








北京大学 李翔宇
编者按:
问题生成是问答系统中很重要的一个部分,在对话系统、数据集生成等任务中都有帮助。目前的问题生成主要聚焦于简单问题生成,对于比较复杂的、需要逻辑推理的问题生成研究较少。同时,图对复杂的逻辑结构有较好的表示性,图上的点边关系可以表示不同实体之间的语义关系,因此近期不少研究人员基于图算法来研究复杂问题的生成。
本文将介绍其中两项代表工作。
问题定义:question generation
简单问题生成
输入:一段文本和答案
输出:简单问题文本
复杂问题生成
输入:几段文本和答案
输出:复杂问题文本
问题的难点:
1)需要捕捉多段文本的语义,存在长距离依赖;
2)需要在多段文本中挑选和答案相关的内容;
3)需要识别被挑选内容之间的语义关系
01 paper:Semantic Graphs for Generating Deep Questions
1.模型
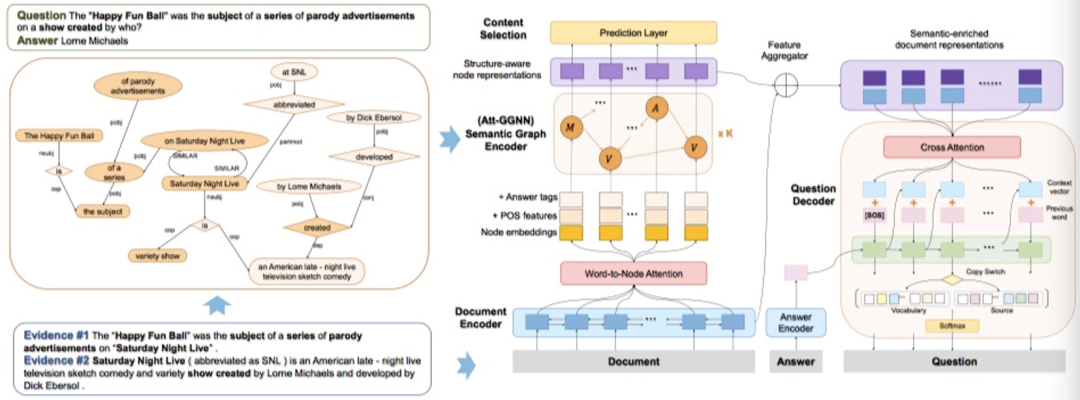
模型分为三个部分:语义图生成,encoder和decoder
1.1 语义图生成
这里用到了两种语义图生成方式,分别为SRL-based Semantic Graph和DP-based Semantic Graph,通过对语句的分析,前者得到(主/谓/宾)形式的tuples,后者得到语法依赖树。例如上图中的两段文本经过DP-based方法,得到了相关的语义图
1.2 encoder
这里分为word-level的文本表示和语义图级别的文本表示,首先对所有文本过GRU网络,得到单词层面的文本表示,并用GRU前向第一个单元的表征和后向最后一个单元的表征表示全文本d。
语义图级别的文本表示又分为四步,1)对于图上每个节点,计算d对节点上每个单词的attention,根据attention得分,聚合每个单词的GRU编码结果,得到该节点的初始化表征;2)对于每个节点,附加pos embedding和answer embedding;3)用GGNN(Gated graph sequence neural networks)对语义图做encoder;4)将每个单词的语义图级别的文本表示并联到原文本表征后,如该单词不在图中,则并联空向量。
1.3 decoder
输出部分同时完成两个任务,挑选和答案相关的图结点(分类任务)+复杂问题生成(生成任务),作者在生成部分用到了copy机制和coverage机制。
2.实验部分
2.1 数据集 HotpotQA
2.2 实验结果
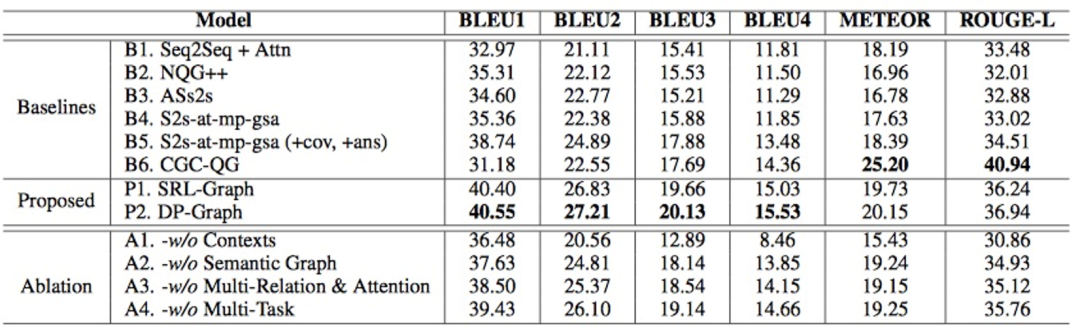
作者主要比较了seq2seq结构的文本生成模型,可以看到提出的模型在各项指标上都有所提升,其中CGC-QG这篇baseline在meteor和rouge-L这两项指标上效果较高,但该模型容易生成非常冗长且逻辑语义不正确的句子,因此可用性较低。
02 paper:Asking Complex Questions with Multi-hop Answer-focused Reasoning
1.模型
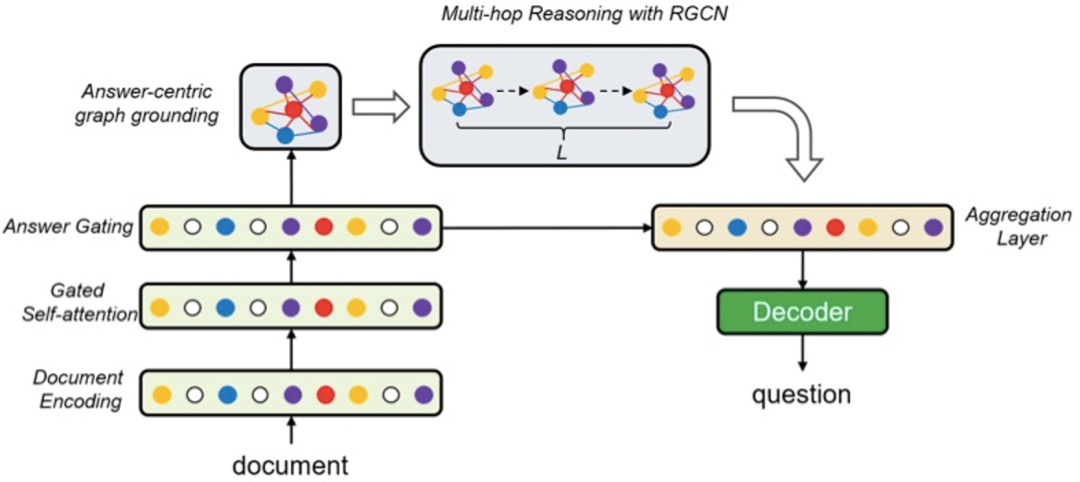
该模型同样分为三个部分,启发式规则构建语义图,encoder部分和decoder部分
1.1 语义图生成
作者将从构造点和构造边两个部分展开构建
1)点:通过命名实体识别,从文本中提取出有效实体,同时提取出文本的title和answer
2)边:将不同文本片段之间相同的命名实体之间连边;将不同文本片段之间精确匹配的单词连接;将每个文本片段的title和图结点连接;将不同的title之间连接;将answer和所有的实体连接
1.2 encoder
首先对文本过LSTM得到初步的表征,然后通过answer gating得到进一步的,所有文本和答案相关的表征:
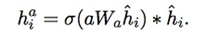
其次用文本的LSTM表征做图结点的初始化,即图结点包含单词的隐向量的平均值;接下来用RGCN(Modeling Relational Data with Graph Convolutional Networks )网络做图encoder,得到每个图结点的embedding结果;最后用所有图节点表征和原文本的LSTM表征做并联,表示含有图语义关系的输入表示。
2.实验部分
2.1 数据集 HotpotQA
2.2 实验结果
作者主要比较了seq2seq结构的文本生成模型和基于GAT+point network的文本生成模型,所提出模型在各项指标上都优于baseline。
总结
这两项工作在任务设定和数据集的使用上基本一致,主要有以下几个区别:
1)构造图的方式不同,第一篇工作利用已有解析工具生成基于主谓宾三元组结构和基于语法依赖树的语义图,第二篇工作通过启发式规则分别构造边和点;
2)对数据集的处理略有不同;
3)使用的图模型不同;
4)文本编码时,对答案的使用方式不同。














 514
514











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









