







后台有读者翻到了一年前发的文献解读,请教了一下文章的图的做法。正好前段时间刚做过单细胞转录组分析,今天就给大家介绍一下常用工具Seurat的用法。
Seurat 4.0 使用指南
设置Seurat对象
示例数据
10X Genomics免费提供的外周血单核细胞(PBMC)数据集。通过Illumina NextSeq 500测序的2700个单细胞。示例数据下载:https://cf.10xgenomics.com/samples/cell/pbmc3k/pbmc3k_filtered_gene_bc_matrices.tar.gz。(或者后台回复seurat,领取完整代码及示例数据)
setwd(".../filtered_gene_bc_matrices/hg19") #设置工作环境到数据所在文件夹
#安装和加载所需包
BiocManager::install("Seurat")
BiocManager::install("dplyr")
BiocManager::install("patchwork")
library(dplyr)
library(Seurat)
library(patchwork)
#导入示例数据
pbmc.data <- Read10X(data.dir = ".../filtered_gene_bc_matrices/hg19/")#自行填写数据所在文件夹
#创建Seurat对象
pbmc <- CreateSeuratObject(counts = pbmc.data, project = "pbmc3k", min.cells = 3, min.features = 200)
#过滤检测少于200个基因的细胞(min.features = 200)和少于3个细胞检测出的基因(min.cells = 3)
pbmc
#参数解释
CreateSeuratObject(
counts, #未标准化的数据,如原始计数或TPMs
project = "CreateSeuratObject",#设置Seurat对象的项目名称
assay = "RNA", #与初始输入数据对应的分析名称
names.field = 1,#对于每个cell的初始标识类,从cell的名称中选择此字段。例如,如果cell在输入矩阵 #中被命名为BARCODE_CLUSTER_CELLTYPE,则设置名称。字段设置为3以将初始标识设置为 #CELLTYPE。
names.delim = "_", #对于每个cell的初始标识类,从cell的列名中选择此分隔符。例如,如果cell命名 #为bar - cluster - celltype,则将此设置为“-”,以便将cell名称分离到其组成部分 #中,以选择相关字段。
meta.data = NULL, #要添加到Seurat对象的其他单元级元数据。应该是data.frame,其中行是单元格名称,列 #是附加的元数据字段。
...
min.cells #包含至少在这些细胞检测到的features。
min.features #包含至少检测到这些features的细胞
)
> pbmc
An object of class Seurat
13714 features across 2700 samples within 1 assay
Active assay: RNA (13714 features, 0 variable features)
#1个数据集,包含2700个细胞,13714个基因。
数据矩阵
# 查看这三个基因的前三十行矩阵
pbmc.data[c("CD3D", "TCL1A", "MS4A1"), 1:30]
> pbmc.data[c("CD3D", "TCL1A", "MS4A1"), 1:30]
3 x 30 sparse Matrix of class "dgCMatrix"
[[ suppressing 30 column names ‘AAACATACAACCAC-1’, ‘AAACATTGAGCTAC-1’, ‘AAACATTGATCAGC-1’ ... ]]
CD3D 4 . 10 . . 1 2 3 1 . . 2 7 1 . . 1 3 . 2
TCL1A . . . . . . . . 1 . . . . . . . . . . .
MS4A1 . 6 . . . . . . 1 1 1 . . . . . . . . .
CD3D 3 . . . . . 3 4 1 5
TCL1A . 1 . . . . . . . .
MS4A1 36 1 2 . . 2 . . . .
.在矩阵中的值表示0(未检测到分子)。由于scRNA-seq矩阵中的大多数值为0,因此Seurat在任何可能的情况下都使用稀疏矩阵表示。这为Drop-seq/inDrop/10x数据节省了大量内存和速度。
标准的预处理流程
下面的步骤包含了Seurat中的scRNA-seq数据的标准预处理流程。包括QC(质控)、数据归一化以及细胞的选择和过滤。
QC和细胞筛选
常用的质控指标:
- 每个细胞在检测到的特异基因数
- 低质量细胞或空液滴通常只能检测到非常少的基因
- 两个或多个细胞被同时捕获通常会有很高的基因数
- 每个细胞检测到的分子总数(与基因密切相关)
- 每个细胞的线粒体基因比例
- 低质量/濒死细胞常表现出广泛的线粒体污染
- 使用
PercentageFeatureSet()函数计算线粒体QC指标 - 使用所有以MT-开头的基因作为一组线粒体基因
#向pbmc新增一列percent.mt数据
pbmc[["percent.mt"]] <- PercentageFeatureSet(pbmc, pattern = "^MT-")
QC指标储存在哪?
每个细胞基因数和总分子数在建立seurat对象时就已经自动计算好了。
#展示前5个细胞的QC指标
head(pbmc@meta.data, 5)
> head(pbmc@meta.data, 5)
orig.ident nCount_RNA
AAACATACAACCAC-1 pbmc3k 2419
AAACATTGAGCTAC-1 pbmc3k 4903
AAACATTGATCAGC-1 pbmc3k 3147
AAACCGTGCTTCCG-1 pbmc3k 2639
AAACCGTGTATGCG-1 pbmc3k 980
nFeature_RNA percent.mt
AAACATACAACCAC-1 779 3.0177759
AAACATTGAGCTAC-1 1352 3.7935958
AAACATTGATCAGC-1 1129 0.8897363
AAACCGTGCTTCCG-1 960 1.7430845
AAACCGTGTATGCG-1 521 1.2244898
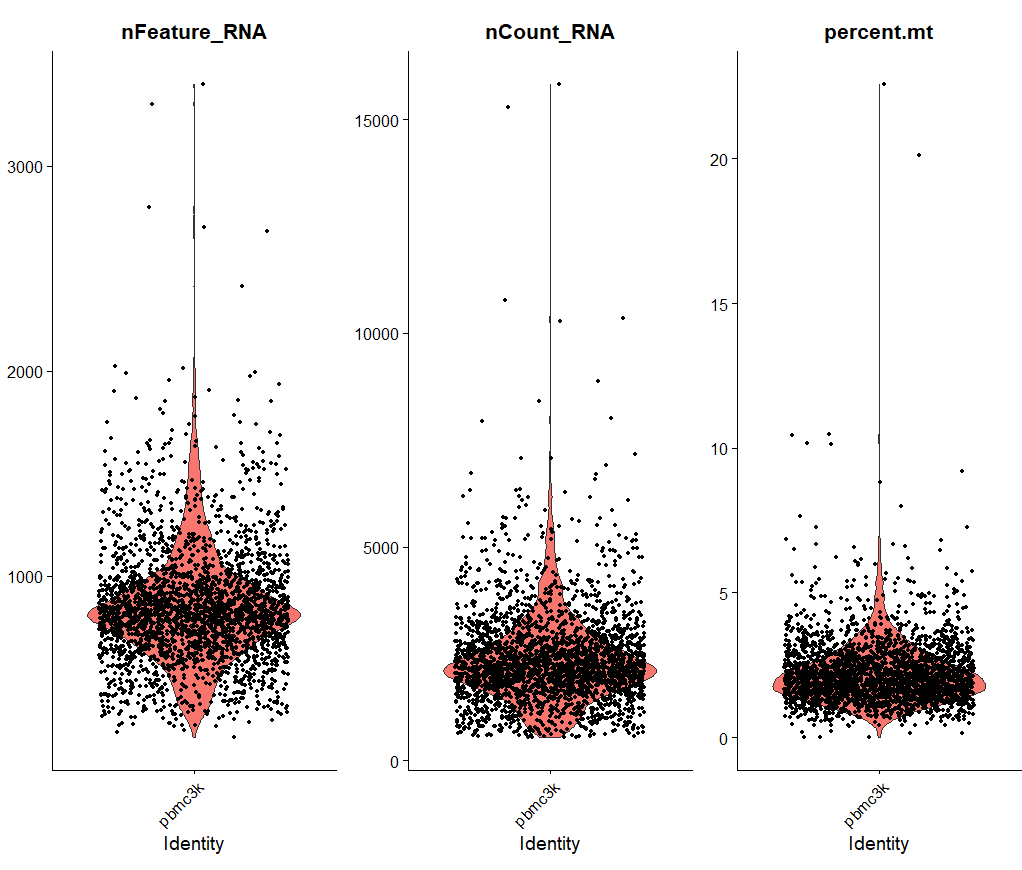
#使用小提琴图可视化QC指标
VlnPlot(pbmc, features = c("nFeature_RNA", "nCount_RNA", "percent.mt"), ncol = 3)
nFeature_RNA代表每个细胞测到的基因数目。nCount_RNA代表每个细胞测到所有基因的表达量之和。percent.mt代表测到的线粒体基因的比例。
#FeatureScatter通常用于可视化 feature-feature 相关性,
#nCount_RNA 与percent.mt的相关性
plot1 <- FeatureScatter(pbmc, feature1 = "nCount_RNA", feature2 = "percent.mt")
#nCount_RNA与nFeature_RNA的相关性
plot2 <- FeatureScatter(pbmc, feature1 = "nCount_RNA", feature2 = "nFeature_RNA")
plot1 + plot2 #合并两图
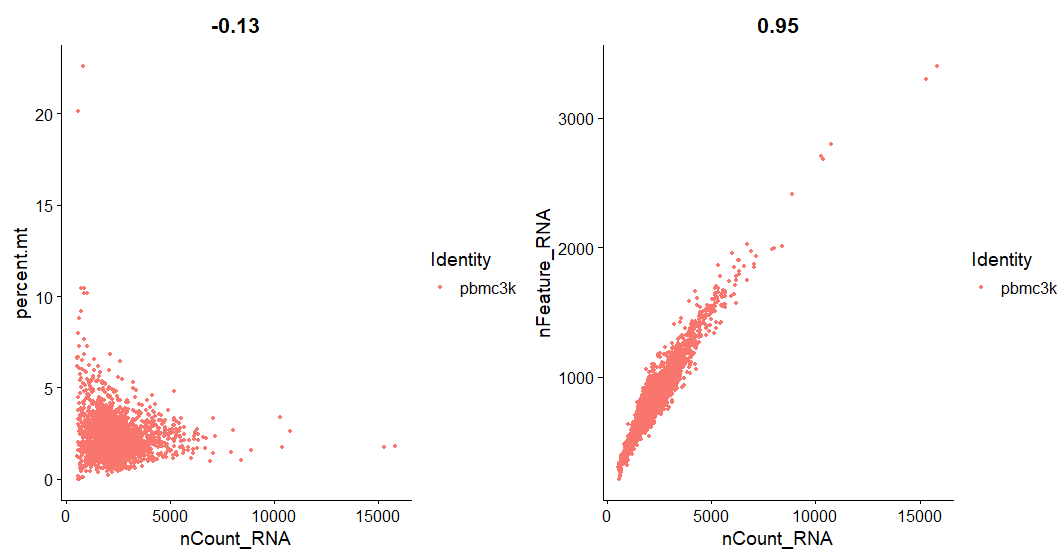
过滤线粒体基因表达比例过高的细胞,和一些极值细胞(可以根据小提琴图判断,查看两端离群值)。
pbmc <- subset(pbmc, subset = nFeature_RNA > 200 & nFeature_RNA < 2500 & percent.mt < 5)
#滤掉 2500 > nFeature_RNA >200 和percent.mt < 5的数据
数据标准化
默认情况下,使用全局缩放归一化方法“LogNormalize”,用总表达量对每个细胞的基因表达式进行归一化,再乘以一个缩放因子(默认为10,000),然后对结果进行log转换。标准化的数值存储在pbmc[["RNA"]]@data中。
pbmc <- NormalizeData(pbmc, normalization.method = "LogNormalize", scale.factor = 10000)
若所有调用的参数都是默认值,则可省去。
pbmc <- NormalizeData(pbmc)
鉴定高变基因
接下来,计算数据集中表现出高细胞间变异的特征基因(即,它们在某些细胞中高表达,而在其他细胞中低表达)。这些基因有助于突出单细胞数据集中的生物信号。
用FindVariableFeatures()函数实现。默认情况下,每个数据集返回2000个features 。这些将用于下游分析,如PCA。
pbmc <- FindVariableFeatures(pbmc, selection.method = "vst", nfeatures = 2000)
# 查看最高变的10个基因
top10 <- head(VariableFeatures(pbmc), 10)
# 画出不带标签或带标签基因点图
plot1 <- VariableFeaturePlot(pbmc)
plot2 <- LabelPoints(plot = plot1, points = top10, repel = TRUE)
plot1 + plot2
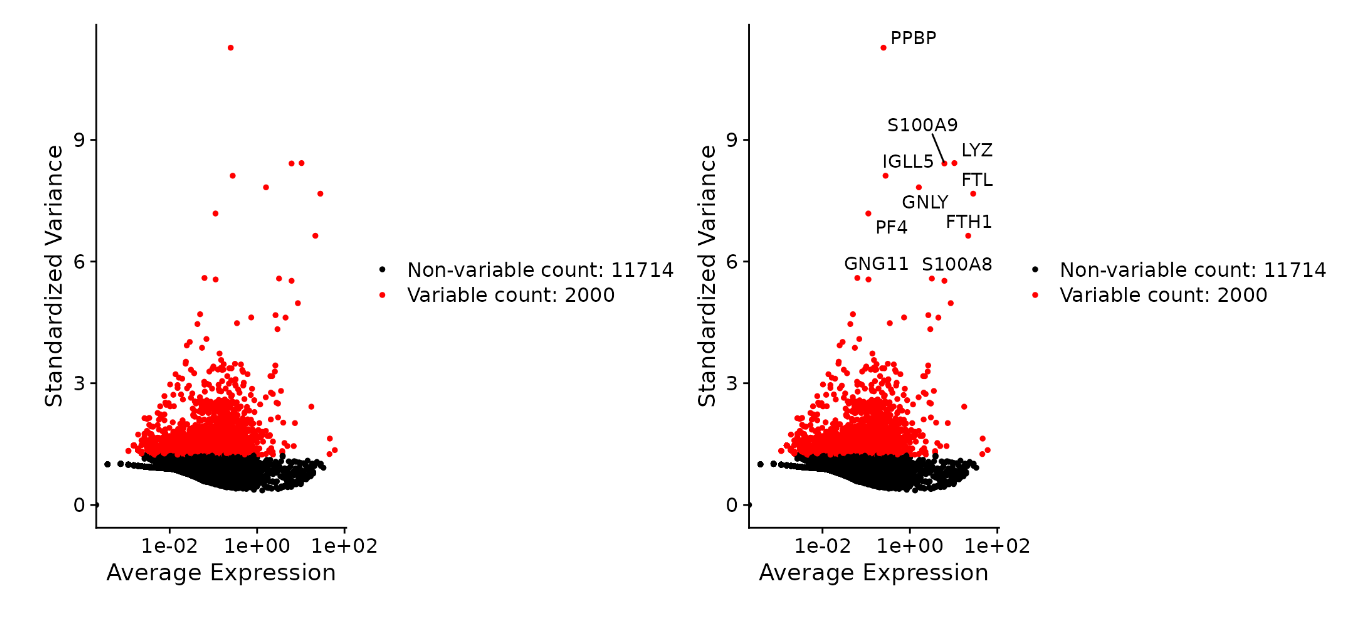
数据缩放
线性变换(“缩放”),是在PCA降维之前的一个标准预处理步骤。ScaleData()函数功能:
-
转换每个基因的表达值,使每个细胞的平均表达为0
-
转换每个基因的表达值,使细胞间的方差为1
- 此步骤在下游分析中具有相同的权重,因此高表达的基因不会占主导地位
-
结果存储在
pbmc[["RNA"]]@scale.data中
all.genes <- rownames(pbmc)
pbmc <- ScaleData(pbmc, features = all.genes)
线性降维
接下来,对缩放的数据执行PCA。默认情况下,只使用前面确定的变量特性作为输入,但是如果想选择不同的子集,可以使用features参数来定义。
pbmc <- RunPCA(pbmc, features = VariableFeatures(object = pbmc))
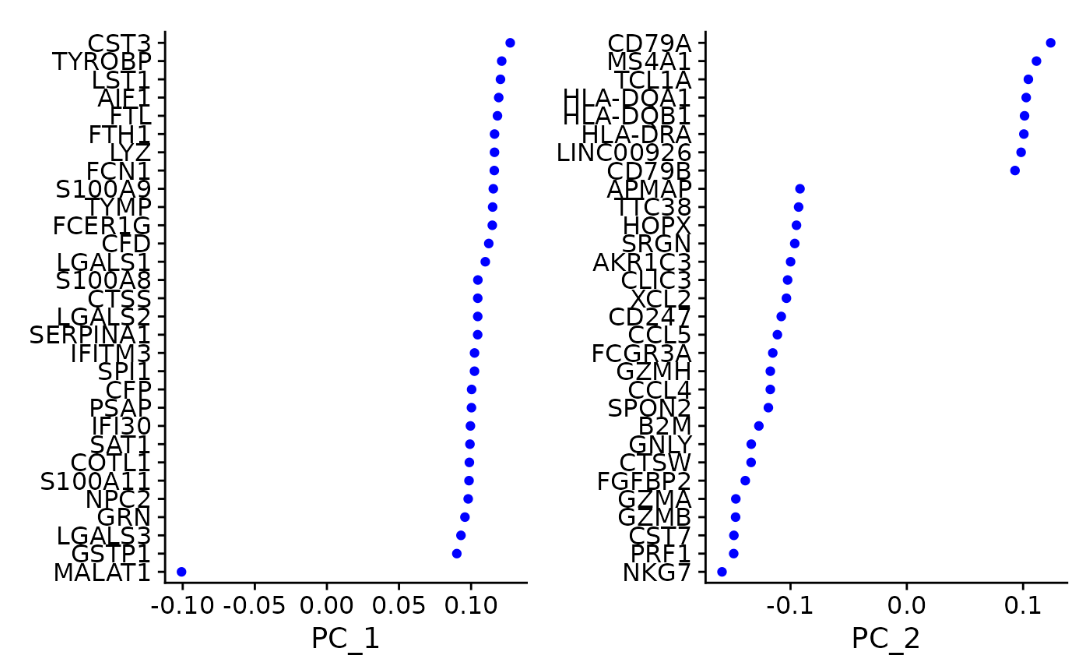
Seurat提供了几种有用的方法来可视化细胞和定义PCA的特性,包括VizDimReduction、DimPlot和DimHeatmap
#查看PCA结果
print(pbmc[["pca"]], dims = 1:5, nfeatures = 5)
> print(pbmc[["pca"]], dims = 1:5, nfeatures = 5)
PC_ 1
Positive: CST3, TYROBP, LST1, AIF1, FTL
Negative: MALAT1, LTB, IL32, IL7R, CD2
PC_ 2
Positive: CD79A, MS4A1, TCL1A, HLA-DQA1, HLA-DQB1
Negative: NKG7, PRF1, CST7, GZMB, GZMA
PC_ 3
Positive: HLA-DQA1, CD79A, CD79B, HLA-DQB1, HLA-DPB1
Negative: PPBP, PF4, SDPR, SPARC, GNG11
PC_ 4
Positive: HLA-DQA1, CD79B, CD79A, MS4A1, HLA-DQB1
Negative: VIM, IL7R, S100A6, IL32, S100A8
PC_ 5
Positive: GZMB, NKG7, S100A8, FGFBP2, GNLY
Negative: LTB, IL7R, CKB, VIM, MS4A7
VizDimLoadings(pbmc, dims = 1:2, reduction = "pca")
DimPlot(pbmc, reduction = "pca")
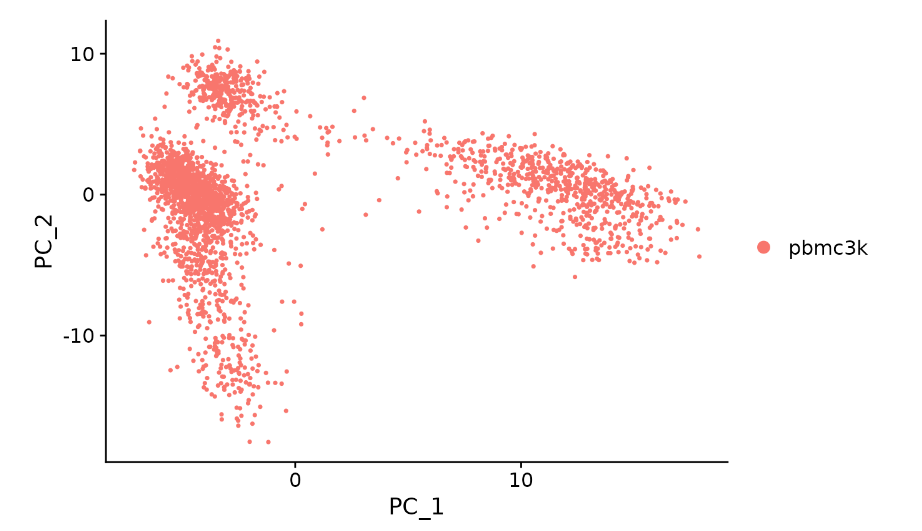
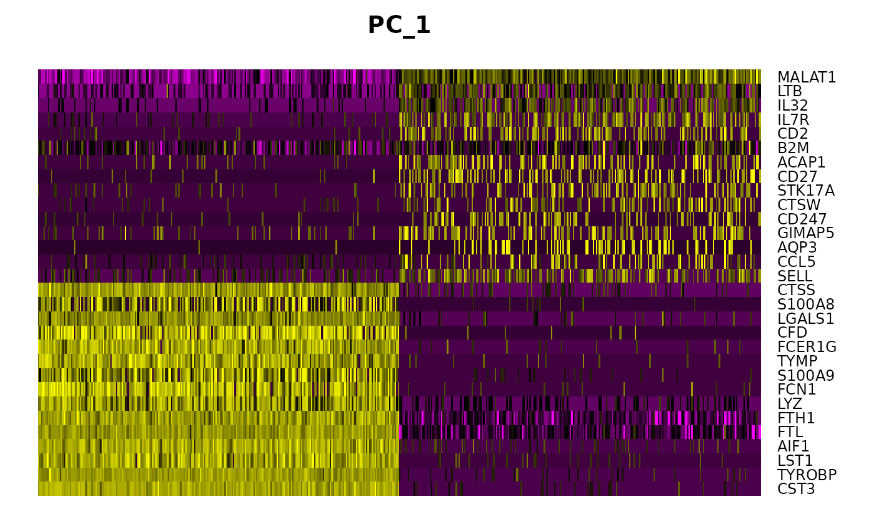
DimHeatmap()可以方便地探索数据集中异质性的主要来源,并且可以确定哪些PC维度可以用于下一步的下游分析。细胞和基因根据PCA分数来排序。
DimHeatmap(pbmc, dims = 1, cells = 500, balanced = TRUE) #1个PC 500个细胞
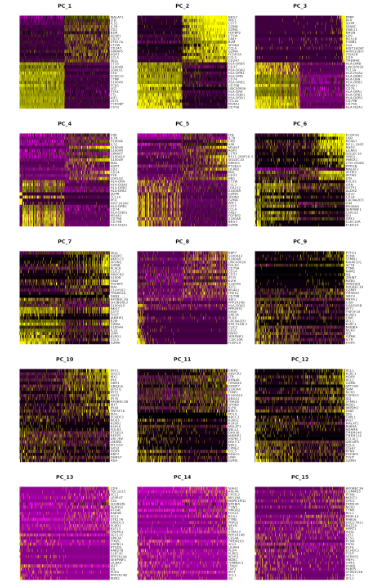
DimHeatmap(pbmc, dims = 1:15, cells = 500, balanced = TRUE) #15个PC
确定数据的维度
主成分分析的原理非常简单,概括来说就是选择包含信息量大的维度(features),去除信息量少的“干扰”维度。所以这里会有个问题——如何知道保留几个维度是最佳的呢?我们希望通过保留尽可能少的维度来留存尽可能多的信息。Seurat有两种方法来确定维度。
- JackStraw
pbmc <- JackStraw(pbmc, num.replicate = 100)
pbmc <- ScoreJackStraw(pbmc, dims = 1:20)
JackStrawPlot(pbmc, dims = 1:15)
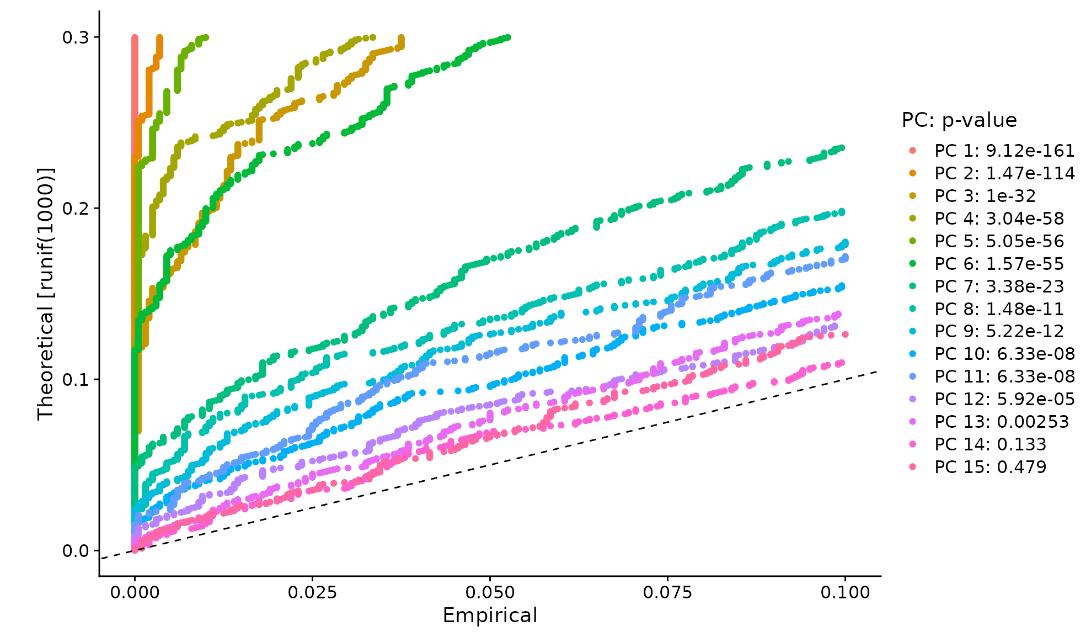
可以看出,在10-12个PC之后,显著性大幅下降,也就是前10-12个维度包含了大部分的样本信息。
- Elbow plot
ElbowPlot(pbmc)
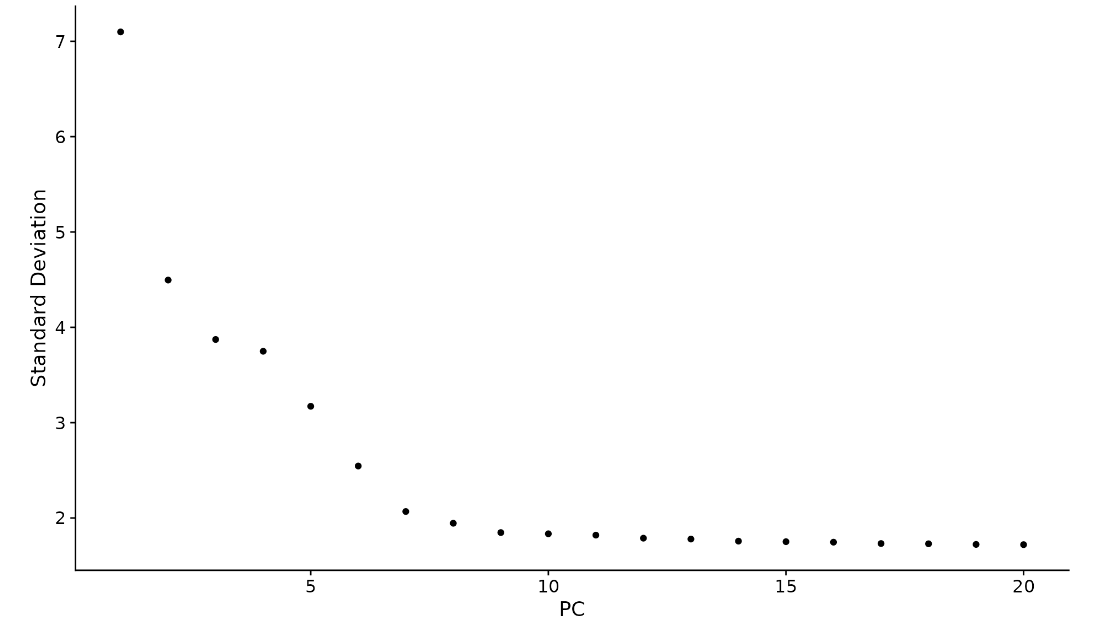
可以看出,PC9-10附近有一个拐点(“elbow”),这表明大部分真实信号是在前10个pc中捕获的。
综合以上方法,选择10个主成成分作为参数用于后续分析。
细胞聚类
Seurat使用KNN算法进行聚类。
pbmc <- FindNeighbors(pbmc, dims = 1:10)
pbmc <- FindClusters(pbmc, resolution = 0.5)
#dims = 1:10 即选取前10个主成分来分类细胞。
#查看前5个细胞的分类ID
head(Idents(pbmc), 5)
非线性降维(UMAP/tSNE)
pbmc <- RunUMAP(pbmc, dims = 1:10)
DimPlot(pbmc, reduction = "umap")
# 显示在聚类标签
DimPlot(pbmc, reduction = "umap", label = TRUE)
# 使用TSNE聚类
pbmc <- RunTSNE(pbmc, dims = 1:10)
DimPlot(pbmc, reduction = "tsne")
# 显示在聚类标签
DimPlot(pbmc, reduction = "tsne", label = TRUE)
#保存rds,用于后续分析
saveRDS(pbmc, file = "../output/pbmc_tutorial.rds")
找差异表达基因(聚类标志cluster biomarkers)
利用 FindMarkers 命令,可以找到找到各个细胞类型中与其他类别的差异表达基因,作为该细胞类型的生物学标记基因。
-
dent.1参数设置待分析的细胞类别 -
min.pct参数,在两组细胞中的任何一组中检测到的最小百分 -
thresh.test参数,在两组细胞间以一定数量的差异表达(平均) -
max.cells.per.ident参数,通过降低每个类的采样值,提高计算速度
# cluster 1的标记基因
cluster1.markers <- FindMarkers(pbmc, ident.1 = 1, min.pct = 0.25)
head(cluster1.markers, n = 5)
#找出区分cluster 5与cluster 0和cluster 3的所有标记
cluster5.markers <- FindMarkers(pbmc, ident.1 = 5, ident.2 = c(0, 3), min.pct = 0.25)
head(cluster5.markers, n = 5)
# 找出每个cluster的标记与所有剩余的细胞相比较,只报告阳性细胞
pbmc.markers <- FindAllMarkers(pbmc, only.pos = TRUE, min.pct = 0.25, logfc.threshold = 0.25)
pbmc.markers %>% group_by(cluster) %>% top_n(n = 2, wt = avg_log2FC)
可视化
VlnPlot(pbmc, features = c("MS4A1", "CD79A"))
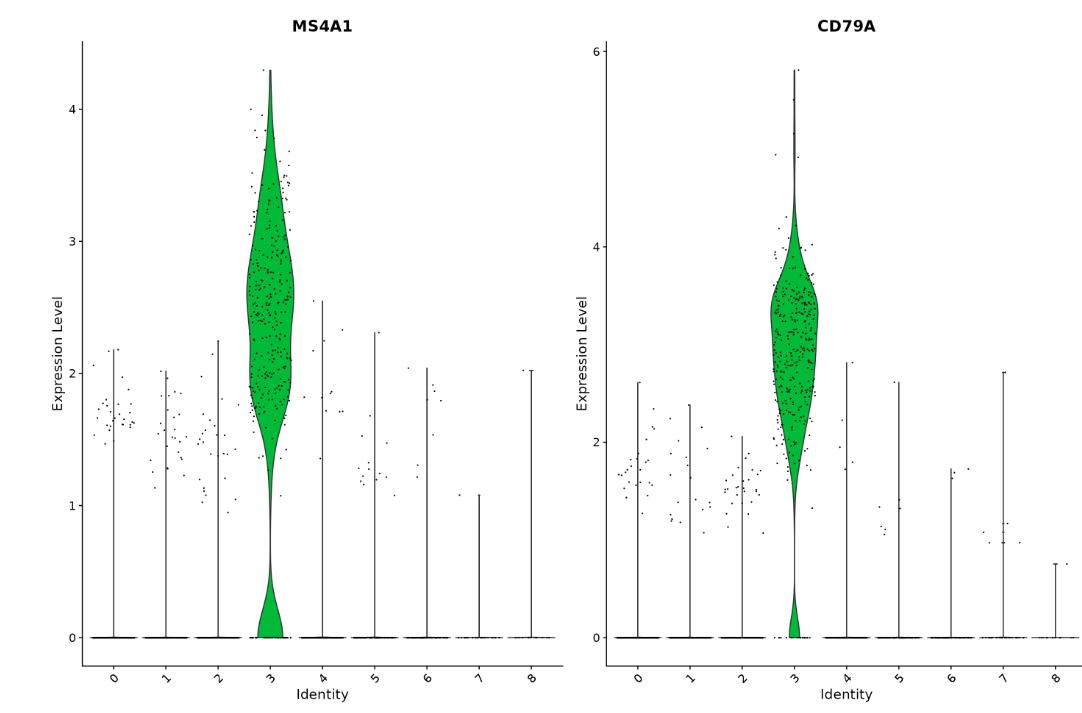
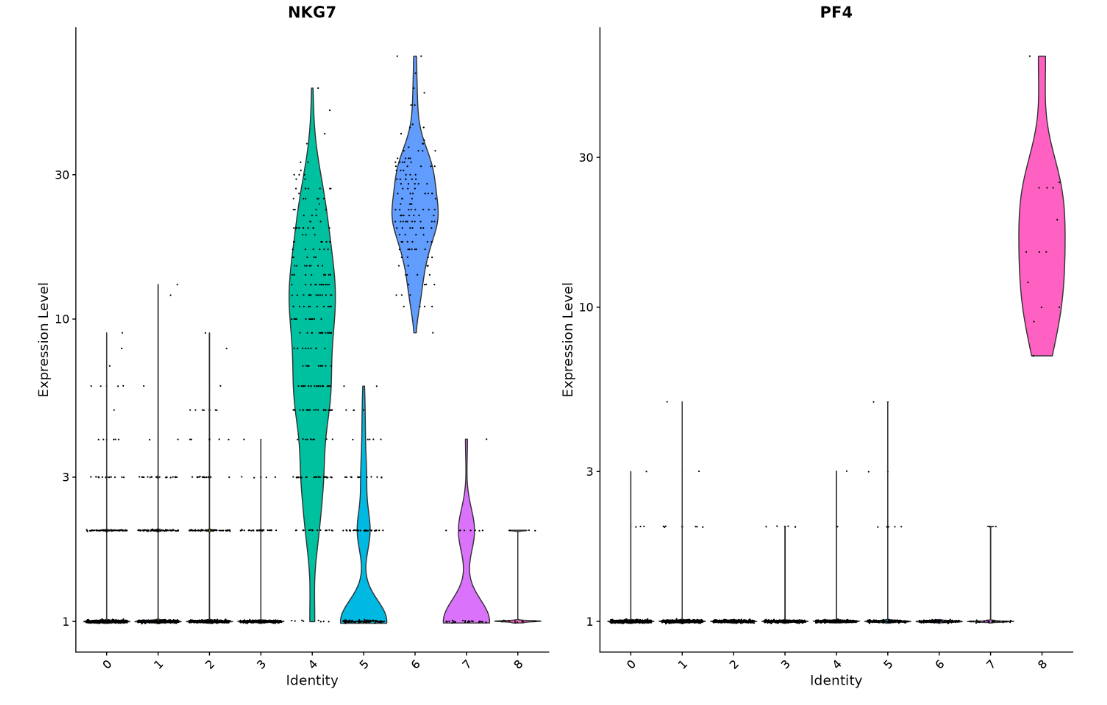
# you can plot raw counts as well
VlnPlot(pbmc, features = c("NKG7", "PF4"), slot = "counts", log = TRUE)
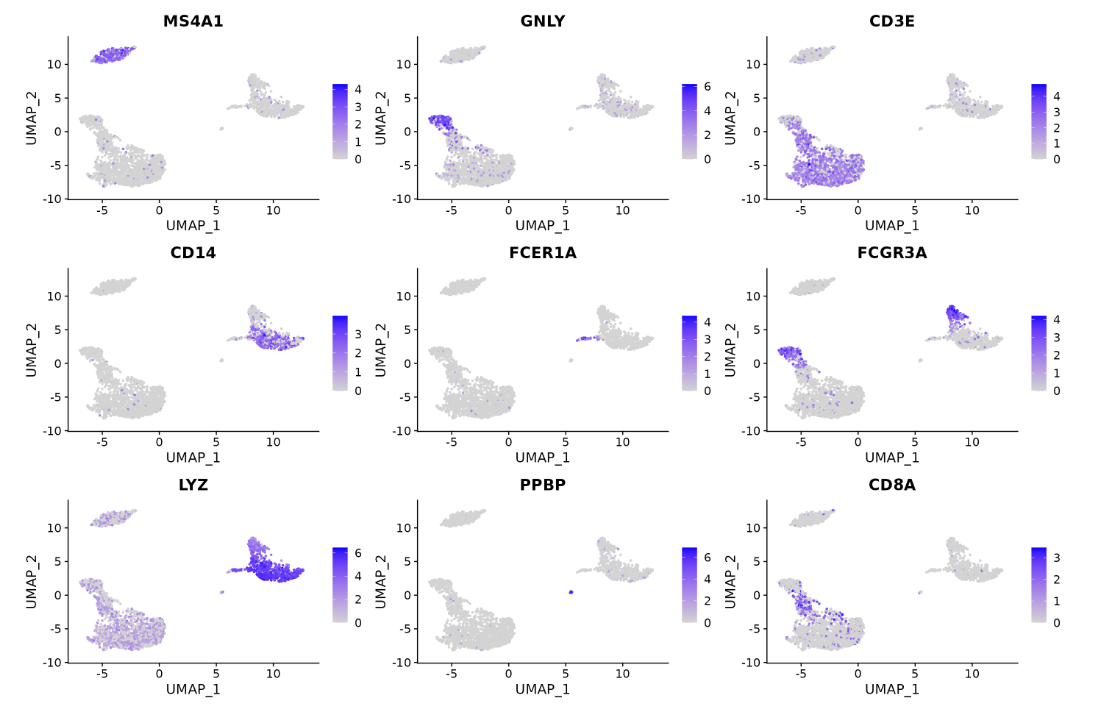
FeaturePlot(pbmc, features = c("MS4A1", "GNLY", "CD3E", "CD14", "FCER1A", "FCGR3A", "LYZ", "PPBP",
"CD8A"))
#每个聚类前10个差异基因表达热图(如果小于10,则绘制所有标记)
top10 <- pbmc.markers %>% group_by(cluster) %>% top_n(n = 10, wt = avg_log2FC)
DoHeatmap(pbmc, features = top10$gene) + NoLegend()
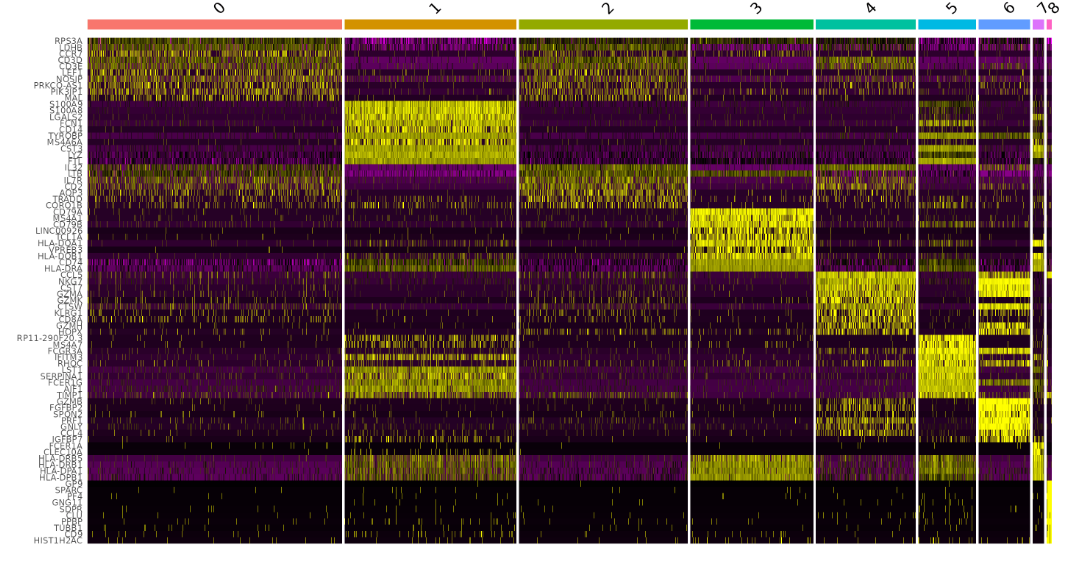
鉴定细胞类型
这个数据集的markers与已知细胞的marker可以轻松配对。也可以通过查阅相关文献人工注释,或者利用singleR(挖个坑,有空再来填)自动注释。
| Cluster ID | Markers | Cell Type |
|---|---|---|
| 0 | IL7R, CCR7 | Naive CD4+ T |
| 1 | CD14, LYZ | CD14+ Mono |
| 2 | IL7R, S100A4 | Memory CD4+ |
| 3 | MS4A1 | B |
| 4 | CD8A | CD8+ T |
| 5 | FCGR3A, MS4A7 | FCGR3A+ Mono |
| 6 | GNLY, NKG7 | NK |
| 7 | FCER1A, CST3 | DC |
| 8 | PPBP | Platelet |
#加上注释
new.cluster.ids <- c("Naive CD4 T", "CD14+ Mono", "Memory CD4 T", "B", "CD8 T", "FCGR3A+ Mono",
"NK", "DC", "Platelet")
names(new.cluster.ids) <- levels(pbmc)
pbmc <- RenameIdents(pbmc, new.cluster.ids)
DimPlot(pbmc, reduction = "umap", label = TRUE, pt.size = 0.5) + NoLegend()
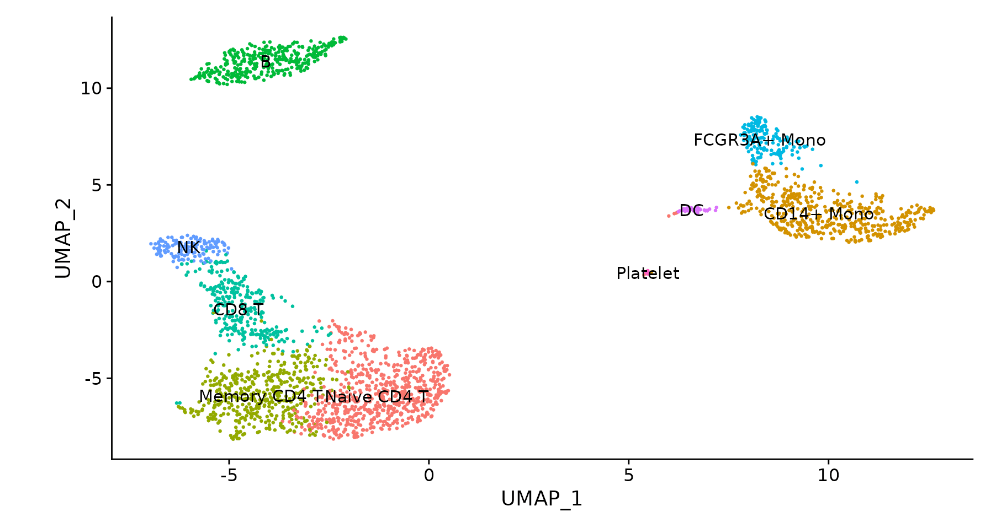
#保存
saveRDS(pbmc, file = "../output/pbmc3k_final.rds")
完整代码及示例数据领取:后台回复seurat领取。
往期内容:

















 381
381

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









