







官方网站: sklearn关于支持向量机多分类的介绍
sklearn.svm中的模型是基于libsvm和liblinear两个包开发出来的。它提供了一系列的支持向量机算法,包括分类(SVC, Support Vector Classifier)、回归(SVR, Support Vector Regressor)和异常检测(Novelty Detection)三类学习算法:
- 分类器:
svm.SVC、svm.LinearSVC和svm.NuSVC - 回归器:
svm.SVR、svm.LinearSVR和svm.NuSVR - 异常检测:
svm.OneClassSVM
二分类
前面提到的三个分类器,LinearSVC特指使用线性核函数的支持向量分类器;NuSVC是基于libsvm的实现;SVC是更一般化和标准的支持向量分类器,它可以设置核函数。
每次分类器都需要使用两个数组作为输入,一个为预测特征 X X X,另一个为目标特征,即标签 y y y。比如:
from sklearn import svm
X = [[-1, 1], [3, 1]]
y = [0, 1]
clf = svm.SVC()
clf.fit(X, y)
SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=3, gamma='auto', kernel='rbf',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
# 拟合得到模型实例后,就可以使用它预测新的样本:
clf.predict([[2, 4]])
array([1])
# 了解模型的具体信息
print clf.support_vectors_ # 支持向量
print clf.support_ # 索引
print clf.n_support_ # 个数
'''
[[-1. 1.]
[ 3. 1.]]
[0 1]
[1 1]
'''
多分类
sklearn.svm的多个分类器主要通过两种策略实现从二分类到多分类的扩展,分别是one-against-one(在sklearn中简写为ovo,即one-vesus-one)和one-against-rest(sklearn中简写为ovr)。
ovo策略是指从多个类别中挑选任意两个类别,然后使用这两个类别的所有数据训练一个二分类器,所以在这种情况下会得到
n
(
n
−
1
)
/
2
n(n-1)/2
n(n−1)/2个二分类器,其中
n
n
n为类别数量,包括“0 vs 1”、“0 vs 2”…“0 vs n”、“1 vs 2”、“1 vs 3”、“1 vs n”…“n-1 vs n”,最后再将多个结果进行聚合。而ovr策略是指用其中一个类别与剩下的类别的所有数据训练一个二分类器,这样将得到
n
n
n个二分类器。
通常情况下,ovr策略的运行时间更少。svm.SVC默认使用ovr的策略,若想要改变为ovo策略,则可以在创建实例时,指定decision_function_shape:
clf = svm.SVC(decision_function_shape="ovo")
classification_report进行分类模型评价
函数参数:
sklearn.metrics.classification_report(y_true, y_pred, *, labels=None, target_names=None, sample_weight=None, digits=2, output_dict=False, zero_division='warn')
官方文档:sklearn.metrics.classification_report — scikit-learn 1.0 documentation
y_true:1维数组,或标签指示器数组/稀疏矩阵,目标值。
y_pred:1维数组,或标签指示器数组/稀疏矩阵,分类器返回的估计值。
labels:array,shape = [n_labels],报表中包含的标签索引的可选列表。
target_names:字符串列表,与标签匹配的可选显示名称(相同顺序)。
sample_weight:类似于shape = [n_samples]的数组,可选项,样本权重。
digits:int,输出浮点值的位数.
返回结果:
包括precision、recall、F值、宏平均macro avg、微平均micro avg;列表左边的一列为分类的标签名,右边support列为每个标签的出现次数
precision recall f1-score support
class 0 0.82 0.90 0.86 107
class 1 0.70 0.55 0.62 47
accuracy 0.79 154
macro avg 0.76 0.73 0.74 154
weighted avg 0.78 0.79 0.78 154
实例
现在,我们提供一份糖尿病患者数据集diabetes.csv,该数据集有768个数据样本,9个特征(最后一列为目标特征数据),并且已经存入变量data。特征的具体信息如下:

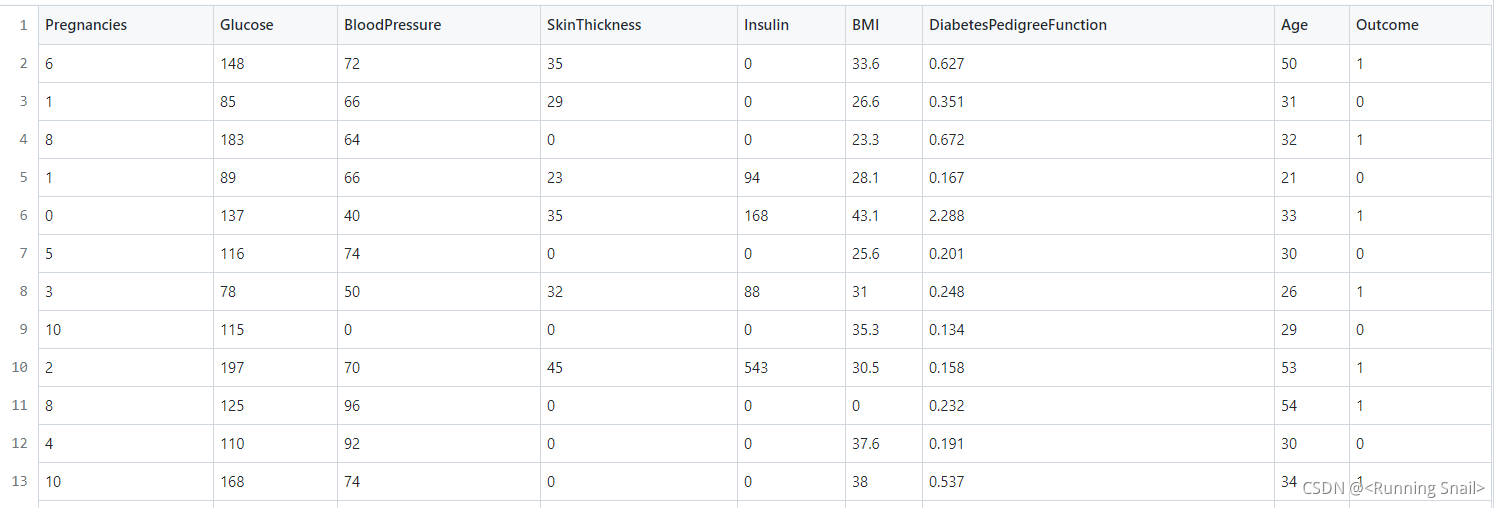
先将数据进行标准化,然后使用sklearn中的svm.SVC支持向量分类器,构建支持向量机模型(所有参数使用默认参数),对测试集进行预测,将预测结果存为pred_y,并对模型进行评价。
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import classification_report
from sklearn.svm import SVC
from sklearn.svm import LinearSVC
# 读取数据
data = pd.read_csv('./data/diabetes.csv')
# 请在下方作答 #
# 将目标特征与其他特征分离
X = data.iloc[:, :-1] # 数据前8列
y = data.iloc[:, -1] # 最后一列
# 划分训练集train_X, train_y和测试集train_X, train_y
train_X, test_X, train_y, test_y = train_test_split(X, y, test_size = .2, random_state = 0)
# 训练集标准化,返回结果为scaled_train_X
scaler = StandardScaler()
scaler.fit(train_X)
scaled_train_X = scaler.transform(train_X)
# 构建支持向量机模型
clf = SVC()
# 模型训练
clf.fit(scaled_train_X, train_y)
# 测试集标准化
scaled_test_X = scaler.transform(test_X)
# 使用模型返回预测值
pred_y = clf.predict(scaled_test_X)
# 打印支持向量的个数,返回结果为列表,[-1标签的支持向量,+1标签的支持向量]
print(clf.n_support_)
# 使用classification_report函数进行模型评价
print('------------------ 原始模型 -------------------------')
print(classification_report(test_y, pred_y))
# 构建惩罚系数为0.3的模型,并与之前的模型做比较
print('----------------- C = 0.3 --------------------------')
clf_new = SVC(C=0.3)
clf_new.fit(scaled_train_X, train_y)
pred_y = clf_new.predict(scaled_test_X)
print(clf_new.n_support_)
print(classification_report(test_y, pred_y))
print('----------------- 线性核函数 --------------------------')
clf_new = SVC(kernel="linear")
clf_new.fit(scaled_train_X, train_y)
pred_y = clf_new.predict(scaled_test_X)
# print(clf_new.n_support_)
print(classification_report(test_y, pred_y))

惩罚系数
惩罚系数C默认为1,与通常作为正则化项的系数如LASSO等模型的做法不同,对于支持向量分类器SVC,参数C代表了经验损失部分的权重,C越小,则正则化的相对程度就越高,C越大,代表我们希望能够更大程度上正确地分类所有训练样本。
在前面的代码设置SVC(C=0.3),模型指标有提升:

添加核函数
几种核函数的参数:
- 线性(
linear) - 径向基函数RBF(
rbf) - 多项式(
polynomial) - Sigmoid(
sigmoid)
比如,在线性情况下,由liblinear实现的LinearSVC通常要比libsvm对应的SVC更为高效
# 以下两种写法是等价的
clf = SVC(kernel="linear")
clf = LinearSVC()


















 3896
3896

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









