









目录

一、 粒子群算法
1.1 概念
1.1.1 粒子群优化算法思想
粒子群优化算法(PSO:Particle swarm optimization) 是一种进化计算技术(evolutionary computation)。源于对鸟群捕食的行为研究。粒子群优化算法的基本思想:是通过群体中个体之间的协作和信息共享来寻找最优解.
PSO的优势:在于简单容易实现并且没有许多参数的调节。目前已被广泛应用于函数优化、神经网络训练、模糊系统控制以及其他遗传算法的应用领域。粒子群算法思想来源于实际生活中鸟捕食的过程。假设在一个n维的空间中,有一群鸟(m只)在捕食,食物位于n维空间的某个点上,对于第i只鸟某一时刻来说,有两个向量描述,一个是鸟的位置向量,第二个是鸟的速度。假设鸟能够判断一个位置的好坏,所谓“好坏”,就是离食物更近了还是更远了。鸟在捕食的过程中会根据自己的经验以及鸟群中的其他鸟的位置决定自己的速度,根据当前的位置和速度,可以得到下一刻的位置,这样每只鸟通过向自己和鸟群学习不断的更新自己的速度位置,最终找到食物,或者离食物足够近的点。
粒子群是比较经典的有自适应过程的算法,类似的有蝙蝠算法、布谷鸟算法、蜂群算法等,某个粒子的移动会参考历史最优和当前最优,可以通过设置c1、c2表示两者的重要程度,每个粒子移动的速度也是不一样的,速度也会收到w的影响,以上三者共同决定粒子下一步到达的位置。
1.1.2 更新规则
PSO初始化为一群随机粒子(随机解)。然后通过迭代找到最优解。在每一次的迭代中,粒子通过跟踪两个“极值”(pbest,gbest)来更新自己。在找到这两个最优值后,粒子通过下面的公式来更新自己的速度和位置。
其中:f为当前适应度函数的平均值;v为粒子速度;x为粒子位置;rand()为介于(0,1)之间的随机数;c1、c2是学习因子,通常c1=c2=2;best为当前最优解;bestx为历史最优解。
公式(1)的第一部分称为【记忆项】,表示上次速度大小和方向的影响;公式(1)的第二部分称为【自身认知项】,是从当前点指向粒子自身最好点的一个矢量,表示粒子的动作来源于自己经验的部分;公式(1)的第三部分称为【群体认知项】,是一个从当前点指向种群最好点的矢量,反映了粒子间的协同合作和知识共享。粒子就是通过自己的经验和同伴中最好的经验来决定下一步的运动。以上面两个公式为基础,形成了PSO的标准形式。
公式(2)和 公式(3)被视为标准PSO算法



1.1.3 惩罚项
惩罚项。它的思想类似线性规划内点法,都是通过增加罚函数,迫使模型在迭代计算的过程中始终在可行域内寻优。
在粒子群算法中,每一步迭代都会更新 Pbest 和 Gbest,虽然可以将有约束问题转换为无约束问题进行迭代求解,但是问题的解 xi依然存在不满足约束条件的情况,因此需要编制一些规则来比较两
个粒子的优劣,规则如下:
1.如果两个粒子 xi 和 xj 都可行,则比较其适应度函数 f(xi)和f(xj),值小的粒子为优。
2.当两个粒子 xi 和 xj 都不可行,则比较惩罚项 P(xi)和 P(xj), 违背约束程度小的粒子更优。
3.当粒子 xi 可行而粒子 xj 不可行,选可行解。对于粒子的上下限约束 可以体现在位置更新函数里,不必加惩 罚项。 具体思路就是遍历每一个粒子的位置,如果超除上下限,位置则更改为上下限中的任何一个位置
1.2 程序框图

二、投资组合优化
上一次:
三、Matlab实现
3.1 结果及可视化
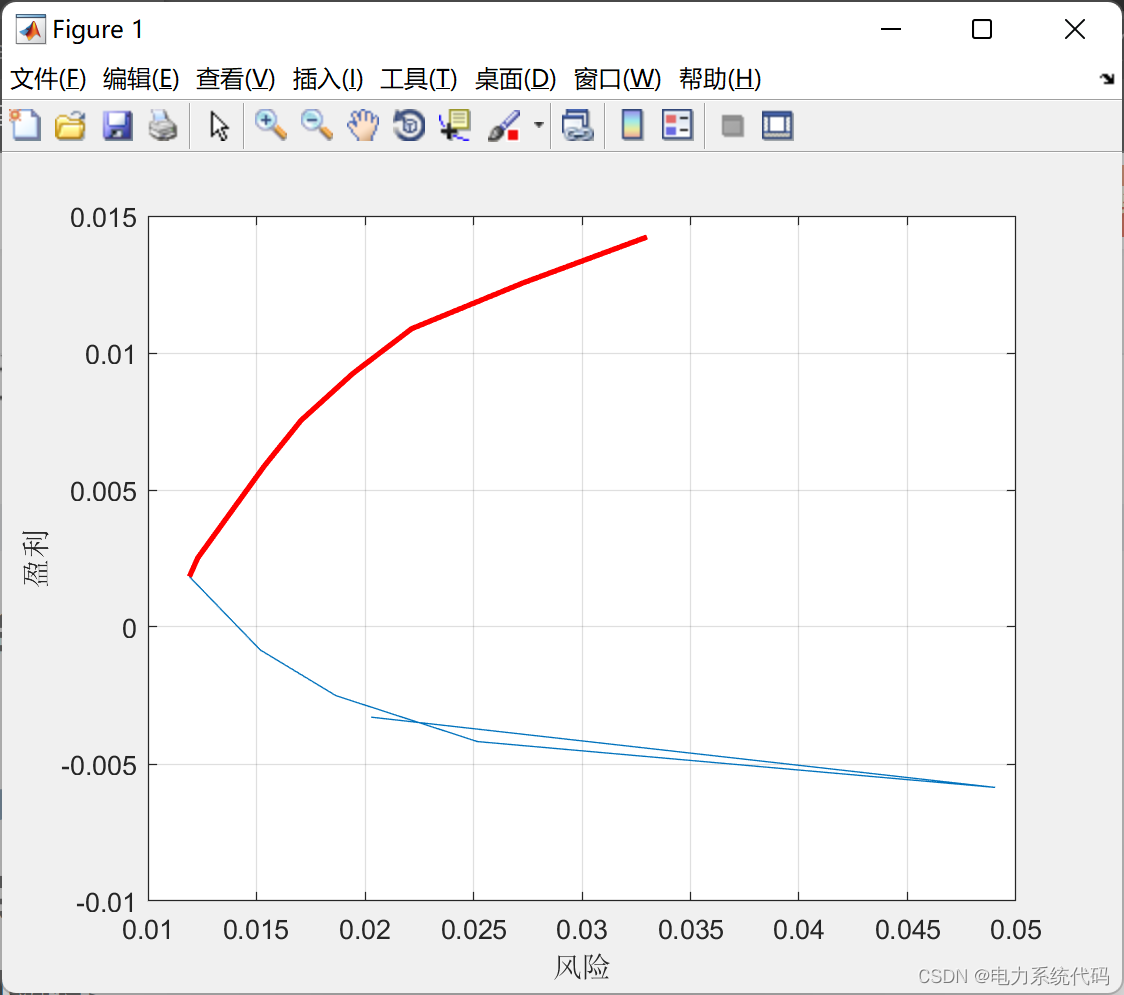
3.2 Matlab代码
部分代码:
function out = RunPSO(model)
%% 目标函数
CostFunction=@(x) PortCost(x,model); % 目标函数
nVar=size(model.R,2); % 决策变量个数
VarSize=[1 nVar]; %决策变量矩阵的大小
VarMin=0; % 决策变量下限
VarMax=1; % 决策变量上限
%% 粒子群参数
MaxIt=100; % 最大迭代次数
nPop=40; % 种群数量
% w=1; % 惯性权重
% wdamp=0.99; % 惯性重量阻尼比
% c1=2; % 个体学习系数
% c2=2; % 全局学习系数
%% 约束系数
phi1=2.05;
phi2=2.05;
phi=phi1+phi2;
chi=2/(phi-2+sqrt(phi^2-4*phi));
w=chi; % 惯性权重
wdamp=1; % 惯性重量阻尼比
c1=chi*phi1; % 个体学习系数
c2=chi*phi2; % 全局学习系数
%% 速度
VelMax=0.1*(VarMax-VarMin);
VelMin=-VelMax;
%% 初始化
empty_particle.Position=[];
empty_particle.Cost=[];
empty_particle.Out=[];
empty_particle.Velocity=[];
empty_particle.Best.Position=[];
empty_particle.Best.Cost=[];
empty_particle.Best.Out=[];
particle=repmat(empty_particle,nPop,1);
BestSol.Cost=inf;
for i=1:nPop
%=====初始化位置=========
particle(i).Position=unifrnd(VarMin,VarMax,VarSize);
%=====初始化速度======
particle(i).Velocity=zeros(VarSize);
%=====评价========
[particle(i).Cost, particle(i).Out]=CostFunction(particle(i).Position);
%====更新个体最优=====
particle(i).Best.Position=particle(i).Position;
particle(i).Best.Cost=particle(i).Cost;
particle(i).Best.Out=particle(i).Out;
%====更新全局最优=====
if particle(i).Best.Cost<BestSol.Cost
BestSol=particle(i).Best;
end
end
BestCost=zeros(MaxIt,1);
%% PSO主循环
for it=1:MaxIt
for i=1:nPop
%====更新速度=========
particle(i).Velocity = w*particle(i).Velocity ...
+c1*rand(VarSize).*(particle(i).Best.Position-particle(i).Position) ...
+c2*rand(VarSize).*(BestSol.Position-particle(i).Position);
%===速度限制=====
particle(i).Velocity = max(particle(i).Velocity,VelMin);
particle(i).Velocity = min(particle(i).Velocity,VelMax);
%===更新位置====
particle(i).Position = particle(i).Position + particle(i).Velocity;
IsOutside=(particle(i).Position<VarMin | particle(i).Position>VarMax);
particle(i).Velocity(IsOutside)=-particle(i).Velocity(IsOutside);
%===位置限制=====
particle(i).Position = max(particle(i).Position,VarMin);
particle(i).Position = min(particle(i).Position,VarMax);
%===评估=======
[particle(i).Cost, particle(i).Out] = CostFunction(particle(i).Position);
%====更新个体最优=====
if particle(i).Cost<particle(i).Best.Cost
particle(i).Best.Position=particle(i).Position;
particle(i).Best.Cost=particle(i).Cost;
particle(i).Best.Out=particle(i).Out;
%====更新全局最优=====
if particle(i).Best.Cost<BestSol.Cost
BestSol=particle(i).Best;
end
end
end
BestCost(it)=BestSol.Cost;
disp(['Iteration ' num2str(it) ': Best Cost = ' num2str(BestCost(it))]);
w=w*wdamp;
end
%% Export Results
out.BestSol=BestSol;
out.BestCost=BestCost;
end
















 602
602











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











