






来源:3DCV
添加小助理:cv3d008,备注:方向+学校/公司+昵称,拉你入群。文末附3D视觉行业细分群。
「3D视觉从入门到精通」知识星球,星球内凝聚了众多3D视觉实战问题,以及各个模块的学习资料:近20门独家秘制视频课程、最新顶会论文、计算机视觉书籍、优质3D视觉算法源码等。想要入门3D视觉、做项目、搞科研,欢迎加入!
0. 这篇文章干了啥?
随着自动驾驶越来越多地采用端到端模型,对可扩展且无域差距的仿真环境的需求变得越来越明显,在这些环境中可以对这些系统进行闭环评估。虽然使用艺术家生成的资产的传统方式在规模、多样性和逼真性方面已达到极限,但生成数字孪生的数据驱动方法的进步通过从设备日志中重建仿真环境提供了一种强有力的替代方案。事实上,神经辐射场(NeRFs)和高斯溅射(GS)已成为以高视觉和几何保真度重建3D场景的强大工具。然而,准确且全面地重建动态驾驶场景仍然是一个重大挑战,特别是由于现实世界中具有各种角色和运动类型的环境的复杂性。
已经有几项工作试图解决这一挑战。早期方法通常忽略动态角色,而只关注重建场景的静态部分。后续工作旨在通过以下方式之一重建动态场景:(i)将场景建模为静态和时间依赖的神经场的组合,其中不同场景部分的分解是一个新兴属性;(ii)构建场景图,其中动态角色和静态背景作为节点表示,并在其规范框架中进行重建和表示。场景图的节点通过编码表示每个角色随时间运动的相对变换参数的边连接。虽然前者是更一般的公式,但后者提供了更高的可编辑性,并可以直接用经典行为模型进行控制。然而,场景图方法仍然只关注可以表示为刚体的车辆,从而在很大程度上忽略了其他弱势道路使用者(VRU),如行人和骑自行车者,这些在驾驶模拟中至关重要。
为了填补这一关键空白,我们的工作旨在建模所有动态角色,包括车辆、行人和骑自行车者等。与在工作室中从多视图系统建模对象不同,从野外场景中重建动态角色极具挑战性。以人类为例。从部分观测中重建人类本身就是一个具有挑战性的问题,而在驾驶场景中,由于传感器观测的不利分布和高度杂乱的环境以及频繁的遮挡,这一问题变得更加复杂。事实上,即使是最先进的人体姿态预测模型也经常难以预测准确的姿态,特别是对于距离较远或被其他物体遮挡的行人。此外,还有其他动态角色,如坐在轮椅上或推着婴儿车的人,这些角色无法简单地用参数化模型进行建模。
为了解决这些相互强化的挑战,我们提出了一个能够处理各种角色的“全能”系统。我们的方法OmniRe高效地重建了包含静态背景、行驶车辆和非刚性移动动态角色的高保真动态驾驶场景(见图1)。具体来说,我们基于高斯溅射表示构建了一个动态神经场景图,并为不同的动态角色构建了专用的局部规范空间。遵循“因地制宜”的原则,OmniRe利用不同表示的集体优势:(i)将车辆建模为静态高斯体,并使用刚体变换来模拟其随时间的运动;(ii)为近距离行走的行人配备基于模板的SMPL模型,使其能够使用线性混合蒙皮权重进行关节级控制;(iii)使用自监督变形场重建远距离和其他无模板的动态角色。这种组合允许对场景中大多数感兴趣对象进行准确表示和可控重建。更重要的是,我们的表示直接适用于自动驾驶仿真中常用的行为和动画模型(如图1-(c)所示)。
下面一起来阅读一下这项工作~
1. 论文信息
标题:OmniRe: Omni Urban Scene Reconstruction
作者:Ziyu Chen, Jiawei Yang, Jiahui Huang, Riccardo de Lutio, Janick Martinez Esturo, Boris Ivanovic, Or Litany, Zan Gojcic, Sanja Fidler, Marco Pavone, Li Song, Yue Wang
机构:Shanghai Jiao Tong University、Technion、University of Toronto、Stanford University、NVIDIA Research、University of Southern California
原文链接:https://arxiv.org/abs/2408.16760
官方主页:https://ziyc.github.io/omnire/
2. 摘要
我们介绍了OmniRe,这是一种整体方法,可以从设备日志中高效地重建高保真度的动态城市场景。最近,使用神经辐射场或高斯溅射(Gaussian Splatting)对驾驶序列进行建模的方法已经展示了重建具有挑战性的动态场景的可能性,但往往忽略了行人和其他非车辆动态角色,从而阻碍了动态城市场景重建的完整流程。为此,我们提出了一个全面的3DGS框架,名为OmniRe,用于驾驶场景,它允许在驾驶日志中准确、完整地重建各种动态对象。OmniRe基于高斯表示构建动态神经场景图,并构建多个局部规范空间,以模拟包括车辆、行人和骑自行车者在内的各种动态角色。这种能力是现有方法无法比拟的。OmniRe使我们能够全面地重建场景中存在的不同对象,从而能够模拟所有角色参与的重构场景,实现实时(~60Hz)模拟。在Waymo数据集上的广泛评估表明,我们的方法在定量和定性上都远远优于之前的最先进方法。我们认为我们的工作填补了驾驶重建领域的一个关键空白。
3. 效果展示


4. 主要贡献
总结而言,我们做出了以下贡献:
• 我们介绍了OmniRe,这是一个全面的动态驾驶场景重建框架,在角色覆盖和表示灵活性方面体现了“全能”原则。OmniRe基于高斯表示的动态神经场景图统一了静态背景、行驶车辆和非刚性移动动态角色的重建。它支持高保真场景重建、从新视角进行传感器模拟以及实时可控场景编辑。
• 我们解决了从驾驶日志中建模人类和其他动态角色所面临的挑战,如遮挡、杂乱环境和现有人体姿态预测模型的局限性。我们的发现基于自动驾驶场景,但可以推广到其他领域。推荐学习:面向自动驾驶领域的BEV与Occupancy网络的全景解析与实战
• 我们进行了广泛的实验和消融研究,以证明我们整体表示的优势。OmniRe在场景重建和新视角合成(NVS)方面达到了最先进的性能,在全图像指标上显著优于之前的方法(重建+1.88 PSNR,NVS+2.38 PSNR)。对于动态角色(如车辆+1.18 PSNR)和人类(重建+4.09 PSNR,NVS+3.06 PSNR)的差异尤为明显(表1)。
5. 基本原理是啥?
如图2所示,我们构建了一个高斯场景图表示,该表示全面覆盖了静态背景和多种可移动实体。我们讨论了表示不同语义类别的系统策略,突出了我们的主要贡献之一。由于人体具有非刚性特性、准确初始化的困难以及野外环境中经常出现的严重遮挡,因此在无约束环境中对人体进行建模尤其具有挑战性。我们介绍了针对此问题的解决方案,该方案显著提高了性能。最后,我们展示了如何端到端地优化场景表示,以获得忠实且可控的重构。
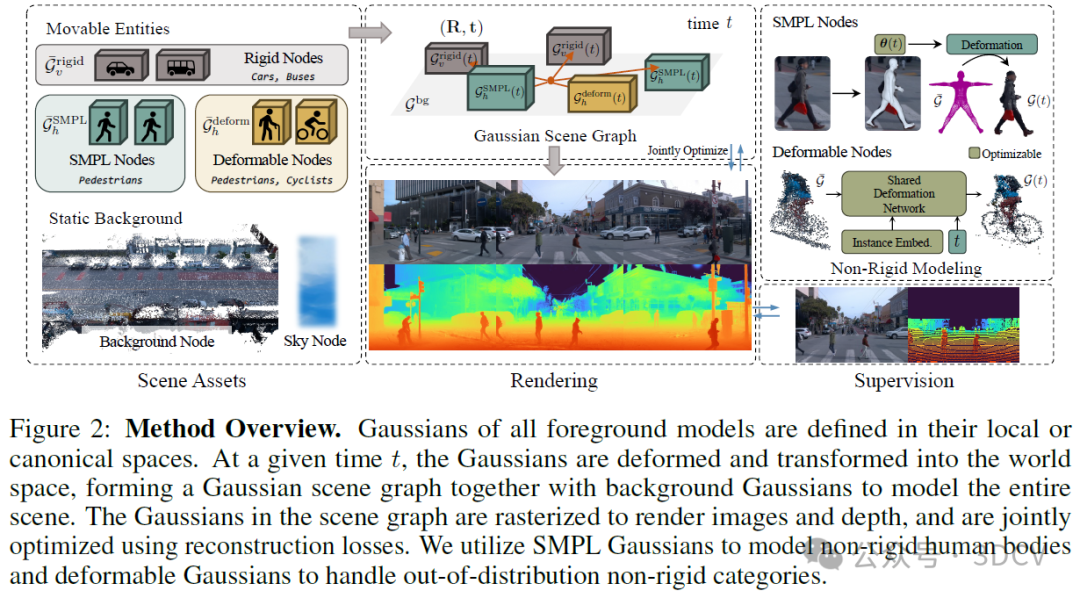
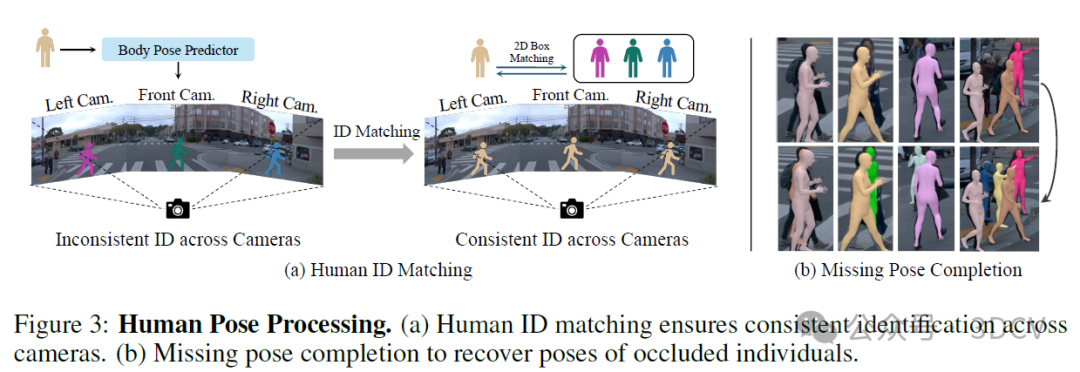
6. 实验结果
我们在场景重建和新视角合成(NVS)任务上评估了我们的方法,每10帧中取一帧作为NVS的留出测试集。我们报告了全图、与人相关区域和与车辆相关区域的峰值信噪比(PSNR)和结构相似性(SSIM)分数,以评估动态重建能力。表1中的量化结果显示,OmniRe在所有其他方法中表现最优,特别是在与人相关区域上表现出显著优势,验证了我们对动态行为者的整体建模。此外,虽然StreetGS和我们的方法都以类似的方式对车辆进行建模,但我们观察到,即使在车辆区域,OmniRe也略优于StreetGS。这是由于StreetGS中没有对人进行建模,导致来自人区域(如颜色、激光雷达深度)的监督信号错误地影响了车辆建模。StreetGS面临的问题是我们整体建模场景中几乎所有事物的动机之一,旨在消除错误的监督和意外的梯度传播。
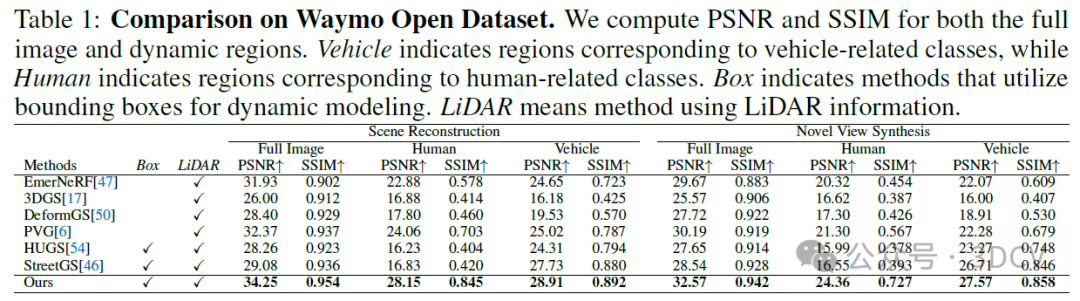
7. 总结 & 未来工作
我们的方法OmniRe使用高斯场景图来解决全面的城市场景建模问题。它实现了快速、高质量的重建和渲染,为自动驾驶和机器人仿真提供了前景。我们还提出了在复杂环境中进行人体建模的解决方案。未来的工作包括自监督学习、改进场景表示以及安全/隐私考虑。
更广泛的影响。我们的方法旨在解决自动驾驶中的一个重大问题——仿真。这种方法有潜力促进自动驾驶汽车的开发和测试,有可能带来更安全、更高效的自动驾驶系统。以安全、可控的方式进行仿真仍然是一个开放且具有挑战性的研究问题。
伦理与隐私。我们的工作不涉及新数据的收集或标注。我们利用的是符合严格道德准则的公共数据集。这些数据集确保包括可识别的人脸特征在内的敏感信息被模糊处理或匿名化,以保护个人隐私。我们致力于确保我们的方法以及未来的应用都能以负责任和符合伦理的方式使用,以维护安全和保护隐私。
局限性。OmniRe仍存在一些局限性。首先,我们的方法没有明确地对光照效果进行建模,这可能导致仿真过程中的视觉和谐性问题,特别是当组合在不同光照条件下重建的元素时。要解决这个问题,需要超出我们当前工作范围之外的专门努力。进一步研究光照效果的建模和增强仿真的真实性对于实现更具说服力和和谐的结果至关重要。其次,与其他按场景优化的方法类似,当相机轨迹与训练轨迹偏差较大时,OmniRe生成的新视角不太令人满意。我们认为,将图像或视频生成模型等数据驱动先验纳入其中,代表了未来探索的一个有前景的方向。
对更多实验结果和文章细节感兴趣的读者,可以阅读一下论文原文~
本文仅做学术分享,如有侵权,请联系删文。















 363
363

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









