







最近,看了DETR的原论文:End-to-End Object Detection with Transformers,对此,作一些笔记关于自己对该论文的理解 😁
1.前言
开篇,作者直接说明提出了一个可以把目标检测视为直接预测集问题的方法。DETR和之前许多的detectors不一样,之前的detectors存在以下缺点:
- 有许多人工设计的组件,会产生许多框,因此就必须加入后处理操作
- 人工设计的组件中,可以调节的超参数就比较少
- 后处理操作和锚框的设计,这些都会影响detectors最后的性能
而DETR非常简单,解决了这些问题:
- 移除了人工设计的组件,比如NMS(非极大值抑制处理)和Anchor(锚框),大大简化了流程
- 整个由网络实现端到端的目标检测实现,简化了训练pipeline
然而,这么简单的结构却在COCO数据集上和经过多次优化的FSTR-RCNN效果相当,可见,DETR作为transformer和目标检测结合的框架的开山之作,当之无愧!🐱🏍
2.DETR框架
DETR框架包括四部分,分别是CNN的backbone,transformer的encoder,transformer的decoder,预测层FFN(Feed Forward Network)。
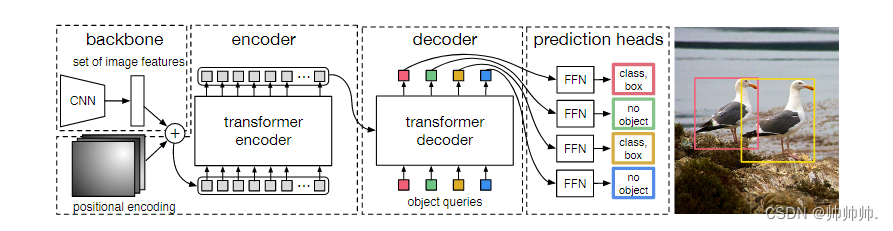
训练过程如下:
- CNN的backbone. 把图片放入CNN中,经过CNN网络提取出图片的特征,然后把特征拉直,加上positional encoding的位置信息,进入下一个环节 encoder。
- transformer encoder. 利用transformer进一步学习全局信息,为decoder生成预测框做铺垫。
- transformer decoder. 生成许多预测框,其中,object queries的作用就是限定会产生多少预测框(在本文中作者设置的是100,意思就是不管什么图片,只会产生100个预测框)。
- FFN(Feed Forward Network). 将产生的100个预测框和两个GT(ground truth)框进行match loss,然后计算最低得两个预测框,然后把剩余的98个标记为“no object”即为背景图。
推理过程: 前三步跟训练过程一样,仅仅是最后一步,计算loss变为设置一个阈值,置信度大于0.7的则保留,小于0.7则认为是背景图片。
总结
- detr对大物体预测很准,主要是因为transformer进行全局建模(如果用anchor 的话,就会受限于anchor的大小)
- detr对小物体检测效果并不好,因为他结构太简单(多尺度、多特征可以提高检测效果)
- 训练时间长,后续留给研究者的work很多















 1893
1893











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









