







yolov2检测网数据集标注_labelme使用_json2txt格式转换
一、安装Anaconda
下载anaconda:https://www.anaconda.com/download/
选择自己电脑相应的版本即可,具体的安装过程可自行百度。
二、创建labelme虚拟环境
打开Anaconda Prompt,或者将anaconda添加到系统环境cmd命令打开也可,可参考链接1。
conda create --name=labelme python=3.6
conda activate labelme
pip install pyqt5
pip install labelme
在该环境下输入labelme,具体的使用方法可以参考链接2

三、使用labelme标注健康非健康猫狗数据
labelme的标注快捷键:
W——新建标注框
A——上一张
D——下一张
ctrl+D——复制标签(选中需要复制的标签,ctrl+D,新复制的标签重叠在原标签上,拉出来就好了)
ctrl+S——保存
ctrl+滑动鼠标——放大缩小
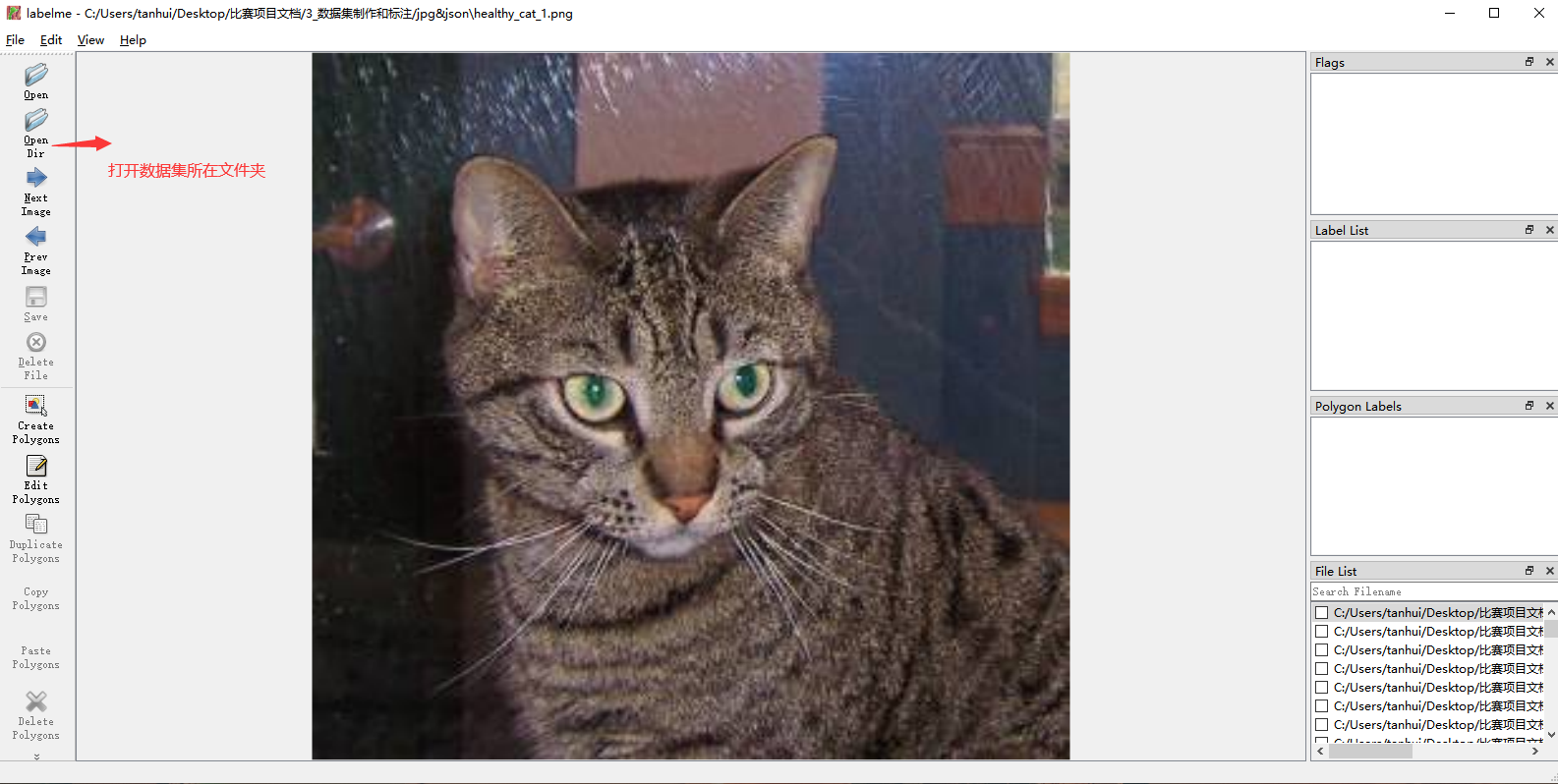
3.1 打开数据集所在文件夹

3.2 进行标注数据集
标签对应:
0 healthy_cat 300张
1 unhealthy_cat 300张
2 healthy_dog 300张
3 unhealthy_dog 300张
按照训练集:验证集:测试集 = 8:1:1

点击Create Polygons —> 鼠标放在图片上,按右键选create rectangle (一定需要是矩形,按两个点矩形不能旋转,一定就要正矩形)
因为健康非健康猫狗的区分特征主要是身体毛色等信息,所以我们需要标注整体动物个体,如上图所示。
说明:label按照上面所提的标签进行标注,Group ID可以不用填写。

为了实现标注后自动保存:点击左上角的File,找到Save Automatically并点击上,做完标注后后自动生成json文件,保存在放图片的文件夹下面,成功生成后,右下角小框会打勾。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OHyDVZWo-1691505768382)(02_标注健康与非健康猫狗数据.assets/image-20230507155220958.png)]](https://img-blog.csdnimg.cn/8ab26cb083ae439b91c615d3414e49fe.png#pic_center)
可以在file list中点下一张图片,也可以左边点next image,为了更快标注,使用快捷键A(上一张) 或 D(下一张) 进行切换图片进行标注。
3.3 json2txt
因为我们使用的是yolo检测框架,其训练环境为darknet,我们需要将前面得到的json标注文件转换为训练框架能够识别的格式,具体格式要求如下所示:
darknet标注信息的数据格式如下:
Class id center_x center_y w h
对数据格式解释如下:
Class id:表示标注框的类别,从0开始计算,当前只要手部1类检测物体,故Class id全为0;
center_x:表示归一化后的手部框中心点坐标的X值。归一化坐标 = 实际坐标 / 整个图片宽
center_y:表示归一化后的手部框中心点坐标的Y值。归一化坐标 = 实际坐标 / 整个图片高
w:表示归一化后的手部框的宽。归一化长度 = 实际长度 / 整个图片宽
h:表示归一化后的手部框的高。归一化长度 = 实际长度 /整个图片高

下面是labelme的json格式转换为darknet所需的txt格式程序:
import os
import json
import numpy as np
from PIL import Image
def json2txt(path_json,path_txt,path_image):
img = Image.open(path_image)
w = img.width #图片的宽
h = img.height #图片的高
with open(path_json,'r', encoding='gb18030') as path_json:
jsonx=json.load(path_json)
with open(path_txt,'w+') as ftxt:
for shape in jsonx['shapes']:
xy=np.array(shape['points'])
seq = []
#print(xy[1][1]) #xy[1]表示第二个点的坐标,xy[1][1]表示第四个值,即第二点的y坐标
center_x = (xy[0][0] + xy[1][0])/2/w #归一化后的中心点坐标的X值
center_y = (xy[0][1] + xy[1][1])/2/h #归一化后的中心点坐标的Y值
pet_w = abs(xy[0][0] - xy[1][0])/w #归一化后的宽
pet_h = abs(xy[0][1] - xy[1][1])/h # 归一化后的高
# for m,n in xy:
# seq.append(str(m)+" "+str(n))
#info = '0' + center_x + center_y + pet_w + pet_h
# 0健康猫 1非健康猫 2健康狗 3非健康狗
ftxt.writelines( '2 %.5f %.5f %.5f %.5f' % (center_x, center_y, pet_w, pet_h) + "\n") #
# ftxt.writelines(" ".join(seq)+"\n") #\n换行
#join(),str = "-";举例:seq = ("a", "b", "c"); # 字符串序列 print str.join( seq ); 结果:a-b-c
dir_json = 'C:/Users/tanhui/Desktop/code/cat_dog_dataset/user_json/3_unhealthy_dogs/' #json路径
dir_txt = 'C:/Users/tanhui/Desktop/code/cat_dog_dataset/user_txt/3_unhealthy_dogs/' #存取的txt路径
dir_image = 'C:/Users/tanhui/Desktop/code/cat_dog_dataset/user_jpg/3_unhealthy_dogs/' #图片的路径
if not os.path.exists(dir_txt):
os.makedirs(dir_txt)
list_json = os.listdir(dir_json)
list_image = os.listdir(dir_image)
for cnt,json_name in enumerate(list_json):
path_json = dir_json + json_name
path_image = dir_image + list_image[cnt] #image_name=list_image[cnt]
print('cnt=%d,name=%s,image=%s' % (cnt, json_name, list_image[cnt]))
path_txt = dir_txt + json_name.replace('.json','.txt')
json2txt(path_json, path_txt, path_image)
3.4 按文件目录和训练测试数据集重分配
如图是训练集和测试集文件夹结构:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-U2pF7IRo-1691505768383)(02_标注健康与非健康猫狗数据.assets/image-20230507200455460.png)]](https://img-blog.csdnimg.cn/194eb9c03cea40d6a1b52e35edeadc0c.png#pic_center)
JPEGImages放的是原始图像,labels放的是json2txt后的darknet标注格式信息,list存放的是原始图像的全局路径(放在服务器上的路径)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kD31t2b7-1691505768383)(02_标注健康与非健康猫狗数据.assets/image-20230507200842076.png)]](https://img-blog.csdnimg.cn/63ff268a5a38474baa2efe1b58cee1fd.png#pic_center)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WZkaya1B-1691505768383)(02_标注健康与非健康猫狗数据.assets/image-20230507200858973.png)]](https://img-blog.csdnimg.cn/b3edb96697dd4b32b6c4915e1c362c99.png#pic_center)

接下来给出写入原始图像路径到list中的程序:
import os
# 指定图片所在路径
img_dir = r"cat_dog_dataset\training_dataset\JPEGImages"
# 自定义输出文件路径和文件名
output_file = r"cat_dog_dataset\training_dataset\list\cat_dog_train.txt"
# 自定义写入txt文件的内容
txt_path = "/home/nicta100-s12/ai/cat_dog_detect/training_dataset/JPEGImages" #服务器绝对路径
# 写入文件
with open(output_file, "w") as f:
# 循环遍历所在路径下所有文件
for filename in os.listdir(img_dir):
filepath = os.path.join(img_dir, filename)
path = os.path.join(txt_path, filename)
path = path.replace("\\", "/") # 将路径中的反斜杠替换为正斜杠
# 判断是否为图片文件
if os.path.isfile(filepath) and (filepath.endswith(".jpg") or filepath.endswith(".png")):
# 将图片路径写入输出文件中
f.write(path + "\n")
四、数据喂给服务器网络
# test_dataset为测试数据
# training_dataset为训练数据
# JPEGImages目录下是需要进行训练的数据集图片
# labels目录下的txt是JPEGImages目录下对应图片所标注的labels
# list目录下的hand_train.txt文件中保存的是JPEGImages目录下所有图片的绝对路径。
# 注意:所有的txt文件都必须是linux格式的,可以使用 dos2unix 工具进行文件格式的转换
# 使用方法: dos2unix filename (如果还不知道如何使用,可上网咨询度娘)
注意:所有的txt文件都必须是linux格式的(包括了标签txt),可以使用 dos2unix 工具进行文件格式的转换,
使用方法: dos2unix filename (如果还不知道如何使用,可上网咨询度娘)
sudo apt-get install dos2unix # 如果服务器没有dos2unix这个软件的话,执行这条命令,先进行安装
dos2unix hand_test.txt # 修改某个文件的文件格式
dos2unix * # 修改该目录下的所有文件的文件格式
















 3324
3324

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









