







标题:基于扫视标注的时态语句定位中探索高斯先验
原文链接:https://openaccess.thecvf.com/content/ICCV2023/papers/Li_D3G_Exploring_Gaussian_Prior_for_Temporal_Sentence_Grounding_with_Glance_ICCV_2023_paper.pdf
源码链接:https://github.com/solicucu/D3G
发表:ICCV-2023
Abstract
时态语句定位(TSG)旨在根据给定的自然语言查询从非剪辑视频中定位特定时刻。最近,弱监督方法与全监督方法相比仍有较大性能差距,而后者需要繁琐的时间戳标注。在本研究中,我们旨在降低标注成本,同时在 TSG 任务中保持与全监督方法相比具有竞争力的性能。为实现这一目标,我们研究了最近提出的扫视监督时态语句定位任务,该任务仅需为每个查询提供单帧标注(称为扫视标注)。在此设置下,我们提出了一种基于动态高斯先验的扫视标注定位框架(D3G),它由语义对齐组对比学习模块(SA - GCL)和动态高斯先验调整模块(DGA)组成。具体而言,SA - GCL 通过联合利用高斯先验和语义一致性从二维时间图中采样可靠的正时刻,这有助于在联合嵌入空间中对齐正语句 - 时刻对。此外,为了减轻扫视标注导致的标注偏差以及对由多个事件组成的复杂查询进行建模,我们提出了 DGA 模块,它动态调整分布以逼近目标时刻的真实情况。在三个具有挑战性的基准上进行的大量实验验证了所提出的 D3G 的有效性。它在很大程度上优于最先进的弱监督方法,并缩小了与全监督方法的性能差距。代码可在https://github.com/solicucu/D3G获取。
1. Introduction
时态语句定位是计算机视觉中的一个基本问题,近年来受到越来越多的关注。给定查询语句和未剪辑的视频,TSG 的目标是定位与查询在语义上对应的特定时刻的开始和结束时间戳。近年来,全监督时态语句定位(FS - TSG)取得了巨大成就 [9, 1, 41, 43, 34, 29, 33, 42]。然而,为每个句子获取准确的时间戳既费力又主观,这阻碍了它扩展到大规模视频 - 句子对和实际应用中。
弱监督时态语句定位(WS - TSG),仅需视频和查询对,最近受到越来越多的关注。尽管近年来取得了很大进展 [19, 32, 12, 45, 43, 44],但 WS - TSG 与 FS - TSG 之间仍然存在巨大的性能差距。WS - TSG 由于视频级标注和剪辑级任务之间的巨大差异而存在严重的定位问题。
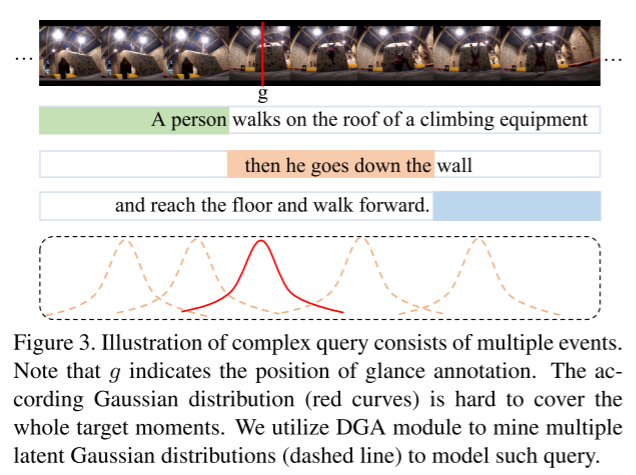
最近,Cui 等人 [6] 提出了一种用于 TSG 的新标注范式,称为扫视标注,仅需目标时刻时间边界内随机单帧的时间戳。值得注意的是,与 WS - TSG 相比,这种标注仅增加了微不足道的标注成本。图 1 说明了扫视标注的细节。基于扫视标注,Cui 等人提出了基于对比学习的 ViGA。ViGA 首先将输入视频切割成固定长度的剪辑,根据扫视标注为其分配生成的高斯权重,然后将剪辑与查询进行对比。这种方式有两个明显的缺点。首先,感兴趣的时刻通常具有不同的持续时间。因此,这些剪辑无法覆盖广泛的目标时刻,这不可避免地会使句子与不完整的时刻对齐,从而获得次优性能。其次,ViGA 利用以扫视帧为中心的固定尺度高斯分布来描述每个标注时刻的跨度。然而,扫视标注并不保证在目标时刻的中心,这会导致如图 2 所示的标注偏差。此外,由于一些复杂的查询语句由多个事件组成,单个高斯分布很难同时覆盖所有事件,如图 3 所示。为了解决上述缺陷,并通过低成本的扫视标注充分释放高斯先验知识的潜力,我们提出了一种基于动态高斯先验的扫视标注定位框架(D3G),如图 4 所示。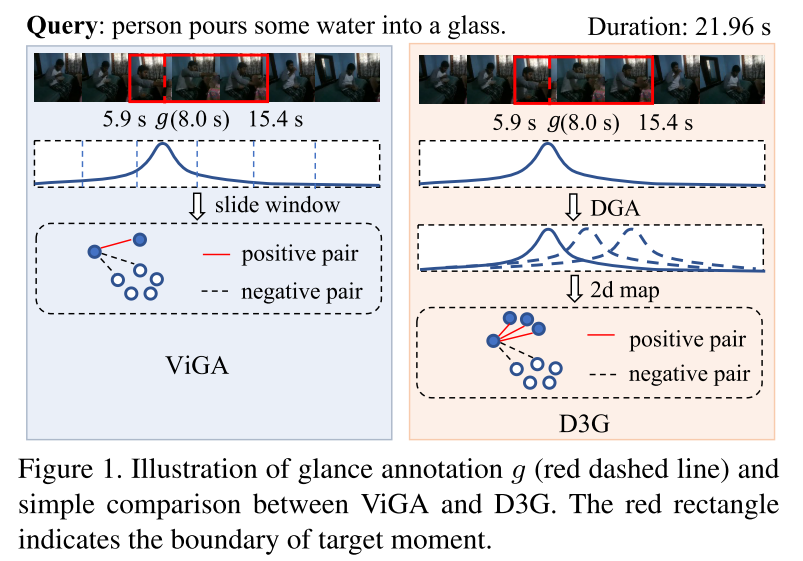
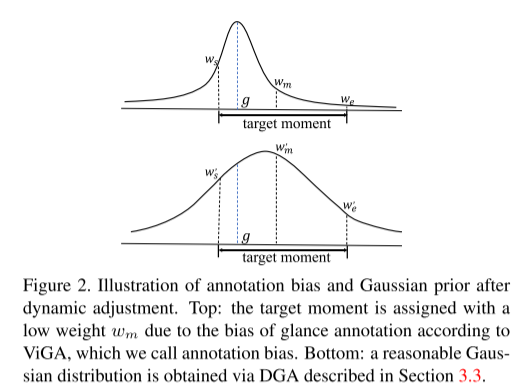
图2。动态调整后的标注偏差和高斯先验说明。上图:根据ViGA,由于glance标注的偏差,目标矩被赋予了较低的权重wm,我们称之为标注偏差。下图:通过3.3节的DGA得到一个合理的高斯分布。
我们首先按照 2D - TAN [43] 生成广泛的候选时刻。然后,我们提出一个语义对齐组对比学习模块(SA - GCL),在联合嵌入空间中对齐正语句 - 时刻对。具体来说,对于每个查询语句,我们根据校准的高斯先验采样一组正时刻,并最小化这些时刻与查询语句之间的距离。通过这种方式,它倾向于逐渐挖掘与真实情况有越来越多重叠的时刻。此外,我们提出一个动态高斯先验调整模块(DGA),进一步减轻标注偏差并近似由多个事件组成的复杂时刻的跨度。具体来说,我们采用多个高斯分布来描述时刻的权重分布。因此,不同时刻的权重分布可以灵活调整并逐渐接近真实情况。我们的贡献总结如下:
我们提出了一种基于动态高斯先验的扫视标注定位框架(D3G),有助于在更低的标注成本下发展时态语句定位。
我们提出了一个语义对齐组对比学习模块来对齐正语句 - 时刻对的特征,以及一个动态高斯先验调整模块来缓解标注偏差并对复杂时刻的分布进行建模。
大量实验表明,D3G 与相同标注范式下的方法相比获得了一致且显著的收益,并在很大程度上优于弱监督方法。
2. Related Work
Full Supervised Temporal Sentence Grounding.
FSTSG 方法可分为两类。两阶段方法 [1, 9, 11, 13, 14, 35] 首先通过滑动窗口或提议生成在视频中提出候选片段。然后使用跨模态匹配网络找到最佳匹配剪辑。然而,由于候选数量众多,这些提议 - 匹配范式非常耗时。为了减少冗余计算,一些研究人员提出了单阶段方法 [2, 3, 40, 41, 30, 20, 43, 21, 39, 37]。2D - TAN [43] 构建二维特征图来建模视频片段的时间关系。最近,Wang 等人 [33] 提出了一种基于 2D - TAN 的相互匹配网络,并通过利用视频内和视频间的负样本进一步提高了性能。尽管全监督方法取得了令人满意的性能,但它们高度依赖于准确的时间戳标注。为大规模视频 - 句子对获取这些标注非常耗时费力。
Weakly Supervised Temporal Sentence Grounding.
具体而言,WS - TSG 方法可分为基于重建的方法 [8, 18, 26, 4] 和多实例学习(MIL)方法 [19, 10, 5, 38, 12, 27]。SCN [18] 采用语义完成网络,用生成的提议恢复查询语句中的被屏蔽单词,为促进最终预测提供反馈。为了进一步利用 MIL - 基于方法中的负样本,CNM [44] 和 CPL [45] 提出用高斯函数生成提议并引入视频内对比学习。WS - TSG 方法确实以低标注成本取得了进展,然而,由于视频级标注和剪辑级任务之间的差异,与 FS - TSG 方法相比仍然存在较大的性能差距。
Glance Supervised Temporal Sentence Grounding.
最近,ViGA [6] 提出了具有新标注范式的扫视监督 TSG(GSTSG)任务。ViGA 利用高斯函数来建模不同剪辑与目标时刻的相关性,并将剪辑与查询进行对比。尽管 ViGA 取得了有前景的性能,但它仍然存在如引言中提到的两个限制。同时,Xu 等人 [36] 提出了类似的任务,称为 PS - VTG,并基于语言激活序列生成伪片段级标签。为了更好地探索具有扫视标注的 TSG 任务中的高斯先验,我们提出了一个简单而有效的 D3G,与 WS - TSG 和 FS - TSG 方法相比都取得了有竞争力的性能。与我们的工作同时,Ju 等人 [15] 提出了一个强大的部分 - 全联合框架(PFU),并在扫视标注或短剪辑标签下取得了优异的性能。
3. Proposed Method
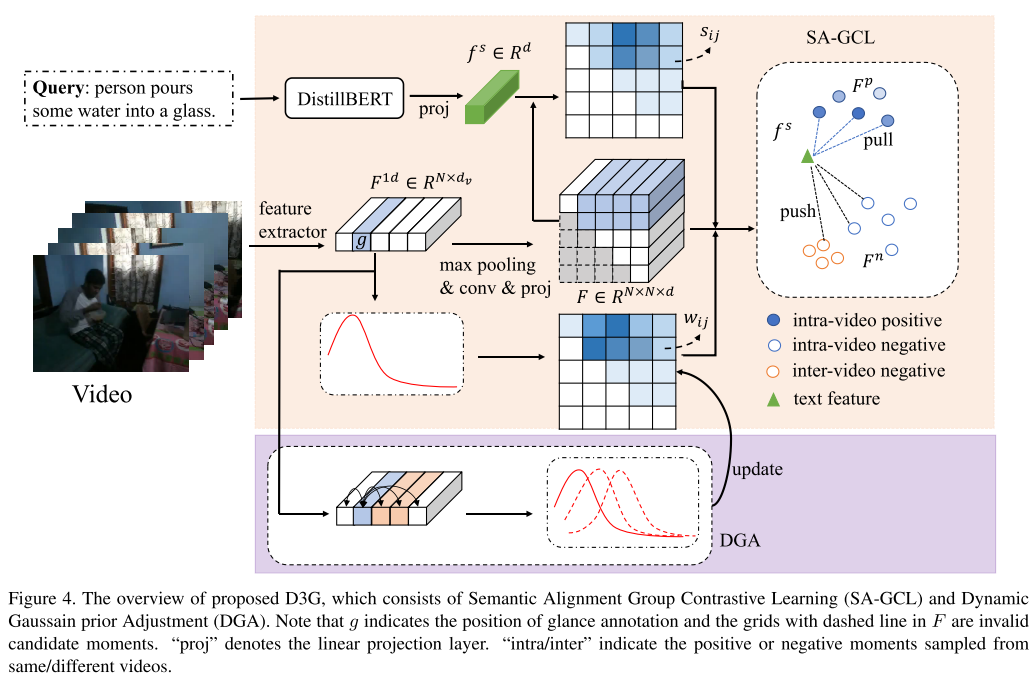
图4。本文概述了语义对齐群体对比学习(SA-GCL)和动态高斯先验调整(DGA)两种语义对齐群体对比学习方法。注意,g表示glance注释的位置,F中虚线的网格是无效的候选矩。“proj”表示线性投影层。“intra/inter”表示从相同/不同视频中采样的正或负时刻。
3.1. Overview
给定未剪辑视频 V V V和查询语句 S S S,时态语句定位任务是确定起始时间戳 t s t_s ts和结束时间戳 t e t_e te,使时刻 V t s : t e V_{t_s:t_e} Vts:te在语义上与查询最佳对应。对于FS - TSG,给定查询描述会提供准确时间戳 ( t s , t e ) (t_s, t_e) (ts,te)。而Cui等人[6]提出新的低成本标注范式——扫视标注,仅需单个时间戳 g g g,满足 g ∈ [ t s , t e ] g \in [t_s, t_e] g∈[ts,te]。依此设定,我们提出D3G以释放扫视标注潜力。
D3G采用类似[43, 33]的网络架构。给定未剪辑视频,先用预训练的2D或3D卷积网络[25, 28]编码为特征向量,将视频特征分割为 N N N个视频剪辑。具体对每个剪辑应用平均池化得剪辑级特征 V = { f 1 v , f 2 v , ⋯ , f N v } ∈ R N × D v V = \{f_1^v, f_2^v, \cdots, f_N^v\} \in \mathbb{R}^{N×D_v} V={f1v,f2v,⋯,fNv}∈RN×Dv,再经全连接层降维得 F 1 d ∈ R N × d v F^{1d} \in \mathbb{R}^{N×d_v} F1d∈RN×dv。然后按2D - TAN[43]用最大池化将其编码为二维时间特征图 F ^ ∈ R N × N × d v \hat{F} \in \mathbb{R}^{N×N×d_v} F^∈RN×N×dv。语言编码器选DistilBERT[23],依[33]得句子级特征 f ^ s ∈ R d s \hat{f}^s \in \mathbb{R}^{d_s} f^s∈Rds。最后用线性投影层将文本和视觉特征投影到相同维度 d d d,句子最终表示为 f s ∈ R d f^s \in \mathbb{R}^d fs∈Rd,所有时刻特征为 F ∈ R N × N × d F \in \mathbb{R}^{N×N×d} F∈RN×N×d,最终匹配分数由 f s f^s fs与 F F F中元素的余弦相似度给出。
3.2. Semantic Alignment Group Contrastive Learning
本节旨在挖掘与查询语义最对应的时刻并最大化相似度。为此有两个关键步骤:一是按2D - TAN生成大量候选时刻,并依扫视标注生成可靠高斯先验权重;二是提出语义对齐组对比学习,在联合嵌入空间对齐正语句 - 时刻对。
具体地,给定编码后的视频特征
F
1
d
∈
R
N
×
d
v
F^{1d} \in \mathbb{R}^{N×d_v}
F1d∈RN×dv和扫视标注
g
g
g,用参数为
(
μ
,
σ
)
(\mu, \sigma)
(μ,σ)的高斯函数建模帧与目标时刻关系,其中
μ
\mu
μ由
g
g
g确定。先将序列索引
I
∈
{
1
,
2
,
⋯
,
N
}
I \in \{1, 2, \cdots, N\}
I∈{1,2,⋯,N}通过线性变换缩放到
[
−
1
,
1
]
[-1, 1]
[−1,1]:
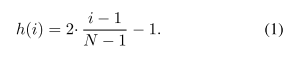
给定索引
i
i
i,通过下式得高斯权重:

其中
μ
∈
I
\mu \in I
μ∈I,
σ
\sigma
σ为超参数,
N
o
r
m
(
)
Norm()
Norm()用于将值缩到
[
0
,
1
]
[0, 1]
[0,1]。
与ViGA[6]不同,我们利用2D - TAN特性生成不同时长的候选时刻。给定视频特征
F
1
d
∈
R
N
×
d
v
F^{1d} \in \mathbb{R}^{N×d_v}
F1d∈RN×dv,编码为二维特征图
F
∈
R
N
×
N
×
d
F \in \mathbb{R}^{N×N×d}
F∈RN×N×d(见图4,
F
i
j
F_{ij}
Fij表示从
i
i
i到
j
j
j的时刻特征,
i
≤
j
i \leq j
i≤j时时刻有效)。然后提出三元组采样策略,为候选时刻生成更合理权重,对起始位置
i
i
i和结束位置
j
j
j的时刻,其高斯先验权重:
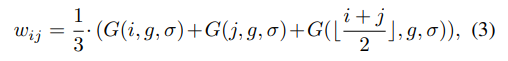
含目标时刻但时长较长的时刻权重较低。
为纠正标注偏差,引入语义一致性先验校准候选时刻的高斯先验权重
w
i
j
w_{ij}
wij。给定查询特征
f
s
∈
R
d
f^s \in \mathbb{R}^d
fs∈Rd和候选时刻特征
F
∈
R
N
×
N
×
d
F \in \mathbb{R}^{N×N×d}
F∈RN×N×d,计算语义一致性分数:
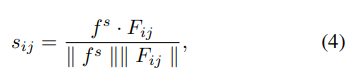
( ∥ ⋅ ∥ \|\cdot\| ∥⋅∥为 l 2 l_2 l2 - 范数),用其校正高斯权重得新先验权重 p i j = w i j ⋅ s i j p_{ij} = w_{ij} \cdot s_{ij} pij=wij⋅sij。
时态语句定位目标是学习跨模态嵌入空间,使查询语句特征与对应时刻特征对齐,远离不相关视频时刻特征。受[31, 17]启发,提出语义对齐组对比学习模块(SA - GCL),逐渐挖掘与查询语义最对齐的候选时刻。具体先依新先验
p
i
j
p_{ij}
pij从
F
F
F中采样前
k
k
k个候选时刻作查询
f
s
f^s
fs的正键,记为
F
p
=
{
F
i
j
∣
1
≤
i
≤
j
≤
N
}
∈
R
k
×
d
F^p = \{F_{ij} | 1 \leq i \leq j \leq N\} \in \mathbb{R}^{k×d}
Fp={Fij∣1≤i≤j≤N}∈Rk×d,同时采样对应时刻的高斯权重
W
p
=
{
w
i
j
∣
1
≤
i
≤
j
≤
N
}
∈
R
k
W^p = \{w_{ij} | 1 \leq i \leq j \leq N\} \in \mathbb{R}^k
Wp={wij∣1≤i≤j≤N}∈Rk。再从视频内收集不含扫视
g
g
g的其他候选时刻和同一批次其他视频的所有候选时刻作负键,记为
F
n
=
{
F
i
j
∣
1
≤
i
≤
j
≤
N
}
∈
R
N
n
×
d
F^n = \{F_{ij} | 1 \leq i \leq j \leq N\} \in \mathbb{R}^{N_n×d}
Fn={Fij∣1≤i≤j≤N}∈RNn×d(
N
n
N_n
Nn为负时刻数量)。SA - GCL目标为:
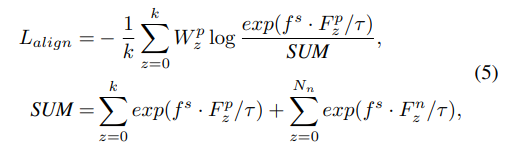
( τ \tau τ为温度缩放因子)。SA - GCL在联合嵌入空间最大化查询 f s f^s fs与正时刻 F p F^p Fp的相似度,推开负对,不同正时刻有相应先验权重 W z p W_z^p Wzp,可避免被不准确时刻主导,倾向挖掘与目标时刻重叠大的候选时刻。
3.3. Dynamic Gaussian prior Adjustment
为进一步减轻标注偏差并表征复杂目标时刻,提出动态高斯先验调整模块(DGA)。用多个不同中心的高斯函数建模目标时刻局部分布,聚合逼近目标时刻分布。
给定视频特征
F
1
d
∈
R
N
×
d
u
F^{1d} \in \mathbb{R}^{N×d_u}
F1d∈RN×du和扫视标注
g
g
g,计算其他位置
i
i
i与
g
g
g的相关性:
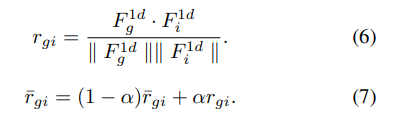
为使相关性分数稳定,用动量因子
α
\alpha
α更新
r
‾
g
i
\overline{r}_{gi}
rgi(首个训练epoch时
r
‾
g
i
=
r
g
i
\overline{r}_{gi} = r_{gi}
rgi=rgi)。根据相关性
{
r
g
i
}
\{r_{gi}\}
{rgi}挖掘目标时刻潜在局部中心,用阈值
T
1
T_1
T1过滤候选位置得扫视
g
g
g的掩码
M
g
∈
{
0
,
1
}
N
M_g \in \{0, 1\}^N
Mg∈{0,1}N:
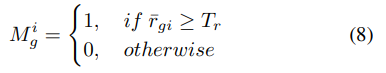
用掩码动态调整高斯先验:
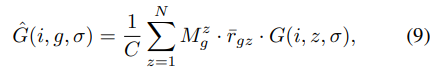
(
C
C
C为掩码
M
g
M_g
Mg总和),用
G
^
(
i
,
g
,
σ
)
\hat{G}(i, g, \sigma)
G^(i,g,σ)替换公式(3)中的
G
(
i
,
g
,
σ
)
G(i, g, \sigma)
G(i,g,σ)得动态高斯先验权重。与ViGA相比,DGA更灵活,能自适应调整高斯分布中心,减轻标注偏差,提供更可靠先验权重。多个高斯分布适合建模多事件复杂目标时刻(见图3),DGA能基于扫视
g
g
g特征自挖掘相邻帧拓宽高斯权重高区域,生成与目标时刻对齐的先验权重,使SA - GCL获高质量正时刻,促进跨模态语义对齐学习和目标时刻定位。
4. Experiments
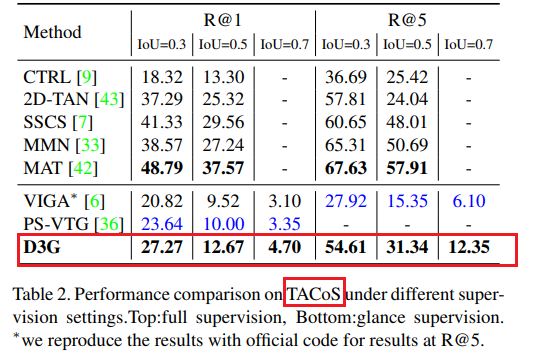
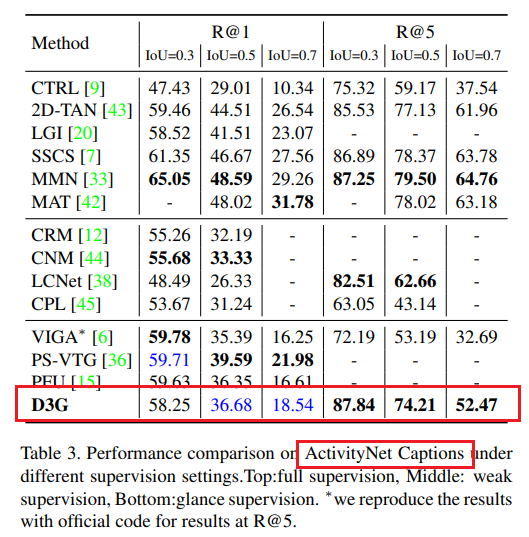
为验证D3G的有效性,我们在三个公开数据集上进行大量实验:Charades - STA[9]、TACoS[9]和ActivityNet Captions[16]。
4.1数据集
- Charades - STA基于数据集Charades[24]构建用于时态语句定位,包含12,408个训练和3,720个测试的时刻 - 句子对。
- TACoS从MPII烹饪复合活动视频语料库[22]中选127个视频,按[9]的标准分割,分别有10,146个训练、4,589个验证和4,083个测试的时刻 - 句子对。我们报告测试集评估结果以公平比较。
- ActivityNet Captions原本用于视频字幕,近期引入时态语句定位,包含37,417个训练、17,505个验证和17,031个测试的时刻 - 句子对。我们按[43, 33]报告评估结果。
特别地,我们对训练集采用[6]发布的扫视标注,将时间边界替换为在原始时间边界内均匀采样的时间戳 g g g。
4.2评估指标和实现细节
- 评估指标:遵循先前工作[9, 43],我们用指标“R@ n , I o U = m n, IoU = m n,IoU=m”评估模型,即前 n n n个结果中至少一个的交并比(IoU)大于 m m m的百分比。具体地,对于Charades - STA,我们报告 m ∈ { 0.5 , 0.7 } m \in \{0.5, 0.7\} m∈{0.5,0.7}的结果;对于TACoS和ActivityNet Captions,报告 m ∈ { 0.3 , 0.5 , 0.7 } m \in \{0.3, 0.5, 0.7\} m∈{0.3,0.5,0.7}的结果;对于所有数据集, n ∈ { 1 , 5 } n \in \{1, 5\} n∈{1,5}。
- 实现细节:在本工作中,我们的主框架从MMN[33]扩展而来,多数实验设置保持相同。为公平比较,按[33]对所有数据集采用现成视频特征(Charades用VGG特征,TACoS和ActivityNet Captions用C3D特征)。具体地,联合特征空间维度 d d d设为256, τ \tau τ设为0.1。在SA - GCL中,Charades、TACoS和ActivityNet Captions的 k k k分别设为10、20和20。公式(2)中的 σ \sigma σ分别设为0.3、0.2和0.6。在DGA中, T r T_r Tr和 α \alpha α分别设为0.9和0.7。
4.3与现有技术比较
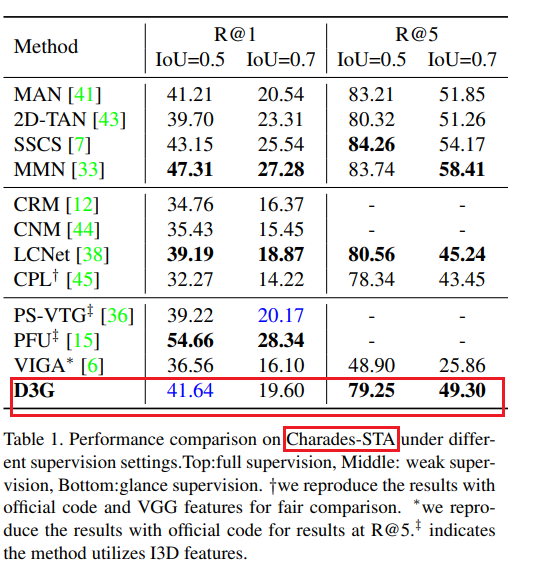
为提供全面分析,我们将提出的D3G与全监督、弱监督和扫视监督方法进行比较。如表1、表2和表3所示,D3G在扫视监督下于三个数据集上取得了极具竞争力的结果,并且与全监督方法相比实现了可比的性能。请注意,我们分别突出显示了每个设置下的最佳值。基于实验结果,我们可以得出以下结论:
-
扫视标注为以更低标注成本实现更好的时态语句定位性能提供了更多潜力。尽管由于引入额外监督,直接将D3G与其他弱监督方法进行比较并不完全公平,但D3G在标注成本增加极少的情况下显著超越了大多数弱监督方法。由于PS - VTG和PFU采用了更强大的I3D特征,它们在Charades - STA上明显优于D3G。然而,在更具挑战性的TACoS数据集上,使用相同特征时D3G优于PS - VTG。此外,弱监督方法通常不在TACoS上进行测试,因为该数据集中的视频很长且包含大量目标时刻。然而,如表2所示,D3G在TACoS上取得了有前景的性能,并且大幅优于ViGA。
-
与ViGA相比,D3G有效地利用了扫视标注提供的信息,并挖掘出更多高质量的时刻用于训练。由于固定尺度高斯函数和固定滑动窗口的限制,ViGA无法挖掘准确的候选时刻以学习良好对齐的联合嵌入空间。相反,D3G生成了广泛的候选时刻,并采样了一组可靠的候选时刻用于组对比学习。与ViGA相比,D3G在Charades - STA上的R@1 IoU = 0.5和R@1 IoU = 0.7指标上分别取得了5.08%和3.5%的显著增益。特别是,在三个数据集的R@5指标上都获得了显著改进。
-
D3G大幅缩小了弱监督/扫视监督方法与全监督方法之间的性能差距。具体而言,D3G在TACoS和ActivityNet Captions上已经超越了先前的方法(如CTRL)。不可否认,与最先进的全监督方法(如MMN)相比仍存在不可忽视的差距。请注意,D3G非常简洁,并且没有嵌入辅助模块(如[45]中使用的MLM)。D3G仍可通过一些互补模块进行增强。
4.4消融研究
为验证所提出的D3G不同组件的有效性并研究超参数的影响,我们在Charades - STA上进行了消融研究。
-
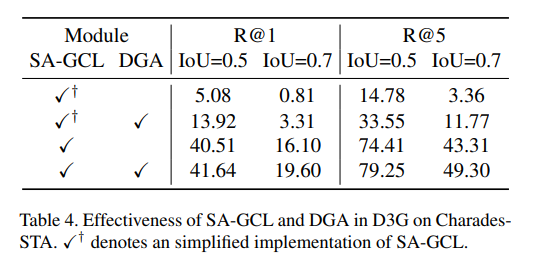
SA - GCL和DGA的有效性:由于 L a l i g n L_{align} Lalign是D3G的唯一损失,为验证SA - GCL的有效性,我们需要将SA - GCL模块简化为基线。具体来说,我们仅采样前1个正时刻来计算正常对比损失(退化为简化的MMN),如表4第一行所示。然而,前1个时刻往往是最短的时刻,与目标时刻的重叠较小,这是由2D - TAN的内在特性决定的。因此,基线的性能无疑非常差,这表明D3G的主要改进并非来自MMN的主干网络。这种现象促使我们在SA - GCL中采样一组正时刻。使用完整的SA - GCL,模型获得了显著的性能提升。此外,我们引入DGA以减轻标注偏差并对由多个事件组成的一些复杂目标时刻进行建模。配备DGA后,D3G和简化的D3G都取得了明显的性能改进。
-
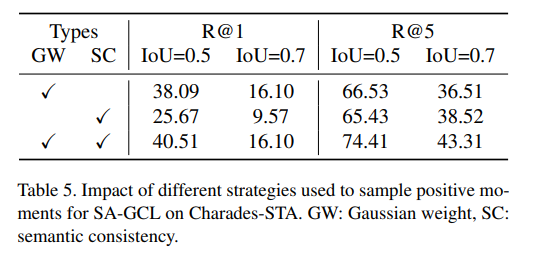
采样策略的影响:在SA - GCL中,采样一组可靠的正时刻非常重要。我们分别研究了两个先验的影响:高斯权重和语义一致性。如表5第一行所示,我们根据高斯先验权重采样前k个正时刻。另一种方案是根据候选时刻与查询语句之间的语义一致性分数采样前k个正时刻。然而,这两种方法都获得了次优性能。这是因为由于标注偏差,高斯先验权重并不总是可靠的,并且语义一致性分数高度依赖于特征的稳定性。因此,我们最终融合这两个先验以获得相对可靠的先验。如表5第三行所示,在同时使用这两个先验后获得了明显的性能提升,这表明这两个先验确实相互补充。
-
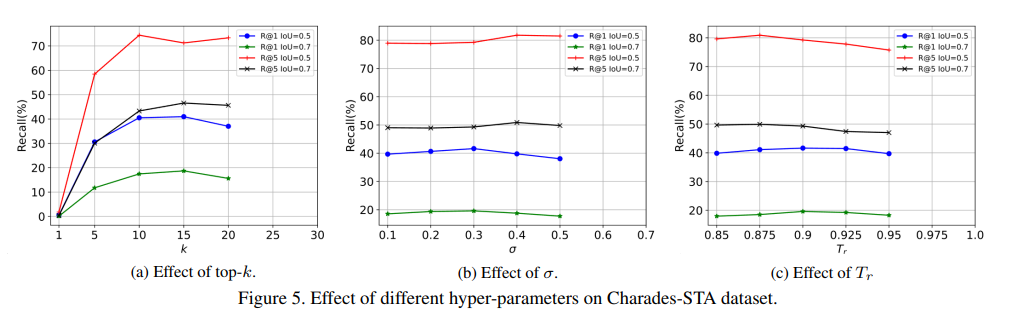
不同超参数的影响:如图5所示,我们研究了D3G中的三个关键超参数。如表4所验证的,采样足够的潜在正时刻有利于挖掘用于训练的目标时刻。如图5(a)所示,随着k的增加,性能增益明显增加。然而,在k达到特定值后,它开始下降。我们认为选择过多的正时刻往往会引入一些假正时刻,从而降低性能。我们最终将Charades - STA的k设置为10,这在性能和计算成本之间取得了良好的平衡。对于超参数 σ \sigma σ,它本质上决定了高斯分布的宽度。较大的 σ \sigma σ可以很好地表征较长持续时间的目标时刻,反之亦然。我们将 σ \sigma σ从0.1变化到0.5,并观察到0.3的值相对适合Charades - STA数据集。对于公式(8)中的超参数 T r T_r Tr,它控制动态高斯先验调整的程度。我们在相关性阈值约为0.9的情况下进行实验。较小的阈值往往会引入干扰,而较大的阈值无法找到语义一致的相邻帧。如图5(c)所示,适中的阈值0.9相对平衡了上述困境。
 - 容忍极端扫视标注
- 容忍极端扫视标注
为了验证处理极端扫视标注的能力,我们首先生成极端扫视标注,其中仅在接近开始/结束时间戳的位置采样作为扫视 g g g。如表6所示, V i G A + ViGA^+ ViGA+和 D 3 G + D3G^+ D3G+在某些指标(如R@1 IoU = 0.5)上都面临性能下降。然而,与ViGA相比,D3G的性能相对稳定,这表明D3G确实能够减轻标注偏差。
4.5定性分析
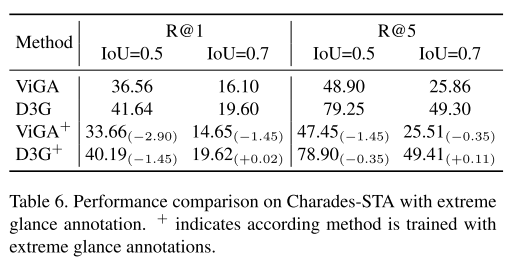
为了清晰地揭示我们方法的有效性,我们可视化了来自Charades - STA数据集和ActivityNet Captions数据集测试集的一些定性示例。如图6所示,与ViGA相比,所提出的D3G实现了对目标时刻更准确的定位。具体来说,ViGA无法很好地对齐视觉内容和语义信息,并且容易受到无关内容的干扰,这可能是由标注偏差引起的。相反,D3G利用SA - GCL和DGA减轻了标注偏差,使其能够将查询与相应时刻很好地对齐。此外,DGA采用多个高斯函数来建模目标时刻,这有利于表示由多个事件组成的复杂时刻的完整分布。如图6(b)所示,D3G仍然有效地定位了复杂时刻,而ViGA错过了最后一个事件“将其放在盘子上展示”。更多定性示例将在补充材料中提供。
5. 结论
在本研究中,我们研究了最近提出的任务——基于扫视标注的时态语句定位。在此设置下,我们提出了基于动态高斯先验的扫视标注定位框架D3G。具体而言,D3G由语义对齐组对比学习模块(SA - GCL)和动态高斯先验调整模块(DGA)组成。SA - GCL旨在挖掘广泛的正时刻,并在联合嵌入空间中对齐正语句 - 时刻对。DGA通过使用多个高斯函数动态调整高斯先验,有效地减轻了标注偏差并对由多个事件组成的复杂查询进行建模,从而提高了定位精度。大量实验表明,D3G显著缩小了全监督方法和扫视监督方法之间的性能差距。在没有过多视觉 - 语言交互的情况下,D3G为低成本扫视标注下具有挑战性的时态语句定位提供了一个简洁的框架和新的见解。
局限性
尽管D3G在扫视标注下取得了有前景的改进,但它仍然存在一些局限性。在本文中,DGA通过多个固定尺度高斯函数的组合来调整高斯先验。它无法缩小高斯分布以适应小的时刻。预计在未来的工作中探索动态可学习的高斯函数来建模任意持续时间的时刻。此外,SA - GCL的采样策略仍然不够灵活,无法采样准确的正时刻。
附录
A. SA - GCL和DGA的有效性
为进一步分析SA - GCL和DGA的有效性,我们在ActivityNet Captions和TACoS数据集上提供了更详细的实验结果,如表7和表8所示。遵循主手稿,我们将SA - GCL的简化实现视为基线。配备完整的SA - GCL后,我们的模型在ActivityNet Captions和TACoS上都取得了显著的改进。这种现象表明,为对比学习采样足够的正时刻非常重要。此外,我们进一步引入DGA模块以减轻标注偏差并对复杂目标时刻进行建模。由于ActivityNet Captions数据集有大量由多个事件组成的复杂查询句子,D3G在ActivityNet Captions上获得了显著的性能提升(例如,在R@5 IoU = 0.7时为9.03%)。然而,由于目标时刻的密集分布,TACoS对D3G来说仍然具有挑战性。
B. 不同超参数的影响
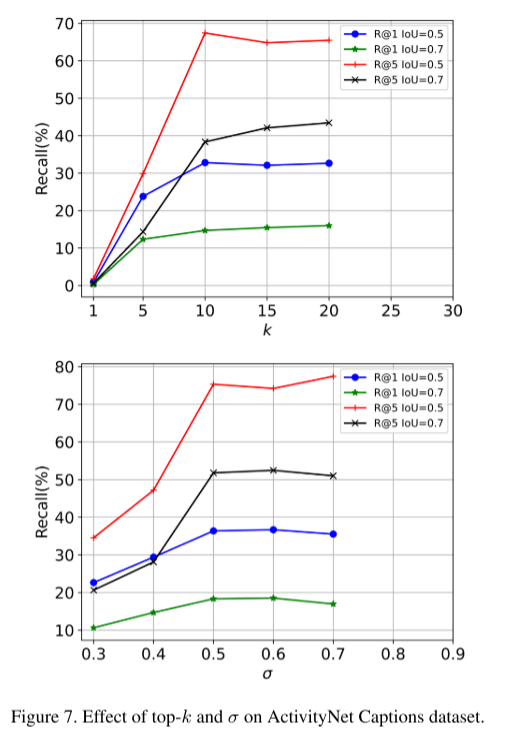
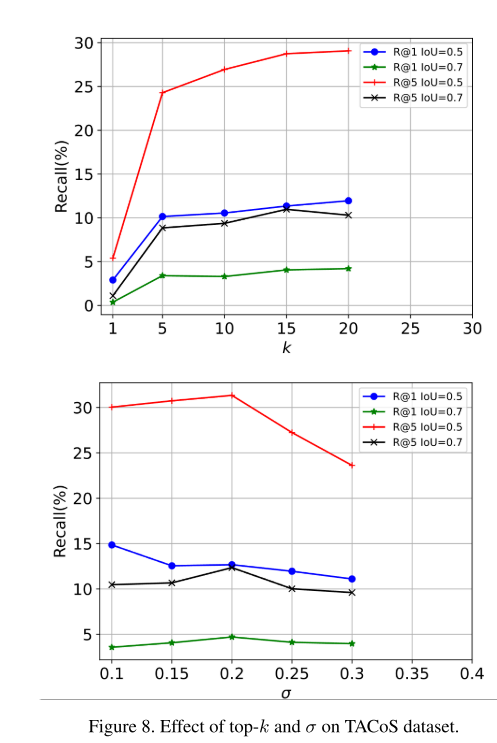
在本节中,我们研究了两个关键超参数对ActivityNet Captions和TACoS数据集的影响。如图7和图8所示,我们报告了四个指标的性能变化。对于top - k,随着k的增加,性能急剧增加。然而,在k达到15之后,性能逐渐达到饱和。我们最终为ActivityNet Captions和TACoS都选择 k = 20 k = 20 k=20。对于 σ \sigma σ,ActivityNet Captions数据集倾向于较大的值,而较小的值更适合TACoS数据集。这是因为前者包含大量长目标时刻,而后者包含许多短目标时刻。如图7和图8所示,我们最终分别为ActivityNet Captions和TACoS选择 σ = 0.6 \sigma = 0.6 σ=0.6和 σ = 0.2 \sigma = 0.2 σ=0.2以获得最佳性能。
C. 定性分析
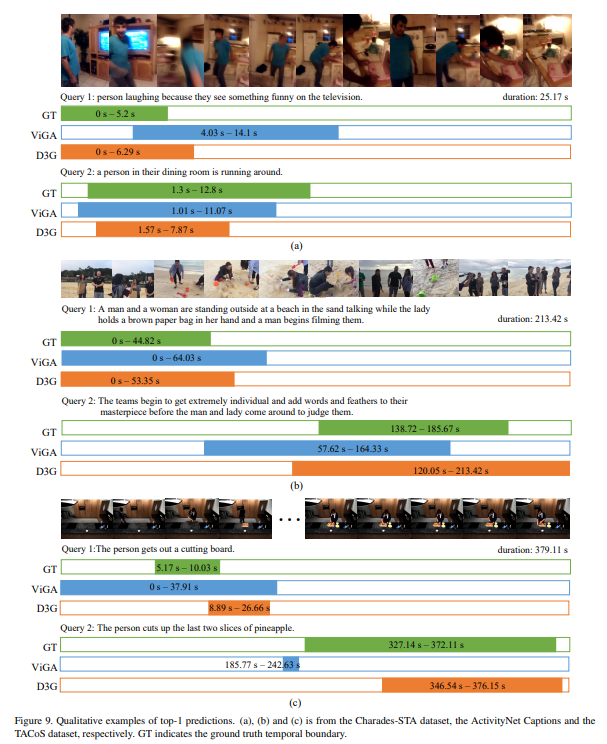
在本节中,我们提供了来自Charades - STA数据集、ActivityNet Captions数据集和TACoS数据集测试集的更多定性示例。对于每个视频,我们选择两个查询进行分析。如图9(a)所示,对于查询1,D3G准确地定位了目标时刻,而ViGA忽略了目标时刻前面的原因。然而,在某些情况下,如查询2,D3G不如ViGA。对于ActivityNet Captions中的复杂查询,D3G仍然定位了一个与目标时刻有较大重叠的时刻。由于句子级特征可能会丢失一些关于特定事件的信息,对于一些复杂查询,D3G无法感知准确的边界,如图9(b)查询2所示。预计在未来探索针对由多个事件组成的查询的事件级特征。TACoS是最具挑战性的数据集,其中视频持续时间长且包含大量时刻 - 句子对。如图9(c)所示,对于查询1,我们观察到D3G无法从长视频中定位一个短持续时间的简单查询。然而,对于查询2,D3G准确地定位了长持续时间的目标时刻。请注意,D3G很好地关注了查询中的“最后两个”数字,而ViGA未能关注此类信息并定位了不相关的时刻。如图9所示,D3G优于ViGA,这与主手稿中的实验结果一致。然而,D3G仍然存在一些局限性,需要在未来进行改进。

















 935
935

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









