







 本文探讨了信贷风控中A卡模型的局限性,提出拒绝演绎策略来解决样本差异问题,通过模型赋值法等方法降低影响,优化贷前决策。关键点包括定义拒绝样本、确定比例及效果验证方法。
本文探讨了信贷风控中A卡模型的局限性,提出拒绝演绎策略来解决样本差异问题,通过模型赋值法等方法降低影响,优化贷前决策。关键点包括定义拒绝样本、确定比例及效果验证方法。
在金融信贷场景的风控体系中,贷前环节往往是通过策略或模型的“决策”动作进行风险防范的,无论是反欺诈,还是信用评估,或者是精准营销等。对于风控系统,有了“决策”审批,自然会有“通过”和“拒绝”的结果。例如,当申请用户触发反欺诈规则会直接拒绝,否则会正常通过;当申请用户触发信用风险模型的阈值会直接拒绝,否则会正常通过等。
在贷前风控的决策过程中,申请信用评分卡模型(A卡)应用非常广泛,在信贷产品业务的很多环节发挥着极为重要的作用,包括风险识别、产品定价、客户分群等方面。A卡模型的构建是一类有监督模型,即根据存量用户在事件发起时点的申请信息,与事件结束时点的还款表现,采用有监督的机器学习算法,对模型进行拟合训练,最终实现模型的线上部署应用。这里需要说明的是,对于A卡模型,往往是基于有贷后表现的用户数据进行建模,而模型的应用是面向未来可能待通过和待拒绝的所有用户群体,这在很大程度上反映了模型训练的样本特征,与模型应用的样本特征存在较大差异,使得模型在实际应用过程中很有可能出现效果不佳的情况。
为了应对此类实际业务中必然存在的问题,拒绝演绎(拒绝推论)的思想可以有效降低A卡模型建立与应用的样本差异影响,从而提高贷前风控模型的风险识别效果,这样更满足实际业务客观情况。拒绝推论主要工作是将通过样本与拒绝样本进行合并,然后实现联合建模,在具体实现过程中,主要存在两个难点,分别是:
1、如何定义拒绝样本的目标变量?
2、如何确定拒绝样本的引入比例?
当有效解决了这两个核心问题,对于联合建模的任务就变得简单很多,即采用合适的算法进行样本处理和模型训练,和我们正常建模的流程是一致的。
对于拒绝推论的方法,常见的有模型赋值法、随机扩充法、特征聚类法、专家经验法等(如图1),虽然每种方法在处理流程、算法选择、业务理解等方面存在较大差异,但最终目标是一致的,即更合理地对拒绝样本的好坏标签进行设定,然后通过有效的机器学习算法得到更符合实际业务的风控模型。
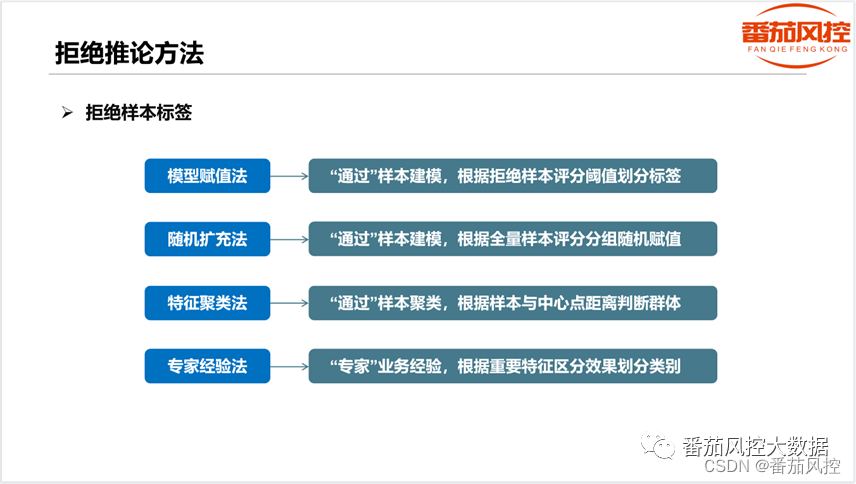
图1 拒绝推论常见方法
当得到拒绝推论模型之后,除了正常评估模型的性能之外,例如模型评分的区分效果(如图2所示),以及模型指标KS、AUC、Accuracy等,还需要重点评估下通过样本与拒绝样本在拒绝推论模型上的具体表现,常见的方法有样本坏账分布、特征分箱IV值、验证样本测试、线上AB-test等,如图3所示。
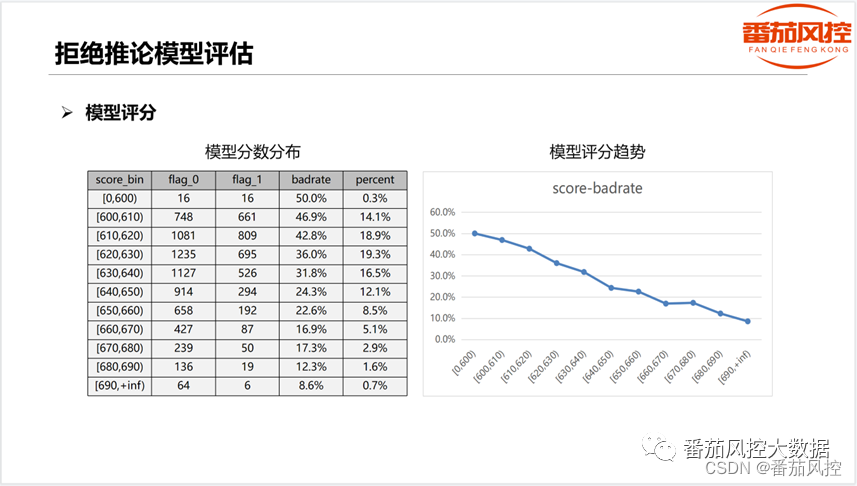
图2 模型评分分布
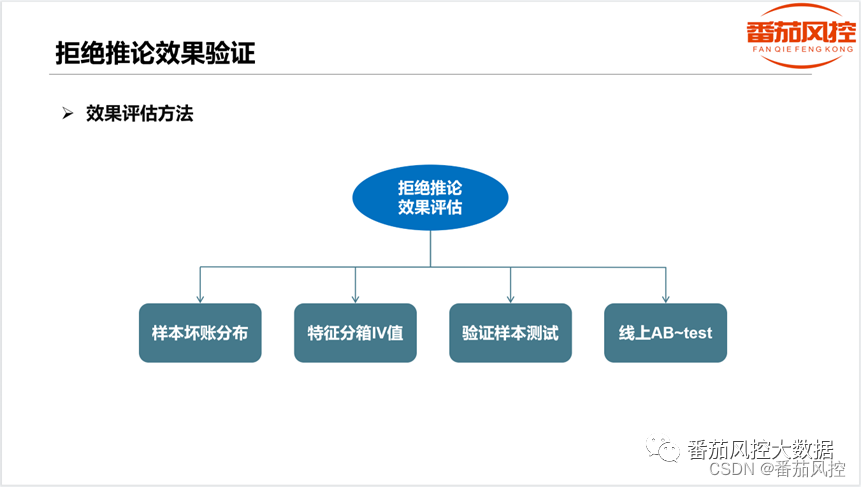
图3 拒绝推论效果验证方法
针对以上介绍的信贷风控的拒绝推论场景,可关注-
《信贷风控拒绝演绎实战》:
…
~原创文章

















 1256
1256

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









