







👨🎓个人主页:研学社的博客
💥💥💞💞欢迎来到本博客❤️❤️💥💥
🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
📋📋📋本文目录如下:🎁🎁🎁
目录

💥1 概述
轨迹或路径规划是各种应用中的基本问题。在本文中,我们展示了通过仅使用加权池操作的多层网络的新配置,可以高效地解决多个起点和终点的迷宫路径规划,而无需网络训练。这些网络创建的解决方案与广度优先搜索 (BFS)、Dijkstra 算法或 TD(0) 等经典算法的解决方案相同。与竞争方法不同,包含近十亿个节点的超大型迷宫具有密集的障碍物配置和数千个重要性加权路径端点,可以在并行硬件上的一次通过中快速解决。
原文摘要:
Abstract:
Trajectory or path planning is a fundamental issue in a wide variety of applications. In this article, we show that it is possible to solve path planning on a maze for multiple start point and endpoint highly efficiently with a novel configuration of multilayer networks that use only weighted pooling operations, for which no network training is needed. These networks create solutions, which are identical to those from classical algorithms such as breadth-first search (BFS), Dijkstra’s algorithm, or TD(0). Different from competing approaches, very large mazes containing almost one billion nodes with dense obstacle configuration and several thousand importance-weighted path endpoints can this way be solved quickly in a single pass on parallel hardware.
路径规划是一个普遍存在的问题,例如,在优化交通流模式的交通控制或游戏行业中。路径规划问题的最佳例子可能是机器人技术。例如,考虑移动机器人的问题,该机器人必须在建筑物内从起点导航到目标位置。这样做需要机器避开它找到门口的墙壁和障碍物,并且不会从楼上掉下来。路径或运动规划的目标是将这些约束编码在某种适当的表示框架中,并将其用作路径规划算法的输入,为机器人生成命令,以创建从起点到终点的无差错运动轨迹。如果输入信息不完整,或者有多个代理(机器人)应该找到每个代理(机器人)到离它们最近的目标的最短路径(多源-多目标问题),情况可能会变得更加复杂。其中许多问题可以通过在基于格网的地图制图表达上查找路径来解决,其中路径约束(例如障碍物)表示为禁止的格网点。其他更通用的算法使用(加权)图作为表示框架,自1950年左右以来已经做了大量工作来解决这类问题。
最常见的经典路径规划方法是广度优先搜索(BFS)[1],[2]以及Dijkstra[3]和Bellman-Ford[4],[5]算法。这些算法在图和基于网格的结构上表现良好,可以解决所谓的单源最短路径(SSSP)问题;但是,它们不能随着尺寸的增加而很好地扩展(例如,nD 空间n>2 ) 和路径长度。
存在一些启发式的、面向目标的搜索算法,如贪婪BFS(Greedy-BFS,[6],[7])、A*算法[8]及其变体(见[9]-[12]),它们比上述算法更快,但是,它们只能找到单源单目标路径查找问题的解决方案。此外,贪婪BFS并不总是能找到最佳解决方案。
另一类常见的方法,特别是在机器人技术中,是基于采样的方法,例如快速探索随机树(RRT)算法(见[13]),它是变体(见[14]-[16])。基于RRT的方法非常适合连续空间,但是,与Dijkstra或A * [17],[18]相比,这些方法在网格或迷宫等复杂环境中表现不佳[<>],[<>]。此外,基于RRT的方法发现的路径通常不是最优的,并且随着样本数量的增长到无穷大,它们只会渐近收敛到最优解。此外,这些方法需要参数调整才能获得最佳性能,而上面讨论的经典和启发式搜索算法是无参数方法。
第三类算法基于人工神经网络。一些早期的方法试图使用Hopfield网络[19],[20]在图中执行最短路径搜索,然而,这些方法只能解决相对较小的图(低于100个节点),并且解决方案并不总是最佳的,或者网络甚至无法找到解决方案,特别是如果图越来越大。后来,提出了其他在网格结构上工作的仿生神经网络[21]-[26]。在这些方法中,环境由具有抑制(表示障碍物)和兴奋性(表示自由空间)神经元的网络表示,这些神经元在网格上拓扑排列。网络中的活动从源神经元传播到相邻细胞,依此类推。在整个网络中的活动传播完成后,通过以下活动梯度重建路径。这些方法的缺点是它们仅适用于小规模环境(例如,尺寸小于1000×1000 元 ),因为网络中的活动很快就会衰减到零(见[24],[26])。 其他一些方法首先学习环境表示,然后使用强化学习找到解决方案(参见[27],[28])。 这些方法不能在某些距离度量方面提供最佳解决方案,而是提供从源到目的地的近似路径。
最近,深度学习方法也利用了深度多层感知器(DMLP;见[29]),深度强化学习方法[28],[30],[31],全卷积网络[32]-[34],长短期记忆(LSTM)网络[18]和图神经网络[35]。 也被提议用于解决寻路问题。但是,这些方法需要学习,因此需要大量的训练数据。此外,这些方法并不总是返回最佳解决方案,并且在相当一部分情况下,它们甚至不能保证会找到解决方案(例如,在与用于训练模型的情况完全不同的情况下)。
解决许多应用程序的路径查找问题的常规方法是首先创建一个梯度字段,用于捕获基础环境的拓扑,包括一个或多个路径的起点和端点。实现这一点后,就可以按照该字段中的一些所需指标(例如,曼哈顿或八进制)计算最佳路径。上面讨论的一些算法(例如,生物启发网络[24]-[26])遵循这种方法,也可以使用一些经典方法,例如BFS [1],[2],Dijkstra算法[3],它们的现代变体[36]-[38],或强化学习方法,如TD学习[39]。.这样做的一个核心优点是,多源多目标路径查找问题可以直接通过这种方式解决。
最近,在[40]中提出了一种新的非常强大的并行方法,该方法也不需要学习。这种方法可以为多个加权源生成欧几里得最优图,本研究的作者在相当详尽的比较中表明,它优于许多其他并行(基于 GPU)的方法 [2]、[41]-[44]。
📚2 运行结果
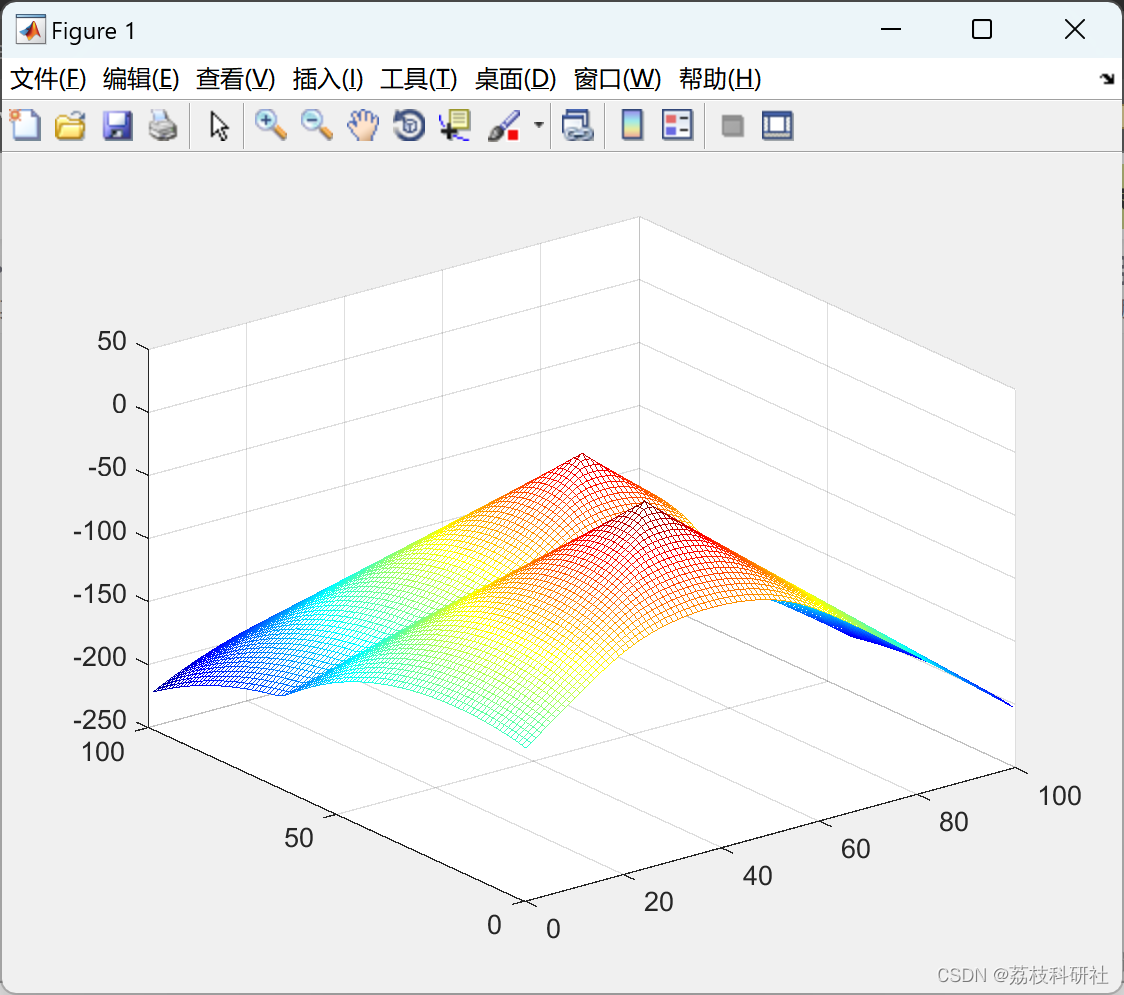
2.1 dijkstra
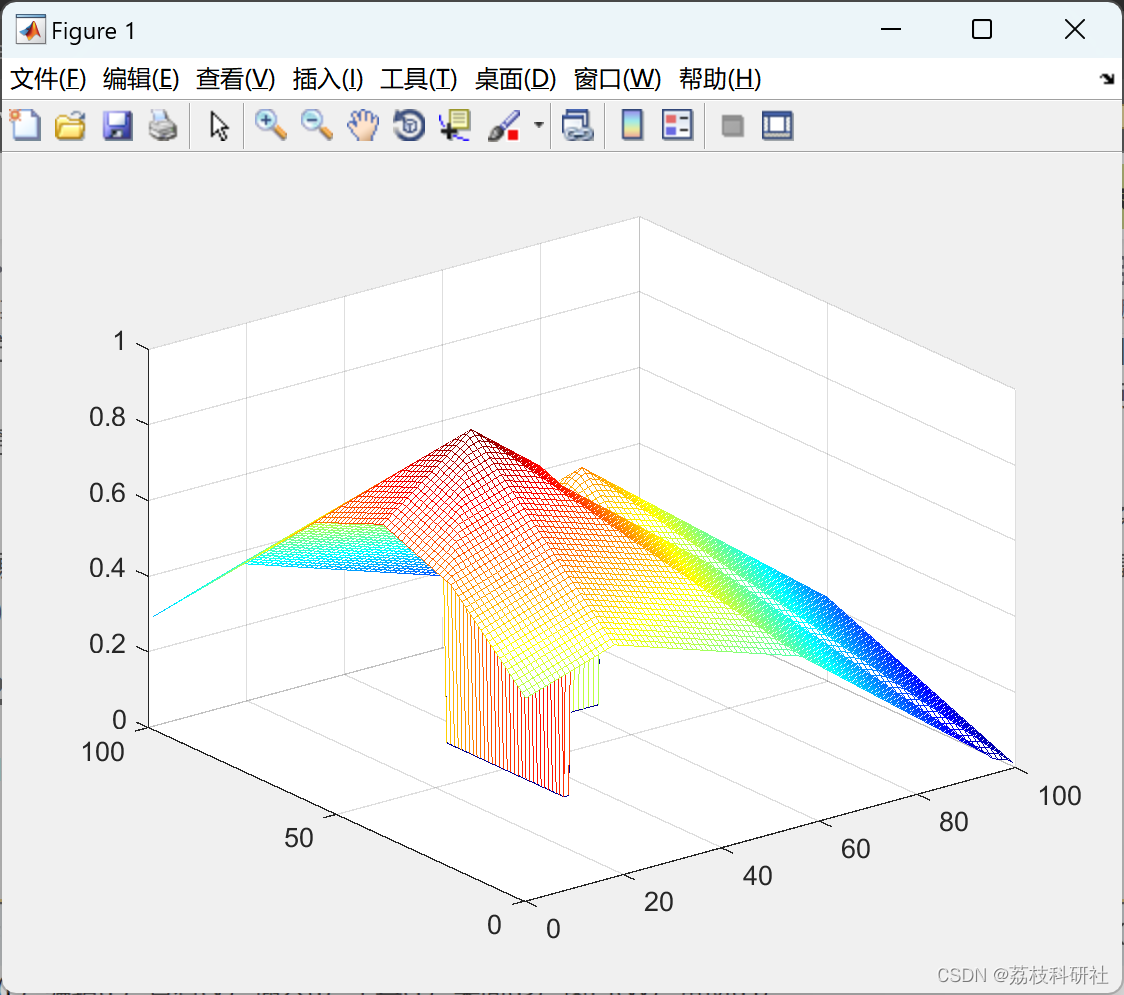
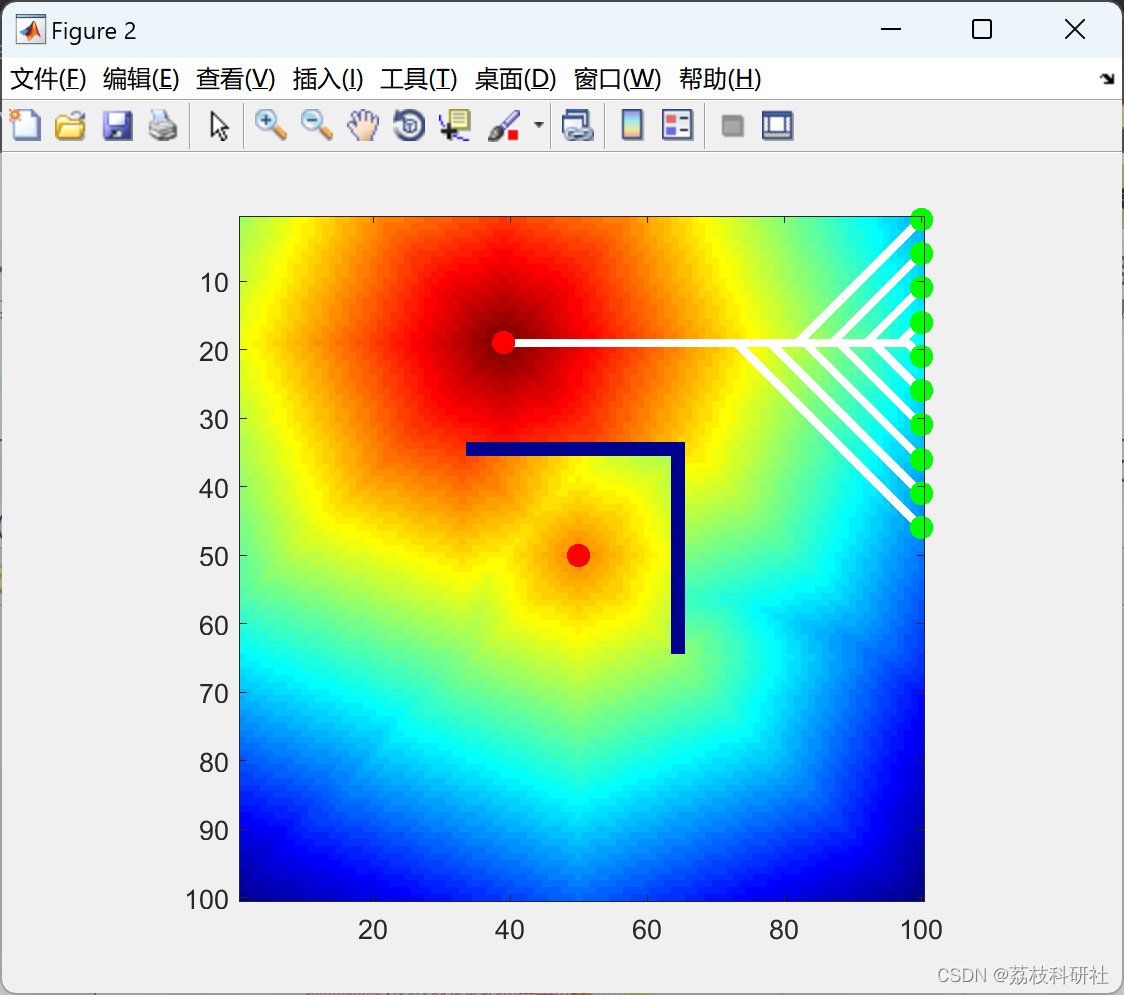
2.2 t_pool_dijkstra

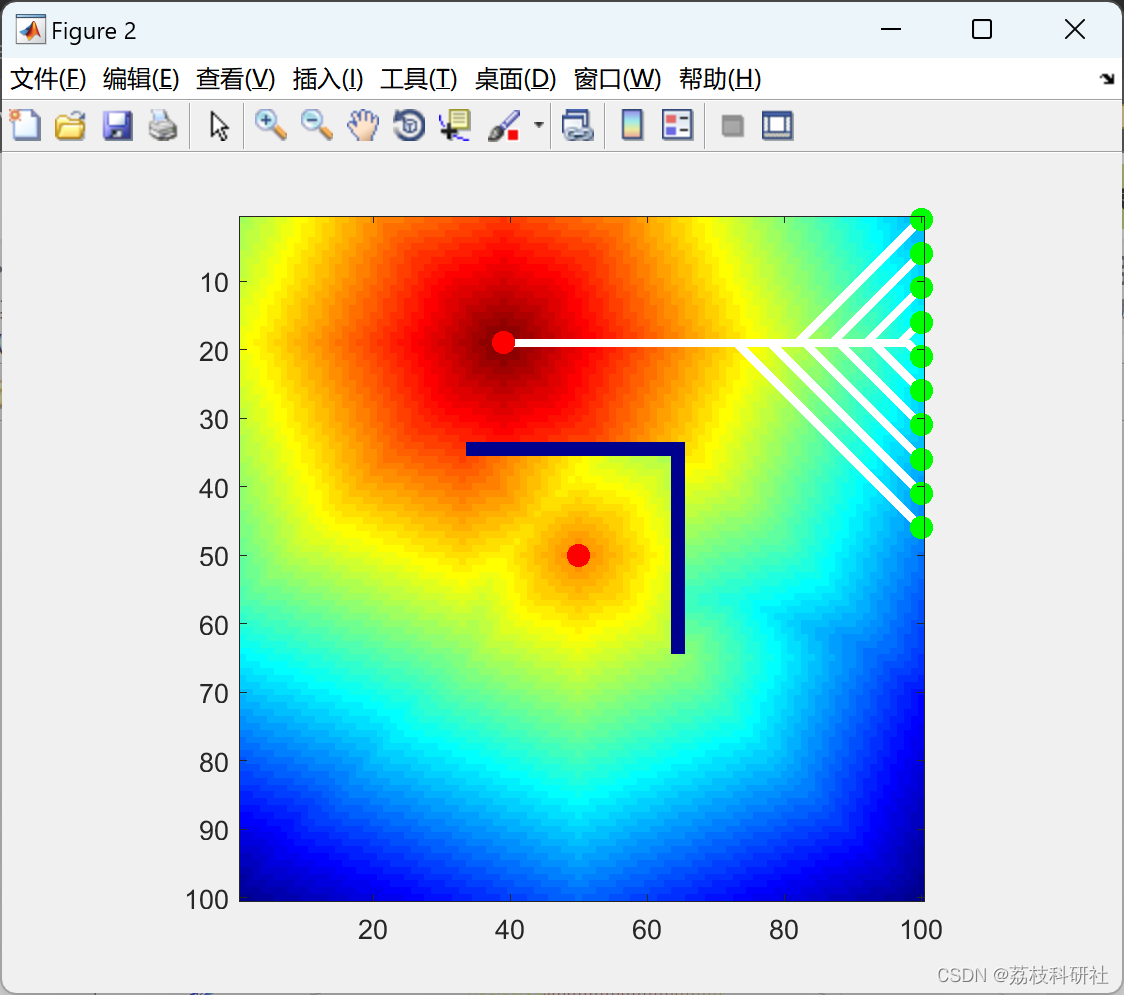
2.3 t_pool_ap_net
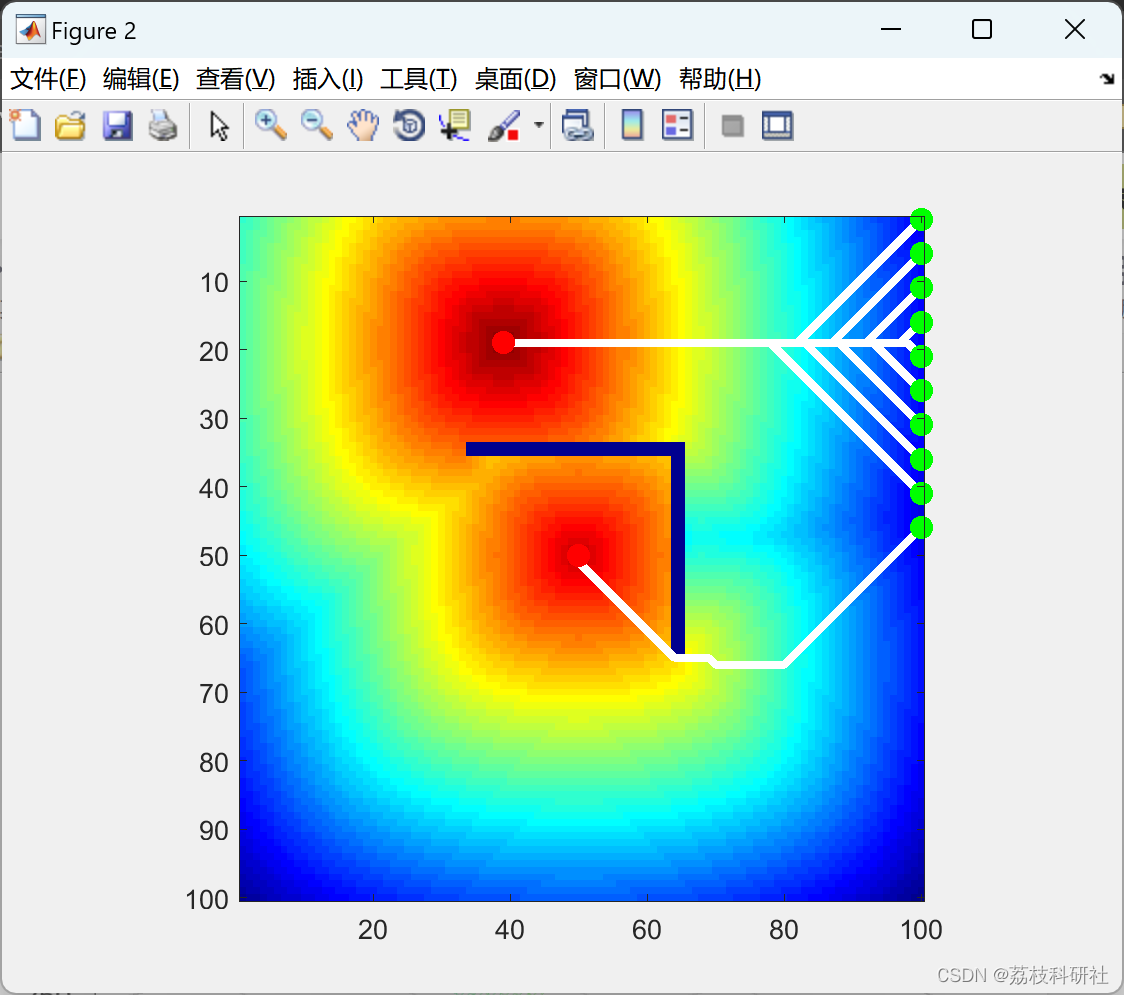
运行结果比较多,其他部分就不一一展示。
x=zeros(n,n); %activity map
x_src=zeros(n,n); %source map
x_env=zeros(n,n); %environment map
%weights for multiplicative average pooling
f=[1/sqrt(2) 1 1/sqrt(2); 1 0 1; 1/sqrt(2) 1 1/sqrt(2)]; %BioNet
f=f./sum(f(:)); %normalise
sx=round(n/2); sy=round(n/2); gx=1; gy=n;
sx(2)=20-1; sy(2)=40-1;
%environment
env=zeros(n,n);
%set obstacles (comment out for no obstacles)
env(34:35,34:64)=1;
env(34:64,64:65)=1;
%generate source map
for i=1:length(sx)
x_src(sx(i),sy(i))=1;
end;
%weigh one source more than the other (comment out for unweighted sources)
x_src(sx(1),sy(1))=0.0000001;
% x_src(sx(2),sy(2))=0.0000001;
%generate environment map
x_env = -nL*env;
%add maps
x_env_src = x_env + x_src;
%initialise activity map
x = x_src;
disp('Starting T-POOL-AP-Net ...')
t0=clock;
for t=1:nL
if mod(t,10)==0
disp([num2str(t) '/' num2str(nL)])
end
%%%weighted average pooling
x=weighted_avg_pooling(x,f); %BioNet
%%%adding obstacles and sources
x = x + x_env_src;
%%%ReLu
x(x<0) = 0; %use this for oMAP and BioNet
end
search_time=etime(clock,t0)
figure
colormap jet
%we use log scale
mesh(log(x))
figure
%we use log scale
imagesc(log(x))
colormap jet
axis square
% axis off
grid off
for k=1:5:50+1
[px,py]=rec_path_octile(x,gx,gy);
path_length=sum(sqrt(diff(px).^2+diff(py).^2));
path_steps=length(px);
hold on
plot(py,px,'w','linewidth',3)
plot(sy,sx,'r.','markersize',30)
plot(gy,gx,'g.','markersize',30)
gx=k;
end
🎉3 文献来源
部分理论来源于网络,如有侵权请联系删除。
[1]Tomas Kulvicius, Sebastian Herzog, Minija Tamosiunaite, Florentin Wörgötter (2021) Finding Optimal Paths Using Networks Without Learning
















 1131
1131











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











