







在搞清楚深度梯度压缩之前,我先将什么是梯度下降捋一捋,同时方便后面的理解。我会将论文里面提到的vanilla SGD和加了动量Momentum的SGD的区别也写出来。
正好,今天上午的最优化理论讲到了各种下降法逼近极小值点,最近读到关于联邦学习中如何减小通信效率和计算效率这个问题,借助深度梯度压缩,会极大地减少局部到服务器的通信成本。
目录
一、什么是vanilla SGD
SGD是当下使用最广泛地优化器,原理是通过求得当前参数损失函数的最大梯度,往梯度的反方向走即可走到损失函数的极小值点。可以想象成盲人要寻找最快下山的过程,那就是不断地摸索当下点周围最陡峭的方位,沿着那个方位走是最大概率时间最短到达山谷的。
1、梯度
梯度:梯度在数学上表示函数在某点处的方向导数沿着该方向取得最大值。(方向导数是形容函数的陡峭程度)
可以这样想:在一个结构类似山谷的函数上存在一点,当然这个点会在各个方向上都存在方向导数,而我们所需要的梯度就是所有方向导数中最大的那个,沿着这个最大方向导数(梯度)上去的函数值增长速度会变得非常快,那反之,沿着梯度负方向的函数值就是负增长速度最快的。
先从第一个点往下找,找到沿着梯度负方向迈出第二步,到达第二个点,再找第二个点的最大梯度负方向迈出第二步,以此类推最后到达山谷最低处,也就是函数极小值点(方向导数此时为0)。如图所示:
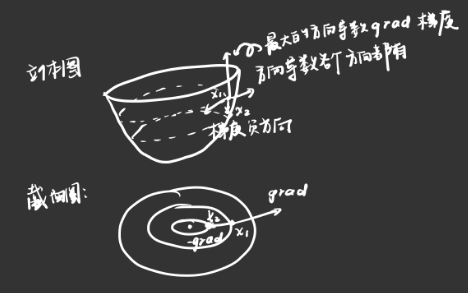
然而决定如何找到极小值点的还有步长,也就是 这个盲人除了要确定山坡的陡峭程度,还得控制自己的步伐大小。
2、步长
步长也就是学习率𝜂,这个可固定,也可变。
综上所述,我们知道决定梯度下降取得极小值点关键的是梯度和步长。这儿需要注意的是,我们计算损失函数的目的是为了取得极小值点的坐标(也就是训练时相关的权值参数),而不是极小值。
3、SGD的数学表示
由一阶泰勒展开可以得到:![]()
令:![]()
上面的式子可以写为:![]()
此时要使得:![]() 时,只能有:
时,只能有:![]()
令:![]() ,此时的
,此时的![]()
将![]() 带入到一节泰勒展开的式子中得到:
带入到一节泰勒展开的式子中得到:
![]() 将
将![]() 写为:
写为:![]()
即为:![]()
于是,我们得到了梯度下降的“雏形”。(学习率大于零)
此时我们真正的主角vanilla SGD登场,我们可将其写为如下形式:
这个现在就很好理解了,𝜂是学习率,∇𝐿(𝑤𝑡)是阿损失函数的梯度,我们所更新的权值参数就是基于上一个损失函数下降得到的。
为了提升计算效率,用的最多的还是小批量SGD 算法,一次训练小批量的样本梯度取平均来更新权值参数。![]() 其中,
其中,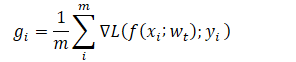
二、带有动量Momentum的SGD
SGD在随机挑选某一分量的梯度方向进行收敛,加一个“动量”的话,相当于有了一个惯性在里面。当我们人在运动时,向前跑由于有惯性,故后期跑起来会比刚开始起步时轻松,另外当你想要往反方向时,会降低你的返回速度。故,在SGD的基础上加一个动量,如果当前收敛效果好,就可以加速收敛,如果不好,则减慢它的步伐。
————————————————
版权声明:本文为CSDN博主「_Skylar_」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/You1022/article/details/11033749
可以看到,加入动量的SGD就是往梯度下降的方向加入一个惯性,如果后一次下降的方向与前一次一致,则这个惯性会将梯度加强,从而使得整个迭代过程加速收敛,反之如果当前的梯度与累积的梯度不一致,则会减弱当前的梯度。
SGD+momentum的公式可以写为:![]()
故权值参数更新的公式写为:![]()















 6879
6879











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









