







目录
论文:https://arxiv.org/pdf/2010.03045v2
代码:https://github. com/LandskapeAI/triplet-attention

一、摘要
由于注意机制具有在通道或空间位置之间建立相互依赖关系的能力,近年来在各种计算机视觉任务中得到了广泛的研究和应用。在本文中,我们研究了轻量级但有效的注意机制,并提出了三重注意,这是一种利用三分支结构捕获跨维交互来计算注意权重的新方法。对于输入张量,三元组注意力通过旋转操作建立维度间依赖关系,然后进行残差变换,并以可忽略不计的计算开销对通道间和空间信息进行编码。我们的方法简单高效,可以作为附加模块轻松插入经典骨干网。我们证明了我们的方法在各种具有挑战性的任务上的有效性,包括在ImageNet-1k上的图像分类和在MSCOCO和PASCAL VOC数据集上的目标检测。此外,我们通过视觉检查GradCAM和GradCAM++结果,提供了对三重注意力性能的广泛洞察。对我们方法的经验评估支持了我们在计算注意力权重时捕获跨维度依赖关系的重要性的直觉。
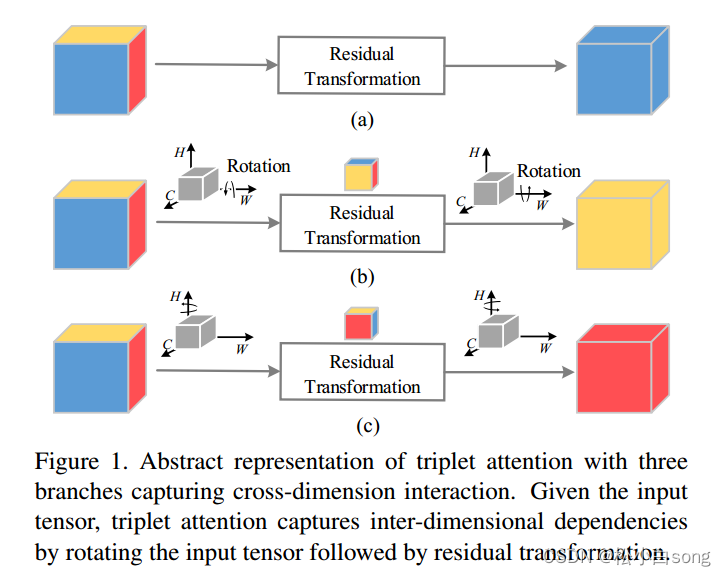
用三个分支捕获跨维交互的三重注意的抽象表示。给定输入张量,三重态注意力通过旋转输入张量,然后进行残差变换来捕获维间依赖关系。
二、创新点总结
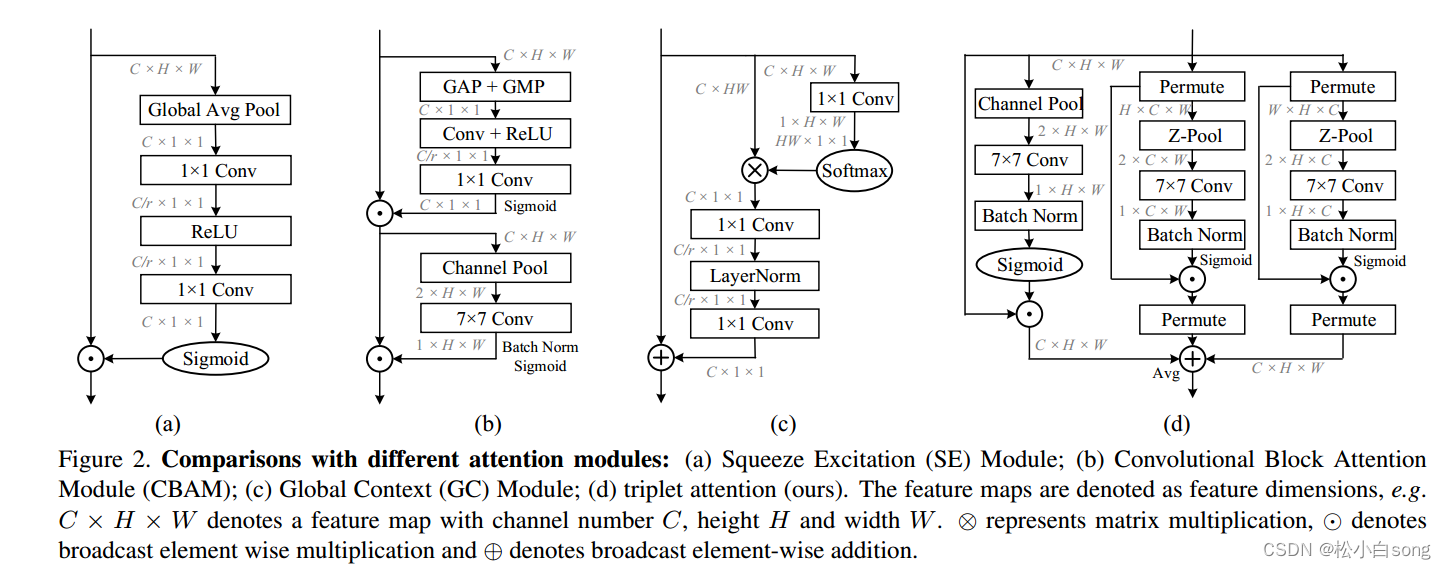
不同注意模块的比较:
(a)挤压激励(SE)模块;
(b)卷积块注意模块(CBAM);
(c)全局上下文模块;
(d)(我们的)三重注意力模块。
特征映射表示为特征维度,例如:
C × H × W表示通道号为C、高H、宽W的特征映射。⊗表示矩阵乘法,⊙表示广播元素明智乘法,⊕表示广播元素明智加法。
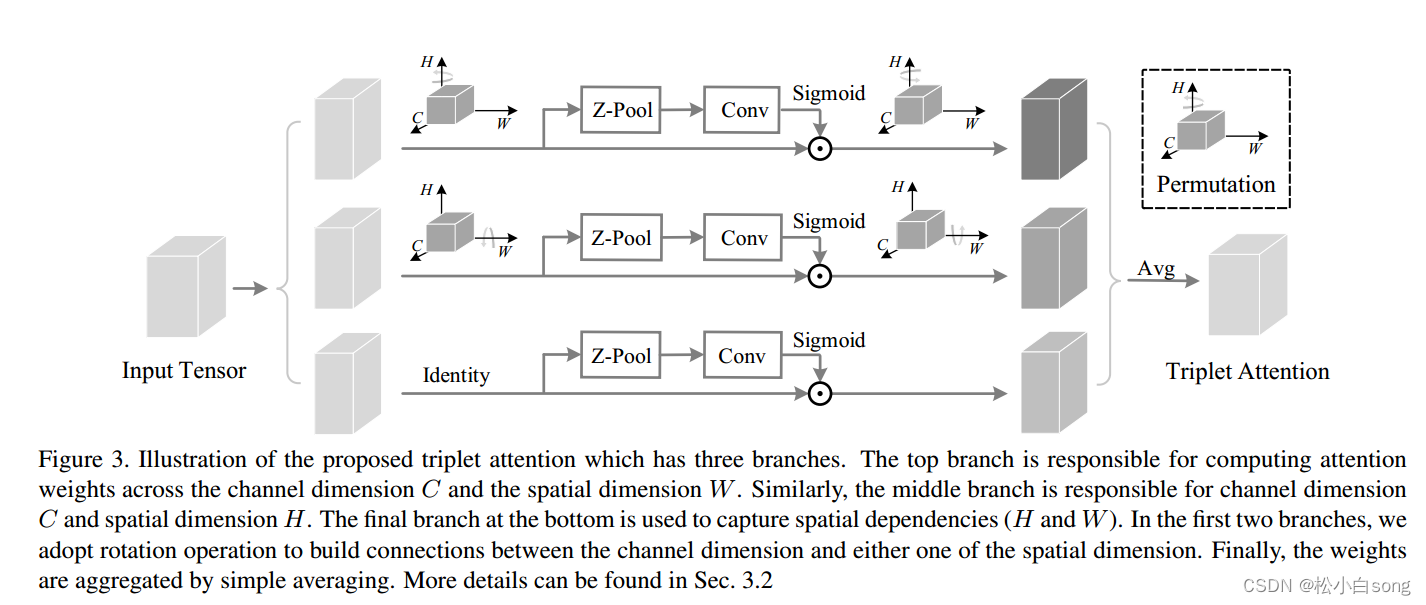
图3 三重注意力的图解,它由三个分支。顶部分支负责计算跨通道维度C和空间W的注意力权重,中间捕捉的是C和H之间的权重,类似的底部分支获取的是H和W的空间相关性。在前两个分支中,我们采用旋转操作来建立通道维度与空间维度中的任一个之间的连接,最后通过简单的平均来合计权重。
跨维度交互:计算通道注意力的传统方法包括计算singular权重,通常是输入张量中每个通道的标量,然后使用奇异权重统一缩放这些特征映射。虽然这个计算通道注意力的过程被证明是非常轻量级的和非常成功的,但是在考虑这种方法有一个重要的确实。为了计算这些通道的奇异权重,通过执行全局平均池化,输入张量被空间分解为每一个通道一个像素。这导致了空间信息的主要损失,因此当计算对这些单像素通道的关注时,通道尺寸和空间尺寸之间的相互依赖性不存在。CBAM引入了空间注意作为通道注意力的补充模块,简而言之,空间注意力告诉’通道的什么地方聚焦,通道注意力告诉’聚焦在哪个通道。然而,这个过程的缺点是通道注意力和空间注意力是分离的,并且彼此独立地计算。因此不考虑两者之间的任何关系。受到建立空间注意力方式的启发,我们提出了跨维度交互的概念,通过捕捉输入张量的空间维度和通道维度之间的交互来解决这个缺点。我们在三重注意力中引入了跨维度相互作用,通过三个分支分别获得张量(C,H)、(C,W)和(H,W)维之间的依赖关系。
Z-pool : 这里的Z池化层负责将第0个维度缩减为两个维度,方法是将该维度上的平均池化和最大池化要素串联起来。这使得该层能够保留实际张量的丰富表示,同时缩小其深度,以使进一步的计算变得轻量级。在数学上可以用如下公式:
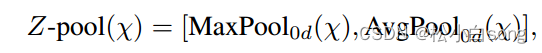
其中0d是发生最大和平均池化的操作的第0维度。例如,一个形状张量为(CxHxW)最后可以生成一个形状张量(2xHxW)的张量。
Triplet Attention:给定上述定义的操作,我们将三重注意定义为一个三分支模块,它接受一个输入张量并输出一个相同形状的细化张量。给定一个输入张量X ∈ R(CxHxW),我们首先把它传递给提出三重注意模块中的每一个。
在第一个分支中,我们构建了高度维度和通道维度之间的交互。为此,输入X沿着H轴逆时针旋转90度。这个旋转张量表示为形状(WxHxC),X1然后通过一个Z-pool,随后被简化为形状为(2 x H x C) ,X1然后通过内核大小为7X7的标准卷积层,随后就是批量归一化层,其提供维度的中间输出(1 x H x C)。然后通过张量穿过sigmod激活层(σ)来生成最终的注意力权重。随后将生成的注意力权重应用于X1,然后沿H轴顺时针旋转90°,以保持x的原始形状输入。
同样的,在第二个分支中,我们沿着W轴逆时针旋转90°。旋转张量X2可以用(H x C x W)表示,并通过一个Z池化层。因此张量被简化为形状x2为(2xCxW)。X2 通过 由核大小为k x k 定义的标准卷积层,随后是批量归一化层,其输出形状的张量(1 x C x W)。然后通过使该张量通过sigmod激活层来获得注意力权重,然后简单地应用于X2,并且输出随后沿着W轴顺时针旋转90°,以保持与输入X相同的形状。
对于最后一个分支,输入张量X的通道被Z池化为两个。然后,该形状的简化张量X3(2 x H x W)通过由核大小k定义的标准卷积层,随后是批量归一化层。输出通过sigmod激活层(σ)生成形状注意力权重(1 x H x W),然后应用于输入X。然后,由三个分支中的每一个生成的形状的精细张量(C x H x W)通过简单平均来聚集。
总之输入张量X ∈ R(C x H x W)的三重注意力中获得的精细注意力应用张量y的过程可以由以下等式表示:
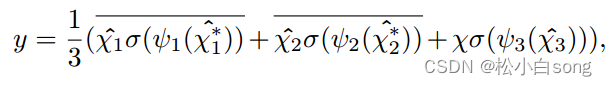
其中σ代表sigmod激活函数;ψ1、ψ2和ψ3代表三重注意的三个分支中由核大小k定义的标准二维卷积层。简单的来说y可以变为:
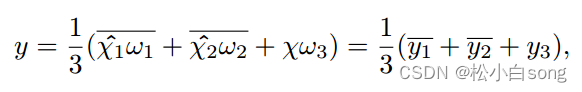
其中ω1、ω2和ω3是在三重注意中计算的三个交叉维度注意权重。等式中的y1和y2 在上述等式中,代表90°顺时针旋转以保持(C × H × W)的原始输入形状。
三、代码详解
代码:
import torch
import torch.nn as nn
# 定义一个基础的卷积模块
class BasicConv(nn.Module):
def __init__(
self,
in_planes, # 输入通道数
out_planes, # 输出通道数
kernel_size, # 卷积核大小
stride=1, # 步长
padding=0, # 填充
dilation=1, # 空洞率
groups=1, # 分组卷积的组数
relu=True, # 是否使用ReLU激活函数
bn=True, # 是否使用批标准化
bias=False, # 卷积是否添加偏置
):
super(BasicConv, self).__init__()
self.out_channels = out_planes
# 定义卷积层
self.conv = nn.Conv2d(
in_planes,
out_planes,
kernel_size=kernel_size,
stride=stride,
padding=padding,
dilation=dilation,
groups=groups,
bias=bias,
)
# 可选的批标准化层
self.bn = (
nn.BatchNorm2d(out_planes, eps=1e-5, momentum=0.01, affine=True)
if bn
else None
)
# 可选的ReLU激活层
self.relu = nn.ReLU() if relu else None
def forward(self, x):
x = self.conv(x)
if self.bn is not None:
x = self.bn(x)
if self.relu is not None:
x = self.relu(x)
return x
# 定义一个通道池化模块
class ChannelPool(nn.Module):
def forward(self, x):
return torch.cat(
(torch.max(x, 1)[0].unsqueeze(1), torch.mean(x, 1).unsqueeze(1)), dim=1
)
# 定义一个空间门控模块
class SpatialGate(nn.Module):
def __init__(self):
super(SpatialGate, self).__init__()
kernel_size = 7
self.compress = ChannelPool()
self.spatial = BasicConv(
2, 1, kernel_size, stride=1, padding=(kernel_size - 1) // 2, relu=False
)
def forward(self, x):
x_compress = self.compress(x)
x_out = self.spatial(x_compress)
scale = torch.sigmoid_(x_out)
return x * scale
# 定义一个三元注意力模块
class TripletAttention(nn.Module):
def __init__(
self,
gate_channels, # 门控通道数
reduction_ratio=16, # 缩减比率
pool_types=["avg", "max"], # 池化类型
no_spatial=False, # 是否禁用空间门控
):
super(TripletAttention, self).__init__()
self.ChannelGateH = SpatialGate()
self.ChannelGateW = SpatialGate()
self.no_spatial = no_spatial
if not no_spatial:
self.SpatialGate = SpatialGate()
def forward(self, x):
x_perm1 = x.permute(0, 2, 1, 3).contiguous()
x_out1 = self.ChannelGateH(x_perm1)
x_out11 = x_out1.permute(0, 2, 1, 3).contiguous()
x_perm2 = x.permute(0, 3, 2, 1).contiguous()
x_out2 = self.ChannelGateW(x_perm2)
x_out21 = x_out2.permute(0, 3, 2, 1).contiguous()
if not self.no_spatial:
x_out = self.SpatialGate(x)
x_out = (1 / 3) * (x_out + x_out11 + x_out21)
else:
x_out = (1 / 2) * (x_out11 + x_out21)
return x_out
论文解读:大佬

















 1212
1212

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









