







LLM本身的表征直接用于Embedding,比如用于检索/聚类/STS等任务,效果其实不太好。因此才需要将Embedding模型和大模型区分开来。本文介绍一篇将LLM转换为Embedding模型的工作,代码全开源,值得好好学习。
论文题目:LLM2Vec: Large Language Models Are Secretly Powerful Text Encoders
来源:Arxiv2024/麦吉尔大学
方向:文本编码/LLM
开源地址:https://github.com/McGill-NLP/llm2vec
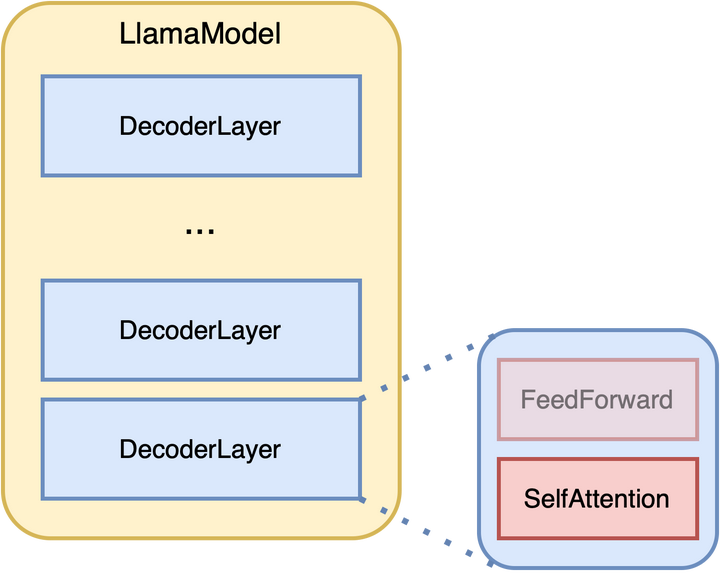
转换LLM为Text Encoder的三步骤
参考作者的Tutorial ,以LLaMA2和FlashAttention为例介绍主要的三个步骤
第一步:实现双向注意力
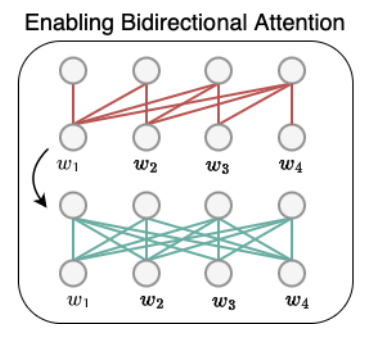
对于llama这样的transformer模型来说,每一层都含有一个自注意力的子层,而这些自注意力在得到embedding的时候都会mask后面的词的attention,只保留前面的词语,即单向注意力。所以需要先将这个掩蔽关闭,每个词都可以和句子中所有词语进行注意力交互,从而实现双向注意力。如下图所示:
下面介绍下代码。首先需要修改llama_attention子层的实现。llama_attention有三种实现,在此我们需要将LlamaFlashAttention2中的is_causal设置为False,从而改为双向注意力。其实只修改了__init__函数
class ModifiedLlamaFlashAttention2(LlamaFlashAttention2):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.is_causal = False # 原Trnasformer实现中是True
LLAMA_ATTENTION_CLASSES = {
"eager": LlamaAttention,
"flash_attention_2": ModifiedLlamaFlashAttention2, # 原是`LlamaFlashAttention2'
"sdpa": LlamaSdpaAttention,
}
接下来需要将每个Decoder层中的attention改为双向注意力attention实现。同样只需要修改__init__函数。这一段直接从transformers库中复制即可
class ModifiedLlamaDecoderLayer(LlamaDecoderLayer):
def __init__(self, config: LlamaConfig, layer_idx: int):
nn.Module.__init__(self) # Initially, super().__init__()
self.hidden_size = config.hidden_size
# 这一行将注意力类绑定为LLAMA_ATTENTION_CLASSES中自定义的类
self 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 424
424

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









