





综述
- 摘要
- 1.INTRODUCTION
- 2.BACKGROUND
- 3 METHODOLOGIES:A SURVEY
- 3.1 Domain Alignment(领域对齐)
- 3.2 Meta-Learning(元学习)
- 3.3 Data Augmentation (数据增强)
- 3.4 Ensemble Learning (集成学习)
- 3.5 Network Architecture Design (网络架构设计)
- 3.6 Self-Supervised Learning (自监督学习)
- 3.7 Learning Disentangled Representations (学习解耦表示)
- 3.8 Invariant Risk Minimization (不变风险最小化)
- 3.9 Training Heuristics (训练启发法)
- 3.10 Side Information (辅助信息)
- 3.11 Transfer Learning(迁移学习)
- 4. FUTURE RESEARCH DIRECTIONS
- 5. CONCLUSION
摘要
面向非分布(OOD,out of the distribution)数据的泛化是人类的一项自然能力但机器的重现却具有挑战性。这是因为大多数统计学习算法强烈依赖于源/目标数据的i.d.假设,而在实践中,源和目标之间的领域偏移是普遍的,领域泛化(DG)的目标是通过仅使用源数据进行模型学习来实现OOD泛化。自2011年首次提出以来,DG的研究取得了很大的进展。特别是,对这一主题的深入研究已经产生了广泛的方法论,例如,那些基于领域对齐,元学习,数据增强,或集成学习,仅举几个例;并涵盖了各种应用,如物体识别,分割,动作识别,行人再识别。本文首次对近十年来的发展进行了全面的文献综述。具体来说,我们首先对DG进行了正式的定义,并将其与领域自适应和迁移学习等其他研究领域联系起来。其次,我们对现有的方法进行了全面的回顾,并根据它们的方法和动机进行了分类。最后,我们通过对未来研究方向的见解和讨论来结束本次调查。
1.INTRODUCTION

2.BACKGROUND

2.1 A Brief History of Domain Generalization

2.2 Problem Definition


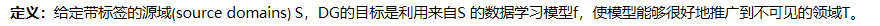



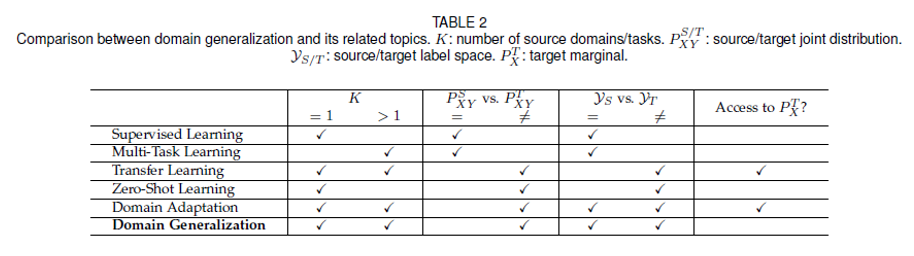
2.3 Related Topics





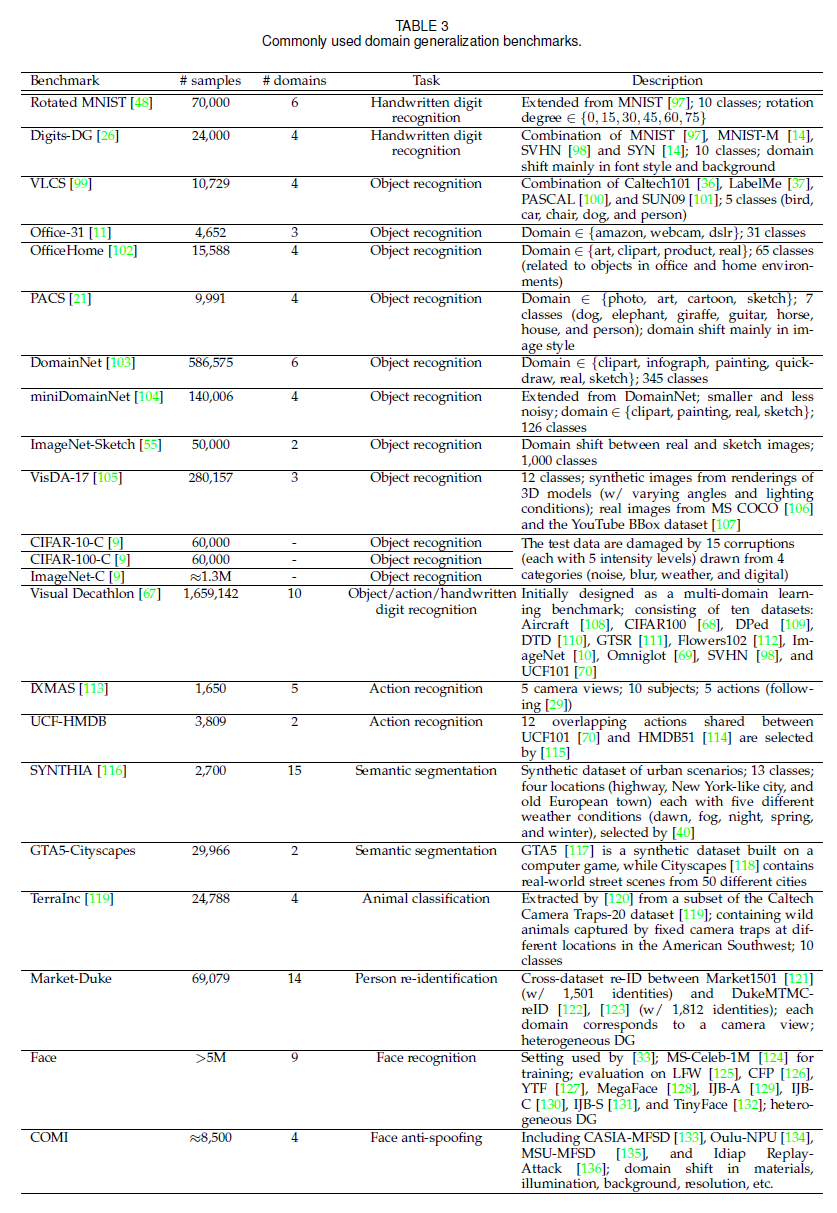
2.4 Evaluation and Datasets







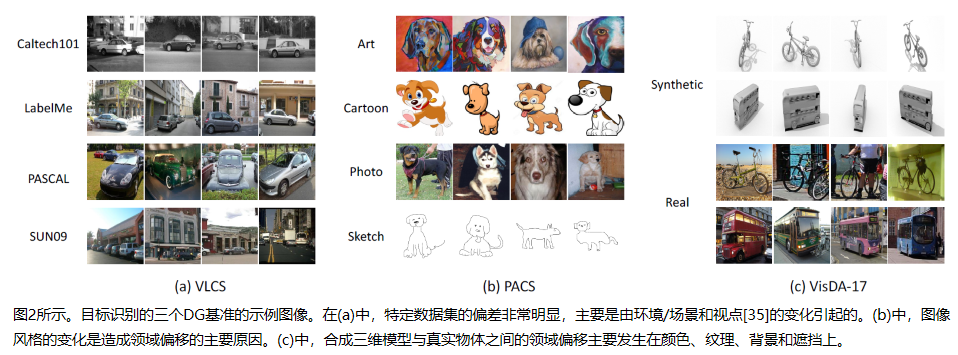






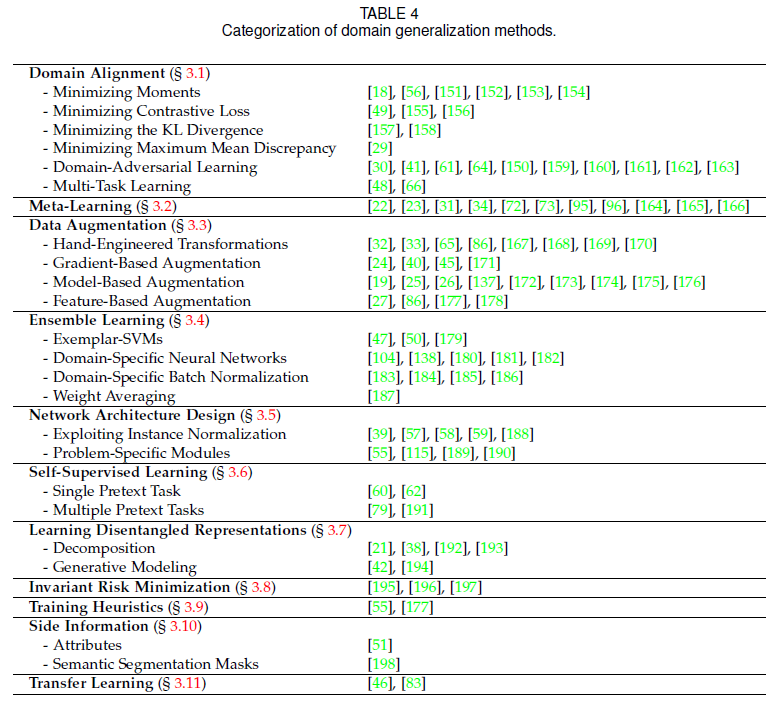
3 METHODOLOGIES:A SURVEY

3.1 Domain Alignment(领域对齐)

3.1.1 What to Align
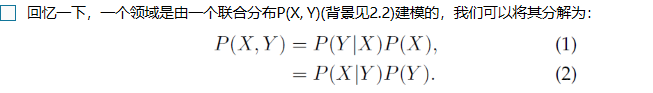
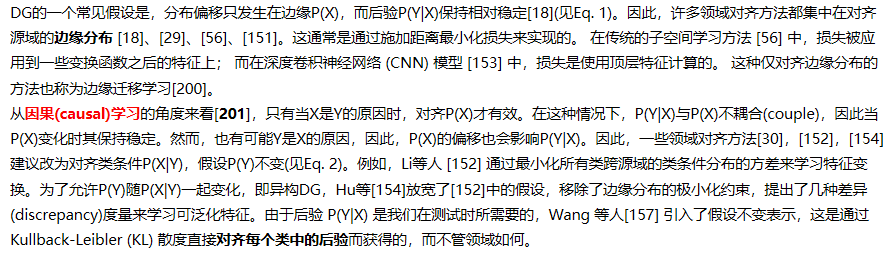
3.1.2 How to Align

3.2 Meta-Learning(元学习)

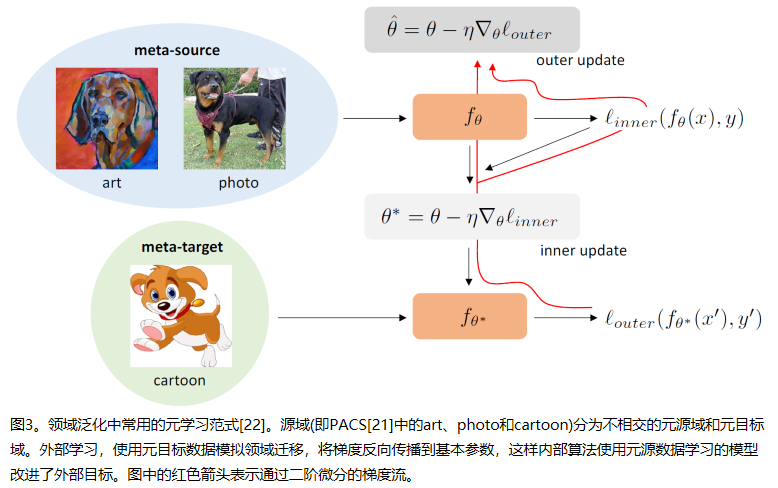

3.3 Data Augmentation (数据增强)

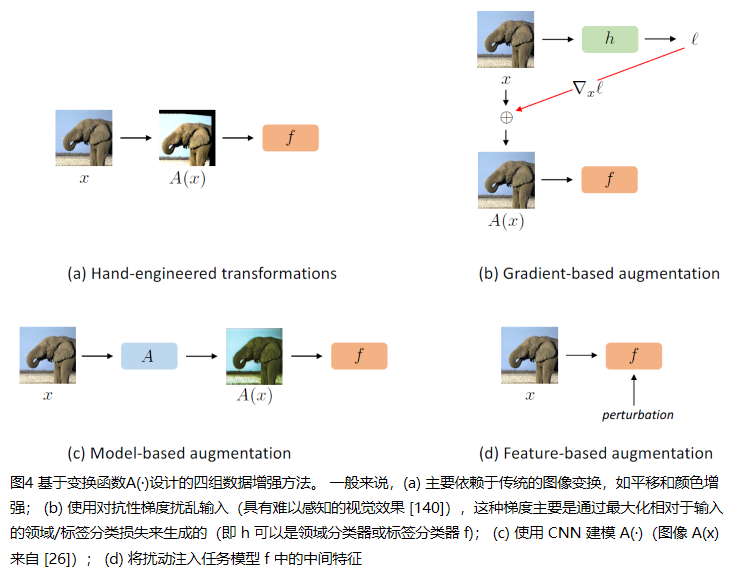





3.4 Ensemble Learning (集成学习)

3.5 Network Architecture Design (网络架构设计)

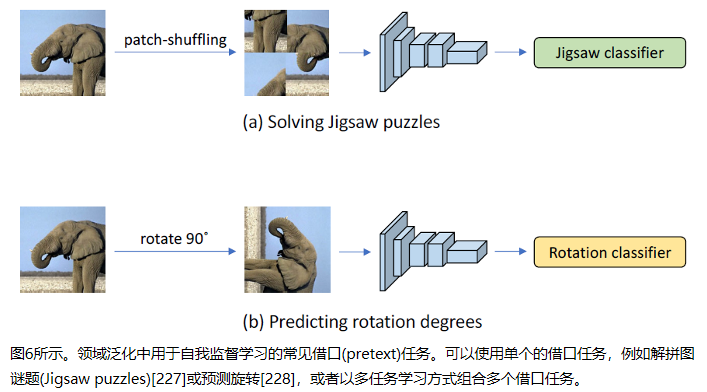
3.6 Self-Supervised Learning (自监督学习)

3.7 Learning Disentangled Representations (学习解耦表示)

3.8 Invariant Risk Minimization (不变风险最小化)

3.9 Training Heuristics (训练启发法)

3.10 Side Information (辅助信息)

3.11 Transfer Learning(迁移学习)

4. FUTURE RESEARCH DIRECTIONS

4.1 Model Arichitecture

4.2 Learning
4.3 Benchmarks

5. CONCLUSION
















 1409
1409











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









