






点击下方卡片,关注「计算机视觉工坊」公众号
选择星标,干货第一时间送达
作者:小张Tt,编辑:计算机视觉工坊
添加小助理:dddvision,备注:方向+学校/公司+昵称,拉你入群。文末附行业细分群
扫描下方二维码,加入3D视觉知识星球,星球内凝聚了众多3D视觉实战问题,以及各个模块的学习资料:近20门视频课程(星球成员免费学习)、最新顶会论文、3DGS系列、计算机视觉书籍、优质3D视觉算法源码等。想要入门3D视觉、做项目、搞科研,欢迎扫码加入!

计算机视觉的迅猛发展离不开数据集的支持,它们不仅为算法验证提供了标准化的评估平台,还推动了各种视觉任务的进展。
MS COCO (Microsoft Common Objects in Context)
下载地址:https://cocodataset.org/
MS COCO(Microsoft Common Objects in Context)数据集是一个大规模的目标检测、分割、关键点检测和描述数据集。该数据集包含328,000张图像。
数据集划分:
MS COCO数据集的第一个版本发布于2014年,包含164,000张图像,分为训练集(83,000张)、验证集(41,000张)和测试集(41,000张)。在2015年,发布了额外的81,000张测试图像,其中包括之前的测试图像以及40,000张新图像。
根据社区反馈,在2017年,训练集和验证集的划分从83K/41K变为118K/5K。新的划分使用了相同的图像和注释。2017年的测试集是2015年测试集的一个子集,包含41,000张图像。此外,2017年发布的版本还包含一个新的未注释数据集,包含123,000张图像。

注释:
目标检测:包含80个物体类别的边界框和每实例分割掩码,
图像描述:图像的自然语言描述(见MS COCO Captions),
关键点检测:包含超过200,000张图像和250,000个标注有关键点(如左眼、鼻子、右臀部、右脚踝)的实例(共17个可能的关键点),
事物图像分割:包含91个事物类别(如草、墙、天空)的每像素分割掩码(见MS COCO Stuff),
全景分割:包含80个物体类别(如人、自行车、大象)和91个事物类别(如草、天空、道路)子集的全景场景分割,
密集姿态:包含超过39,000张图像和56,000个标注有DensePose注释的实例——每个标注的人体实例都有一个实例ID,并且有一个在图像像素与模板3D模型之间的映射关系。
KITTI
下载地址:https://www.cvlibs.net/datasets/kitti/
KITTI(卡尔斯鲁厄理工学院和丰田技术研究所)是移动机器人和自动驾驶领域最受欢迎的数据集之一。它由各种传感器记录的数小时交通场景组成,包括高分辨率RGB、灰度立体相机和3D激光扫描仪。尽管该数据集非常受欢迎,但其本身并不包含语义分割的地面真值。然而,各种研究人员根据他们的需求手动标注了部分数据集。
Álvarez等人为道路检测挑战中的323张图像生成了地面真值,分为三个类别:道路、垂直和天空。Zhang等人为跟踪挑战中的252个(140用于训练,112用于测试)获取的图像——包括RGB图像和Velodyne扫描——标注了十个对象类别:建筑物、天空、道路、植被、人行道、汽车、行人、骑车人、标志/杆和围栏。Ros等人为视觉里程计挑战中的170张训练图像和46张测试图像标注了11个类别:建筑物、树木、天空、汽车、标志、道路、行人、围栏、杆、人行道和骑车人。

nuScenes
下载地址:https://www.nuscenes.org/
nuScenes 数据集是一个大规模的自动驾驶数据集。该数据集包含在波士顿和新加坡收集的1000个场景的3D边界框。每个场景持续20秒,并以2Hz的频率进行注释。这导致训练集共有28,130个样本,验证集有6,019个样本,测试集有6,008个样本。该数据集提供完整的自动驾驶车辆数据套件:32束激光雷达、6个摄像头和具有完整360°覆盖的雷达。3D目标检测挑战评估10个类别的性能:汽车、卡车、公共汽车、拖车、施工车辆、行人、摩托车、自行车、交通锥和障碍物。

Visual Genome
下载地址:https://homes.cs.washington.edu/~ranjay/visualgenome/index.html
Visual Genome 包含以多选方式设置的视觉问答数据。它由MSCOCO的101,174张图像组成,包含170万个问答对,平均每张图像有17个问题。与视觉问答数据集相比,Visual Genome在六种问题类型上呈现更均衡的分布:什么、在哪里、何时、谁、为什么和如何。Visual Genome数据集还提供了108,000张图像,密集地注释了对象、属性和关系。

LVIS
下载地址:https://www.lvisdataset.org/dataset
LVIS 是一个用于长尾实例分割的数据集。它在164,000张图像中为超过1000个物体类别提供了注释。

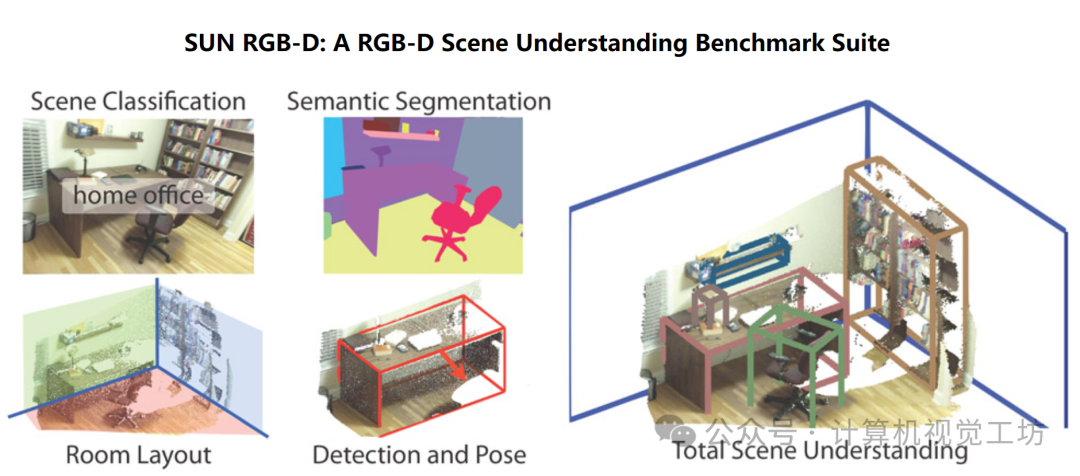
SUN RGBD
下载地址:https://rgbd.cs.princeton.edu/
SUN RGBD 数据集包含10335张真实的房间场景的RGB-D图像。每张RGB图像都有对应的深度图和分割图。多达700个物体类别被标注。训练集和测试集分别包含5285张和5050张图像。
Waymo Open Dataset
下载地址:https://waymo.com/open
Waymo Open Dataset 是由Waymo自动驾驶车辆在各种条件下收集的高分辨率传感器数据组成的。
目前,Waymo Open Dataset 包含1950个片段。作者计划在未来扩展该数据集。当前数据集包括:
1950个片段,每个片段20秒,以10Hz频率采集(共390,000帧),覆盖不同的地理位置和条件
传感器数据
1个中程激光雷达
4个短程激光雷达
5个摄像头(前方和侧面)
同步的激光雷达和摄像头数据
激光雷达到摄像头的投影
传感器校准和车辆姿态
标注数据
4类目标的标注 - 车辆、行人、骑行者、标志
1200个片段中高质量的激光雷达数据标注
1260万个带有跟踪ID的激光雷达数据3D边界框标注
1000个片段中高质量的摄像头数据标注
1180万个带有跟踪ID的摄像头数据2D边界框标注

BDD100K
下载地址:https://www.bdd100k.com/
数据集推动了视觉领域的进步,但现有的驾驶数据集在视觉内容和支持的任务方面贫乏,无法研究自动驾驶的多任务学习。研究人员通常限制于在一个数据集上研究一小部分问题,而现实世界的计算机视觉应用需要执行各种复杂性的任务。我们构建了BDD100K,这是最大的驾驶视频数据集,包含10万个视频和10个任务,用于评估图像识别算法在自动驾驶上的令人振奋的进展。该数据集具有地理、环境和天气的多样性,有助于训练出不易在新条件下出错的模型。基于这个多样化的数据集,我们建立了一个用于异构多任务学习的基准,并研究如何一起解决这些任务。我们的实验表明,现有模型需要特殊的训练策略才能执行如此异质的任务。BDD100K为未来在这一重要领域的研究打开了大门。更多详细信息请参见数据集主页。

MVTec AD
下载地址:https://www.mvtec.com/company/research/datasets/mvtec-ad/
MVTec AD 是一个用于基准测试异常检测方法的数据集,专注于工业检测。它包含超过5000张高分辨率图像,分为十五个不同的物体和纹理类别。每个类别包括一组无缺陷的训练图像和一个包含各种缺陷以及无缺陷图像的测试集。
有两个常用的指标:检测AUROC和分割(或像素级)AUROC。
检测(或分类)方法为每张输入测试图像输出一个浮点数(异常分数)。

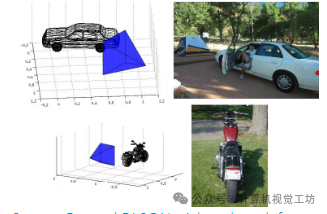
Pascal3D+
下载地址:https://cvgl.stanford.edu/projects/pascal3d.html
Pascal3D+多视角数据集包含野外图像,即展示高变异性的物体类别图像,这些图像在不受控制的环境中拍摄,场景杂乱,并呈现多种不同姿势。Pascal3D+包含从PASCAL VOC 2012数据集中选择的12个刚性物体类别。这些物体带有姿势信息标注(方位角、仰角和到相机的距离)。Pascal3D+还添加了来自ImageNet数据集的这12个类别的带有姿势标注的图像。
Foggy Cityscapes
下载地址:http://people.ee.ethz.ch/~csakarid/SFSU_synthetic/
Foggy Cityscapes 是一个合成的雾霾数据集,模拟真实场景中的雾霾效果。每张雾霾图像都是基于Cityscapes的清晰图像和深度图渲染而成。因此,Foggy Cityscapes 中的标注和数据分割均继承自Cityscapes。

本文仅做学术分享,如有侵权,请联系删文。
计算机视觉工坊交流群
目前我们已经建立了3D视觉方向多个社群,包括2D计算机视觉、大模型、工业3D视觉、SLAM、自动驾驶、三维重建、无人机等方向,细分群包括:
2D计算机视觉:图像分类/分割、目标/检测、医学影像、GAN、OCR、2D缺陷检测、遥感测绘、超分辨率、人脸检测、行为识别、模型量化剪枝、迁移学习、人体姿态估计等
大模型:NLP、CV、ASR、生成对抗大模型、强化学习大模型、对话大模型等
工业3D视觉:相机标定、立体匹配、三维点云、结构光、机械臂抓取、缺陷检测、6D位姿估计、相位偏折术、Halcon、摄影测量、阵列相机、光度立体视觉等。
SLAM:视觉SLAM、激光SLAM、语义SLAM、滤波算法、多传感器融合、多传感器标定、动态SLAM、MOT SLAM、NeRF SLAM、机器人导航等。
自动驾驶:深度估计、Transformer、毫米波|激光雷达|视觉摄像头传感器、多传感器标定、多传感器融合、自动驾驶综合群等、3D目标检测、路径规划、轨迹预测、3D点云分割、模型部署、车道线检测、BEV感知、Occupancy、目标跟踪、端到端自动驾驶等。
三维重建:3DGS、NeRF、多视图几何、OpenMVS、MVSNet、colmap、纹理贴图等
无人机:四旋翼建模、无人机飞控等
除了这些,还有求职、硬件选型、视觉产品落地、最新论文、3D视觉最新产品、3D视觉行业新闻等交流群
添加小助理: dddvision,备注:研究方向+学校/公司+昵称(如3D点云+清华+小草莓), 拉你入群。

3D视觉学习知识星球
3D视觉从入门到精通知识星球、国内成立最早、6000+成员交流学习。包括:星球视频课程近20门(价值超6000)、项目对接、3D视觉学习路线总结、最新顶会论文&代码、3D视觉行业最新模组、3D视觉优质源码汇总、书籍推荐、编程基础&学习工具、实战项目&作业、求职招聘&面经&面试题等等。欢迎加入3D视觉从入门到精通知识星球,一起学习进步。
3DGS、NeRF、结构光、相位偏折术、机械臂抓取、点云实战、Open3D、缺陷检测、BEV感知、Occupancy、Transformer、模型部署、3D目标检测、深度估计、多传感器标定、规划与控制、无人机仿真、三维视觉C++、三维视觉python、dToF、相机标定、ROS2、机器人控制规划、LeGo-LAOM、多模态融合SLAM、LOAM-SLAM、室内室外SLAM、VINS-Fusion、ORB-SLAM3、MVSNet三维重建、colmap、线面结构光、硬件结构光扫描仪,无人机等。
3D视觉相关硬件
| 图片 | 说明 | 名称 |
|---|---|---|
 | 硬件+源码+视频教程 | 精迅V1(科研级))单目/双目3D结构光扫描仪 |
 | 硬件+源码+视频教程 | 深迅V13D线结构光三维扫描仪 |
 | 硬件+源码+视频教程 | 御风250无人机(基于PX4) |
 | 低成本+体积小 +重量轻+抗高反 | YA001高精度3D相机 |
 | 抗高反+无惧黑色+半透明 | KW-D | 高精度3D结构光开源相机 |
 | 硬件+源码 | 工坊智能ROS小车 |
 | 配套标定源码 | 高精度标定板(玻璃or大理石) |
| 添加微信:cv3d007或者QYong2014 咨询更多 | ||















 420
420











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









