







- ICCV2021 workshop
- https://github.com/JingyunLiang/SwinIR
- 问题引入
- 将swim transformer使用到图像恢复任务当中,因为卷积存在不能建模长距离依赖以及使用相同的卷积核来恢复不同的图像区域;
- 并不是首个将transformer引入图像恢复中的方法,但是之前的方法将图片分为固定大小的patch,在patch的边缘会产生伪影
- 方法
- 模型分为三个部分:shallow feature extraction, deep feature extraction和high-quality image reconstruction,其中深层特征提取器包含多个residual Swin Transformer blocks (RSTB)
- 特征提取模块对所有的任务共享,但是重建模块为任务单独设计;
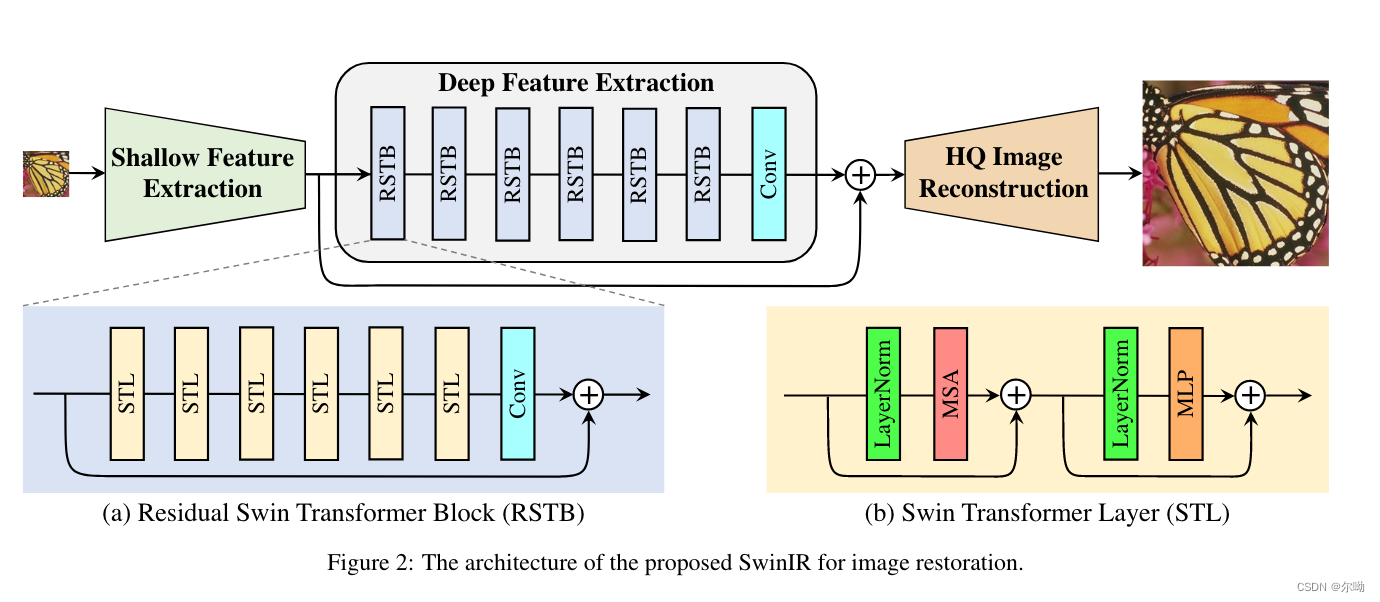
- Shallow and deep feature extraction:浅层特征提取,输入 I L Q ∈ R H × W × C i n I_{LQ}\in\mathbb{R}^{H\times W\times C_{in}} ILQ∈RH×W×Cin,经过一个 3 × 3 3\times 3 3×3的卷积层 H S F ( ⋅ ) H_{SF}(\cdot) HSF(⋅)得到输出 F 0 ∈ R H × W × C F_0\in\mathbb{R}^{H\times W\times C} F0∈RH×W×C,之后进行深层特征提取 F D F ∈ R H × W × C , F D F = H D F ( F 0 ) F_{DF}\in\mathbb{R}^{H\times W\times C},F_{DF}=H_{DF}(F_0) FDF∈RH×W×C,FDF=HDF(F0),其中 H D F ( ⋅ ) H_{DF}(\cdot) HDF(⋅)包含 K K K个residual Swin Transformer blocks (RSTB) and a 3 × 3 convolutional layer
- 图像重建层:以图像超分任务为例 I R H Q = H R E C ( F 0 + F D F ) I_{RHQ}=H_{REC}(F_0+F_{DF}) IRHQ=HREC(F0+FDF),使用sub-pixel convolution layer来进行上采样,假如不需要上采样的任务例如图像去噪和JPEG compression artifact reduction,就使用一层卷积实现重建层,模型学习的目标是LR和HR的residual,所以 I R H Q = H S w i n I R ( I L Q ) + I L Q I_{RHQ}=H_{SwinIR}(I_{LQ})+I_{LQ} IRHQ=HSwinIR(ILQ)+ILQ;
- 超分任务损失函数使用的是L1 pixel loss, L = ∣ ∣ I R H Q − I H Q ∣ ∣ 1 L = ||I_{RHQ}-I_{HQ}||_1 L=∣∣IRHQ−IHQ∣∣1,其他任务使用的是Charbonnier loss;
- Residual Swin Transformer Block:由L个STL和一个卷积层组成;
- Swin Transformer layer:对于输入 H × W × C H\times W\times C H×W×C,首先将输入reshape成 H W M 2 × M 2 × C \frac{HW}{M^2}\times M^2\times C M2HW×M2×C,总共有 H W M 2 \frac{HW}{M^2} M2HW个相互之间不重叠的window,之后再每个window上进行local attention,也就是标准的attention;对于当个window X ∈ R M 2 × C X\in\mathbb{R}^{M^2\times C} X∈RM2×C, Q = X P Q , K = X P K , V = X P V Q=XP_Q,K=XP_K,V=XP_V Q=XPQ,K=XPK,V=XPV,其中 P Q , P K , P V P_Q,P_K,P_V PQ,PK,PV是不同window之间共享的参数, Q , K , V ∈ R M 2 × d Q,K,V\in\mathbb{R}^{M^2\times d} Q,K,V∈RM2×d,之后 A t t e n t i o n ( Q , K , V ) = S o f t M a x ( Q K T / d + B ) V Attention(Q,K,V)=SoftMax(QK^T/\sqrt{d}+B)V Attention(Q,K,V)=SoftMax(QKT/d+B)V,其中 B B B是可学习的相对位置编码,此处是多头注意力机制,接下来是MLP层(包含两层全连接和GELU),整体 X = M S A ( L N ( X ) ) + X , X = M L P ( L N ( X ) ) + X X = MSA(LN(X))+X,X=MLP(LN(X))+X X=MSA(LN(X))+X,X=MLP(LN(X))+X,为了保证cross-window connections,铍铜的window partition和shifted window partition是交替使用的;

















 3349
3349

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









