







这篇文章是香港大学韩晓光老师等人在SIGGRAPH 2017的工作,创建了一个业余者也可以创建3D Face或漫画模型的系统。

CV上目前存在许多场景,包含卡通角色,社交媒体上的虚拟形象,3D Face漫画以及与Face有关的艺术和设计…
1 INTRODUCTION
为什么需要?
文章首先阐述虽然有一些场景需要实际采集的高精度的人脸模型,但还有很多场景是需要一种低成本交互式的3D人脸建模方式。接着,带着读者思考了我们绘制2D人脸的方式,先画轮廓(silhouette)然后再描绘眼睛鼻子嘴巴等特征。
这些要素在3D中也同样存在,但是这些要素之间的深度信息和面部区域形状仍是未知的。但好在,二维轮廓与三维形状是高度相关的——鼻子轮廓与人的整体形状间存在强关联性,嘴巴轮廓与鼻子形状也有强相关性。因此,文中指出,关键是要从数据中学习这种关联性,并让它们指导省力地脸部建模 。
做了什么?怎么用的?
据此,这篇文章中提出了一个基于深度学习的为3D脸部和漫画建模的草图系统。这个系统包含一个省力的素描系统,允许用户自由地绘制不精确但有表现力的二维线条,代表面部特征的轮廓。系统包含两个阶段的素描,最初的勾画和接下来的素描。
- Initial Sketching: 用户从头开始绘制2D草图,生成的初始3D模型不一定完全匹配。
- Follow-up Sketching: 开始阶段,初始3D模型上的特征轮廓被投射到二维画布,产生一个更新的草图;如果不满意,用户可以重新绘制一些投射线。重新绘制的线条成为更难的约束条件,需要更紧密的匹配。
什么方法?
在负责将2D face转换到3D face model深度回归网络上。一方面,我们要让用户可以绘制随意数量的线条,所以我们将2D sketch看作一整张图片,依靠一个CNN网络去计算。但是这种方式,即使是最上层的神经元也没法“看到”整张图象。所以,为了弥补全局信息的缺失,我们还使用了一个降维模型直接表示主要面部特征。深度学习网络的输出是一组双线性人脸表征的系数,可以用于重建人脸网格的所有三维顶点。这个双线性表示法将身份和表情视为两种独立模式,具有独立的系数。为了避免这两种模式的干扰,深度学习网络有两个独立的分支,在共享卷积层后有不同数量的全连接层。
我们工作的数据库是在(Cao et al. 2014)上扩展的,最终有15000个注册的三维人脸模型,其中包括150个身份,25个表情和4个夸张程度,其对应手绘二维草图也包括在内。
Contribution
- 提出了一个用于三维人脸和漫画建模的新型素描系统。该系统有一个省力的素描界面,通过学习其二维草图之间的关联,初始的三维人脸模型从二维草图中自动生成。我们的系统支持基于手势的互动,以便用户进一步操作初始人脸模型。
- 一个基于深度回归的,用于从2D草图中推断3D人脸的CNN网络被设计。网络融合了CNN和基于输入草图形状的特征,并且包含两个独立的全连接层分支,生成两个独立的系数子集,用于双线性人脸表示。
- 一个公开发布的,用于训练和测试的,具有不同身份、表情和夸张成都的大幅扩展的人脸数据集。
2 RELATED WORK
这里我觉得暂时不细读。
- Data-Driven Modeling by Sketching
- Morphable Face Models
- 3D Face Caricatures
- Sketch-Based Freeform Modeling
3 USER INTERFACE
总体流程如Fig.2,仔细看这个图其实就可以。简单来说,就是先画一个,然后进行2D细节修改,最后进行3D的修改完善。
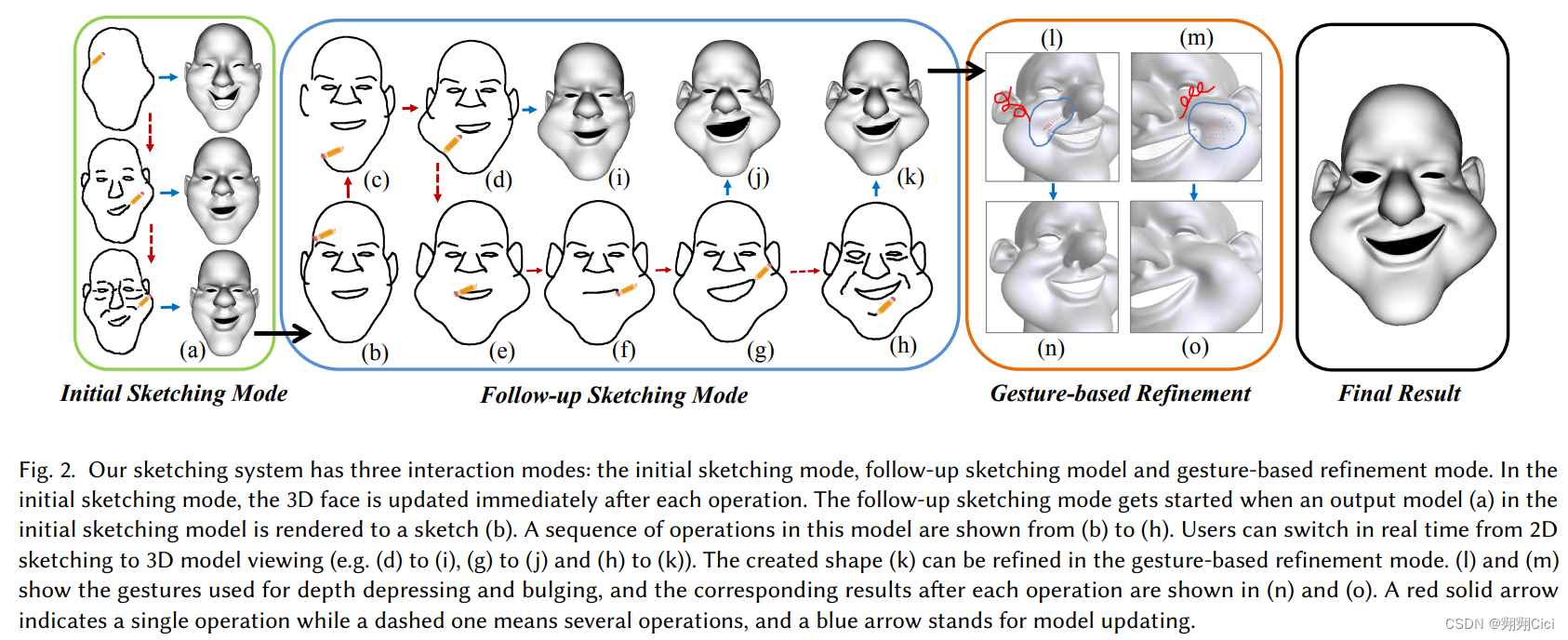
Input Device: a mouse or a peb tablet. Three phase of coarse-to-fine👇
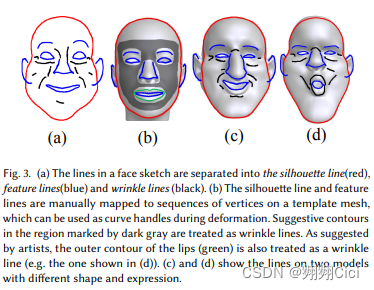
Three categories lines: a silhouette line (highlighted in red), feature lines (highlighted in blue), wrinkle
lines (highlighted in black). [这个颜色并不是用户用的颜色区分,just for highlight]
3.1 Initial Sketching Mode
这个阶段每画一条线,3D face都会更新。
Operations: Draw, erase
3.2 Follow-up Sketching Mode
可以切换2D和3D视图,也可以直接进入这个阶段,如果用一个模板face的话。
Operations: draw, erase, auto-snapp.
擦除轮廓和特征之后需要进行绘图操作Section 5.1,不能让它是开放的
3.3 Gesture-Based 3D Face Refinement
handel-based deformation. 设计了10种笔画,定义不同的操作。

Handle-based deformation:
- a selection step: 用户可以通过刷涂和擦除来标记需要处理的顶点。
- 利用上图的笔触来定义ROI(Region of Interest),如果未定义,默认未所有网格。
- a deformation step: ROI选择,XY平面上的变形,沿Z轴的变形和轮廓驱动的变形。line被用于平移。当需要修改深度时,凸起和凹陷各设置了3个级别,up/down roll。left arrow: undo. right arrow: redo.
4 3D FACE INFERENCE FROM SKETCHES
从本质上讲,使用深度神经网络去估算了一个函数 V=φ(I) ,来将Image I匹配到顶点。
4.1 Database Construction
15,000 meshed (150 identities, 25 expressions and 4 levels of exaggeration)(each mesh 11500 vertices, all same topology)
New Expressions
选了新的与原来表情差异较大的表情,让艺术家在一个中立的face上进行建模新的14种表情。用deformation-transfer的方法迁移到其余的身份上。

Shape Exaggeration
基于(Sela et al. 2015),给定一个网络,对顶点的梯度应用一个缩放系数,然后用(Yu et al.)的方法进行重建。由于无关周围梯度不稳定,所以进行固定,而夸大其他部分(脸颊、下巴、额头、鼻子和耳朵)。1级是原始的,应用3种不同的缩放系数。见Fig.5。
Sketch Rendering
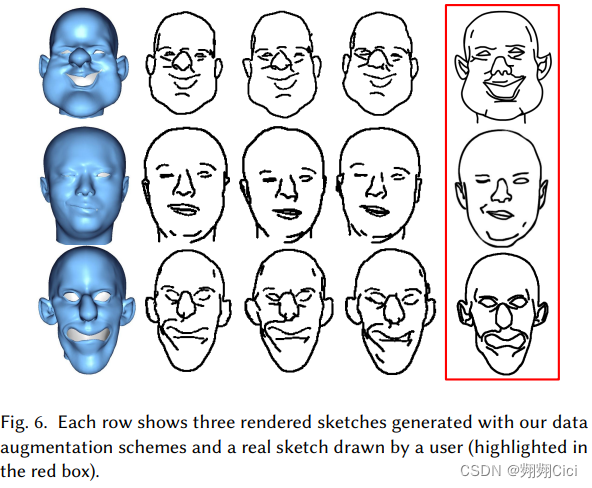
Hand-drawn Sketches
为了让数据集里的2D sketch更真实,还请了20个user每人绘制200张。这绘制的2000张是从总数里随机选出的。
4.2 Bilinear Morphable Representatiom
3D face inference 可以被看作是一个回归函数,将草图和相关联的3Dface的 u, v向量进行关联。
- 3-mode tensor T with 11,500vertices X 600 identities X 25 expressions
- After N-mode singular value decomposition and tensor truncation, a reduced core tensor C is obtained
- V: a vertex set
- an identity weigh vector u (50)
- an expression wight vector v (16)
V = C × 2 u T × 3 v T V=C ×_2 u^T ×_3 v^T V=C×2uT×3vT
4.3 Network Architecture

包含多个卷积层去提取输入图像中的特征。这些卷积层和AlexNet (Krizhevsky et al. 2012)中的设置相同。
Bilinera Output
区分身份信息和表情信息两个独立的u, v权重向量,用两个独立的不同数量的全连接层来生成u, v。同时,我们按照AlexNet中的设置,仍然保持全连接层在卷积层之后。
u: 3个FC层,identity mode(600 shapes),更复杂
v: 1个FC层,expression mode(25 types)
都是1024个神经元,经验设置,这样会有更好的性能。
Pixel-Level Input
首先输入包含所有绘画内容的,a 256×256 binary sketch image
Shape-Level Input
50个维度identity mode,16个维度的expression mode,共66个系数组成了Shape-level Input。在u,v两个分支的FC层里,这66个系数都跟随其后,包含512个神经元,这部分的输出会与之前的特征向量进行串联。也有尝试一开始就串联进入分支,但是是负面效果。
Vertex Loss Layer
我们的回归网络是直接被训练与减小顶点近似误差。所以设置了一个顶点损失层,通过u和v向量来估算真实顶点和重建得到顶点的L2 error。
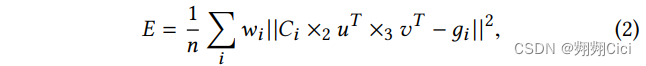
Ci是对应于第i个顶点的,core tensor C的二维切面。gi是第i个顶点的真实位置。wi是第i个顶点的权重,依照重要性设定的,譬如3D轮廓和特征线就更重要。
4.4 Network Training
在训练阶段,所有的权重都是随机初始化的。为了使训练过程稳定收敛,分为了三部分:① classifier training;② u-v regression;③ final tuning。
首先对随机初始化的分类网络进行多任务训练,该网络在两个分支中使用softmax层作为输出层,任务是将输入的草图分类到相应的身份和表情类别中。
其次,固定卷积层的权重,回归u和v。这需要将softmax层输出替换到u和v的回归层。回归过程中,u和v向量的L2误差之和被作为损失函数使用。
最后的调整步骤,我们将顶点损失层添加到u-v回归曾的顶部,并训练整个网络知道收敛。
5 IMPLEMENTATION
5.1 Face Modeling from Sketches
Initial sketching mode: 仅仅通过网络来进行3D人脸模型的更新,不进行handle-based的变形。
Follow-up sketching mode: 网络+一个现存的基于拉普拉斯 (Sorkine et al. 2004)的handle-based shape deformation技术。为了使我们的设置同其向匹配,预定义了一些3D curve handles,2D的轮廓和特征同3D curves相关,如Fig.3(b)。由于所有模型拥有相同的拓扑结构,所以这些模板的mesh可以被迁移到任何face mesh。最开始,系统会通过投影3D curve handles来画一个初始的2D Sketch,然后用户可以擦了再画,新画的内容可以有点对点的关系。这一步的handle-based并不改变深度信息。

- “为什么要通过投影预定义的顶点序列来渲染轮廓?”因为渲染出来的轮廓都是对变化非常敏感的部分。
- “怎么实现Handle-based Laplacian deformation?”通过解决一个线性系统,在预处理阶段进行矩阵分解,然后获取一个持续更新的b。
A T A x = A T b A^TAx = A^Tb ATAx=ATb
【疑问,第二步的Follow-up Sketching mode,修改后的模型好像并没有纳入上一次预测的信息?】
5.2 Gesture-Based 3D Face Refinement
这一步要实现交互的流畅性,就需要实现高精度的gesture classification。
Gesture Classification
Data: 从5个用户中,每种gestures,200个sample。
CNN: 11×11×32的卷积,ReLU,3×3 max pooling,5x5x64 convolution, ReLU, 3x3 max pooling, 3x3x16 convolution, ReLU, 3x3 max pooling, 256-d fully connected, 9-d fully connected. These layers are followed by a softmax layer for final classification.
Train and Test Proportion: 9:1
**Accuracy: ** 96%
Local Deformation
只对ROI里的进行变形
6 RESULTS AND USER STUDY
Caffe deep learning library (Jia et al. 2014) and GPUs | iterations 500000, 800000 and 500000 | learning rate 0.001, 0.00001, 0.00001 | mini-batch size 50 | momentum prameter 0.9 | weight decay 0.0005
每个network的预测花费50s,handle-based deformation 41ms
6.1 User Studies on the Interface
Stage Ⅰ: User Experience
12个成年人,8男4女。都是22-29的毕业生。9位基本无经验,1名很熟悉建模,只有2名很会画画。实验开始前会有15分钟的教学。
原系统 vs. 仅用于变形的系统。用户需要建模两次。为了便于比较,跳过了initial sketch的部分。
两个问题:① 哪个界面会帮助用户创建更好地模型。② 皱纹线会帮助创造更好的结果吗?9是 vs 3看情况
并记录了建模时间——我们的系统:10min,只有10%用于修改。基于变形的系统:80%的时间用于修改。
Stage Ⅱ: Evaluation
邀请了38名没有参与建模的用户,对阶段Ⅰ的结果进行评估。需要选择看起来更自然,更像素描的模型。
456 votes (38 users x 12 questions) -> received 374 votes
虽然去除阶段Ⅰ用户在不同界面绘画时,轮廓和特征线的微小差异。我们对齐每队模型上,3D轮廓和特征的线。这里是通过5.1中的curve handles来完成的。
6.2 Comparison with ZBrush
邀请了一位艺术家进行10min建模。展示用户自己建的和艺术家建的。
6.3 Comparisons on 3D Model Inference
在用深度回归网络推断双线性人脸的表示系数时,有许多选择。本文在多个选择中进行比较,以验证最后的设计。
Ablation Study on Network Architecture
PixelShapeCNN: 卷积层+2D双线性形状编码,也是最后的网络
PixelCNN: 只运用卷积层特征的网络
ShapeNN: 一个以2D双线性编码作为输入的回归网络
PixelCNN-Wrinkle: 和PixelCNN网络相同,但是训练图像是没有wrinkle lines的图像
PixelCNNSingle: 只有一个stack的全连接层来推断u和v
用所有顶点的平均距离误差来作为main error
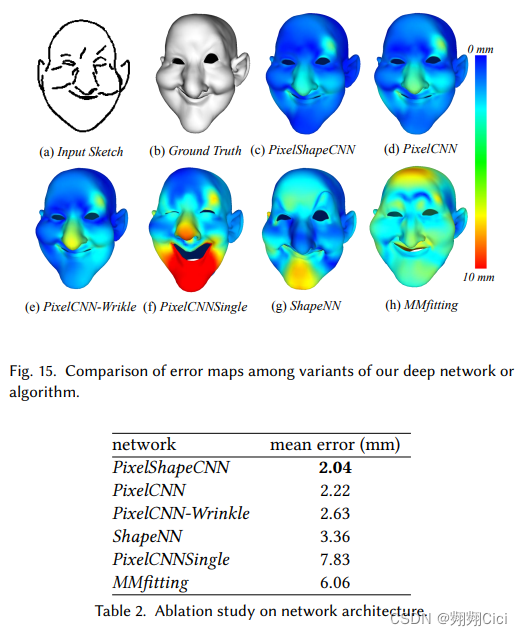
Morphable Model Fitting
MMfitting(Cao等人,2014)
7 CONCLUSIONS AND DISCUSSION

建立数据集时,所有部位和面部的夸张程度是一致的,当不一致是,系统会产生不够准确的结果。未来可以去扩充数据集。
此外,可变行模型没办法在新的位置创建新的特征细节。未来可以用U-net或GAN等方法实现pixel-pixel prediction















 3112
3112











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









