







前言
本篇博文记载了自己学习ResNet的过程。
提示:以下是本篇文章正文内容,下面案例可供参考
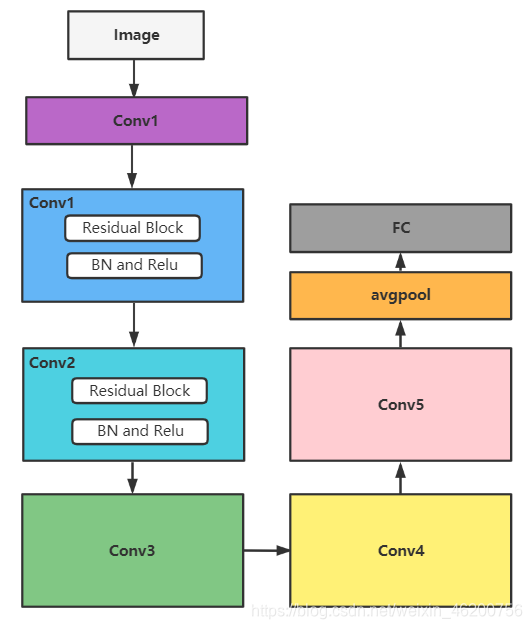
一、ResNet系列网络图

首先网络结构图可以这样理解
① 层:conv1_x,conv2_x,…,conv_5x,其中conv2_x,…,conv_5x每层都是由若干个Residual块组成,经过不同层,特征矩阵的长宽size和深度channel发生改变
②Residual块:Residual块分为两种,实线Block和虚线Block
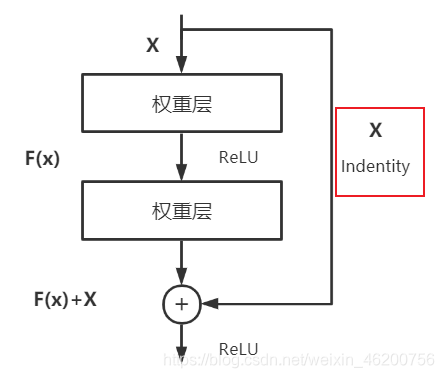
区别在于:为了保证残差块主分支特征矩阵 F(x) 和 shortcut分支的特征矩阵 X 能进行相加,其shape要相同,故要根据主分支输出F(x)的shape决定是否需要将X的shape进行变化
二、代码
1.Model大致结构

2.Model.py
import torch.nn as nn
import torch
# 定义一个类 残差结构 Basic Block
class BasicBlock(nn.module): # 继承来自于nn.Modele
expansion = 1 # 残差结构主分支中 卷积核的个数比 比如ResNet_18和ResNet_34中每个ConV层中几个残差结构的Channel都一样
# 定义初始函数 残差结构需要的一系列层结构
# 输入channel; 输出channel; stride 步距; downsample 是否下采样,对应于虚线残差结构中[1X1,128,s=2]
def __init__(self,in_channel, out_channel, stride=1, downsample=None):
super(BasicBlock, self).__init__()
# 第一个卷积层ConV1 输入,输出深度channel,核大小=3,
# 当stride=1即对应实线Residual,当stride=2即对应虚线Residual,改变输入特征矩阵的宽高为原来一半
# 使用BN操作,无需添加偏置Bias
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=out_channel, kernel_size=3,
stride=stride, padding=1, bias=False)
# 其输入就是ConV1的输出Channel
self.bn1 = nn.BatchNorm2d(out_channel)
# 第二个卷积层Conv2 参数和ConV1差不多,只需注意输入输出Channles
self.conv2 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel, kernel_size=3,
stride=1, padding=1, bias=False)
# BN操作
self.bn2 = nn.BatchNorm2d(out_channel)
# 定义下采样方法
self.downsample = downsample
# 定义正向传播过程 输入特征矩阵x
def forward(self, x):
identity = x
# 判断Residual模块是否需要下采样
if self.downsample is not None:
identity = self.downsample
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out += identity
out = self.relu(out)
return out
# 至此 ResNet-18和34完成
# 同样的方法 ResNet-50/101/152层
class Bottleneck(nn.Module):
"""
注意:原论文中,在虚线残差结构的主分支上,第一个1x1卷积层的步距是2,第二个3x3卷积层步距是1。
但在pytorch官方实现过程中是第一个1x1卷积层的步距是1,第二个3x3卷积层步距是2,
这么做的好处是能够在top1上提升大概0.5%的准确率。
可参考Resnet v1.5 https://ngc.nvidia.com/catalog/model-scripts/nvidia:resnet_50_v1_5_for_pytorch
"""
# 因为ResNet-50/101/152中每个Conv_X块中第三个卷积层的Channel都是前两层的4倍
expansion = 4
# 定义初始化函数
def __init__(self, in_channel, out_channel, stride = 1, downsample=None):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=out_channel, kernel_size=1, stride=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channel)
# -------------------------------------
self.conv2 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel, kernel_size=3, stride=stride, bias=False)
self.bn2 = nn.BatchNorm2d(out_channel)
# -------------------------------------
self.conv3 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel*self.expansion, kernel_size=1, stride=1, bias=False)
self.bn3 = nn.BatchNorm2d(out_channel*self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
def forward(self, x):
identify = x
if self.downsample is not None:
identify = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out += identify
out = self.relu(out)
return out
class Resnet(nn.module):
"""
block为定义的残差块,如果是18或34层就对应BasicBlock,如果是54,101,154层就对应BottleNeck
block_nums残差结构数目 为列表结构 存储的ConV_X块有几个残差块 例如ResNet-18中每个ConV_X块中分别需要残差块个数为[2,2,2,2]
num_classes训练集分类个数
"""
def __init__(self,
block,
block_nums,
num_classes=1000,
include_top= True):
super(Resnet, self).__init__()
self.include_top = include_top
self.in_channel = 64 # 输入的Channel为64
# Conv1 为[7X7,c64,s2]
# 输入channel为RGN三通道图像
# 输出channel为64 即7X7的卷积核为64个 其他参数不详细解释
self.conv1 = nn.Conv2d(3, self.in_channel, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(self.in_channel)
self.relu = nn.ReLU(self.in_channel)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1) # 设置padding=1 保证输入特征矩阵缩减为原来一半
# -------------生成ConV2---------------
self.layer2 = self._make_layer(block, 64, block_nums[0])
# -------------ConV3---------------
self.layer3 = self._make_layer(block, 128, block_nums[1], stride=2)
# -------------ConV4---------------
self.layer4 = self._make_layer(block, 256, block_nums[2], stride=2)
# -------------ConV5---------------
self.layer5 = self._make_layer(block, 512, block_nums[3], stride=2)
if self.include_top: # 其默认为True
self.avgpool = nn.AdaptiveAvgpool2d((1, 1)) # 自适应的平均池化下采样操作 无论输入特征矩阵大小为多少,最后out_size=[1,1]
# 输入节点个数即为最终[1X1]特征矩阵的深度 输出节点个数即为分类别个数
self.fc = nn.Linear(512*block.expansion, num_classes)
# 对卷积层初始化操作
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
"""
block 实线residual块或者虚线residual块
channel 残差结构中 第一个卷积层所用的卷积核的个数
block_num 每个(层)卷积块中有多少个残差块
stride 初始为1
-----------
这里需要注意的是,ResNet18/34 从Conv1==>max pool==>Conv2时,矩阵的宽高不发生变化 深度channel也不发生变化为64 实线Residual
ResNet50/101/152 从Conv1==>max pool==>Conv2时,矩阵的宽高不发生变化 深度channel发生变化为64-->128 虚线Residual
-----------
"""
def _make_layer(self, block, channel, block_nums, stride =1):
downsample = None
"""
如果是ResNet18/30 则不进入循环 不进行下采样 Conv2第一个实线Residual, 特征矩阵大小不变,深度也不变
如果是ResNet50/101/152 则进入循环 进行下采样 Conv2第一个虚线Residual, 特征矩阵大小不变,深度变为4X64
事实上,ResNet50/101/152 进入下一个ConvX层时,第一个残差块都是虚线的,后面的残差块都是实的
"""
if stride !=1 or self.in_channel != channel*block.expansion:
# 虚线residual 输入channel为in_channel,输出应为in_channel*4, kernel_size=1
downsample = nn.Sequential(nn.Conv2d(self.in_channel,
channel*block.expansion,
kernel_size=1,
stride=stride,
bias=False), nn.BatchNorm2d(channel*block.expansion)
)
# 定义一个空列表 用来存储每一个ConvX中的残差块
layers = []
layers.append(block(self.in_channel, # 定义第一个【虚线残差块】,并压入layers
channel,
downsample=downsample,
stride=stride))
self.in_channel = channel*block.expansion # 如果是ResNet-18/30 expansion=1;而ResNet-50/101/152 expansion=4
for _ in range(1, block_nums): # 将Conv2层,其他 【实线残差】 结构依次压进去
layers.append(block(self.in_channel, channel)) # channel为残差块第一个卷积层卷积核的个数
# 以【非关键字参数形式】 将layers传入 nn.sequential函数中
return nn.Sequential(*layers)
def forward(self, x):
"""
x输入图像 -->conv1-->bn1-->Relu1-->maxpool--> 输出特征矩阵x
"""
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
# 接下来就是x-->conv2一系列残差结构-->conv3--conv4-->conv5
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.layer5(x)
if self.include_top:
x = self.avgpool(x) # 平均池化下采样
x = torch.flatten(x, 1) # 展平操作
x = self.fc(x) # 全连接操作
return x
# 定义ResNet-34
def resnet34(num_classes=1000, include_top=True):
return Resnet(BasicBlock, [3, 4, 6, 3], num_classes=num_classes, include_top=include_top)
def resnet101(num_classes=1000, include_top=True):
return Resnet(Bottleneck, [3, 4, 23, 3], num_classes=num_classes, include_top=include_top)
3.网络亮点和细节
3.1 Residual块
搞明白ResNet网络的问题以后,我们需要思考一个问题,引入的残差块到底解决了什么问题?在He的原文中有提到是解决深层网络的一种退化问题,但并明确说明是什么问题!
这里我参考了知乎“薰风初入弦”作者的观点,原帖链接如下,欢迎大家阅读原文,支持原作者
知乎:Resnet到底在解决一个什么问题呢?–作者:薰风初入弦(上海交通大学 计算机科学与技术博士在读)
借用上作者帖子中的一句话来简单回答这个问题:
“当我们堆叠一个模型时,理所当然的会认为效果会越堆越好。因为,假设一个比较浅的网络已经可以达到不错的效果,那么即使之后堆上去的网络什么也不做,模型的效果也不会变差。
然而事实上,这却是问题所在。“什么都不做”恰好是当前神经网络最难做到的东西之一。MobileNet V2的论文[2]也提到过类似的现象,由于非线性激活函数Relu的存在,每次输入到输出的过程都几乎是不可逆的(信息损失)。我们很难从输出反推回完整的输入。
也许赋予神经网络无限可能性的“非线性”让神经网络模型走得太远,却也让它忘记了为什么出发(想想还挺哲学)。这也使得特征随着层层前向传播得到完整保留(什么也不做)的可能性都微乎其微。
用学术点的话说,这种神经网络丢失的“不忘初心”/“什么都不做”的品质叫做恒等映射(identity mapping)。
因此,可以认为Residual Learning的初衷,其实是让模型的内部结构至少有恒等映射的能力。以保证在堆叠网络的过程中,网络至少不会因为继续堆叠而产生退化!
3.2 BN操作
BN操作目的是使得一批Batch的Feature Map满足均值为0,方差为1的分布规律。例如下图1所示,对于Conv1来说输入的就是满足某一分布的特征矩阵,但对于Conv2而言输入的feature map就不一定满足某一分布规律了,标准化处理也就是是使得feature map满足均值为0,方差为1的分布规律。
 它是如何能够做到加速网络收敛?缓解梯度消失?
它是如何能够做到加速网络收敛?缓解梯度消失?
通过查找资料后发现这里面有几个关键点:
(1)中心极限定理:
根据中心极限定理,在样本较多的情况下,独立分布的叠加收敛于正态分布。以RGB图像中R通道为例,一个batch就相当于一个独立分布,多个batch叠加,正好符合中心极限定理的条件,也就用正态分布来标准化了。
(2)Internal Covariate Shift:
网络中间层在训练过程中,数据分布的改变称之为Internal Covariate Shift,即内部协变量偏移,而BN就是要解决在训练过程中,中间层数据分布发生改变的情况。如图2所示,
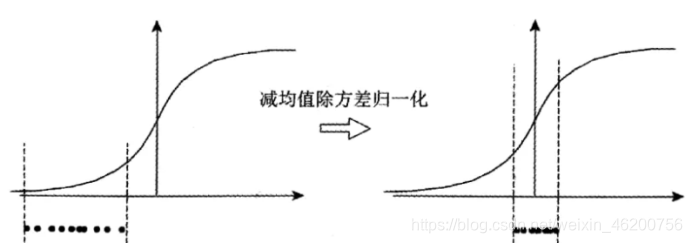
但是单纯的了减均值除方差归一化操作会带来一个问题,数据大量存在于Sigmod函数的非饱和区域:
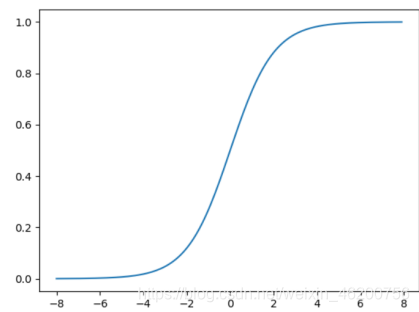
在这一区域内绝大多数激活函数都会有一个问题:函数梯度变化程线性增长,不能保证对数据的非线性变换,从而影响数据表征能力,降低神经网络的作用。
因此作者加入了一个反变化,确保至少可以把数据还原为原数据,这里的两个参数都是需要后续去学习的:
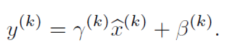
最后,BN的本质就是利用优化变一下方差大小和均值位置,使得新的分布更切合数据的真实分布,保证模型的非线性表达能力。
最后解决梯度消失问题,加速网络收敛就顺理成章了,就是改变数据的分布,合适的数据愤分布,就会避免梯度消失,加速模型收敛。
总结
1.学习深度网络要牢牢把握特征矩阵经过不同层后的Shape的情况,这样就可以把握网络的结构
2.注意每个网络的提出的创新点,解决了什么问题
ResNet提出的残差块和BN操作是其亮点














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









