







原理透析
确认了有多少棵树之后,我们来思考一个问题:建立了众多的树,怎么就能够保证模型整体的效果变强呢?集成的目的是为了模型在样本上能表现出更好的效果,所以对于所有的提升集成算法,每构建一个评估器,集成模型的效果都会比之前更好。也就是随着迭代的进行,模型整体的效果必须要逐渐提升,最后要实现集成模型的效果最优。要实现这个目标,我们可以首先从训练数据上着手。
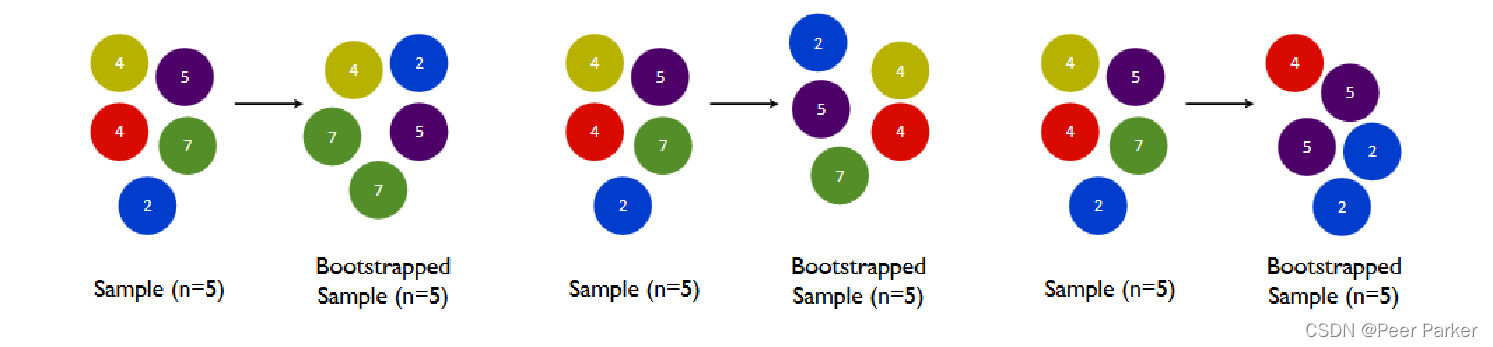
我们训练模型之前,必然会有一个巨大的数据集。我们都知道树模型是天生过拟合的模型,并且如果数据量太过巨大,树模型的计算会非常缓慢,因此,我们要对我们的原始数据集进行有放回抽样(bootstrap)。有放回的抽样每次只能抽取一个样本,若我们需要总共N个样本,就需要抽取N次。每次抽取一个样本的过程是独立的,这一次被抽到的样本会被放回数据集中,下一次还可能被抽到,因此抽出的数据集中,可能有一些重复的数据。
无论是
Bagging
还是
Boosting
的集成算法中,有放回抽样都是防止过拟合,让单一弱分类器变得更轻量的必要操作。实际应用中,每次抽取50%左右的数据就能够有不错的效果了。
sklearn
的随机森林类中也有名为
boostrap的参数来帮助我们控制这种随机有放回抽样。同时,这样做还可以保证集成算法中的每个弱分类器(每棵树)都是不同的模型,基于不同的数据建立的自然是不同的模型,而集成一系列一模一样的弱分类器是没有意义的。在梯度提升树中,我们每一次迭代都要建立一棵新的树,因此我们每次迭代中,都要有放回抽取一个新的训练样本。不过,这并不能保证每次建新树后,集成的效果都比之前要好。因此我们规定,在梯度提升树中,每构建一个评估器,都让模型更加集中于数据集中容易被判错的那些样本。来看看下面的这个过程。
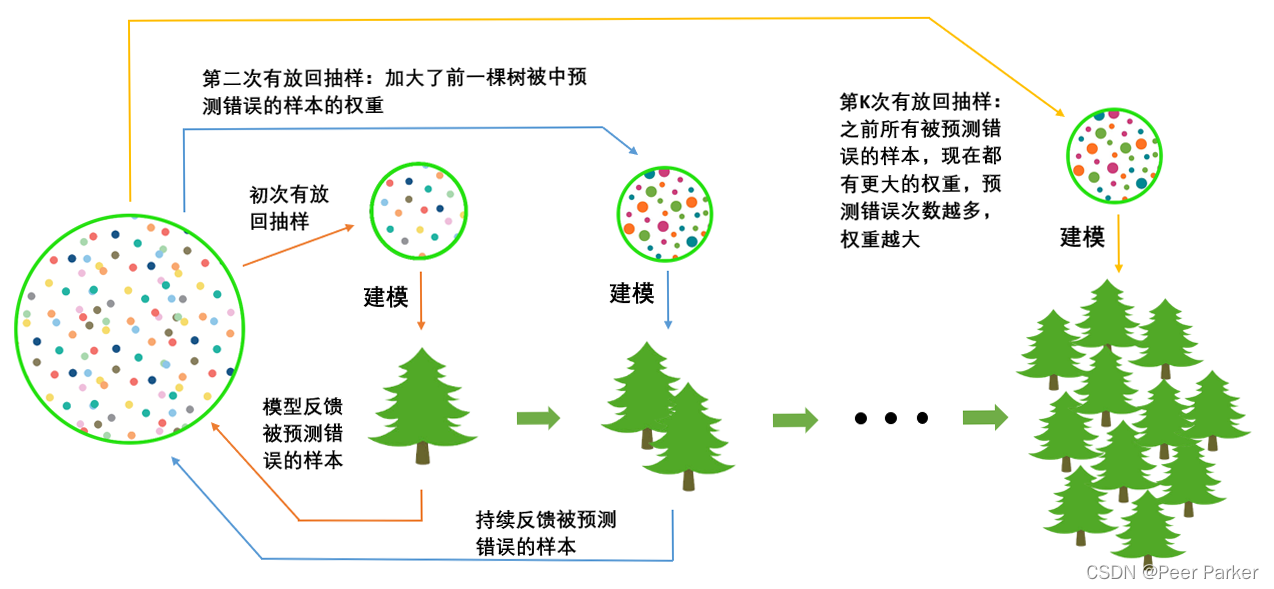
首先我们有一个巨大的数据集,在建第一棵树时,我们对数据进行初次又放回抽样,然后建模。建模完毕后,我们对模型进行一个评估,然后将模型预测错误的样本反馈给我们的数据集,一次迭代就算完成。紧接着,我们要建立第二棵决策树,于是开始进行第二次又放回抽样。
但这次有放回抽样,和初次的随机有放回抽样就不同了,在这次的抽样中,我们加大了被第一棵树判断错误的样本的权重。
也就是说,被第一棵树判断错误的样本,更有可能被我们抽中。
基于这个有权重的训练集来建模,我们新建的决策树就会更加倾向于这些权重更大的,很容易被判错的样本。
建模完毕之后,我们又将判错的样本反馈给原始数据集。下一次迭代的时候,被判错的样本的权重会更大,新的模型会更加倾向于很难被判断的这些样本。如此反复迭代,越后面建的树,越是之前的树们判错样本上的专家,越专注于攻克那些之前的树们不擅长的数据。对于一个样本而言,它被预测错误的次数越多,被加大权重的次数也就越多。我们相信,只要弱分类器足够强大,随着模型整体不断在被判错的样本上发力,这些样本会渐渐被判断正确。如此就一定程度上实现了我们每新建一棵树模型的效果都会提升的目标。
参数设置
| 参数含义 |
xgb.train()
|
|
随机抽样的时候抽取的样本比例,范围
(0,1]
|
subsample
,默认
1
|
除了让模型更加集中于那些困难样本,采样还会减少样本数量,而从学习曲线来看样本数量越少模型的过拟合会越严重,因为对模型来说,数据量越少模型学习越容易,学到的规则也会越具体越不适用于测试样本。所以subsample
参数通常是在样本量本身很大的时候来调整和使用。


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











