






 本文探讨了点云分割算法的发展,从PointNet的局部特征聚合到DGCNN的边缘卷积,再到AGNet的自注意力池化。AGNet通过自注意力机制在保持点云无序性的同时,减少了信息损失,提高了分割效果。实验显示,AGNet在ModelNet40、ShapeNetPart、S3DIS等数据集上取得领先结果,相较于传统方法有显著优势。
本文探讨了点云分割算法的发展,从PointNet的局部特征聚合到DGCNN的边缘卷积,再到AGNet的自注意力池化。AGNet通过自注意力机制在保持点云无序性的同时,减少了信息损失,提高了分割效果。实验显示,AGNet在ModelNet40、ShapeNetPart、S3DIS等数据集上取得领先结果,相较于传统方法有显著优势。
之前看的论文比较多的是大场景点云分割的,它们的做法就是获取邻域特征信息编码,然后利用注意力等加权学习特征,之后聚合局部的特征(自注意力池聚合),完成下采样的工作。其实图卷积也可以很好的完成分割效果,自从PointNet没有提取到邻域局部特征信息后,很多图卷积的网络都使用了一种边缘卷积的方法来学习邻域之间点云的特征关系。但是像DGCNN这种虽然学习了邻域的特征,但是在聚合的时候使用了和PointNet一样的对称函数(max pooling),这种方法虽然简单,而且可以解决点云的排序不变性,但是这样会丢失很多信息。AGNet提出了一种自注意力池的结构,有点类似于大场景点云分割算法中的那种自注意力池,这种池化可以防止丢失很多信息。
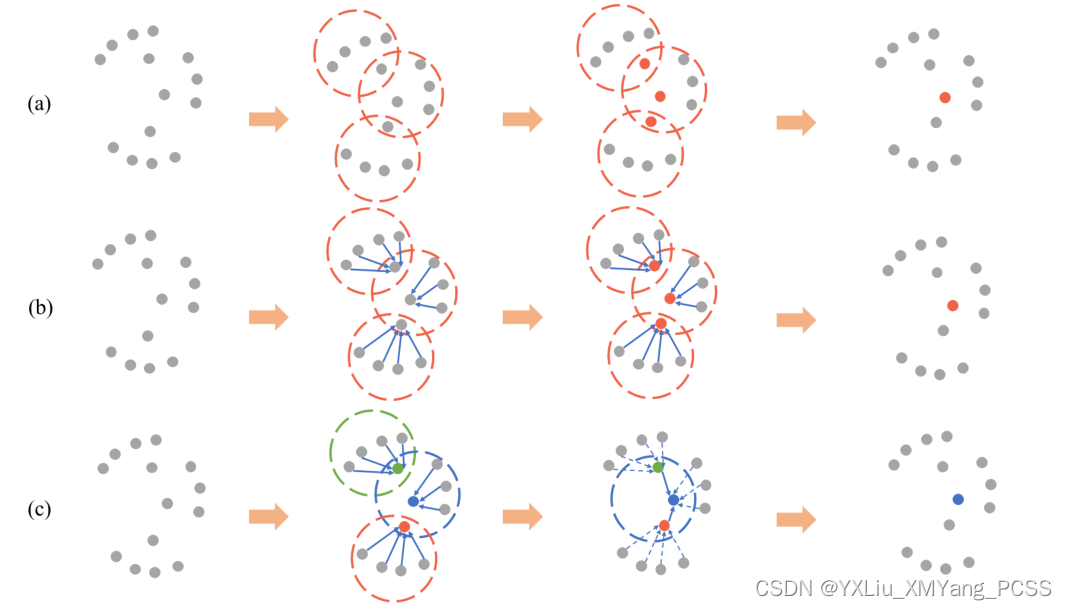
上图分别是PointNet++、DGCNN、AGNet的邻域局部特征聚合过程,可以看到最后的AGNet最后聚合的时候是利用的不同的注意力打分进行聚合的(颜色代表着不同的权重)。
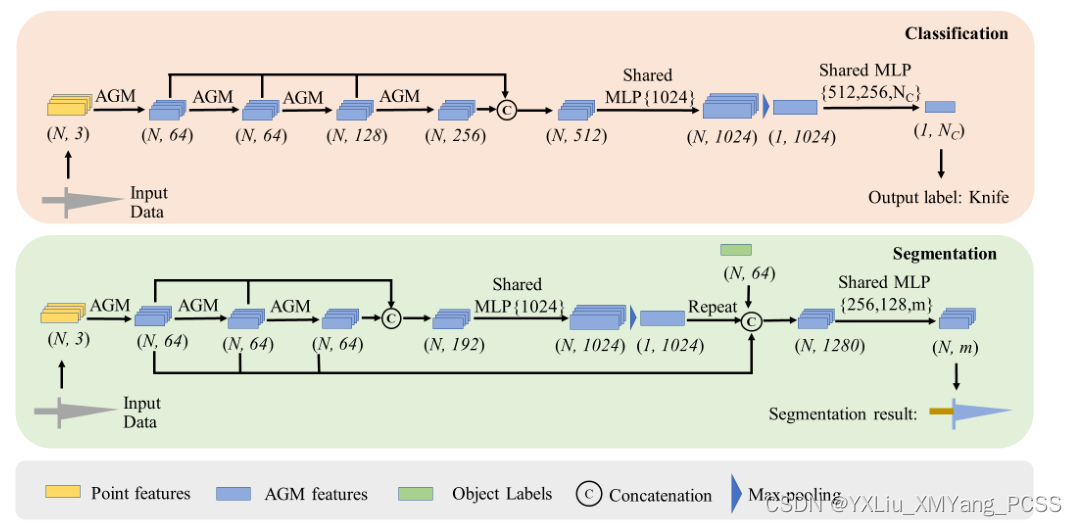
从上图的AGNet的网络结构来看,整体的网络框架类似于PointNet,只是在前面提取特征的过程中,加入了AGM模块(attention graph module),这部分主要是学习点与点之间的位置特征关系,只不过聚合的时候利用的是自注意力池而不是最大池化。
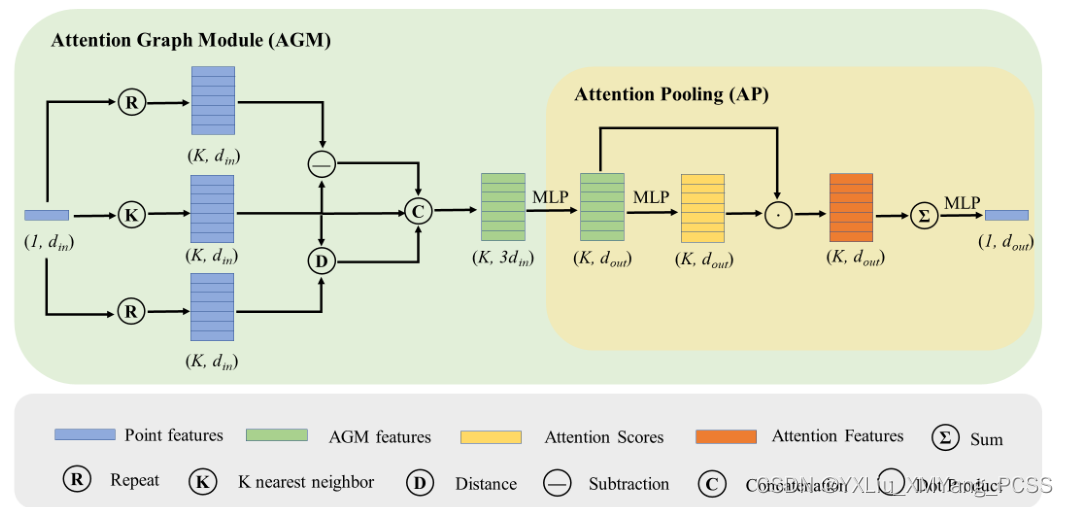
如上图所示,特征输入之后,经过三个模块的学习,分别是中心点、中心点和邻域点的差值、中心点和邻域点的距离。

上述公式的α,β,γ都是可以学习的参数。经过上述的特征学习之后,进行一个自注意力池,这一步主要是聚合特征,这种聚合的方法不会损失太多的点特征,还可以解决点云的无序性。
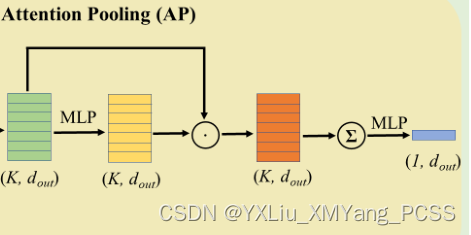
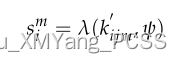
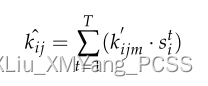
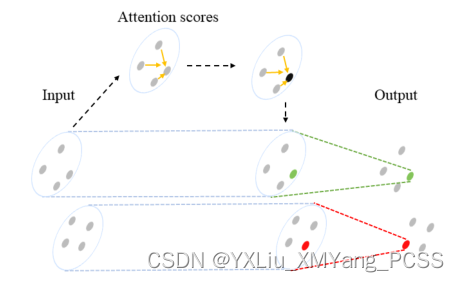
对于自注意力池的理解,可以理解为对不同点云的一个打分,对于比较主要的点,给它打分比较高的权重,聚合时会更加注意这方面的点,如下图2D点所示,绿点和红点都是相对比较重要的点。
目前很多点云分割的算法在聚合特征的时候都不采用之前的对称函数的做法,那样会丢失很多点云信息,目前这种Attention Pool的方法很是流行。从作者做的实验来看,在一些先进的数据集上(ModelNet40、ShapeNet Part、S3DIS)上取得了领先的结果。
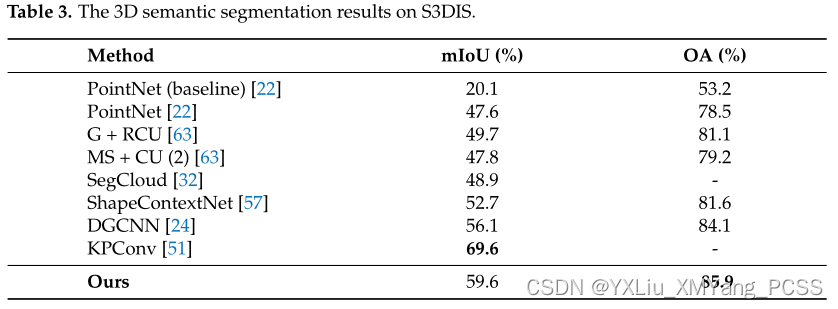
虽然它的miou不是特别的高,但是它相比于一些图卷积的文章的效果要好很多。具体参考论文。


















09-18
 247
247
247
11-18
6220
6220
03-27
2967
2967
03-08

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











