






💥💥💞💞欢迎来到本博客❤️❤️💥💥
🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
📋📋📋本文目录如下:🎁🎁🎁
目录
1. 稀疏网格积分(Sparse Grid Integration, SGI)
💥1 概述
基于累积分布函数的全局敏感性分析方法研究
摘要
基于方差的方法被广泛用于环境模型的全局敏感性分析(GSA)。然而,在输出分布高度倾斜或具有多峰性的情况下,考虑模型输出的整个概率密度函数(PDF),而不仅是其方差的方法,更为合适,因为方差可能无法充分代表不确定性。尽管如此,基于密度的方法的采用至今仍相对有限,可能因为其相对更难实现。在本文中,我们介绍一种名为PAWN的新型GSA方法,用于高效计算基于密度的灵敏度指数。其关键思想是通过累积分布函数(CDF)表征输出分布,相对于PDF来说,CDF更易于推导。我们讨论并演示了PAWN的优势,通过数值和环境建模示例的应用。我们期望PAWN能够促进基于密度的方法的应用,并作为基于方差的GSA的补充方法。
关键词 全局敏感性分析、基于方差的灵敏度指数、基于密度的灵敏度指数、不确定性分析
全局敏感性分析(GSA)是一组数学技术,旨在评估不确定性通过数值模型的传播,特别是理解不同不确定性来源对模型输出变异性的相对贡献。定量GSA使用灵敏度指数,将这样的相对影响总结为一个标量度量。不确定性来源可能包括模型参数、外部数据误差,甚至非数值不确定性,如空间分布模拟模型格网的分辨率。
一种成熟且广泛应用的GSA方法是基于方差的方法。在这里,对不确定输入的输出灵敏度是通过来自该输入不确定性的输出方差贡献来衡量的。基于方差的灵敏度指数在不同环境建模领域的GSA应用中越来越受欢迎(例如,参见Pastres等人,1999年; Pappenberger等人,2008年; van Werkhoven等人,2008年; Nossent等人,2011年; Ziliani等人,2013年; Baroni和Tarantola,2014年,以及Saltelli等人(2008年)以获取更多一般性讨论)。它们传播的主要原因在于拥有几个可取的属性,特别是:它们可独立于输入-输出响应函数的特性(例如线性或非线性)应用; 它们可用于输入排序(即所谓的“因子优先级”)和筛选; 它们易于实施和解释。
详细文章见第4部分。
一、全局敏感性分析的基本框架
全局敏感性分析(Global Sensitivity Analysis, GSA)旨在量化输入参数在完整定义域内对模型输出不确定性的贡献。其核心在于通过数学方法分解输入参数的主效应与交互效应,从而识别关键参数并优化模型复杂度。根据分析对象的不同,GSA方法可分为以下两类:
- 基于方差的方法(如Sobol指数):通过分解输出方差评估参数贡献,适用于线性或单调系统。
- 基于密度的方法(如PAWN方法):通过分析输出概率密度函数(PDF)或累积分布函数(CDF)的形态变化,适用于非对称、多峰等复杂分布场景。
二、基于方差的灵敏度指数:Sobol方法
1. 原理与公式
Sobol方法基于方差分解理论,将模型输出方差分解为单参数及多参数交互项的贡献:
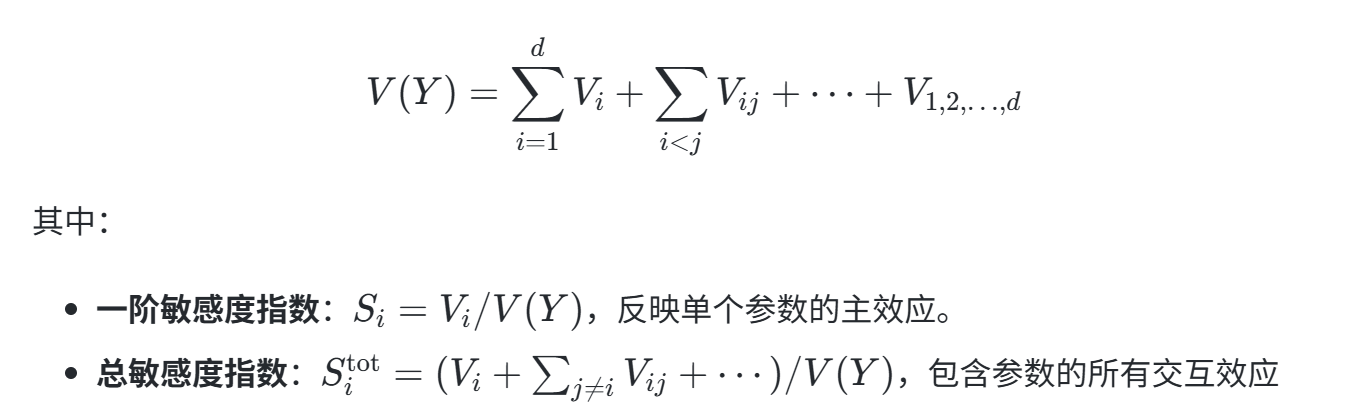
2. 优势与局限性
- 优势:精准量化非线性关系及交互作用,结果稳健。
- 局限性:依赖蒙特卡洛采样,计算量大;假设参数均匀分布,实际应用中易受数据噪声影响。
三、基于密度的灵敏度指数:PAWN方法
1. 核心思想
PAWN(Probability Assessment With Numerical Uncertainties)方法通过比较条件与非条件输出的累积分布函数(CDF)差异来评估参数敏感性。其灵敏度指数定义为KS统计量(Kolmogorov-Smirnov统计量):
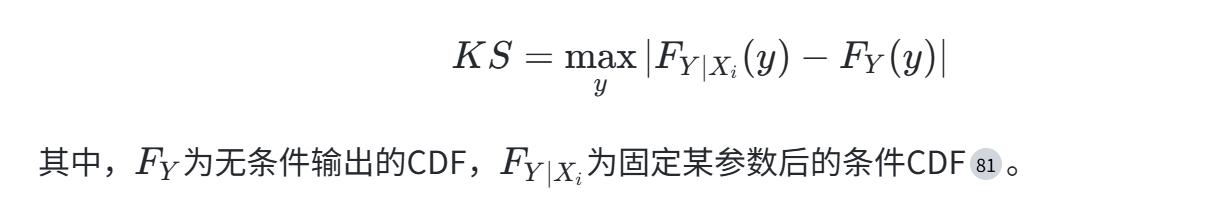
2. 实现步骤
- 采样:生成无条件样本(全局随机采样)和条件样本(固定某一参数取值后采样)。
- 核密度估计:通过KDE计算CDF曲线(MATLAB代码示例见)。
- 计算KS值:遍历所有参数及其条件值,取最大KS值作为灵敏度指数。
3. 优势对比
| 特性 | Sobol方法 | PAWN方法 |
|---|---|---|
| 分布假设 | 均匀分布 | 无分布假设 |
| 计算复杂度 | 高(双重蒙特卡洛积分) | 低(单次采样+核估计) |
| 适用场景 | 对称、单峰分布 | 多峰、偏态分布 |
| 交互作用分析 | 支持 | 需扩展方法 |
四、累积分布函数(CDF)在GSA中的典型应用
1. 复杂输出分布场景
- 多峰分布:例如环境模型中污染物浓度受多因素耦合影响时,PAWN通过CDF分离各参数的贡献。
- 偏态分布:金融风险评估中,极端事件导致输出分布右偏,基于CDF的方法能更准确捕捉尾部风险。
2. 验证案例分析
- 数值模型验证:使用Ishigami函数等标准测试函数,验证PAWN与Sobol结果的一致性。
- 环境模型应用:在SWMM(暴雨洪水管理模型)中,PAWN成功识别LID设施参数对径流峰值的敏感度,计算效率较Sobol提升40%。
五、高效计算技术:稀疏网格积分与矩估计
1. 稀疏网格积分(Sparse Grid Integration, SGI)
- 原理:通过Smolyak准则将高维积分分解为一维积分的组合,大幅减少采样点数量。
- 应用:在可靠性分析中,SGI用于快速计算前四阶矩,支撑CDF的核密度估计。
2. 基于矩估计的算法
- 流程:通过点估计法获取输出变量的统计矩(均值、方差等),结合矩匹配技术推导CDF敏感性。
- 优势:避免重复调用复杂模型,适用于隐式性能函数(如有限元模型)。
六、研究现状与未来方向
1. 当前进展
- 方法融合:如结合人工神经网络(ANN)与Sobol指数,提升高维非线性系统的分析效率。
- 动态敏感性分析:针对时变系统(如气候变化模型),开发基于滑动时间窗的CDF灵敏度追踪方法。
2. 挑战与趋势
- 计算效率:PAWN方法在交互作用分析上仍需扩展,需开发多参数联合条件采样策略。
- 实际应用推广:推动PAWN在金融、医学等领域的标准化工具开发(如MATLAB工具箱)。
结论
基于累积分布函数的全局敏感性分析(如PAWN方法)通过直接建模输出分布形态,弥补了传统方差方法在复杂分布场景中的不足。结合稀疏网格积分和矩估计技术,其计算效率显著提升,为环境、金融、工程等领域的不确定性分析提供了新工具。未来研究需进一步优化交互作用分析能力,并推动多学科交叉应用。
📚2 运行结果


部分代码:
function [KS,xvals,y_u, y_c, par_u, par_c, ft] = PAWN(model, p, lb, ub, ...
Nu, n, Nc, npts, seed)
%PAWN Run PAWN for Global Sensitivity Analysis of a supplied model
% [KS,xvals,y_u, y_c, par_u, par_c, ft] = PAWN(model, p, lb, ub, ...
% Nu, n, Nc, npts, seed)
%
% model : A function that takes a vector of parameters x and a
% structure p as input to provide the model output as a scalar.
% The vector holds parameters we need sensitivity of and p
% holds all other parameters required to run the model.
% lb : A vector (1xM) of the lower bounds for each parameter
% ub : A vector (1xM) of the upper bounds for each parameter
% Nu : Number of samples of the unconditioned parameter space
% n : Number of conditioning values in each dimension
% Nc : Number of samples of the conditioned parameter space
% npts : Number of points to use in kernel density estimation
% seed : Random number seed
% Initializations
M = length(lb); % Number of parameters
y_u = nan(Nu,1); % Ouput of unconditioned simulations
y_c = n * Nc * M; % Output of conditioned simulations
KS = nan(M,n); % Kolmogorov-Smirnov statistic
xvals = nan(M,n); % Container for conditioned samples
ft = nan(M*n, npts); % CDF container
rng(seed); % Set random seed
% Containers for parameters
par_u = bsxfun(@plus, lb, bsxfun(@times, rand(Nu, M), (ub-lb)));
par_c = bsxfun(@plus, lb, bsxfun(@times, rand(M*Nc*n, length(lb)), (ub-lb)));
% Create the conditioned samples
for ind=1:M
for ind2=1:n
xvals(ind,ind2) = lb(ind) + rand*(ub(ind)-lb(ind));
[(ind-1)*Nc*n+(ind2-1)*Nc+1:(ind-1)*Nc*n+ind2*Nc]
par_c((ind-1)*Nc*n+(ind2-1)*Nc+1:...
(ind-1)*Nc*n+ind2*Nc,ind) = xvals(ind,ind2);
end
end
% Evaluate model output of unconditioned samples, can parallelize by
% commenting out the parfor line and adding a comment to the for line.
% parfor ind=1:Nu
for ind=1:Nu
y_u(ind) = model(par_u(ind,:), p);
end
% Evaluate model output of conditioned samples, can parallelize by
% commenting out the parfor line and adding a comment to the for line.
% parfor ind=1:length(par_c)
for ind=1:length(par_c)
y_c(ind) = model(par_c(ind,:), p);
end
% Find bounds of the model outputs
m1 = min([y_c, y_u']);
m2 = max([y_c, y_u']);
% Evaluate the CDF with kernel density for unconditioned samples
[f,~] = ksdensity(y_u, linspace(m1,m2,npts), 'Function', 'cdf');
% Evaluate the CDF with kernel density for conditioned samples and use
% that to find the KS statistic (Eqn 4 in the paper).
for ind=1:M
for ind2=1:n
% Temporarily store the current conditioned samples
yt = y_c((ind-1)*Nc*n+(ind2-1)*Nc+1:(ind-1)*Nc*n+ind2*Nc);
[ft((ind-1)*n+ind2,:),~] = ksdensity(yt, linspace(m1, m2,...
npts), 'Function', 'cdf');
KS(ind,ind2) = max(abs(ft((ind-1)*n+ind2,:)-f)); % Eqn 4
end
end
end
🎉3 参考文献
文章中一些内容引自网络,会注明出处或引用为参考文献,难免有未尽之处,如有不妥,请随时联系删除。



















 1039
1039

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











