605178833, 2.983497142791748, 2.5584042072296143, 2.505509614944458]每次运行模型得到的验证分数有很大差异,平均数是比单一分数更可靠的指标——这就是K折交叉验证的关键。
num_epochs = 500
all_mae_histories = []
for i in range(k):
print('processing fold #', i)
val_data = train_data[i * num_val_samples: (i + 1) * num_val_samples]
val_targets = train_targets[i * num_val_samples: (i + 1) * num_val_samples]
partial_train_data = np.concatenate(
[train_data[:i * num_val_samples],
train_data[(i + 1) * num_val_samples:]],
axis=0
)
partial_train_targets = np.concatenate(
[train_targets[:i * num_val_samples],
train_targets[(i + 1) * num_val_samples:]],
axis=0
)
model = build_model()
history = model.fit(partial_train_data, partial_train_targets, validation_data=(val_data, val_targets), epochs=num_epochs, batch_size=1, verbose=0)
mae_history = history.history['val_mean_absolute_error']
all_mae_histories.append(mae_history)计算所有轮次中的K折验证分数平均值:
average_mae_history = [np.mean(x[i] for x in all_mae_histories) for i in range(num_epochs)]绘制验证分数:
plt.plot(range(1, len(average_mae_history) + 1), average_mae_history)
plt.xlabel('Epochs')
plt.ylabel('Validation MAE')
plt.show()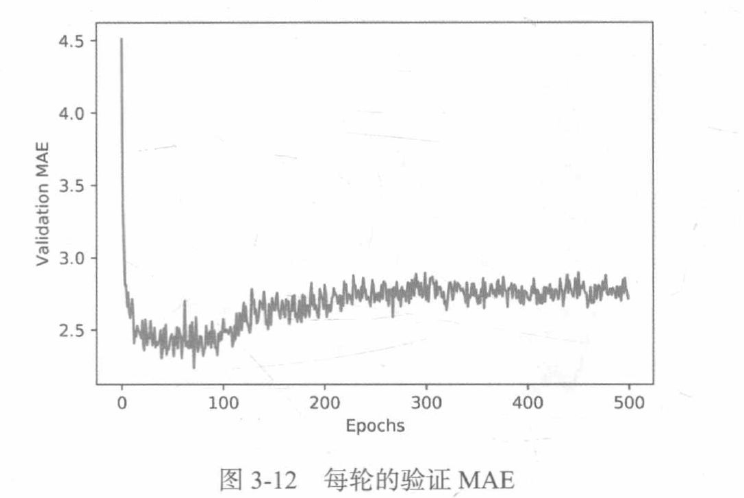
绘制验证分数(删除前10个数据点) :
def smooth_curve(points, factor=0.9):
smoothed_points = []
for point in points:
if smoothed_points:
previous = smoothed_points[-1]
smoothed_points.append(previous * factor + point * (1 - factor))
else:
smoothed_points.append(point)
return smoothed_points
smooth_mae_history = smooth_curve(average_mae_history[10:])
plt.plot(range(1, len(smooth_mae_history) + 1), smooth_mae_history)
plt.xlabel('Epochs')
plt.ylabel('Validation MAE')
plt.show()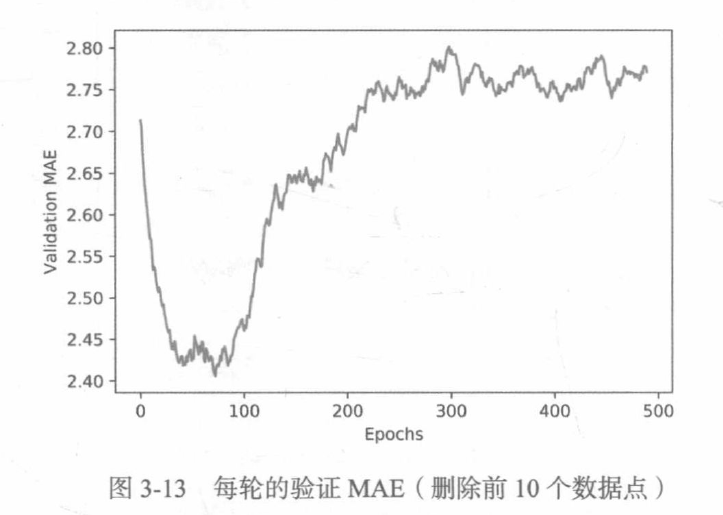
完成模型调参之后,你可以使用最佳参数在所有训练数据上训练最终的生产模型,然后观察模型在测试集上的性能。
训练最终模型:
model = build_model()
model.fit(train_data, train_targets, epochs=80, batch_size=16, verbose=0)
test_mse_score, test_mae_score = model.evaluate(test_data, test_targets)3.6.5 小结
1.回归问题使用的损失函数与分类问题不同,回归常用的损失函数是均方误差(MSE);
2.同样,回归问题使用的评估指标也与分类问题不同。显而易见,精度的概念不适用于回归问题,常见的回归指标是平均绝对误差(MAE);
3.如果输入数据的特征具有不同的取值范围,应该先进行预处理,对每个特征单独进行缩放;
4.如果可用的数据很少,使用K折验证可以可靠地评估模型;
5.如果可用的训练数据很少,最好使用隐藏层较少(通常只有一到两个)的小型网络,以避免严重的过拟合。
本章小结
现在已学习处理了关于向量数据最常见的机器学习任务:二分类问题、多分类问题和标量回归问题。
1.在将原始数据输入神经网络之前,通常需要对其进行预处理;
2.如果数据特征具有不同的取值范围,那么需要进行预处理,将每个特征单独缩放;
3.随着训练的进行,神经网络最终会过拟合,并在前所未见的数据上得到更差的结果;
4.如果训练数据不是很多,应该使用只有一两个隐藏层的小型网络,以避免严重的过拟合;
5.如果数据被分为多个类别,那么中间层过小可能会导致信息瓶颈;
6.回归问题使用的损失函数核评估指标都与分类问题不同;
7.如果要处理的数据很少,K折验证有助于可靠地评估模型。















 1119
1119











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









