






点击下方卡片,关注「计算机视觉工坊」公众号
选择星标,干货第一时间送达
作者:Jinglin Xu | 编辑:计算机视觉工坊
添加小助理:dddvision,备注:方向+学校/公司+昵称,拉你入群。文末附行业细分群
扫描下方二维码,加入3D视觉知识星球,星球内凝聚了众多3D视觉实战问题,以及各个模块的学习资料:近20门视频课程(星球成员免费学习)、最新顶会论文、计算机视觉书籍、优质3D视觉算法源码等。想要入门3D视觉、做项目、搞科研,欢迎扫码加入!

1.读者个人理解
这篇文章介绍了一种名为FinePOSE的新方法,用于3D人体姿势估计。该方法包括三个主要组成部分:FPP、FPC和PTS。FPP用于学习精细化的部件感知提示,以提供对每个人体部位的精确指导;FPC用于建立可学习的部件感知提示与姿势之间的精细通信,增强去噪能力;PTS则引入时间戳信息到去噪过程中,增强在每个噪声水平上的预测细化能力。通过在两个基准数据集上的实验,该方法显示出超越现有方法的性能,同时还将其扩展到了复杂的多人场景中。
2. 导读
三维人体姿势估计(3D HPE)任务使用2D图像或视频来预测人体关节在三维空间中的坐标。尽管深度学习方法在最近取得了进展,但它们大多忽视了结合可访问文本和人类自然可行知识的能力,从而错过了指导3D HPE任务的有价值的隐式监督。此外,先前的研究往往从整个人体的角度研究这一任务,忽视了隐藏在不同身体部位中的细粒度指导。为此,我们提出了一种基于扩散模型的新的细粒度提示驱动去噪器,用于3D HPE,名为FinePOSE。它由三个核心模块组成,增强了扩散模型的逆过程:(1)细粒度部位感知提示学习(FPP)模块通过结合可访问的文本和人体部位的自然可行知识以及可学习的提示来构建细粒度的部位感知提示,以建模隐式指导。(2)细粒度提示-姿势通信(FPC)模块建立了学习到的部位感知提示和姿势之间的细粒度通信,以提高去噪质量。(3)提示驱动的时间戳风格化(PTS)模块集成了学习到的提示嵌入和与噪声水平相关的时间信息,以使每个去噪步骤能够进行自适应调整。在公共单人姿势估计数据集上进行的大量实验表明,FinePOSE优于最先进的方法。我们进一步将FinePOSE扩展到多人姿势估计。在EgoHumans数据集上实现的34.3mm平均MPJPE表明了FinePOSE处理复杂多人场景的潜力。
3. 效果展示
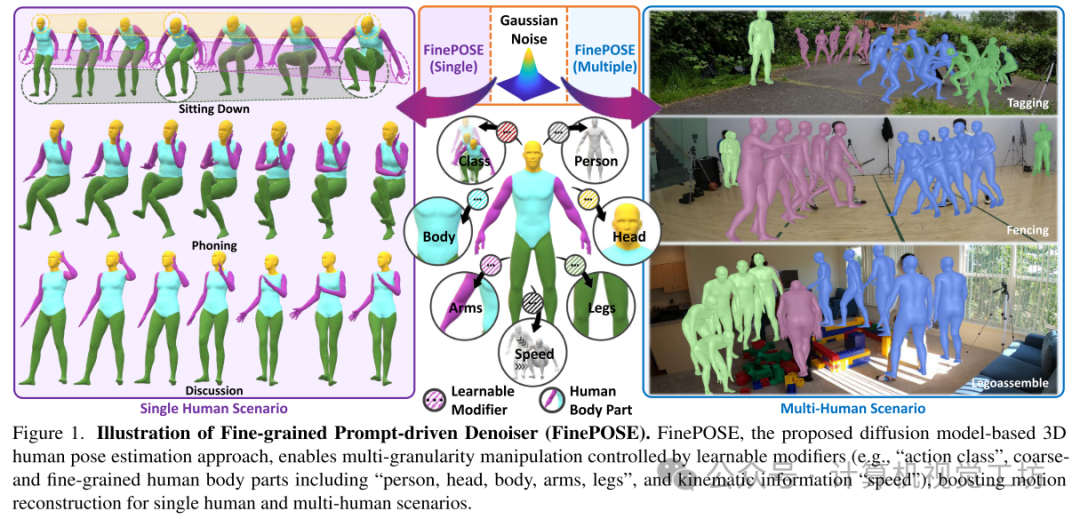
细粒度提示驱动的去噪器(FinePOSE)示意图。FinePOSE是一种基于扩散模型的3D人体姿势估计方法,可以通过可学习的修饰器(例如,“动作类别”,包括“人员、头部、身体、手臂、腿部”的粗细粒度人体部位以及“速度”等)实现多粒度操作,从而增强了单人和多人场景的运动重建能力。
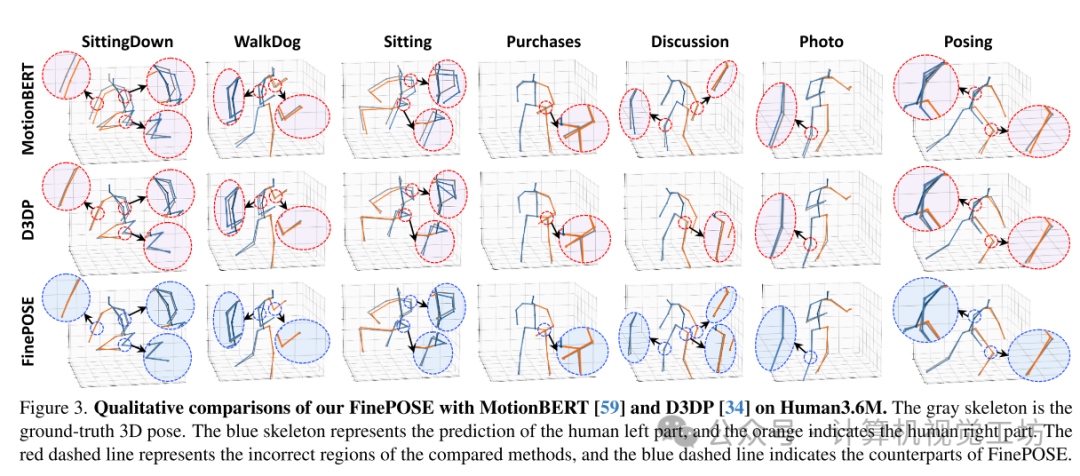
我们FinePOSE与MotionBERT和D3DP在Human3.6M数据集上的定性比较。灰色骨架是真实的3D姿势。蓝色骨架代表人体的左侧部分,橙色表示人体的右侧部分。红色虚线表示比较方法的错误区域,蓝色虚线表示FinePOSE的对应部分。
4. 主要贡献
我们提出了一种新的细粒度部位感知提示学习机制,与扩散模型相结合,具有人体部位可控的高质量生成能力,有利于3D人体姿势估计任务。
我们的FinePOSE编码了关于动作类别、粗粒度和细粒度的人体部位以及运动学信息的多粒度信息,并建立了可学习部位感知提示和姿势之间的细粒度通信,以增强去噪能力。
大量实验证明,我们的FinePOSE在Human3.6M和MPIINF-3DHP数据集上取得了显著的改进,并达到了最先进水平。对EgoHumans的更多实验表明FinePOSE处理复杂多人场景的潜力。
5. 基本原理是啥?
这篇文章的基本原理是使用了一种称为FinePOSE的方法来进行3D人体姿势估计。FinePOSE结合了扩散模型和细粒度提示驱动去噪器,通过引入细粒度的部位感知提示学习机制,提高了3D人体姿势估计的准确性和质量。
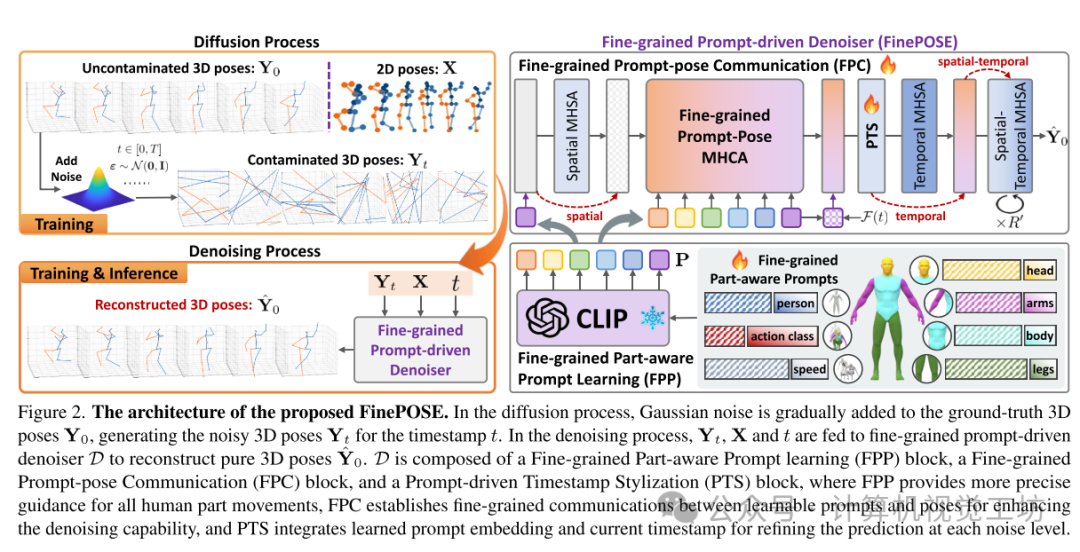
首先,文章介绍了扩散模型,这是一种生成模型,通过逐步向原始数据添加噪声,然后再去噪,来重建原始数据。作者利用扩散模型的文本可控去噪过程,提出了FinePOSE方法。FinePOSE通过三个核心模块来生成精确的3D人体姿势:细粒度部位感知提示学习(FPP)、细粒度提示-姿势通信(FPC)和提示驱动时间戳风格化(PTS)。
在FPP模块中,FinePOSE设计了一个学习部位感知提示的机制,它将动作类别、人体部位的粗细粒度和运动信息编码到提示嵌入空间中。这些提示嵌入与姿势特征相结合,用于后续处理。FPC模块用于建立学习部位感知提示和姿势之间的细粒度通信,以提高去噪质量。PTS模块则将时间戳嵌入到生成过程中,以处理不同噪声水平的3D姿势。
文章最后介绍了FinePOSE的训练和推理过程。在训练中,通过最小化均方误差损失来优化整个框架。在推理中,通过从单位高斯分布中采样来生成初始3D姿势,然后通过迭代的方式,将生成的姿势用于下一个时间戳的输入,直到获得最终的3D姿势估计。
6. 实验结果
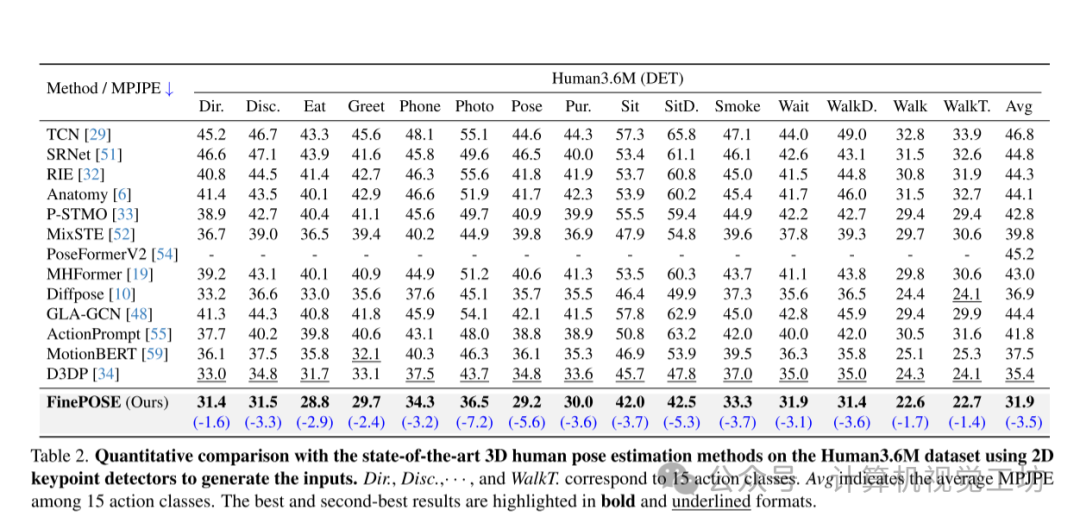
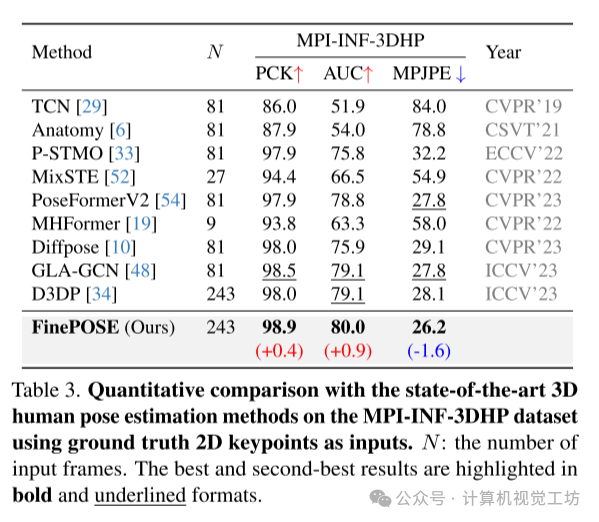
本文的实验主要围绕着作者提出的FinePOSE方法展开,该方法是一种用于3D人体姿势估计的新型方法:
数据集和评估指标:作者在实验中使用了三个主要数据集:Human3.6M、MPI-INF-3DHP和EgoHumans。Human3.6M包含了大量的RGB图像和精确的3D关节标注,MPI-INF-3DHP提供了同步的RGB视频序列和准确的3D关节标注,EgoHumans包含了多人运动的自我-外我视频。评估指标主要包括平均关节位置误差(MPJPE)、Procrustes MPJPE(P-MPJPE)、正确估计关键点的百分比(PCK)以及曲线下面积(AUC)等。
实现细节:作者使用MixSTE作为FinePOSE的骨干网络,CLIP作为冻结的文本编码器。FinePOSE的训练轮数为100,批量大小为4,采用AdamW优化器进行训练。
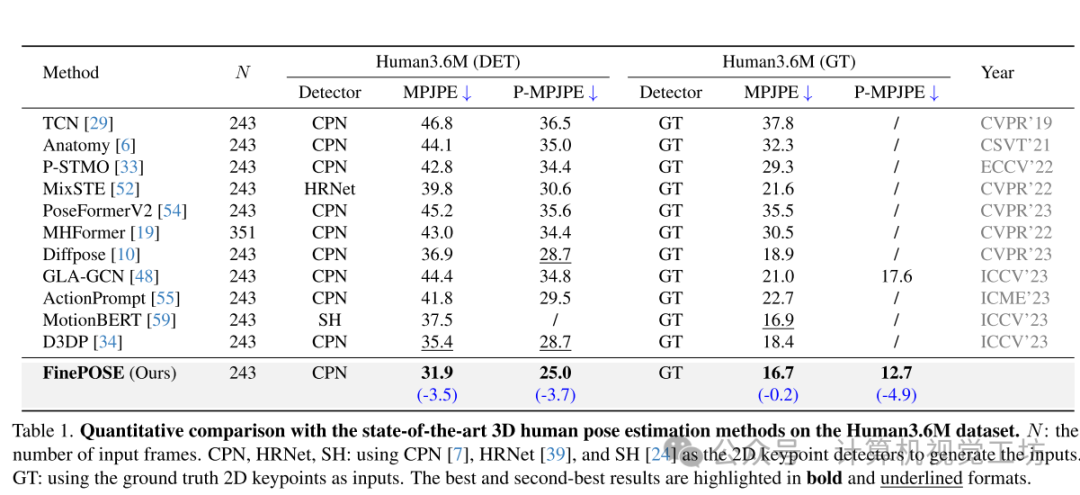
与现有方法的比较:在Human3.6M数据集上,FinePOSE在使用检测到的2D关键点作为输入时取得了显著的性能提升,超过了现有的方法。在MPI-INF-3DHP数据集上,FinePOSE相比GLA-GCN等现有方法,MPJPE降低了1.6mm,PCK提高了0.4%,AUC提高了0.9%。
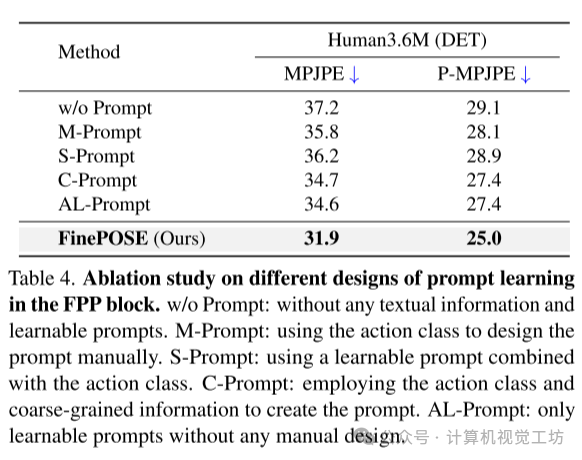
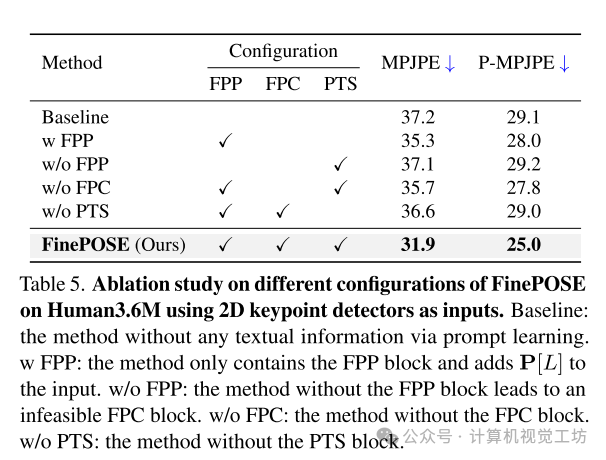
消融实验:作者进行了一系列消融实验,评估了FinePOSE中不同模块的影响。例如,在FinePOSE中的Fine-grained Part-aware Prompt Learning(FPP)模块中,作者设计了多种版本的FPP模块,包括不使用Prompt、手动设计Prompt、使用学习Prompt等。实验结果表明,FinePOSE的FPP模块在提高MPJPE和P-MPJPE方面发挥了关键作用。
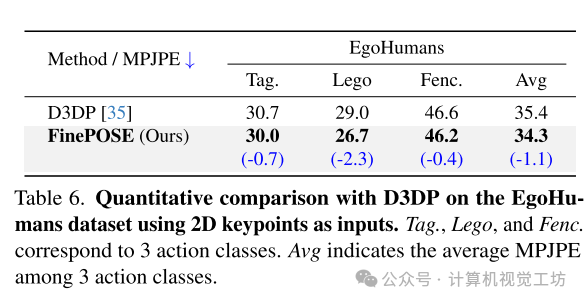
多人姿势估计扩展:作者扩展了FinePOSE以适用于多人场景,通过对EgoHumans数据集的实验验证了该扩展的有效性,并与D3DP方法进行了对比。
可视化:作者对比了D3DP、MotionBERT和FinePOSE在Human3.6M数据集上的可视化结果。结果显示,FinePOSE在一些动作中的表现优于其他方法,特别是在复杂形状的动作中,如坐下和躺下。
7. 总结 & 未来工作
本文提出了FinePOSE,一种新的用于3D人体姿势估计的精细化提示驱动去噪器。FinePOSE由FPP、FPC和PTS块组成。FPP学习了精细化的部件感知提示,为每个人体部位提供精确的指导。FPC建立了可学习的部件感知提示与姿势之间的精细化通信,增强了去噪能力。PTS将时间戳信息引入到去噪过程中,增强了在每个噪声水平上细化预测的能力。在两个基准数据集上的实验结果表明,FinePOSE超越了现有方法。我们还将FinePOSE从单人场景扩展到多人场景,展示了我们的模型在复杂多人场景中的良好表现。
FinePOSE并非专门设计用于多人场景。基于扩散模型的3D人体姿势估计方法在计算上相对昂贵。
8. 论文信息
[1]FinePOSE: Fine-Grained Prompt-Driven 3D Human Pose Estimation via Diffusion Models
计算机视觉工坊交流群
目前我们已经建立了3D视觉方向多个社群,包括2D计算机视觉、大模型、工业3D视觉、SLAM、自动驾驶、三维重建、无人机等方向,细分群包括:
2D计算机视觉:图像分类/分割、目标/检测、医学影像、GAN、OCR、2D缺陷检测、遥感测绘、超分辨率、人脸检测、行为识别、模型量化剪枝、迁移学习、人体姿态估计等
大模型:NLP、CV、ASR、生成对抗大模型、强化学习大模型、对话大模型等
工业3D视觉:相机标定、立体匹配、三维点云、结构光、机械臂抓取、缺陷检测、6D位姿估计、相位偏折术、Halcon、摄影测量、阵列相机、光度立体视觉等。
SLAM:视觉SLAM、激光SLAM、语义SLAM、滤波算法、多传感器融合、多传感器标定、动态SLAM、MOT SLAM、NeRF SLAM、机器人导航等。
自动驾驶:深度估计、Transformer、毫米波|激光雷达|视觉摄像头传感器、多传感器标定、多传感器融合、自动驾驶综合群等、3D目标检测、路径规划、轨迹预测、3D点云分割、模型部署、车道线检测、BEV感知、Occupancy、目标跟踪、端到端自动驾驶等。
三维重建:3DGS、NeRF、多视图几何、OpenMVS、MVSNet、colmap、纹理贴图等
无人机:四旋翼建模、无人机飞控等
除了这些,还有求职、硬件选型、视觉产品落地、最新论文、3D视觉最新产品、3D视觉行业新闻等交流群
添加小助理: dddvision,备注:研究方向+学校/公司+昵称(如3D点云+清华+小草莓), 拉你入群。

3D视觉学习知识星球
3D视觉从入门到精通知识星球、国内成立最早、6000+成员交流学习。包括:星球视频课程近20门(价值超6000)、项目对接、3D视觉学习路线总结、最新顶会论文&代码、3D视觉行业最新模组、3D视觉优质源码汇总、书籍推荐、编程基础&学习工具、实战项目&作业、求职招聘&面经&面试题等等。欢迎加入3D视觉从入门到精通知识星球,一起学习进步。
3DGS、NeRF、结构光、相位偏折术、机械臂抓取、点云实战、Open3D、缺陷检测、BEV感知、Occupancy、Transformer、模型部署、3D目标检测、深度估计、多传感器标定、规划与控制、无人机仿真、三维视觉C++、三维视觉python、dToF、相机标定、ROS2、机器人控制规划、LeGo-LAOM、多模态融合SLAM、LOAM-SLAM、室内室外SLAM、VINS-Fusion、ORB-SLAM3、MVSNet三维重建、colmap、线面结构光、硬件结构光扫描仪,无人机等。
3D视觉相关硬件
| 图片 | 说明 | 名称 |
|---|---|---|
 | 硬件+源码+视频教程 | 精迅V1(科研级))单目/双目3D结构光扫描仪 |
 | 硬件+源码+视频教程 | 深迅V13D线结构光三维扫描仪 |
 | 硬件+源码+视频教程 | 御风250无人机(基于PX4) |
 | 硬件+源码 | 工坊智能ROS小车 |
 | 配套标定源码 | 高精度标定板(玻璃or大理石) |
| 添加微信:cv3d007或者QYong2014 咨询更多 | ||















 255
255

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









