







今天采用之前写的拆标签工具进行拆标签的时候,之前是在linux电脑上操作,今天是在windows上面才做。原来代码如下(别急着拷代码,这代码有瑕疵,后面有改进的代码)
# -*- coding:utf-8 -*-
from __future__ import absolute_import
from __future__ import print_function
from __future__ import division
import os, cv2
import random, tqdm
import numpy as np
import xml.etree.ElementTree as ET
from xml.dom.minidom import Document
ori_xml_dir = '../Annotations'
ori_jpg_dir = '../JPEGImages'
tar_xml_dir = './Annotations'
tar_jpg_dir = './JPEGImages'
def get_sk2():
for jpg in tqdm.tqdm(os.listdir(ori_jpg_dir)): #遍历ori_jpg_dir中每一张图
xml = jpg[:-4]+'.xml' #遍历ori_jpg_dir中的图定义对应的xml文件
jpgpath = os.path.join(ori_jpg_dir, jpg) #图路径
xmlpath = os.path.join(ori_xml_dir, xml) #xml路径
if not os.path.exists(xmlpath):
continue #有图没xml文件继续
oriimg = cv2.imdecode(np.fromfile(jpgpath,dtype=np.uint8), cv2.IMREAD_COLOR | cv2.IMREAD_IGNORE_ORIENTATION) #从指定的内存缓存中读取数据,并把数据转换(解码)成图像格式
h, w, _ = oriimg.shape #保存oriimg原图的大小
tree=ET.parse(xmlpath) #载入xml文件
root=tree.getroot() # 获取根节点
numbox_list, newbox_list = [], []
nn = 0
for obj in root.iter('object'): #遍历root只拿出object。obj在这些中循环
cls = obj.find('name').text
if cls in ['jkxl_qxd_01040105', 'jkxl_td_sh_01010107', 'jkxl_yw_nc_01010106', 'jkxl_wb_bzd_01020202', 'jkxl_wh_fdhj_01030101','jkxl_fl_xs_01010103','rdq_jyz_qs_05010104','jkxl_zx_hx_lw_01010102','jkxl_gd_blg_01030103','jkxl_ybm_tl_01030102','jkxl_jyht_ps_01020104','blq_tk_06010105','jkxl_jyz_tl_01040104','jkxl_qt_xs_01040106']:
bnd_box = obj.find('bndbox')
box = [
int(float(bnd_box.find('xmin').text)),
int(float(bnd_box.find('ymin').text)),
int(float(bnd_box.find('xmax').text)),
int(float(bnd_box.find('ymax').text)),
]
label_h, label_w = box[3]-box[1], box[2]-box[0]
tarimg = oriimg[box[1]:box[3], box[0]:box[2], :]
if label_h < 0 or label_h > h or label_w < 0 or label_w > w:
tarimg = oriimg
nn = nn + 1
newjpgdir = os.path.join(tar_jpg_dir, cls)
if not os.path.exists(newjpgdir):
os.mkdir(newjpgdir)
newjpgpath = os.path.join(newjpgdir, jpg[:-4]+'_'+cls+'_'+str(nn)+'.jpg')
cv2.imwrite(newjpgpath, tarimg)
if __name__ == '__main__':
get_sk2()
运行的时候遇到一些问题:
1、发现拆出来的小图图片名字中文变乱码了。不好改,直接把windows的默认编码改了,修改方式如下(windows10专业版)。控制面板-时钟和区域、更改日期、时间或数字格式-管理-更改系统区域设置(C)... -Beta 版: 使用 Unicode UTF-8 提供全球语言支持(U)
前面打勾,然后重启。
2、图片报错

原代码

利用try:
except Exception:
把问题图找出来,查看问题图,修改代码如下:

查看问题图:


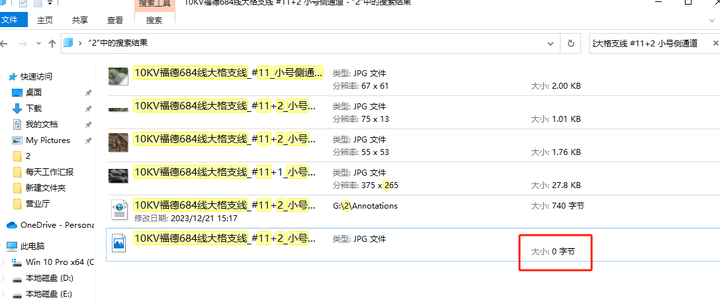
把问题图改的改,删的删,终于代码正常运行,正常代码如下:
# -*- coding:utf-8 -*-
from __future__ import absolute_import
from __future__ import print_function
from __future__ import division
import os, cv2
import random, tqdm
import numpy as np
import xml.etree.ElementTree as ET
from xml.dom.minidom import Document
ori_xml_dir = '../Annotations'
ori_jpg_dir = '../JPEGImages'
tar_xml_dir = './Annotations'
tar_jpg_dir = './JPEGImages'
def get_sk2():
for jpg in tqdm.tqdm(os.listdir(ori_jpg_dir)): #遍历ori_jpg_dir中每一张图
xml = jpg[:-4]+'.xml' #遍历ori_jpg_dir中的图定义对应的xml文件
jpgpath = os.path.join(ori_jpg_dir, jpg) #图路径
xmlpath = os.path.join(ori_xml_dir, xml) #xml路径
if not os.path.exists(xmlpath):
continue #有图没xml文件继续
try:
oriimg = cv2.imdecode(np.fromfile(jpgpath,dtype=np.uint8), cv2.IMREAD_COLOR | cv2.IMREAD_IGNORE_ORIENTATION) #从指定的内存缓存中读取数据,并把数据转换(解码)成图像格式
except Exception:
print(jpgpath)
h, w, _ = oriimg.shape #保存oriimg原图的大小
tree=ET.parse(xmlpath) #载入xml文件
root=tree.getroot() # 获取根节点
numbox_list, newbox_list = [], []
nn = 0
for obj in root.iter('object'): #遍历root只拿出object。obj在这些中循环
cls = obj.find('name').text
if cls in ['jkxl_qxd_01040105', 'jkxl_td_sh_01010107', 'jkxl_yw_nc_01010106', 'jkxl_wb_bzd_01020202', 'jkxl_wh_fdhj_01030101','jkxl_fl_xs_01010103','rdq_jyz_qs_05010104','jkxl_zx_hx_lw_01010102','jkxl_gd_blg_01030103','jkxl_ybm_tl_01030102','jkxl_jyht_ps_01020104','blq_tk_06010105','jkxl_jyz_tl_01040104','jkxl_qt_xs_01040106']:
bnd_box = obj.find('bndbox')
box = [
int(float(bnd_box.find('xmin').text)),
int(float(bnd_box.find('ymin').text)),
int(float(bnd_box.find('xmax').text)),
int(float(bnd_box.find('ymax').text)),
]
label_h, label_w = box[3]-box[1], box[2]-box[0]
tarimg = oriimg[box[1]:box[3], box[0]:box[2], :]
if label_h < 0 or label_h > h or label_w < 0 or label_w > w:
tarimg = oriimg
nn = nn + 1
newjpgdir = os.path.join(tar_jpg_dir, cls)
if not os.path.exists(newjpgdir):
os.mkdir(newjpgdir)
try:
newjpgpath = os.path.join(newjpgdir, jpg[:-4]+'_'+cls+'_'+str(nn)+'.jpg')
cv2.imwrite(newjpgpath, tarimg)
except Exception:
print(newjpgpath)
if __name__ == '__main__':
get_sk2()

使用了一段时间,把windows的默认编码改为Unicode UTF-8会造成很多图标乱码,而已有写基于windows默认GBK开发的应用程序都打不开了,所以只好把默认改为Unicode UTF-8取消掉。那么这时候乱码问题又出现了。自己百度了下,就是把
cv2.imwrite(filename, img)
改为
cv2.imencode('.jpg', img)[1].tofile(filename)
我们文档这样改

添加图片注释,不超过 140 字(可选)
OK,完美解决
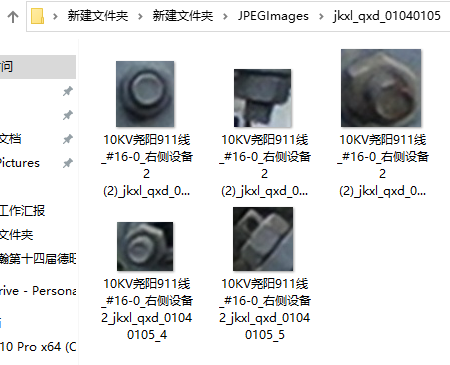
所以更新下完整代码为(支持windows默认编码GBK的)
# -*- coding:utf-8 -*-
from __future__ import absolute_import
from __future__ import print_function
from __future__ import division
import os, cv2
import random, tqdm
import numpy as np
import xml.etree.ElementTree as ET
from xml.dom.minidom import Document
ori_xml_dir = '../Annotations'
ori_jpg_dir = '../JPEGImages'
tar_xml_dir = './Annotations'
tar_jpg_dir = './JPEGImages'
def get_sk2():
for jpg in tqdm.tqdm(os.listdir(ori_jpg_dir)): # 遍历ori_jpg_dir中每一张图
xml = jpg[:-4] + '.xml' # 遍历ori_jpg_dir中的图定义对应的xml文件
jpgpath = os.path.join(ori_jpg_dir, jpg) # 图路径
xmlpath = os.path.join(ori_xml_dir, xml) # xml路径
if not os.path.exists(xmlpath):
continue # 有图没xml文件继续
try:
oriimg = cv2.imdecode(np.fromfile(jpgpath, dtype=np.uint8),
cv2.IMREAD_COLOR | cv2.IMREAD_IGNORE_ORIENTATION) # 从指定的内存缓存中读取数据,并把数据转换(解码)成图像格式
except Exception:
print(jpgpath) # 若太多不想改只想直接跳过此处改为 continue
h, w, _ = oriimg.shape # 保存oriimg原图的大小
tree = ET.parse(xmlpath) # 载入xml文件
root = tree.getroot() # 获取根节点
numbox_list, newbox_list = [], []
nn = 0
for obj in root.iter('object'): # 遍历root只拿出object。obj在这些中循环
cls = obj.find('name').text
if cls in ['jkxl_qxd_01040105', 'jkxl_td_sh_01010107', 'jkxl_yw_nc_01010106', 'jkxl_wb_bzd_01020202',
'jkxl_wh_fdhj_01030101', 'jkxl_fl_xs_01010103', 'rdq_jyz_qs_05010104', 'jkxl_zx_hx_lw_01010102',
'jkxl_gd_blg_01030103', 'jkxl_ybm_tl_01030102', 'jkxl_jyht_ps_01020104', 'blq_tk_06010105',
'jkxl_jyz_tl_01040104', 'jkxl_qt_xs_01040106']:
bnd_box = obj.find('bndbox')
box = [
int(float(bnd_box.find('xmin').text)),
int(float(bnd_box.find('ymin').text)),
int(float(bnd_box.find('xmax').text)),
int(float(bnd_box.find('ymax').text)),
]
label_h, label_w = box[3] - box[1], box[2] - box[0]
tarimg = oriimg[box[1]:box[3], box[0]:box[2], :]
if label_h < 0 or label_h > h or label_w < 0 or label_w > w:
tarimg = oriimg
nn = nn + 1
newjpgdir = os.path.join(tar_jpg_dir, cls)
if not os.path.exists(newjpgdir):
os.mkdir(newjpgdir)
try:
newjpgpath = os.path.join(newjpgdir, jpg[:-4] + '_' + cls + '_' + str(nn) + '.jpg')
# cv2.imwrite(newjpgpath, tarimg)
cv2.imencode('.jpg', tarimg)[1].tofile(newjpgpath)
except Exception:
print(newjpgpath)
if __name__ == '__main__':
get_sk2()














 4590
4590











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









