







- tencent PCG
- https://arxiv.org/pdf/2302.08453
- https://github.com/TencentARC/T2I-Adapter?tab=readme-ov-file
- 问题引入
- 为sd模型在文本以外增加更多的控制,例如深度图等等,以adapter的形式;
- 认为sd模型本身就具备生成各种图片的能力,本文要做的只是一种对齐,模型内部能力和外部控制信号的对齐;
- methods
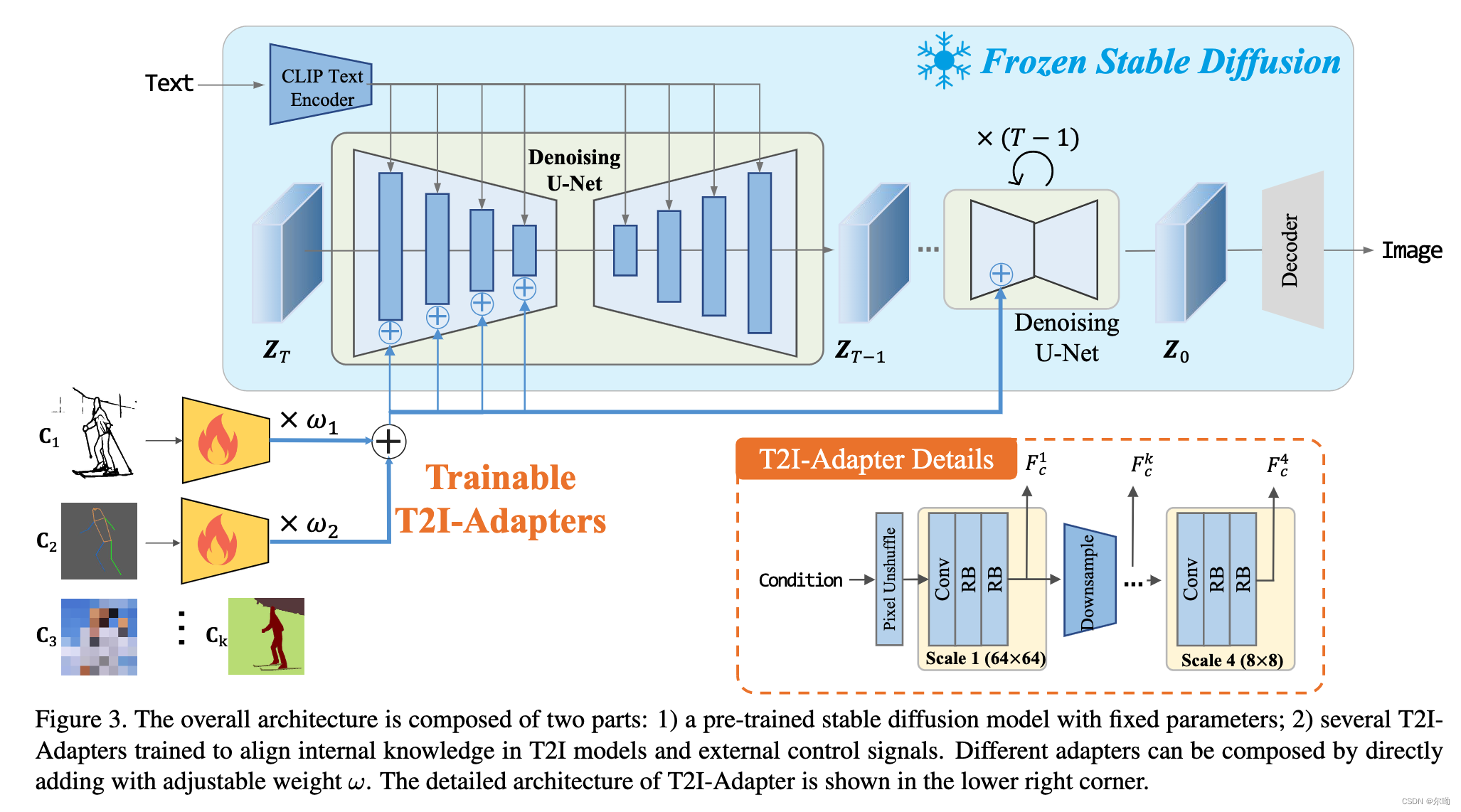
- 对于输入的条件 512 × 512 512\times 512 512×512,然后使用pixel shuffle来使其尺寸到达 64 × 64 64\times 64 64×64,总共有四个scale,每个scale包含一个卷积和2个residual blocks,这样可以得到multi scale的条件特征 F c = { F c 1 , F c 2 , F c 3 , F c 4 } F_c = \{F^1_c,F^2_c,F_c^3,F_c^4\} Fc={Fc1,Fc2,Fc3,Fc4},其中每个 F c i F_c^i Fci和unet对应scale的中间特征尺寸相同,分别进行相加;
- 对应结构性控制条件的图片直接作为输入,作为控制图片颜色的条件,首先进行降采样然后最近邻插值后的结果作为输入;
- 多个adapter可以进行叠加使用;
- 进行了cubic采样来提高较大t的概率来提高训练效果;















 861
861

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









