






OpenAI Gym是一个用于开发和比较强化学习算法的工具包。OpenAI Gym提供了一个模拟环境,能够在这个环境中测试和评估强化学习算法。
目录
1、Gym中的小游戏
OpenAI Gym中有很多写好的游戏环境,有经典的控制问题、机器人以及Atari视频游戏等。这些游戏环境被广泛用于测试和比较各种强化学习算法的性能,有“Acrobot-v1”、“CartPole-v1”、“MountaiCar-v0”、“Pendulum-v0”、“LunarLander-v2”、“Breakout-ram-v0”等。
这里通过代码看一下‘CartPole-v0’环境和‘Pendulum-v0’环境的信息。
1.1、‘CartPole-v0’
车杆环境信息(‘CartPole-v0’):
import gym
env = gym.make('CartPole-v0') # 获取环境
# env = gym.make('Pendulum-v0')
print(env.spec.id) # env.spec.id = 'CartPole-v0'
env.render() # 把环境渲染出来
for i_episode in range(20): # 20个序列
observation = env.reset() # 初始状态
for t in range(100): # 每个序列的步长T
env.render()
action = env.action_space.sample() # 动作空间随机采样动作
observation, reward, done, info = env.step(action) # 环境采取动作后的反馈信息
print(type(observation))
print(observation.dtype)
print(info)
print(i_episode, action, reward, observation) # 打印信息
print(env.observation_space.shape)
print('观测空间 = {}'.format(env.observation_space))
print(type(env.observation_space))
print(env.observation_space.dtype)
print(env.observation_space.high)
print(type(env.observation_space.high))
print(env.observation_space.high.shape)
print(env.action_space.shape)
print('动作空间 = {}'.format(env.action_space))
print(type(env.action_space))
print(env.action_space.dtype)
if done: # 若杆的倾斜度数过大,或者车子离初始位置左右的偏离程度过大,或者坚持时间到200帧,则游戏结束
break
env.close() # 结束环境CartPole-v0
0
<class 'numpy.ndarray'>
float64
{}
0 1 1.0 [-0.01759727 0.19541452 0.03675939 -0.3142585 ]
(4,)
观测空间 = Box([-4.8000002e+00 -3.4028235e+38 -4.1887903e-01 -3.4028235e+38], [4.8000002e+00 3.4028235e+38 4.1887903e-01 3.4028235e+38], (4,), float32)
<class 'gym.spaces.box.Box'>
float32
[4.8000002e+00 3.4028235e+38 4.1887903e-01 3.4028235e+38]
<class 'numpy.ndarray'>
(4,)
()
动作空间 = Discrete(2)
<class 'gym.spaces.discrete.Discrete'>
int64
‘CartPole-v0’游戏画面:
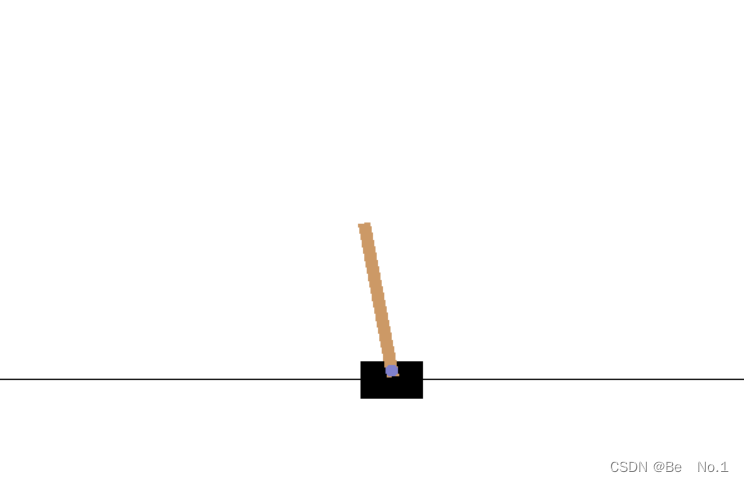
1.2、‘Pendulum-v0’
倒立摆环境信息(‘Pendulum-v0’):
import gym
env = gym.make('Pendulum-v0') # 获取环境
print(env.spec.id) # env.spec.id = 'Pendulum-v0'
for i_episode in range(20): # 20个序列
observation = env.reset() # 初始状态
for t in range(100): # 每个序列的步长T
env.render() # 把环境渲染出来
action = env.action_space.sample() # 动作空间随机采样动作
observation, reward, done, info = env.step(action) # 环境采取动作后的反馈信息
print(type(observation))
print(observation.dtype)
print(info)
print(i_episode, action, reward, observation) # 打印信息
print(env.observation_space.shape)
print('观测空间 = {}'.format(env.observation_space))
print(type(env.observation_space))
print(env.observation_space.dtype)
print(env.observation_space.high)
print(type(env.observation_space.high))
print(env.observation_space.high.shape)
print(env.action_space.shape)
print('动作空间 = {}'.format(env.action_space))
print(type(env.action_space))
print(env.action_space.dtype)
print(env.action_space.high)
print(type(env.action_space.high))
print(env.action_space.high.shape)
if done: # 若杆的倾斜度数过大,或者车子离初始位置左右的偏离程度过大,或者坚持时间到200帧,则游戏结束
break
env.close() # 结束环境Pendulum-v0
<class 'numpy.ndarray'>
float64
{}
0 [1.1776284] -5.104848307802821 [-0.65246865 -0.75781572 -0.45207371]
(3,)
观测空间 = Box([-1. -1. -8.], [1. 1. 8.], (3,), float32)
<class 'gym.spaces.box.Box'>
float32
[1. 1. 8.]
<class 'numpy.ndarray'>
(3,)
(1,)
动作空间 = Box([-2.], [2.], (1,), float32)
<class 'gym.spaces.box.Box'>
float32
[2.]
<class 'numpy.ndarray'>
(1,)‘Pendulum-v0’游戏画面:

2、Gym环境
2.1、测试环境的步骤
通过观察第一部分的两个游戏环境代码,我们可以发现运行一个环境的代码框架:
import gym
# env = gym.make('CartPole-v0') # 获取环境
env = gym.make('Pendulum-v0') # 获取环境
print(env.spec.id) # env.spec.id = 'Pendulum-v0'
for i_episode in range(20): # 20个序列
observation = env.reset() # 初始状态
for t in range(100): # 每个序列的步长T
env.render() # 把环境渲染出来
action = env.action_space.sample() # 动作空间随机采样动作
observation, reward, done, info = env.step(action) # 环境采取动作后的反馈信息
if done: # 若杆的倾斜度数过大,或者车子离初始位置左右的偏离程度过大,或者坚持时间到200帧,则游戏结束
break
env.close() # 结束环境环境的主要构成部分:
a、创建环境:env = gym.make('Pendulum-v0')
b、获取环境的初始状态:observation = env.reset()
c、执行动作获取之后的信息:observation, reward, done, info = env.step(action)
d、环境渲染:env.render()
e、关闭环境:env.close()
最重要的是env.reset()和env.step(action):
env.reset():让环境回到初始时刻,得到环境的初始状态,然后可以开始新一轮的游戏序列。
env.step(action):用某一算法得到此状态
的action之后代入env.step(action),环境内部的逻辑就能够施加这一action,之后游戏环境会反馈相应的信息(下一状态、奖励值、是否完成这一序列、info)。
2.2、创建环境
创建环境代码env = gym.make('Pendulum-v0')代表是从Gym中已经注册过的环境中创建的,若我们想要自己创建一个环境,那么就要了解Gym中环境中创建的流程。
Gym中已经写好了一个环境的基类Env,因此构造自己的环境就要继承基类Env,重写其中的方法(类中的函数)就行了。
2.2.1、基类Env
基类Env的python代码链接:https://github.com/openai/gym/blob/0cd9266d986d470ed9c0dd87a41cd680b65cfe1c/gym/core.py
class Env(object):
# Set this in SOME subclasses
metadata = {'render.modes': []}
reward_range = (-float('inf'), float('inf'))
spec = None
# Set these in ALL subclasses
action_space = None
observation_space = None
def step(self, action):
raise NotImplementedError # 在继承Env的子类中若不实现对该方法的设计,那么子类对象调用Env类的该方法会报错
def reset(self):
raise NotImplementedError
def render(self, mode='human'):
raise NotImplementedError
def close(self):
pass
def seed(self, seed=None):
return
@property # 修饰器
def unwrapped(self):
# 完全解开这个环境
return self # 返回:基础非包装gym.Env实例对象
def __str__(self):
if self.spec is None:
return '<{} instance>'.format(type(self).__name__)
else:
return '<{}<{}>>'.format(type(self).__name__, self.spec.id)
def __enter__(self):
return self
def __exit__(self, *args):
self.close()
# propagate exception
return False
property函数(实际上是一个Built-in-Class,类似int()、str()、float()),即:
class property(fget=None,fset=None,fdel=None,doc=None)
property函数的优点:
1、property函数返回一个property属性对象,简化魔法方法的操作:
class C: def __init__(self): self._x = 250 def getx(self): return self._x def setx(self, value): self._x = value def delx(self): del self._x x = property(getx, setx, delx) # 这样x可以全权代理_x,对x的访问和修改都会影响到_x c = C() # 实例化对象c print(c.x) print(c._x) print(c.__dict__) c.x = 520 # c._x = 520也可以得到相同的结果 print(c.x) print(c._x) print(c.__dict__) del c.x # del c._x也可以得到相同的结果 # print(c.x) # 报错,因为已经被删了 # print(c._x) # 报错,因为已经被删了 print(c.__dict__)250 250 {'_x': 250} 520 520 {'_x': 520} {}其实通过__getattr__()、__setattr__()、__delattr__()三个魔法方法也可以实现,但是太麻烦了,要写一个判断条件来判断是不是“x”传进来,因此property函数的第一个优点是简化操作。
2、作为装饰器使用
从property函数的参数就可以看出,前三个参数传入的是函数,而装饰器实现的原理就是通过传入函数参数来实现的。装饰器是property函数最为经典的应用了。
property函数作为装饰器来使用会让创建只读属性的工作变得极为简单。
class E: def __init__(self): self._x = 250 @property # 只传入property用于获取的参数,赋值和删除的参数函数默认值为None,表示不支持赋值和删除操作。 def x(self): return self._x e = E() print(e.x) print(e._x) print(e.__dict__) # e.x = 520 报错 # del e.x 报错250 250 {'_x': 250}装饰器就是一个语法糖(语法糖:是计算机语言中添加的某种语法,这种语法对语言的功能性没有影响,但是更方便程序员使用。语法糖让程序更加简洁,有更高的可读性。)
class E: def __init__(self): self._x = 250 def x(self): return self._x x = property(x) # 只传入property用于获取的参数,赋值和删除的参数函数默认值为None,表示不支持赋值和删除操作。 e = E() print(e.x) print(e._x) print(e.__dict__) # e.x = 520 报错 # del e.x 报错250 250 {'_x': 250}如果要通过装饰器来写写入、赋值和删除操作,可以用property属性对象提供的getter、setter和deleter三个方法(这三个方法对应的就是property函数的三个参数接口)。这样做和x = property(getx, setx, delx)效果一样:
class E: def __init__(self): self._x = 250 @property def x(self): return self._x @x.setter def x(self, value): self._x = value @x.deleter def x(self): del self._x e = E() print(e.x) print(e._x) print(e.__dict__) e.x = 520 print(e.x) print(e._x) print(e.__dict__) del e.x # print(e.x) # 报错,因为已经被删了 # print(e._x) # 报错,因为已经被删了 print(e.__dict__)250 250 {'_x': 250} 520 520 {'_x': 520} {}以上就是property函数的用处。
Env类是OpenAI Gym主要的类。它封装了一个具有任意幕后动态的环境。环境可以是部分可观测的(POMDP)或全部可观测的(MDP)。
Env类需要了解的主要API方法有以下五个方法:
step(self, action):
reset(self):
render(self, mode='human'):
close(self):
seed(self, seed=None):
在Env类设置以下属性:
action_space:有效动作对应的Space对象。
observation_space:有效观测值对应的Space对象。
reward_range:对应于最小和最大可能奖励的元组(设置为[-inf,+inf]的默认奖励范围已经存在。如果想要更窄的范围,请设置它)。
2.2.1.1、step()方法
step(self, action)就是我们要设计的环境的规则。
作用:运行环境动态的一个时间步长,接受一个动作action并返回一个元组(观察observation、奖励reward、完成done、信息info)。
tip:当到达序列末端时,调用reset()重置此环境的状态。
参数:action(object),即代理提供的动作。
返回:observation,reward,done,info。
observation(object):智能体对当前环境的观察。
reward(float) : 上次操作后返回的奖励。
done(bool): 该序列是否已经结束,在这种情况下,进一步的step()调用将返回未定义的结果(布尔值True或False)。
info(dict):包含辅助诊断信息(有助于调试,有时也有助于学习)。
2.2.1.2、reset()方法
reset(self)就是我们要设计的环境的初始状态,即每次环境的开始状态。
作用:重置环境状态并返回初始观察值。
返回:observation(object),即初始观察。
该方法无参数。
2.2.1.3、render()方法
render(self, mode='human')就是我们要设计的环境的渲染界面。
作用:渲染环境。支持的渲染模式集因环境而异(还有一些环境根本不支持渲染)。按照惯例,有三种模式:
- human:渲染到当前显示器或终端而且什么也不返回,通常供人类用。
- rgb_array:返回形状为 (x, y, 3) 的numpy.ndarray形式的数据,表示x×y像素图像的RGB值,适合用于转成视频。
- ansi:返回一个包含一个终端样式的文本表示的字符串(str)或StringIO.StringIO。文本可以包含换行符和ANSI转义序列(例如对于颜色)。
tip:确保您的类的metadata的键“render.modes”的值包含支持的模式列表。建议调用super()在实现中使用此方法的功能。
参数:mode(str),即渲染模式
该方法无return。
例子:
class MyEnv(Env):
metadata = {'render.modes': ['human', 'rgb_array']}
def render(self, mode='human'):
if mode == 'rgb_array':
return np.array(...) # return RGB frame suitable for video
elif mode == 'human':
... # pop up a window and render
else:
super(MyEnv, self).render(mode=mode) # just raise an excep2.2.1.4、close()方法
close(self)就是我们要设计的环境的结束。
作用:在子类中重写close来执行任何必要的清理。垃圾收集或程序退出时环境将自动close()自身。
该方法无参数,无返回return。
2.2.1.5、seed()方法
seed(self,seed=None)就是我们要设计的环境的随机数生成器的种子。
tip:某些环境使用多个伪随机数生成器。我们希望捕获所有使用过的此类种子,以确保多个生成器之间并不存在偶然的相关性。
返回:list<bigint>,即返回此环境随机中使用的种子列表数字生成器。列表中的第一个值应该是“主”种子,或复制者应传递给的'种子'。通常,主种子等于提供的“种子”,但是如果seed=None,则这不会成立。
2.2.2、GoalEnv类
class GoalEnv(Env):
def reset(self):
if not isinstance(self.observation_space, gym.spaces.Dict):
raise error.Error('GoalEnv requires an observation space of type gym.spaces.Dict')
for key in ['observation', 'achieved_goal', 'desired_goal']:
if key not in self.observation_space.spaces:
raise error.Error('GoalEnv requires the "{}" key to be part of the observation dictionary.'.format(key))
def compute_reward(self, achieved_goal, desired_goal, info):
raise NotImplementedErrorGoalEnv类是继承基类Env的子类,GoalEnv类的功能与任何常规OpenAI Gym环境一样,主要对观察空间施加所需的结构。更具体地说,观察空间需要包含至少三个元素,即‘observation’、 ‘desired_goal’、 ‘achieved_goal’。
‘desired_goal’指定agent应该尝试实现的目标。
‘achieved_goal’是agent当前实现的目标。
‘observation’包含像往常一样对环境进行实际观察。
2.2.3、Wrapper类
class Wrapper(Env):
def __init__(self, env):
self.env = env
self.action_space = self.env.action_space # 动作空间
self.observation_space = self.env.observation_space # 状态空间
self.reward_range = self.env.reward_range # 奖励范围
self.metadata = self.env.metadata # 渲染模式
def __getattr__(self, name):
if name.startswith('_'):
raise AttributeError("attempted to get missing private attribute '{}'".format(name))
return getattr(self.env, name)
@property
def spec(self):
return self.env.spec
@classmethod
def class_name(cls):
return cls.__name__
def step(self, action):
return self.env.step(action)
def reset(self, **kwargs):
return self.env.reset(**kwargs)
def render(self, mode='human', **kwargs):
return self.env.render(mode, **kwargs)
def close(self):
return self.env.close()
def seed(self, seed=None):
return self.env.seed(seed)
def compute_reward(self, achieved_goal, desired_goal, info):
return self.env.compute_reward(achieved_goal, desired_goal, info)
def __str__(self):
return '<{}{}>'.format(type(self).__name__, self.env)
def __repr__(self):
return str(self)
@property
def unwrapped(self):
return self.env.unwrapped # 返回原始的环境对象EnvWrapper类是继承基类Env的子类,包装环境以允许模块化转换,Wrapper类是所有包装器的基类。
子类可以在不接触原始代码下重写一些方法改变原始环境的行为。如果子类重写了"__init__",不要忘记调用 "super().__init__(env)" 把父类的初始化也完成。
继承Wrapper改写状态空间:
class ObservationWrapper(Wrapper):
def reset(self, **kwargs):
observation = self.env.reset(**kwargs)
return self.observation(observation)
def step(self, action):
observation, reward, done, info = self.env.step(action)
return self.observation(observation), reward, done, info
def observation(self, observation):
raise NotImplementedError继承Wrapper改写奖励:
class RewardWrapper(Wrapper):
def reset(self, **kwargs):
return self.env.reset(**kwargs)
def step(self, action):
observation, reward, done, info = self.env.step(action)
return observation, self.reward(reward), done, info
def reward(self, reward):
raise NotImplementedError继承Wrapper改写动作空间:
class ActionWrapper(Wrapper):
def reset(self, **kwargs):
return self.env.reset(**kwargs)
def step(self, action):
return self.env.step(self.action(action))
def action(self, action):
raise NotImplementedError
def reverse_action(self, action):
raise NotImplementedError2.2.4、基类Space
基类Space的python代码链接:https://github.com/openai/gym/blob/0cd9266d986d470ed9c0dd87a41cd680b65cfe1c/gym/spaces/space.py
class Space(object):
def __init__(self, shape=None, dtype=None):
import numpy as np # takes about 300-400ms to import, so we load lazily
self.shape = None if shape is None else tuple(shape)
self.dtype = None if dtype is None else np.dtype(dtype)
self.np_random = None
self.seed()
def sample(self):
raise NotImplementedError
def seed(self, seed=None):
self.np_random, seed = seeding.np_random(seed)
return [seed]
def contains(self, x):
raise NotImplementedError
def __contains__(self, x):
return self.contains(x)
def to_jsonable(self, sample_n):
return sample_n
def from_jsonable(self, sample_n):
return sample_n基类Space是强化学习的状态空间和动作空间的基类,一般连续的空间使用Box类,离散的空间使用Discrete类,也有一些其他的类供状态空间和动作空间使用如Dict、Tuple类等。
2.2.5、连续状态空间Box类
class Box(Space):
def __init__(self, low, high, shape=None, dtype=np.float32):
assert dtype is not None, 'dtype must be explicitly provided. '
self.dtype = np.dtype(dtype)
if shape is None:
assert low.shape == high.shape, 'box dimension mismatch. '
self.shape = low.shape
self.low = low
self.high = high
else:
assert np.isscalar(low) and np.isscalar(high), 'box requires scalar bounds. '
self.shape = tuple(shape)
self.low = np.full(self.shape, low)
self.high = np.full(self.shape, high)
self.low = self.low.astype(self.dtype)
self.high = self.high.astype(self.dtype)
self.bounded_below = -np.inf < self.low
self.bounded_above = np.inf > self.high
super(Box, self).__init__(self.shape, self.dtype)
def is_bounded(self, manner="both"):
below = np.all(self.bounded_below)
above = np.all(self.bounded_above)
if manner == "both":
return below and above
elif manner == "below":
return below
elif manner == "above":
return above
else:
raise ValueError("manner is not in {'below', 'above', 'both'}")
def sample(self):
high = self.high if self.dtype.kind == 'f' \
else self.high.astype('int64') + 1
sample = np.empty(self.shape)
unbounded = ~self.bounded_below & ~self.bounded_above
upp_bounded = ~self.bounded_below & self.bounded_above
low_bounded = self.bounded_below & ~self.bounded_above
bounded = self.bounded_below & self.bounded_above
sample[unbounded] = self.np_random.normal(
size=unbounded[unbounded].shape)
sample[low_bounded] = self.np_random.exponential(
size=low_bounded[low_bounded].shape) + self.low[low_bounded]
sample[upp_bounded] = -self.np_random.exponential(
size=upp_bounded[upp_bounded].shape) - self.high[upp_bounded]
sample[bounded] = self.np_random.uniform(low=self.low[bounded],
high=high[bounded],
size=bounded[bounded].shape)
return sample.astype(self.dtype)
def contains(self, x):
if isinstance(x, list):
x = np.array(x) # Promote list to array for contains check
return x.shape == self.shape and np.all(x >= self.low) and np.all(x <= self.high)
def to_jsonable(self, sample_n):
return np.array(sample_n).tolist()
def from_jsonable(self, sample_n):
return [np.asarray(sample) for sample in sample_n]
def __repr__(self):
return "Box" + str(self.shape)
def __eq__(self, other):
return isinstance(other, Box) and (self.shape == other.shape) and np.allclose(self.low, other.low) and np.allclose(self.high, other.high) Box是中的一个(可能无界)盒子。具体来说,一个Box代表n个闭区间的笛卡尔积。每个区间的形式可以是
,
,
,
。
有两种常见的用例:
a、每个维度的界限相同
Box(low=-1.0, high=2.0, shape=(3, 4), dtype=np.float32)
Box(3, 4)b、每个维度的独立边界
Box(low=np.array([-1.0, -2.0]), high=np.array([2.0, 4.0]), dtype=np.float32)
Box(2,)
在Box类的空间中内生成单个随机样本时,每个坐标是根据区间的形式被采样的:
:均匀分布
:平移指数分布
:平移负指数分布
:正态分布
2.2.6、离散动作空间Discrete类
class Discrete(Space):
def __init__(self, n):
assert n >= 0
self.n = n
super(Discrete, self).__init__((), np.int64)
def sample(self):
return self.np_random.randint(self.n)
def contains(self, x):
if isinstance(x, int):
as_int = x
elif isinstance(x, (np.generic, np.ndarray)) and (x.dtype.kind in np.typecodes['AllInteger'] and x.shape == ()):
as_int = int(x)
else:
return False
return as_int >= 0 and as_int < self.n
def __repr__(self):
return "Discrete(%d)" % self.n
def __eq__(self, other):
return isinstance(other, Discrete) and self.n == other.nDiscrete类是离散的空间,有几个动作就有几个离散的数,从0一直到n,如Discrete(2)代表二个动作的离散空间(0和1)。
Discrete类空间采样是从n个数中随机采样的。
2.3、注册环境
自定义注册一个Gym环境,首先需要安装Gym包(pip install gym),然后建立文件如下:
my_env/
__init__.py
my_env.py
test.py
tip:测试文件test.py和my_env在同一级
在my_env/__init__.py文件中添加以下代码(定义初始化文件):
from gym.envs.registration import register
register(
id='MyEnv-v0',
entry_point='my_env.my_env:MyEnv',
)在my_env/my_env.py文件中添加以下代码(定义环境文件):
class MyEnv(gym.Env):
def __init__(self, params):
def reset(self):
def step(self, action):
def seed(self, seed=None):
def render(self, mode):
def close(self):
在test.py文件中添加以下代码(定义测试环境的文件):
import gym
import my_env
env = gym.make('MyEnv-v0')综上,这就是搭建强化学习环境的相关步骤。
















 9万+
9万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









