




我自己的原文哦~ https://blog.51cto.com/whaosoft/13252192
#为什么说AI创业也在重复其中的错误?
70年AI研究得出了《苦涩的教训》
人人都在做垂直 AI 产品,为什么要反其道而行?
Scaling Laws 是否失灵,这个话题从 2024 年年尾一直讨论至今,也没有定论。
Ilya Sutskever 在 NeurIPS 会上直言:大模型预训练这条路可能已经走到头了。上周的 CES 2025,黄仁勋有提到,在英伟达看来,Scaling Laws 仍在继续,所有新 RTX 显卡都在遵循三个新的扩展维度:预训练、后训练和测试时间(推理),提供了更佳的实时视觉效果。
而这一切的思考,都可以追溯到「RL 之父」 Rich Sutton 在 2019 年发表的经典短文 The Bitter Lesson 《苦涩的教训》。
Y Combinator 校友日上,Andon Labs 的 CEO 兼联合创始人 Lukas Petersson 听完 100 多个项目路演后写下了一个有趣的观察:《苦涩的教训》中所写的 AI 研究历史似乎正在 AI 创业界重演。
研究人员曾一次又一次试图通过精巧的工程设计来提升性能,但最终都败给了简单粗暴的「加大算力」方案。
而今天,AI 产品的开发者们,似乎正在重走这条老路。
在不改变博客原意的基础上进行了编译。
如果觉得博客太长,核心内容已经总结好了:
- 历史证明,通用方法总是在 AI 领域胜出;
- 当下 AI 应用领域的创业者正在重蹈 AI 研究者过去的覆辙;
- 更强大的 AI 模型将催生通用型 AI 应用,同时也会削弱 AI 模型「套壳」软件的附加价值。
AI 技术的飞速发展带来了一波又一波新产品。在 YC 校友演示日上,我见证了 100 多个创业项目的路演。这些项目都有一个共同点:它们瞄准的都是施加了各种限制和约束的 AI 解决的简单问题。
AI 真正的价值在于它能灵活处理各类问题。给 AI 更多自由度通常能带来更好的效果,但现阶段的 AI 模型还不够稳定可靠,所以还无法大规模开发这样的产品。
这种情况在 AI 发展史上反复出现过,每次技术突破的路径都惊人地相似。如果创业者们不了解这段历史教训,恐怕要为这些经验「交些学费」。
2019 年,AI 研究泰斗 Richard Sutton 在他那篇著名的《苦涩的教训》开篇提到:
「70 年的 AI 研究历史告诉我们一个最重要的道理:依靠纯粹算力的通用方法,最终总能以压倒性优势胜出。」
这篇文章标题里的「苦涩」二字,正是来自那些精心设计的「专家系统」最终都被纯靠算力支撑的系统打得落花流水。这个剧情在 AI 圈一演再演 —— 从语音识别到计算机象棋,再到计算机视觉,无一例外。
如果 Sutton 今天重写《苦涩的教训》,他一定会把最近大火的生成式 AI 也加入这份「打脸清单」,提醒我们:这条铁律还未失效。
同在 AI 领域,我们似乎还没有真正吸取教训,因为我们仍在重复同样的错误......
我们必须接受这个残酷的现实:在 AI 系统中,强行植入我们认为的思维方式,从长远来看注定失败。这个「苦涩的教训」源于以下观察:
1.AI 研究者总想把人类的知识经验塞进 AI
2. 这招短期确实管用,还能让研究者有成就感
3. 但迟早会遇到瓶颈,甚至阻碍 AI 的进步
4. 真正的突破往往出人意料 —— 就是简单地加大计算规模
站在 AI 研究者的角度,得到了《苦涩的教训》,意味着在总结教训的过程中明确了什么是「更好」的。对于 AI 任务,这很好量化 —— 下象棋就看赢棋概率,语音识别就看准确率。对于本文讨论的 AI 应用产品,「更好」不仅要看技术表现,还要考虑产品性能和市场认可度。
从产品性能维度来看,即产品能在多大程度上取代人类的工作。性能越强,就能处理越复杂的任务,创造的价值自然也就越大。

图 1. 展示了不同类型的 AI 产品,本文主要讨论应用层
AI 产品通常是给 AI 模型加一层软件包装。因此,要提升产品性能,有两条路径:
1. 工程升级:在软件层面利用领域知识设置约束
2. 模型升级:等待 AI 实验室发布更强大的模型
这两条路看似都可行,但在此有个重要洞察:随着模型性能提升,优化工程的价值在不断下降。
现阶段,软件端的设计确实能提升产品表现,但这只是因为当前模型还不够完善。随着模型变得更可靠,只需要将模型接入软件就能解决大多数问题了 —— 不需要复杂的的工程。

图 2. 投入工程的价值会随着投入增加和更强大模型的出现而递减。
上图展示了一个趋势:随着 AI 模型的进步,工程带来的价值将逐渐减少。虽然当前的模型还有明显不足,企业仍能通过工程投入获得可观回报。
这一点在 YC 校友演示日上表现得很明显。创业公司主要分为两类:第一类是已经实现规模化的产品,专注解决简单问题,但数量还不多;第二类则瞄准了相对复杂的问题。后者目前发展势头不错,因为他们的概念验证证明:只要在工程上下足功夫,就能达到预期目标。
但这些公司面临一个关键问题:下一个模型发布会不会让所有工程上的都成为无用功,摧毁他们的竞争优势?OpenAI 的 o1 模型发布就很好地说明了这个风险。
我和很多 AI 应用层的创业者聊过,他们都很担心,因为他们投入了大量精力来完善提示词。有了 o1 后,提示词工程的重要性就大大降低了。
从本质上讲,这种工程的目的是为了约束 AI 少犯错误。通过观察众多产品,可以概括为两类约束:
- 专业性:衡量产品的聚焦程度。垂直型产品专注于解决特定领域的问题,配备了专门的软件包装;而水平型产品则更通用,能处理多种不同类型的任务。
- 自主性:衡量 AI 的独立决策能力。在此借鉴一下 Anthropic 的分类:
1. 工作流:AI 按预设路径运行,使用固定的工具和流程
2. 智能体:AI 可以自主选择工具和方法,灵活决策如何完成任务
这就规定了一个 AI 产品的分类框架:

表 1. 对知名 AI 产品的分类。需要注意的是,ChatGPT 可能每次对话都会遵循预先设定的代码路径,因此更像工作流而非智能体。
以商业分析师制作路演 PPT 为例,看看每类产品如何实现这个任务:
- 垂类工作流:它按固定步骤执行任务,比如,先用 RAG 查询公司数据库,小型 LLM 做总结,大型 LLM 提取关键数据并计算,检查数据合理性后写入幻灯片,最后生成演示文稿。每次都严格遵循这个流程。
- 垂类智能体:LLM 能自主决策,循环工作:用上一步的结果指导下一步行动,虽然可用工具相同,但由 AI 自己决定何时使用。直到达到质量标准才停止。
- 通用工作流:像 ChatGPT 这样的通用工具只能完成部分任务,既不够专业也不够自主,无法完整处理整个工作流程。
- 水平智能体:如 Claude computer-use,能像人一样操作常规办公软件。分析师只需用自然语言下达指令,它就能根据实际情况灵活调整工作方法。
这很好理解 —— 当前的 AI 模型还不够成熟,只能用这种方式才能达到可用水平。结果就是,即使是过于复杂的问题,创业者们也不得不硬塞进这个框架,因为这是目前唯一能让产品勉强可用的方法。
虽然通过工程优化可以提升这些产品,但提升空间有限。对于当前模型难以处理的问题,与其投入大量工程资源,不如等待更强大的模型出现 —— 到时只需很少的工程就能解决问题。
正如 Leopold Aschenbrenner 在《Situational Awareness》中所指出的:「完善这些繁琐的工程,可能比等待更强大的模型还要耗时。」
这不禁让人联想起《苦涩的教训》:AI 研究者反复尝试用工程手段提升性能,最终却总是被简单堆砌算力的通用方案超越。今天的 AI 产品开发似乎正在重蹈覆辙。
把表 1 的内容和《苦涩的教训》联系起来之后,这样能更清楚地看到其中的关联:

总而言之,我的观点是:试图用软件工程来弥补当前 AI 模型的不足,似乎是一场注定失败的战斗,尤其是考虑到模型进步的惊人速度。
正如 YC 合伙人 Jarred 在 Lightcone 播客中所说:「第一波基于固定流程的 AI 应用,大多被新一代 GPT 模型淹没了。」
Sam Altman 常说,要打造那种期待而不是害怕新模型发布的创业公司。我遇到的很多 AI 创业者对新模型都很兴奋,但从他们公司的利益看,这种兴奋可能不太合适。
从统计学角度理解《苦涩的教训》
让我们用简单的统计学来理解这个道理。在做模型时,通常要面临一个选择:要么做一个规则很死板的模型(高偏差),要么做一个灵活但不太稳定的模型(高方差)。《苦涩的教训》告诉我们:选灵活的。
究其原因,因为只要有足够的算力和数据,灵活的模型最终也能变得很稳定。就像打篮球,就算姿势不标准,练得多了也能投准。但反过来就不行了,太死板的方法会被自己的规则限制住。
这跟 AI 产品是一个道理。做垂直领域的工具,加各种限制,就像给 AI 加规则,现在看起来更稳定,但限制了它的潜力。相反,让 AI 更自由一点虽然现在看着不太靠谱,但随着模型越来越强,它反而能找到更好的办法。历史一再证明,跟灵活性对着干是不明智的。
两种做 AI 的方法

图 1:对比了两种方法。传统机器学习需要人工来告诉机器「什么是重要的」,深度学习则能自己学会。
传统机器学习需要人来决定什么信息重要。比如给一张图片,你得手动找出有用的特征,数一数有多少个圆形,测量一下各种尺寸等等。但深度学习不同,它能自己学会找重要的东西。

图 2:比如自动驾驶。系统要识别和跟踪车辆、行人、车道线等具体物体。这就是分解复杂问题的传统方法。
以自动驾驶来说,你有两种方式:
1. 老方法:把车看到的东西分解:前面的车在哪,车道线在哪,那个人跑多快?
2. 新方法:直接把视频扔给 AI,让它自己学会开车。
老方法看着更靠谱,更有把握。所以早期的 AI 都这么干。但正如 George Hotz 所说:「AI 的历史告诉我们,老方法最后总会被新方法打败。」

图 3:DeepMind 研究员 Sholto Douglas:就像其他所有深度学习系统一样,押注端到端就对了
作者简介
博客作者为 Lukas Petersson。今年 26 岁的他于去年从隆德大学毕业,拿下了工程物理和数学双硕士学位。
虽然年轻,但他的经历可谓丰富多彩:

现在他是 Andon Labs 的 CEO 兼联合创始人,专注 AI 安全评估和大语言模型研究。此前,他曾在 Google 实习,曾在 Disney Research 开发病毒式机器人,还曾参与探空火箭发射项目,担任项目主要负责人。
参考链接:
https://x.com/dotey/status/1878595515924820420
https://lukaspetersson.com/blog/2025/bitter-vertical/
#CityGaussianV2
高效重建几何精准的大规模复杂三维场景
是否还在担心大规模场景训练和压缩耗时太长、显存开销太大?是否还在苦恼重建出的建筑物和道路表面破碎不堪?是否还在困扰如何定量衡量大规模场景几何重建的精确程度?

来自中科院自动化所的研究团队提出了用于大规模复杂三维场景的高效重建算法 CityGaussianV2,能够在快速实现训练和压缩的同时,得到精准的几何结构与逼真的实时渲染体验。该论文已接受于 ICLR`2025,其代码也已同步开源。
- 论文题目:CityGaussianV2: Efficient and Geometrically Accurate Reconstruction for Large-Scale Scenes
- 项目主页: https://dekuliutesla.github.io/CityGaussianV2
- 论文链接: https://arxiv.org/pdf/2411.00771
- 代码链接 (600+⭐): https://github.com/DekuLiuTesla/CityGaussian

研究背景
三维场景重建旨在基于围绕目标场景拍摄的一组图像恢复出场景的三维结构,其核心追求是精准的几何结构以及逼真的图像渲染。随着近两年的发展,3D Gaussian Splatting(3DGS)因其训练和渲染效率上的优势逐渐成为该领域的主流算法。这一技术使用一组离散的高斯椭球来表示场景,并使用高度优化的光栅器进行渲染。然而,这一离散且无序的表征形式通常难以很好地拟合物体表面的实际分布,导致重建出的场景几何结构并不精准。近来包括 SuGaR、2DGS、GOF 在内的一系列杰出工作针对这一问题进行了探索,并给出了有效的解决方案。

几何重建质量可视化比较
尽管这些技术在单一目标或小场景上取得了巨大的成功,但它们应用于复杂的大规模场景却往往面临比 3DGS 更加严峻的挑战。上图展现了不同算法在大规模场景下的几何重建效果。SuGaR 的模型容量有限,难以还原精细的几何结构;GOF 受到严重的模糊鬼影的干扰,许多视角下画面被鬼影完全遮挡,以至于监督失效,重建结果面对显著的欠拟合;2DGS 受到模糊鬼影的影响较弱,但也妨碍了其收敛效果,并且退化现象容易诱发高斯基元的过度增长,进而引起显存爆炸,训练难以为继。
此外,大规模场景下长期以来缺少几何重建质量的有效评估手段,已有的工作或只进行了可视化定性比较,或忽视了欠观测区域不稳定的重建效果对指标产生的干扰。大规模场景的重建往往还意味着显著的训练开销,要重建 1.97 平方千米的区域会产生接近两千万的高斯点,这意味着 4.6G 的存储以及 31.5G 的显存开销,以及超过三小时的训练时长。如果要进一步完成压缩,通常还需要额外将近一个小时的时间。
针对这三方面的技术挑战,本文提出了 CityGaussianV2。该算法继承了 CityGaussian 的子模型划分与数据分配方案,并使用 2DGS 作为基元来重建。在此基础上,CityGaussianV2 引入了基于延展率过滤和梯度解耦的稠密化技术,以及深度回归监督,同时合并了训练和压缩过程,得到了端到端的高效。训练管线,不仅有效加速算法收敛,同时保障了稳定、快速、低显存开销的并行训练。
CityGaussianV2 方法介绍
1.场景重建基础
3DGS 使用一组高斯分布表征的椭球对场景进行表征,每个高斯球同时绑定包括不透明度、颜色以及高阶球谐系数等用于 alpha blending 渲染的属性,并通过包含 L1 损失和 SSIM 损失的加权和对渲染质量进行监督。在训练过程中,算法还会根据每个高斯基元的梯度信息进行自适应地分裂和克隆,使得重建效果不佳的区域能够自动被更合适的基元填充。2DGS 旨在增强几何重建精度,并将椭球降维为椭圆面片作为基元表征场景,同时对渲染出的深度和法向量分布施加监督,保证重建表面的平整性。
CityGaussian 旨在将 3DGS 泛化到大场景,首先预训练一个表征全局场景的粗粒度的 3DGS 场,随后将预训练结果划分为一系列子模型,并根据子模型对训练视图渲染的贡献程度为每个子模型分配训练数据。每个子模型随后会用不同的 GPU 并行微调,并在训练结束后进行合并和压缩,得到场景的最终表征。
2.CityGaussianV2 的优化算法

高斯基元优化算法示意图
现有表面重建方案在泛化到大场景时往往展现出收敛迟缓、训练不稳定等问题,导致并行训练失败,难以取得良好的重建效果。我们的算法以泛化能力最好的 2DGS 为基元,在引入 Depth-Anything-V2 的伪深度监督提供几何先验的基础上,进一步提出了新的高斯基元稠密化方案。我们观察到,在复杂大规模场景上,2DGS 在早期训练阶段比 3DGS 受到更严重的模糊伪影的干扰,导致在迭代次数有限的情况下性能显著劣于 3DGS。为了缓解这一问题,我们引入梯度解耦策略,利用对图像结构差异更为敏感的 SSIM 损失作为稠密化的主要梯度来源:

此处 ω 用于控制梯度的尺度;另外在大规模场景下用 2DGS 进行重建的障碍在于其退化现象。实验证据表明,当从远距离或侧面视角渲染时,部分面片可能会退化成线或点,尤其是那些延展率比较高的面片。对于那些具有高不透明度的投影点,它们的移动往往意味着像素值的剧烈变化,从而使得它们获得较高的梯度,并在稠密化过程中大量增殖,导致基元数量指数级增长,最终导致显存爆炸问题。为了解决这一问题,在稠密化过程中,我们对容易引起退化和梯度集中的具有极端延展率的高斯面片进行了筛选,并对其增殖过程进行了限制,从而在不牺牲性能的情况下有效稳定了训练过程,保障了优化过程的顺利进行。
3.CityGaussianV2 的并行训练管线

CityGaussianV2 训练管线,虚线框为摒弃的算法流程
CityGaussianV2 在 V1 的基础上进一步优化了并行训练管线,使得训练和压缩过程得到统一,删除了冗余的后处理流程。具体而言,算法在子模型的并行训练过程中周期性地遍历训练视角集合 V_m 并计算每个高斯基元的重要性分数:


其中 P_k 为第 k 张训练视图的像素几何,α_n 为第 n 个基元的不透明度。以此为基础,重要性低于一定百分比阈值的基元会被删除,从而降低显存和存储的开销,使得训练对于低端设备更友好,也显著加速了模型总体的收敛速度。
4.大规模重建几何评估协议

大规模场景几何精度评估流程
CityGaussianV2 填补了大规模场景下几何评测协议长期以来的空白,在 Tanks and Temple (TnT) 数据集的启发下,基于点云的目击频次统计设计了针对大规模场景欠观测区域的边界估计方案。具体而言,点云真值会首先被初始化为 3DGS,在遍历所有训练视图的同时记录每个点的观测频次,观测频次低于阈值的点将被滤除;剩余的点将用于估计垂直方向的高度分布范围,以及地平面内的多边形外接轮廓,二者构成的 Crop Volume 进一步用于 TnT 形式的指标计算。这一方案有效规避了欠观测区域重建效果不稳定带来的指标波动,使得大规模复杂场景的几何性能评估更为客观公正。
实验与分析

与主流算法的性能对比

几何重建质量可视化比较
在实验中,相比于已有算法,CityGaussianV2 在几何精度(精度 P,召回率 R,综合指标 F1-Score)方面达到了最佳的性能表现。从可视化结果中也可以看到,CityGaussianV2 的重建结果具有更准确的细节,完整性也更高。而渲染质量方面,CityGaussianV2 则达到了和 V1 相媲美的程度,能够带来逼真的浏览体验。此外,CityGaussianV2 还能较好地泛化到街道景观,并且在渲染质量和几何精度上都取得良好的性能结果。

渲染质量可视化比较

街拍场景可视化比较

高斯基元数量相近情况下的重建性能及训练开销比较
在训练开销方面,CityGaussianV2 克服了 2DGS 泛化到大规模复杂场景下的种种挑战,不仅有效规避显存爆炸问题,而且实现了相对于 V1 显著的显存优化,同时在训练用时和几何质量方面大幅领先。针对 2DGS 的量化压缩策略也使得大规模场景的重建结果能够以 400M 左右的开销存储下来。
总结
本工作致力于大规模复杂场景的高效精准重建,并建立了大规模场景下的几何精度评估基准。所提出的 CityGaussianV2 以 2DGS 为基元,消除了其收敛速度和扩展能力方面的问题,并实现了高效的并行训练和压缩,从而大大降低了模型的训练成本。在多个具有挑战性的数据集上的实验结果证明了所提出方法的效率、有效性和鲁棒性。
#MobileAgent
UIUC与阿里通义实验室推出新型多层级手机智能体 攻克复杂任务场景 可自我进化
项目主页:https://x-plug.github.io/MobileAgent/
论文地址:https://arxiv.org/abs/2501.11733
在如今的智能手机时代,手机的使用已然成为人们日常生活的重要组成部分。除了娱乐,用户还需要应对许多繁琐耗时的任务,例如跨购物平台比价、检索和记录信息等。
尽管现有的移动智能助手在简单指令和单个应用上已有不错的表现,但面对复杂推理、多步规划及跨应用操作的任务,往往难以胜任。此外,这些助手通常没有自我学习提升的能力,每次任务都如“从零开始”。
针对上述挑战,伊利诺伊大学香槟分校(UIUC)与阿里巴巴通义实验室联合推出了一种全新的智能体框架:Mobile-Agent-E。它采用分层多智能体架构,结合长期记忆与自我进化模块,不仅提升了复杂任务的解决能力,还能够通过反思过往经验不断改进交互效率。
我们先来看一个例子,用户想要购买一个全新的任天堂Switch手柄,并要求在三个不同的网购App上对比价格并找到最便宜的选项。Mobile-Agent-E成功完成了这一复杂长流程任务,而以往SOTA仅达到了约50%的完成度。

Mobile-Agent-E:全新层次化多智能体框架层次化多智能体架构
Mobile-Agent-E 的第一个核心创新在于采用层次化多智能体协同框架,显式区分高层规划与低层动作执行,极大增强了长远规划能力与错误修复能力。

Mobile-Agent-E 由一个高层管理智能体和四个执行智能体组成:
- 管理者(Manager):负责高层次推理与任务规划,基于用户请求分解子目标,并参考长期记忆中的捷径(Shortcuts)优化规划。当低层任务失败时,管理者会接手调整策略。
- 感知者(Perceptor):由视觉感知模块组成,用于识别截图中的细粒度文本和图标信息,包括 OCR、图标识别和描述生成功能。
- 操作员(Operator):根据管理者提供的计划,执行具体操作(如点击、滑动)。操作员同时利用提示(Tips)和捷径(Shortcuts)优化操作效率。
- 动作反思者(Action Reflector):通过对比动作前后的状态,判断操作是否成功,并生成反馈。
- 记录员(Notetaker):在任务中记录关键信息,例如价格、电话号码等,为后续任务提供参考。
通过这种分工协作的架构,Mobile-Agent-E 实现了在复杂任务中的高效运作,例如在多个购物平台间比价并找到最优选项。
下图展现了具体任务执行过程中,各个智能体的输入和输出:

自我进化模块
Mobile-Agent-E 独创了自我进化模块,赋予智能体类似人类逐渐熟练使用手机的能力。该模块包括两种知识形式:
- 提示(Tips):从过往任务中总结出的交互指导和经验教训,类似于人类的情景记忆。
- 捷径(Shortcuts):由多个原子操作组成的技能,适用于重复性子任务,类似程序性知识。
提示和捷径被存储在长期记忆中,并在每次任务完成后通过经验反思优化更新。例如,“点击输入框-输入文本-回车”的操作仅在页面有输入框时可用,反思模块会验证其适用性并优化使用条件。

基准测试与实验结果Mobile-Eval-E Benchmark
为验证 Mobile-Agent-E 的性能,研究团队设计了新的基准测试集 Mobile-Eval-E,专注于多步骤、多应用交互任务。相比现有测试集,其任务平均操作步骤翻倍,且超 76% 涉及跨应用场景。

评价指标
研究团队提出了全新的评价指标——满意度得分(Satisfaction Score, SS),综合评估关键步骤完成度与探索行为。此外,还设计了满意度-步骤曲线(SSS 曲线),直观展示不同模型在效率上的差异。
实验结果
实验显示,Mobile-Agent-E 在多种基础模型上均超越现有 SOTA,尤其是启用自我进化模块后,满意度得分提高了 33.9% 。


SSS 曲线表明,Mobile-Agent-E 能以更少的步骤实现更高满意度,展现了卓越的效率。

更多分析
- Mobile-Agent-E 随任务增多表现显著提升:
-

- 捷径的引入显著加快了任务执行速度:
-

案例研究
当模型在执行大量任务和应对多种场景时,积累的提示(Tips)和捷径(Shortcuts)可能会多到无法全部纳入决策上下文。
为了解决这一问题,作者引入了两个经验检索代理(Experience Retriever),从经过优化的长期记忆中提取与新任务最相关的提示和捷径。
如下图案例研究所示,Mobile-Agent-E 能够高效检索并利用高度相关的提示和捷径,从而成功完成一个具有挑战性的全新任务。这一探索为未来构建完全闭环的自我进化手机智能体开辟了新的可能性。

实机演示
以下视频展示了更多Mobile-Agent-E操作真实安卓手机的例子:
,时长01:24
,时长01:15
,时长01:07
* 视频经过加速处理
展望
Mobile-Agent-E 的推出标志着移动智能体从简单场景应用迈向更多真实世界中的复杂任务。尤其其自我进化能力为未来发展提供了广阔空间,后续研究可聚焦于更强的自主进化能力、个性化优化及安全性提升等。
#谷歌新一代Gemini全型号
冲击DeepSeek R1,谷歌发布新一代Gemini全型号刷榜,编程、物理模拟能力炸裂
Jeff Dean:一次生成就能出正确代码。
在 DeepSeek 的强烈攻势下,这次轮到谷歌坐不住了。
本周三,该公司全面发布 Gemini 2.0 Flash、 Gemini 2.0 Flash-Lite 以及新一代旗舰大模型 Gemini 2.0 Pro 实验版本,并且还在 Gemini App 中推出了其推理模型 Gemini 2.0 Flash Thinking。

下图为三个模型在通用、代码、推理、事实性、多语言、数学、长上下文、图像、音频和视频等多领域任务中的性能指标。

在大模型排行榜上,Gemini 2.0-Pro 在 Chatbot Arena 所有类别中排名第一。Pro 版在代码等复杂任务上表现突出,Gemini Advanced 用户目前已经可以在 App 上进行试用了。

与此同时,排名并列第三的 Gemini-2.0-Flash 已通过 Google AI Studio 和 Vertex AI 向开发人员广泛开放(价格是 0.1 美元 / M token),Flash-lite 也以更低的成本进入了前十。谷歌还在 Gemini 应用程序中推出了旗下「推理」模型 Gemini 2.0 Flash Thinking。
新版本 Gemini 2.0 可以做到很多以前做不到的事。谷歌首席科学家 Jeff Dean 表示 Gemini 2.0 Pro 模型可以编写完整的代码,包括所有正确的数据结构和搜索算法,一次尝试就可以获得正确的数据结构。
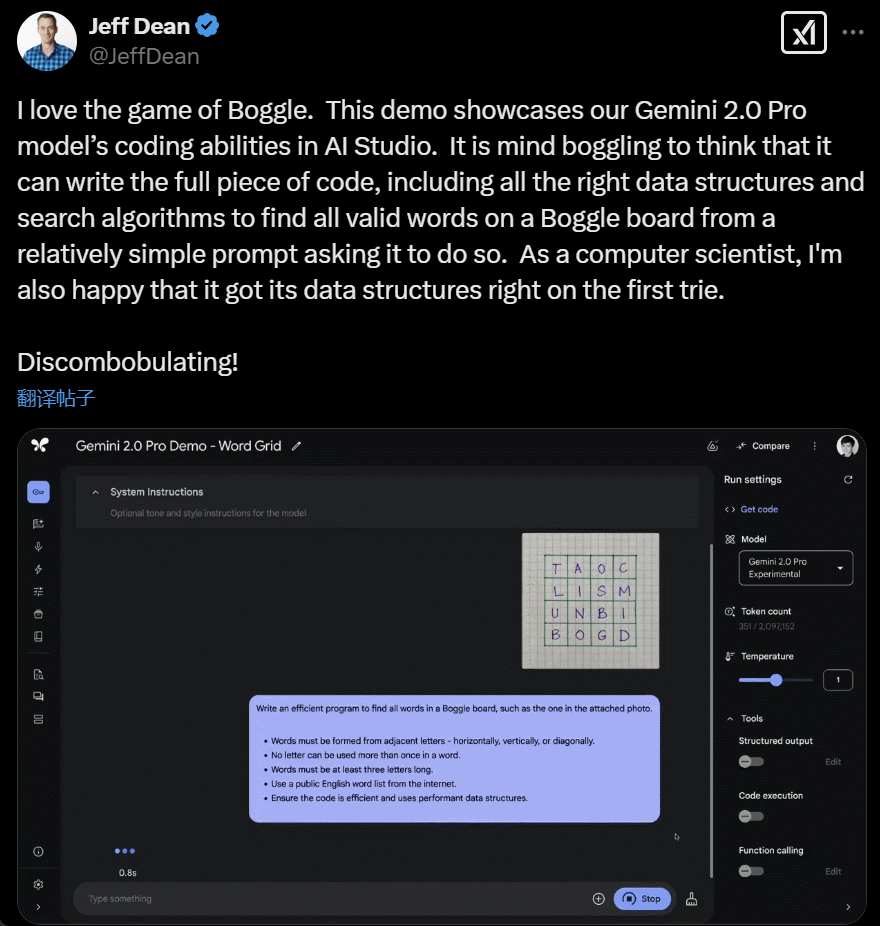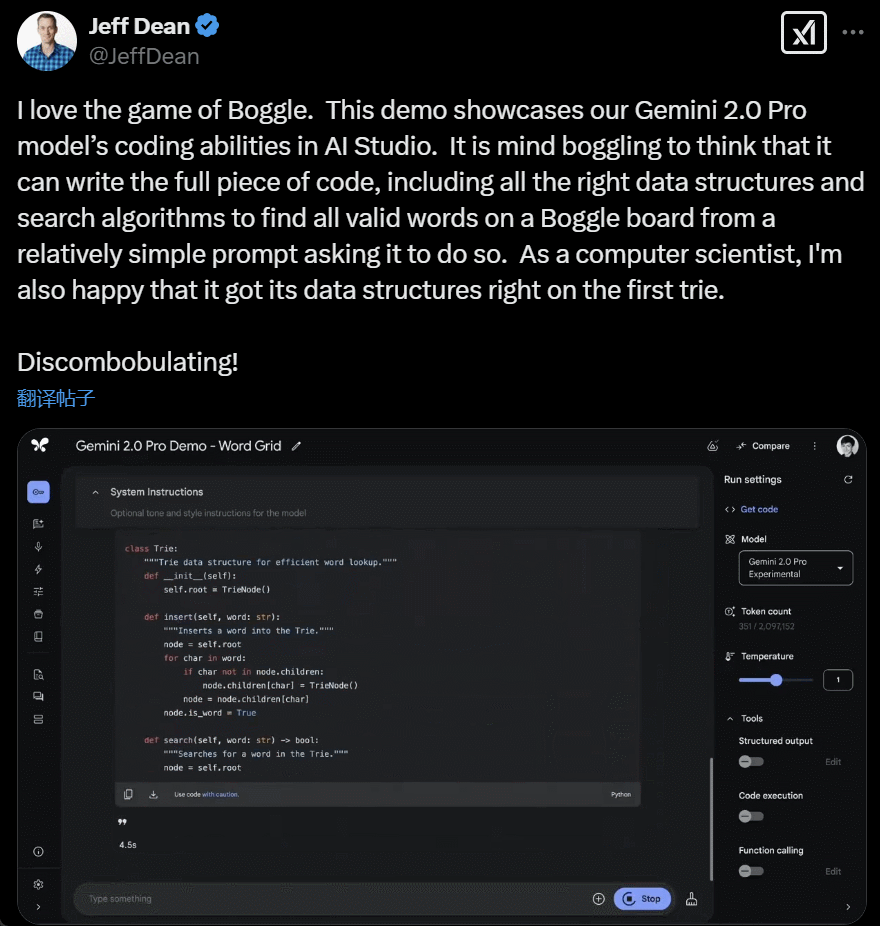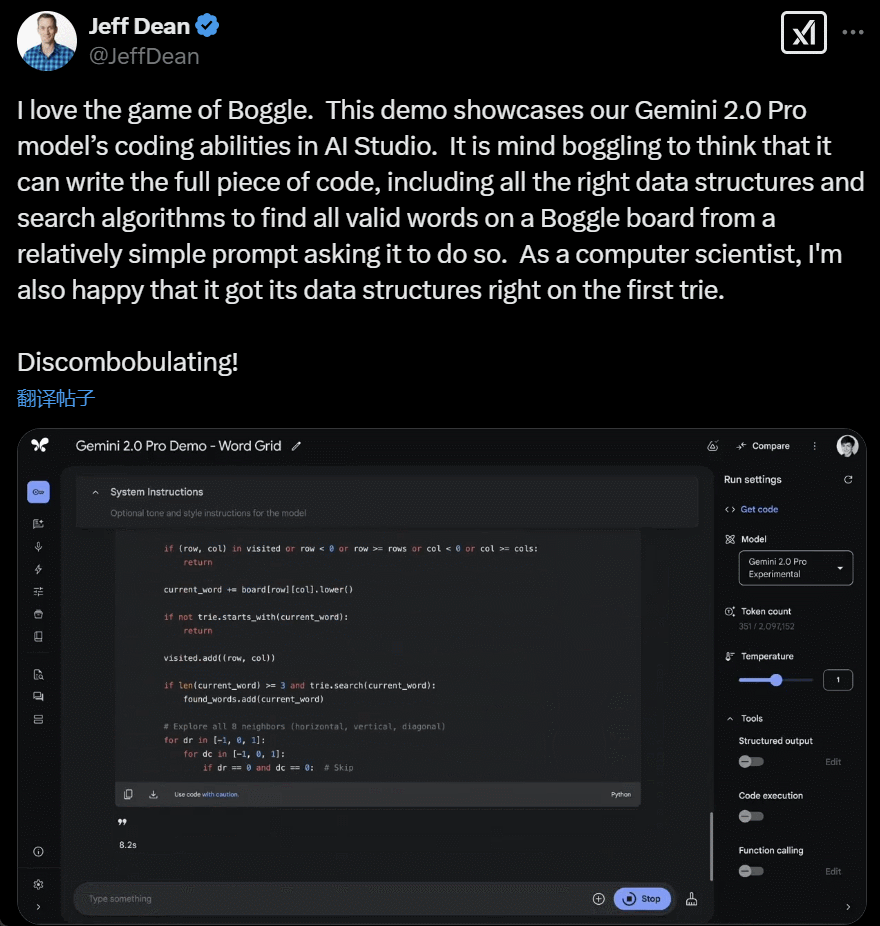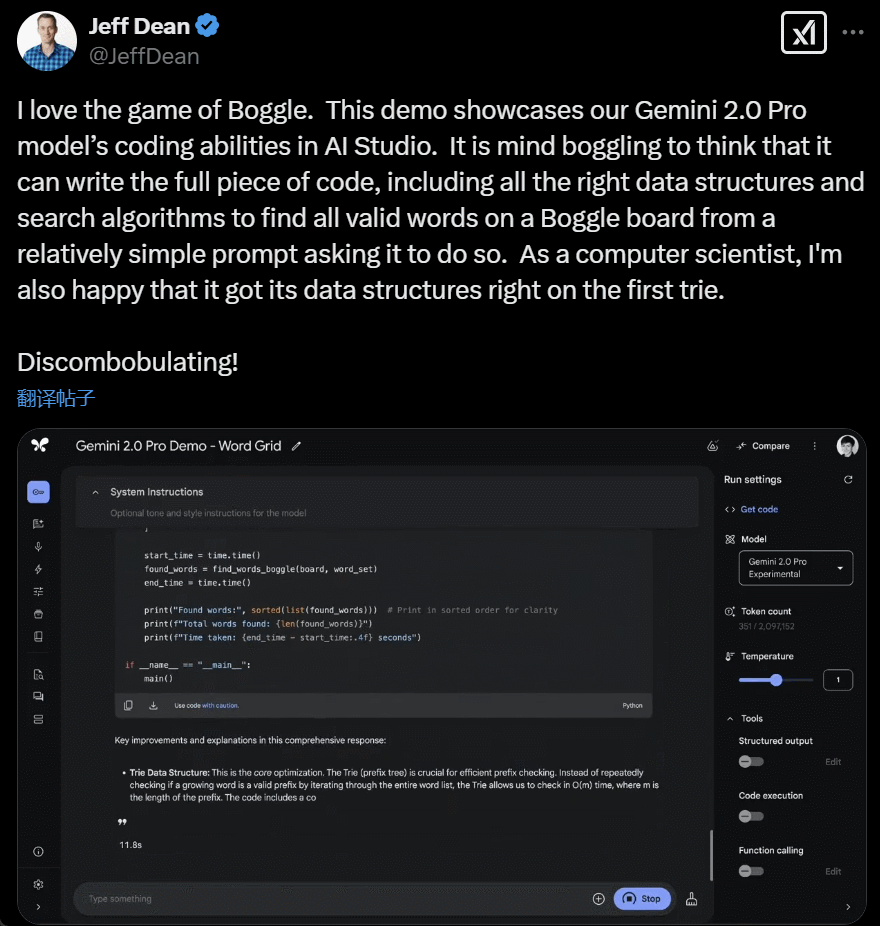
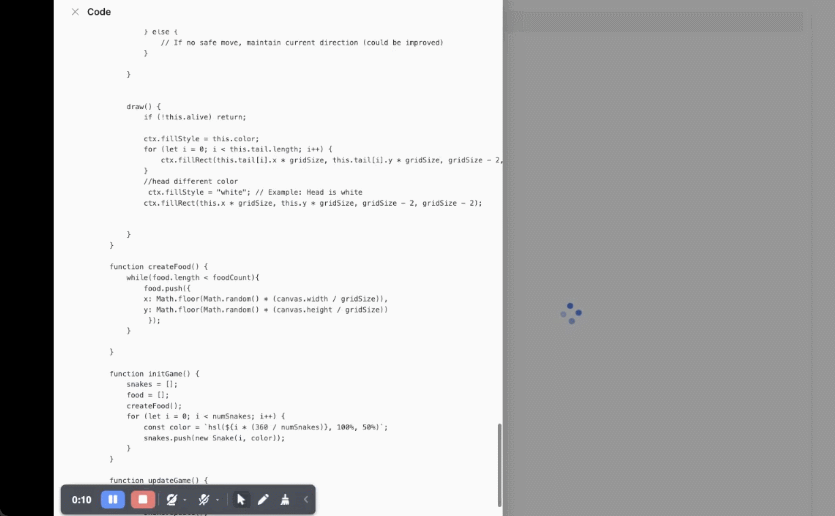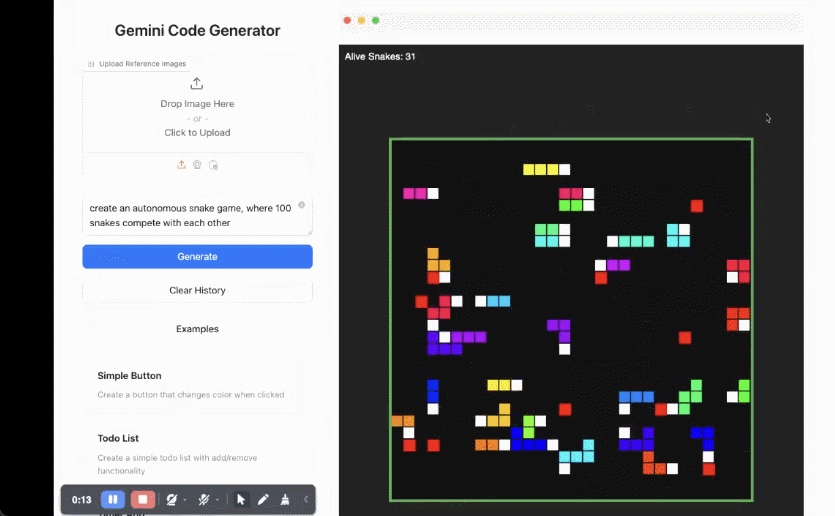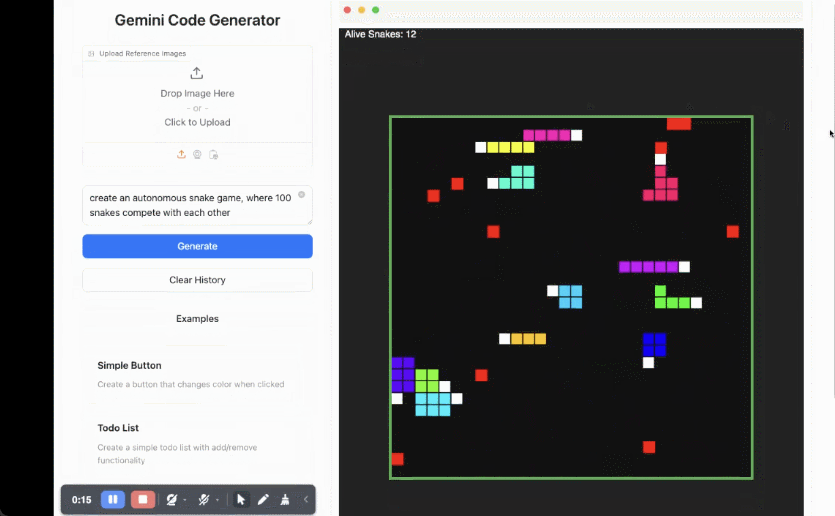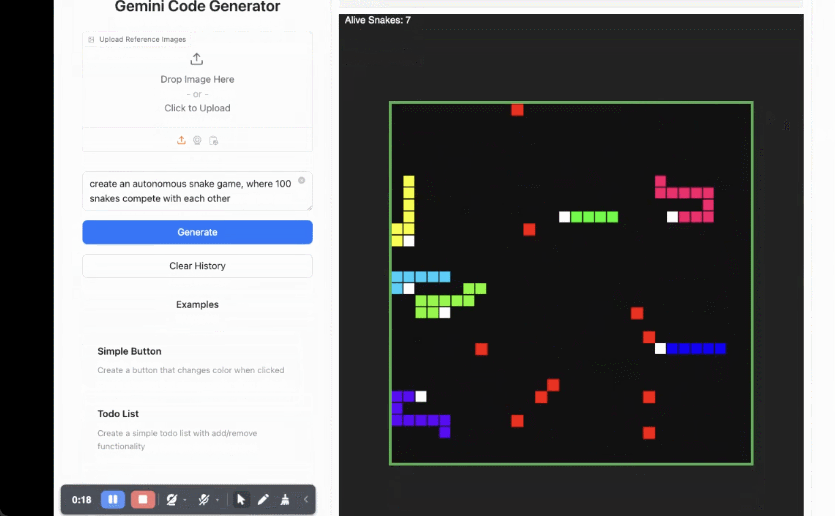
更多第三方试用的结果也已陆续出现在社交网络上,可见 Gemini 2.0 的性能提升明显,可以生成代码实现一些模拟物理规律的效果。
提示词:创建一个自行动的贪吃蛇游戏,其中 100 条蛇相互竞争。(单次尝试)
提示词:编写一个脚本,显示一个球在旋转的六边形内弹跳。球应该受到重力和摩擦力的影响,并且必须逼真地从旋转的墙壁上弹起,在 p5.js 中实现。(单次尝试)
提示词:编写一个 p5.js 脚本,模拟圆柱形容器真空空间中的 25 个粒子,它们在容器边界内弹跳。为每个球使用不同的颜色,并确保它们留下显示其运动的轨迹。添加容器的缓慢旋转,以便更好地查看场景中发生的事情。确保创建适当的碰撞检测和物理规则,以确保粒子留在容器中。添加外部球形容器。为整个场景添加缓慢放大和缩小效果。

种种迹象表明,进入 2025 年之后,全球大模型领域的竞争烈度又上了一个台阶。谷歌正式发布 Gemini 2 系列的同时,OpenAI 立即作出回应,宣布将其 AI 搜索功能面向所有免费用户开放。

值得注意的是,有媒体报道称在谷歌发布新模型之际,科技界的注意力仍然集中在 DeepSeek 上。DeepSeek 的模型在性能上媲美甚至超越了美国科技公司提供的领先 AI 模型。与此同时,企业可以通过 DeepSeek 的 API 以相对低廉的价格使用其模型。
谷歌和 DeepSeek 都在去年 12 月发布了 AI 推理模型,但 DeepSeek 的 R1 模型获得了更多关注。现在,谷歌可能正试图通过其广受欢迎的 Gemini app,让更多人了解其 Gemini 2.0 Flash Thinking 模型。
至于 Gemini 2.0 Pro,作为谷歌去年 2 月推出的 Gemini 1.5 Pro 模型的继任者,谷歌表示它现在是 Gemini AI 模型家族中的领先模型。
在价格方面,谷歌将继续通过 Gemini 2.0 Flash 和 2.0 Flash-Lite 降低成本。两者均采用单一输入类型的定价模式,取消了 Gemini 1.5 Flash 中对短上下文和长上下文请求的区分。这意味着,尽管 2.0 Flash 和 Flash-Lite 在性能上有所提升,但在混合上下文工作负载下,两者的成本可能低于 Gemini 1.5 Flash。

谷歌 Gemini 2.0 三大模型:全方位加强
Gemini 2.0 Pro 实验版本
首次是新一代旗舰 Gemini 2.0 Pro 实验版本,它是谷歌迄今为止在编码和复杂指令任务中表现最好的模型。
在 Gemini 2.0 早期实验版本中(如 Gemini-Exp-1206),开发人员已经发现了这些模型的优势和最佳用例,比如编码、复杂指令。
此次,Gemini 2.0 Pro 实验版本进一步强化了这些功能,具备了最强大的编码性能和处理复杂指令的能力,并且比谷歌此前发布的任何模型都具备更好的理解和推理世界知识的能力。
据介绍,该模型支持了谷歌最长的 200 万 tokens 上下文窗口,可以处理 2 小时视频、22 小时音频、6 万+ 行代码和 140 万 + 单词,从而能够全面分析和理解海量信息。同时,该模型还支持调用 Google 搜索和代码执行等工具。
目前,Gemini 2.0 Pro 已经作为实验模型提供给 Google AI Studio 和 Vertex AI 的开发人员使用,并且 Gemini Advanced 用户在桌面和移动设备中也可以体验。

Gemini 2.0 Flash
其次来看 Gemini 2.0 Flash,它是谷歌 Flash 系列模型的最新「成员」。
在 2024 年谷歌 I/O 大会上,Gemini 2.0 Flash(实验版本)首次亮相,此后便作为强大的主力模型而深受开发者的喜爱,并最适合大规模处理高容量、高频率任务,并能够通过 100 万 tokens 上下文窗口对海量信息进行多模态推理。
当前,Gemini 2.0 Flash 已经在谷歌的 AI 产品中向更多人全面开放使用。据介绍,该模型提供了全面的功能,包括原生工具使用。目前支持文本输出,并即将推出图像生成与文本转语音功能,未来几个月还将提供多模态 Live API。
目前,用户既可以在 Gemini App 中试用该模型,也可以在 Google AI Studio 和 Vertex AI 中使用 Gemini API。

Gemini 2.0 Flash-Lite
最后是 Gemini 2.0 Flash-Lite,它是谷歌目前为止性价比最高的模型。该模型针对大规模文本输出用例进行了成本优化。

谷歌表示,他们收到了关于 Gemini 1.5 Flash 在价格和速度方面的积极反馈,并希望在保持成本与速度优势的同时继续提升模型质量。因此,Gemini 2.0 Flash-Lite 在性能上更强,在大多数基准测试中均优于 1.5 Flash,并且速度和成本相当。
此外,与 2.0 Flash 一样,Gemini 2.0 Flash-Lite 支持 100 万 tokens 上下文窗口和多模态输入。比如,该模型可以为大约 4 万张不同的照片生成相关的单行字幕(或标题),在 Google AI Studio 付费套餐中仅花费不到 1 美元。
目前,Gemini 2.0 Flash-Lite 在 Google AI Studio 和 Vertex AI 中提供公开预览版。
下图为三个模型的一些参数汇总,可以看出图像和音频功能即将上线。

改变游戏规则?
Gemini 2.0 全面开放后,其领先能力在机器学习社区被热烈讨论。有评论认为,在这代模型推出后包括 OCR 等一些领域的游戏规则已被改变。

Gemin 2.0 在处理真实文档时已经可以做到极高的准确率和低成本,实测很少会出现具体数值被误读的情况。除了表格解析之外,Gemini 在 PDF 到 Markdown 转换的所有其他方面可以始终提供近乎完美的准确性。所有特性结合在一起,你将获得一个极其简单、可扩展且便宜的索引流程。

我们一直在等的大模型技术革命,已经在很多领域出现了。
参考链接:
https://developers.googleblog.com/en/gemini-2-family-expands/
https://blog.google/technology/google-deepmind/gemini-model-updates-february-2025/
https://techcrunch.com/2025/02/05/google-launches-new-ai-models-and-brings-thinking-to-gemini/
https://news.ycombinator.com/item?id=42952605
#广义关联回忆(Generalized Associative Recall, GAR)
大模型会组合关系推理吗?打开黑盒,窥探Transformer脑回路
本文作者为北京邮电大学网络空间安全学院硕士研究生倪睿康,指导老师为肖达副教授。主要研究方向包括自然语言处理、模型可解释性。该工作为倪睿康在彩云科技实习期间完成。联系邮箱:ni@bupt.edu.cn, xiaoda99@bupt.edu.cn
人类拥有一种强大的能力,能够理解多个实体之间复杂的关系并基于这些关系进行推理,这被称为组合关系推理(Compositional Relational Reasoning, CRR)。这种能力不仅是智能的标志,也是我们应对日常问题和复杂任务的核心技能。那么,像 GPT 这样的大型语言模型(LLM)是否具备这种能力?它们又是如何在内部处理这种任务的?为了回答这个问题,研究者开发了一个新的基准测试,称为广义关联回忆(Generalized Associative Recall, GAR),专门用来评估 LLM 在组合推理任务中的表现,并进一步研究模型如何解决这些任务。论文《Benchmarking and Understanding Compositional Relational Reasoning of LLMs》已被 AAAI 2025 接收。本工作由北京邮电大学和彩云科技合作完成。
- 论文地址:https://arxiv.org/abs/2412.12841
- 代码地址:https://github.com/Caiyun-AI/GAR
GAR 基准测试
研究者注意到,目前大多数用于测试 LLM 的任务要么过于简单,只能用于可解释性分析,无法真实反映模型在复杂推理场景下的表现,要么过于复杂,不适合深入研究模型的内部机制。因此,他们设计了 GAR,一个更加多样化和具有挑战性的基准测试。GAR 整合了多个经典任务(如 knowledge recall、associate recall、Indirect Object Identification (IOI) 等),并通过不同的任务形式(如肯定 / 否定句、生成 / 分类任务)和难度等级,系统地考察模型的推理能力。
简单来讲(更多例子见下图 1 和图 2):
- associate recall 就是从前文 “抄写”:前文说了 “小明有苹果”,后文再说 “小明有__”,就知道要填 “苹果”;
- knowledge recall 就是记到 “脑子” 里的各种常识知识:苹果是一种__(水果),巴黎在__(法国)
- IOI 就是排除(否定):【苹果、狗、苹果】哪个不是苹果?__(狗)
GAR 的特点是:
1. 挑战性足够高:即使是最先进的 LLM,在 GAR 任务上的表现也并不理想,暴露了它们在组合推理能力上的缺陷。
2. 适合深入研究:GAR 任务相对简单的生成过程,使得研究者能够更好地追踪模型内部的推理机制。

图 1 广义关联回忆(Generalized Associative Recall, GAR)任务构建框架。GAR 任务的设计流程包括三个步骤:选择关系模式(如 “same” 或 “kindOf”)、采样数据构建关系环(结合语义与语法关系)以及生成语句并引入语义和句法变体(如否定形式或主宾交换),图中左中右部分分别展示了关系环的构建、任务数据的生成与语句的多样化处理,体现了 GAR 在任务灵活性和复杂度上的优势

图 2 GAR 任务示例。任务分为两大类:生成式(填空题,补全最后一个词)和判别式(判断题,回答 Yes 或 No)
现有模型的表现
通过对主流开源(如 Llama-2/3 7B/13B/33B/70B)和闭源模型(如 GPT-3.5/4)的测试发现:
- 任务难度显著影响表现:当任务的推理步骤或复杂度增加时,模型的正确率会明显下降。
- “组合性差距(Compositionality Gap)”:模型在回答任务的各个子问题时可能表现良好,但无法正确组合这些答案以得出最终结论。例如,模型能回答对 “【小明有苹果,小红有狗】小明有__(苹果)”(前文抄写),对 “苹果是一种__(水果)”(常识)和 “【小明、小红】里哪个不是小红?__(小明)”(否定排除)也毫无压力,但把它们组合起来:“【小明有苹果,小红有狗】小红没有一种__(水果)”,模型就很容易蒙圈(在不允许 CoT 的情况下)。
- 模型规模与性能:虽然更大的模型在一些任务上表现更好,但它们的 “组合性差距” 往往更明显,这表明增加模型规模并不能完全解决这个问题。

图 3 (a) 不同 LLM 在 GAR 上的表现。本图比较了生成任务(Gen.)和分类任务(Cls.)的平均准确率和正确答案的预测概率,随着模型规模增大,准确率和答案概率均呈正相关增长

图 3 (b 左) GPT-4 和 Vicuna-33B 在不同难度的生成式任务上的表现,通过增加非相同语义关系和引入否定语义变体调整任务难度;(c 中) 组合性差距随模型规模的变化, Llama 系列模型随规模增大而表现出更大的组合性差距,反映出 LLM 在组合关系推理中的不足;(d 右) 语法变化差距随模型规模的变化,句法变体对模型性能影响较小,表明模型对语法变化的敏感性较低
GAR 任务还有个很有趣的特点:尽管它对最先进的 LLM 都具有挑战性,它对人类来说却非常简单:研究者评估,在具备必要知识(如国家 - 首都关系)的情况下,人类完成任务的准确率超过 90%。并且通过实验表明,LLM 回答错误并不是因为缺少这些事实性知识。这揭示了 LLM 在组合关系推理上存在某些根本性缺陷。
模型内部的推理机制
为了更好地理解 LLM 如何解决 GAR 任务,研究者采用了归因补丁(attribution patching)的方法。这种技术可以帮助发现模型在推理过程中依赖的关键计算单元,特别是某些注意力头的作用。值得指出的是,这里无论任务难度、回路复杂度还是模型大小,都远超已有模型可解释性工作。研究发现:
- 核心回路:Vicuna-33B 模型中存在一组通用的核心回路,能够被不同任务重复利用。
- 注意力头的作用:研究者识别出两类关键注意力头(True head 和 False head),它们的激活状态分别表示抽象的 “真” 和 “假” 的概念。进一步的实验表明,这些头在不同任务和模型中都扮演了重要角色,是组合推理能力的基础。

图 4 (a 左) True head 子回路 (b 右) False head 子回路

图 4 (c) 判别回路

图 4 (d) 肯定式生成回路

图 4 (e) 否定式生成回路
研究者发现,无论哪种回路,从更高的层次看,都包含我们称之为 “relational loop” 的由注意力边组成的闭环。这和构造 GAR 任务时的关系环是一致的。研究者认为正是这些闭环的存在保证了可预测性。
通过干预关键注意力头提升 LLM 表现
注意到 True/False 头在图 4 的所有回路中都有出现并扮演了关键角色。为了验证 Vicuna 模型中的 True/False 头的通用性和有效性,并探讨其在不同模型规模上的一致性。研究者选择了三个具有代表性的分类任务:由 GendersOfPersons 关系模式分别与 CountriesOfCities (CoC)、KindsOfThings (KoT) 和 UsagesOfThings (UoT) 三个关系模式组合作为数据源。首先,利用 attribution patching 识别不同规模的 Vicuna 模型(Vicuna-7B/13B/33B)的 True/False 头。随后,在模型推理过程中对 True/False 头进行干预:当答案为 Yes/No 时,对 True/False 头施加干预,同时屏蔽 False/True 头,以观察其对模型判断的影响。

图 5 (a 左) 干预 Vicuna-7B 的 True / False heads 提升判别任务的准确率,干预后模型准确率分别提高了 17%/14%/6%,证明 True/False 头在各个模型中均表现出一致的效果;(b 右) True / False heads 的激活区分真 / 假陈述,通过可视化 True 和 False 头的激活值,发现它们有效地区分了真假语句。这表明,True/False 头编码了真假概念,并在 GAR 任务中起到了判断语句真伪的关键作用
研究意义
这项研究首次明确指出了 LLMs 在组合关系推理任务中的核心缺陷,并通过实验揭示了模型内部的关键推理机制。这不仅加深了我们对 LLMs 工作原理的理解,也为模型改进提供了启发和洞见。例如:
- 优化注意力机制:通过改进关键注意力头的功能,可以显著提升模型的推理能力,例如研究团队的 DCFormer 工作 [1] 的最早期想法就是分析 LLM 在类似 GAR 任务上的表现启发而来的。。
- 设计更具多样性的基准:在真实世界任务中测试和改进模型的组合推理表现。
#LLaVA-Mini
每张图像所需视觉token压缩至1个,兼顾效率内存
以 GPT-4o 为代表的实时交互多模态大模型(LMMs)引发了研究者对高效 LMM 的广泛关注。现有主流模型通过将视觉输入转化为大量视觉 tokens,并将其嵌入大语言模型(LLM)上下文来实现视觉信息理解。然而,庞大的视觉 token(vision token)量显著增加了 LMMs 的计算复杂度和推理延迟,尤其在高分辨率图像或视频处理的场景下,效率问题愈加突出。因此,提高多模态大模型的计算效率成为实现低延时实时交互的核心挑战之一。

为了应对这一挑战,中国科学院计算技术研究所自然语言处理团队创新性的提出了高效多模态大模型 ——LLaVA-Mini。通过对 LMMs 中视觉 tokens 处理过程的可解释性分析,LLaVA-Mini 将每张图像所需的视觉 tokens 压缩至 1 个,并在确保视觉理解能力的同时显著提升了图像和视频理解的效率,包括:计算效率提升(FLOPs 减少 77%)、响应时延降低(响应延时降至 40 毫秒)、显存占用减少(从 360 MB / 图像降至 0.6MB / 图像,支持 24GB GPU 上进行长达 3 小时的视频处理)。
- 论文题目:LLaVA-Mini: Efficient Image and Video Large Multimodal Models with One Vision Token
- 论文链接:https://arxiv.org/abs/2501.03895
- 开源代码:https://github.com/ictnlp/LLaVA-Mini
- 模型下载:https://huggingface.co/ICTNLP/llava-mini-llama-3.1-8b
多模态大模型如何理解视觉 Tokens?
为了在减少视觉 token 的同时保持视觉理解能力,研究者首先分析了 LMMs 如何处理和理解大量视觉 token。分析集中在 LLaVA 架构,特别从注意力机制的角度探讨了视觉 token 的作用及其数量对 LMMs 性能的影响。具体而言,实验评估了视觉 token 在 LMMs 不同层中的重要性,涵盖了多种 LMMs,以识别不同规模和训练数据集的模型之间的共性。

视觉 token 在 LMMs 不同层中获取的注意力权重

LMMs 中不同层的注意力可视化
分析发现:
1. 视觉 token 在前几层中的重要性较高:在 LMMs 的前几层,视觉 token 获得了更多的注意力,但随着层数增加,注意力迅速转向指令 token(文本),超过 80% 的注意力集中在指令 token 上。这表明,视觉 token 主要在前层发挥作用,文本 token 通过注意力机制从视觉 token 中获取视觉信息,而后续层则依赖于已经融合视觉信息的指令 token 来生成回复。
2. 大部分视觉 token 在前几层中被关注:如上图注意力可视化所示,早期层中几乎所有视觉 token 都受到均匀关注,而在后期层,模型则集中注意力于少数几个视觉 token。这表明,直接减少所有层中的视觉 token 数量不可避免地会导致视觉信息的丢失。
更多分析请参考论文。通过预先分析,研究者发现视觉 token 在 LMMs 的早期层中起着至关重要的作用,在这一阶段,文本 token 通过关注视觉 token 融合视觉信息。这一发现为 LLaVA-Mini 极限压缩视觉 token 的策略提供了重要的指导。
LLaVA-Mini 介绍
LLaVA-Mini 使用视觉编码器将图像编码为若干视觉 token。为了提升效率,LLaVA-Mini 通过压缩模块大幅减少输入 LLM 底座的视觉 token 数量。为了在压缩过程中保留视觉信息,基于先前的研究发现,视觉 token 在早期层中对于融合视觉信息至关重要,LLaVA-Mini 在 LLM 底座之前引入了模态预融合模块,将视觉信息融入文本 token 中,从而确保视觉理解能力。

视觉 token 压缩
LLaVA-Mini 通过基于查询的压缩模块(query-based compression)减少输入 LLM 底座的视觉 token 数量。为学习视觉 token 的压缩,LLaVA-Mini 引入若干可学习的压缩查询(query),通过交叉注意力机制与所有视觉 token 交互,选择性提取关键的视觉信息,生成压缩后的视觉 token。当压缩查询数量为 1 时,LLaVA-Mini 仅用一个视觉 token 表示一张图像。
模态预融合
视觉 token 的压缩不可避免地会丢失部分视觉信息。为了在压缩过程中尽可能保留更多的视觉信息,LLaVA-Mini 在 LLM 底座前引入模态预融合模块,文本 token 预先融合来自所有视觉 token 的相关视觉信息。基于之前的发现,视觉文本信息融合通常发生在 LLM 底座的早期层,而 LLaVA-Mini 将这种融合过程显示地提取到 LLM 外部进行,从而减少计算量。
最终,LLaVA-Mini 将输入 LLM 底座的 token 数量从 “576 个视觉 token+N 个文本 token” 压缩至 “1 个视觉 token+ N 个模态融合 token”。通过此,LLaVA-Mini 能够更高效地完成图像理解和视频理解。
实验结果
在本文的实验中,研究者在 11 个图像理解基准和 7 个视觉理解基准上评估了 LLaVA-Mini 的性能以及效率优势,以下是所得的关键实验结果。
图像理解评估

如上表所示,研究者在 11 个基准测试上比较了 LLaVA-Mini 和 LLaVA-v1.5。结果表明,LLaVA-Mini 仅使用 1 个视觉 token(压缩率 0.17%),远低于 LLaVA-v1.5 的 576 个视觉 token,取得与 LLaVA-v1.5 相当的图像理解能力。
视频理解评估

如上表所示,LLaVA-Mini 在视频理解上优于目前先进的视频 LMMs。这些视频 LMMs 使用大量视觉 token 表示每帧(224 或 576),受限于上下文长度,仅能提取 8-16 帧,可能导致部分视频信息丢失。相比之下,LLaVA-Mini 通过 1 个视觉 token 表示每张图像,能够以每秒 1 帧的速度提取视频帧,从而在视频理解上表现更佳。
长视频理解评估

研究者进一步将 LLaVA-Mini 与先进的长视频 LMMs(能够处理超过 100 帧的视频)在长视频基准 MLVU 和 EgoSchema 上进行比较。
如上表所示,LLaVA-Mini 在长视频理解上具有显著优势。通过将每帧表示为一个视觉 token,LLaVA-Mini 在推理时能够轻松扩展到更长的视频,并且通过 token 之间的位置编码隐式建模时序关系。特别地,LLaVA-Mini 仅在少于 1 分钟(< 60 帧)的视频上进行训练,且在推理时能够处理超过 2 小时(> 7200 帧)的长视频。
LLaVA-Mini 效率提升

效率优势是 LLaVA-Mini 的一大亮点。如上图所示,与 LLaVA-v1.5 相比,LLaVA-Mini 显著减少了 77% 的计算负载,实现了 2.9 倍的加速。LLaVA-Mini 的响应延迟低于 40 毫秒,这对于开发低延迟实时 LMMs 至关重要。

视频处理是 LMMs 面临的另一个挑战,特别是在显存消耗方面。上图展示了 LMMs 在处理不同长度视频时的内存需求。以往的方法每张图像需要约 200-358 MB 的内存,使得它们在 40GB GPU 上仅能处理约 100 帧。相比之下,LLaVA-Mini 仅需 0.6 MB 内存即可处理每张图像,理论上可在 24GB 内存的 RTX 3090 上支持处理超过 10,000 帧的视频。
视觉 token 压缩效果

为验证 LLaVA-Mini 将图片压缩成 1 个视觉 token 的有效性,上图可视化了压缩过程中的交叉注意力。在不同类型和风格的图像(如照片、文本、截图和卡通图)中,LLaVA-Mini 的压缩展现了强大的可解释性,能够有效地从图像中提取关键的视觉信息。
总结
LLaVA-Mini 是一个统一的多模态大模型,能够高效地支持图像、高分辨率图像和视频的理解。LLaVA-Mini 在图像和视频理解方面表现出色,同时在计算效率、推理延迟和内存使用上具有优势,促进了高效 LMM 的实时多模态交互。
不过,LLaVA-Mini 也存在一些局限,主要表现在处理一些 OCR 等精细化视觉任务时,压缩成 1 个视觉 token 势必会影响其性能。但由于 LLaVA-Mini 的灵活性,在使用时可根据具体场景设置压缩后的视觉 token 数量,从而在性能和效率中取得权衡。
#数学真理的极限在哪里?
希尔伯特第十问题扩展版得到证明
数学世界充满了无法触及的角落,那里存在着许许多多无法解决的问题。现在,又一个角落被照亮了。
1900 年,著名数学家大卫・希尔伯特(David Hilbert)公布了一份清单,其中包含 23 个关键问题,并希望以此指导下个世纪的数学研究。他的问题不仅为数学领域提供了路线图,还反映了一个更雄心勃勃的愿景 —— 建立一个坚实的基础,使得所有数学真理都可以基于此推理出来。
这个愿景很宏大,而其中的一大关键是假定数学是「完备的(complete)」。也就是说,所有数学陈述都应该可以被证明为真或假。
1930 年代,库尔特・哥德尔(Kurt Gödel)证明这是不可能的:在任何数学系统中,都有既不能证明也不能证伪的陈述。几年后,艾伦・图灵(Alan Turing)等人基于他的工作,表明数学充斥着「不可判定(undecidable)」的陈述 —— 即任何计算机算法都无法解决的问题。
这些结果表明,证明和计算的能力存在一些根本性限制。有些数学根本无法被人知晓。
希尔伯特的梦想破灭了。但它的碎片依旧继续存在着。他曾提出的那些问题仍会让人想起他的愿景,使「完备数学」的理念可在更狭窄的语境下生存。
在这些问题中,第十问题是最主要的一个,其与丢番图方程(又称不定方程)有关。丢番图方程是指有整数系数的多项式,例如 x² + y² = 5。我们很熟悉这些方程,而它们也是数学领域最核心的研究对象之一。几千年来,数学家一直在寻找它们的整数解。例如,在这个例子中,一个解是 x = 1,y = 2(因为 1² + 2² = 5)。另一个是 x = 2,y = −1。
大卫・希尔伯特
x² + y² = 3 等许多丢番图方程却可能没有任何整数解。希尔伯特的第十问题是:是否总是可以判断给定的丢番图方程是否有整数解。是否存在一种算法可以确定每个方程的解,还是说这个问题是不可判定的?也许不可能为所有数学问题找到一种完备而系统的求解方法 —— 甚至不可能解决希尔伯特的所有 23 个问题 —— 但对于丢番图方程,可能仍然存在一种求解方法,作为希尔伯特理想的一个微缩版本。乌得勒支大学的 Peter Koymans 说:「这个问题是那个梦想的一个非常自然的版本。」
1970 年,一位名叫 Yuri Matiyasevich 的俄罗斯数学家打破了这个梦想。他的研究表明,并不存在一种可以确定任何给定的丢番图方程是否有整数解的通用算法 —— 希尔伯特第十问题是一个不可判定的问题。你也许能够构想出一种可以评估大多数方程的算法,但它无法适用于每一个方程。
即使在这种最简单的数学中,也隐藏着不可知性。
Yuri Matiyasevich,摄于 1969 年
数学家们想检验 Matiyasevich 的结论的适用范围。比如如果允许丢番图方程有复数解(可以用实部和虚部写出的数字,并且不限于整数)呢?在这种情况下,每个丢番图方程都有一个解,而希尔伯特第十问题的答案是肯定的。但是,在解必须是整数的方程和解可以是复数的方程之间,丢番图方程还存在很广的范围。
「对于整数,它是不可求解的,然后当传递给更大的数字系统时,可能会突然获得可解性。」哈佛大学的 Barry Mazur 说。「但这个转折点在哪里?」
自希尔伯特第十问题被解决以来的 50 年里,数学家们一直在寻找这个转折点。现在,Koymans 和他的长期合作伙伴、蒙特利尔康考迪亚大学的 Carlo Pagano 以及另一组独立研究的团队朝着这一目标迈出了重要一步。
这两个小组都证明,对于整数之外的大量重要数集,同样不存在可确定任意给定的丢番图方程是否有解的通用算法。这两项工作不仅让数学家能够更精确地了解他们能知道什么和不能知道什么,还让他们对数学中最核心的对象之一有了全新的控制水平。
- 论文标题:Hilbert's tenth problem via additive combinatorics
- 论文地址:https://arxiv.org/abs/2412.01768
- 论文标题:Rank stability in quadratic extensions and Hilbert's tenth problem for the ring of integers of a number field
- 论文地址:https://arxiv.org/abs/2501.18774
从整数开始扩展
这些新证明的核心是希尔伯特第十问题的一种自然扩展。该扩展涉及的丢番图方程的解属于一个与整数密切相关的数字系统。
从 1 和 -1 开始,可以通过不同的组合方式得到所有其它整数。但如果是从 1、-1、和
![]()
开始呢?通过不同组合方式,也能得到一个数字系统,这被称为整数环(ring of integers)。很显然,名字虽然是整数环,但这个数字系统中并不只有整数。使用其它的数字集合也能构建其它的整数环,比如可包括
![]()
(也就是虚数 i)或
![]()
。
那么,问题来了:是否存在一种算法,可以总是确定给定丢番图方程的解是否属于某个整数环?
Carlo Pagano
数学家猜想,对于每一个整数环(即无限多个数字系统),这个问题仍然是不可判定的。这将使该结论远远超出希尔伯特第十问题初始的整数范围。
为了证明这一点,他们希望追随原始问题的证明脚步 —— 仅涉及整数解的问题。
一般来说,不可判定性证明(确定是否存在可以回答给定问题的通用算法的证明)遵循相同的方法:证明相关问题等价于计算机科学中一个著名的不可判定问题,即停机问题(halting problem)。停机问题问的是:对于一个理想的计算设备(称为图灵机),当给定某个输入时,该设备将永远运行还是最终会停止?现在人们已经知道,并不存在一个可为每台图灵机解答这个问题的算法。
也可以将丢番图方程视为计算设备。以方程 y = x² 为例。它有无穷多个整数解。只需为 x 代入不同的整数并求解 y,得到的值都属于一个著名的整数集:完全平方数(the perfect squares)。我们很容易就能想象出一个能执行其等价任务的计算机程序(即图灵机):「计算完全平方数的序列」。
其它丢番图方程也可以编码成其它类型的计算。
Julia Robinson
为了解决希尔伯特最初的第十问题,数学家们以这个想法为基础开始了研究。Julia Robinson 等人于 1950 年左右开始研究,最终汇集成了 1970 年 Matiyasevich 的成果。研究结果表明,对于每个图灵机,都有一个对应的丢番图方程。「这完全出乎意料,」智利天主教大学的 Hector Pasten 说。「基于整数的丢番图方程足以定义你能想象到的任何东西。」
此外,数学家们还建立了一种优雅的对应关系:如果图灵机因给定输入而停止,其对应的丢番图方程将有一个整数解。如果图灵机永远运行,其对应的丢番图方程将没有解。但这意味着希尔伯特第十问题编码了停机问题:如果一种算法可以根据是否有整数解对丢番图方程进行分类,那么该算法也可用于根据是否会停机对图灵机进行分类。
换句话说,希尔伯特第十问题是不可判定的。
数学家们希望采用同样的方法来证明该问题扩展的整数环版本 —— 但他们遇到了一个障碍。
将研究成果黏合起来
当允许方程有非整数解时,图灵机和丢番图方程之间的有用对应关系就会瓦解。再次以方程 y = x² 为例。如果你研究的是包含
![]()
的整数环,那么你最终会得到一些新的解,例如 x =
![]()
, y = 2。该方程不再对应于计算完全平方数的图灵机 —— 更广义地说,丢番图方程不再能编码停机问题。
但在 1988 年,纽约大学的一名研究生 Sasha Shlapentokh 开始想办法解决这个问题。到 2000 年,她和其他一些研究者制定了一个计划。假设你要为 y = x² 添加一些其它项,从而可迫使 x 再次为整数,即便要使用不同的数字系统。然后,你可以挽救与图灵机的对应关系了。那所有丢番图方程都可以这样做吗?如果可以,那就意味着希尔伯特问题可以在新的数字系统中编码停机问题。
多年来,Shlapentokh 等数学家弄清楚了他们必须在各种环的丢番图方程中添加哪些项,这使他们能够证明希尔伯特问题在这些设置下仍然无法判定。然后,他们将所有剩余的整数环归结为一种情况:涉及虚数 i 的环。数学家们意识到,在这种情况下,必须添加的项可以使用一类名为椭圆曲线(elliptic curve)的特殊方程来确定。
但椭圆曲线必须满足两个属性。首先,它需要有无限多个解。其次,如果切换到不同的整数环 —— 如果从数字系统中移除虚数 —— 那么该椭圆曲线的所有解都必须保持相同的底层结构。
事实证明,构建这样一条适用于所有剩余环的椭圆曲线是一项极其微妙和困难的任务。但 Koymans 和 Pagano—— 从研究生阶段就开始就密切合作的椭圆曲线专家 —— 拥有合适的工具集来进行尝试。
许多个不眠之夜
从本科开始,Koymans 就一直在思考希尔伯特第十问题。在就读研究生以及在与 Pagano 合作期间,这个问题一直在召唤他。「我每年都会花几天时间思考这个问题,但总是陷入困境,」Koymans 说。「我尝试了三种方法,但它们都失败了。」
2022 年,在加拿大班夫举行的一次会议上,他和 Pagano 最终聊到了这个问题。他们希望能够一起构建出解决这个问题所需的特殊椭圆曲线。在完成了其它一些项目后,他们开始了研究。
Peter Koymans
他们从一个简单的椭圆曲线方程开始,这个方程不满足任何所需的属性。他们知道他们可以使用一种名为二次扭曲(quadratic twist,这是他们已经研究了近十年的东西)的成熟技术来调整方程,使其满足第一个条件。他们只需将方程的一个变量乘以一个特定的数字,他们就会得到一条有无限多个解的新椭圆曲线。
但这给他们留下了一个问题。他们无法保证这条新曲线满足第二个性质 —— 对于相差一个虚数的环,其解看起来会很相似。数学家们需要更好地控制二次扭曲。
他们陷入困境。「我有一种不好的感觉,」Koymans 说。「我开始怀疑我们遗漏了什么东西。」
然后,在 2024 年夏天,在研究另一个问题时,两人不得不再次使用二次扭曲。一天晚上,在这项研究过程中,科伊曼斯发现自己躺在床上睡不着,无法停止思考希尔伯特第十问题。
Koymans 意识到,另一项工作给了他们一个重要的提示,即那些有时会出现的奇怪且惊人的数学一致性(mathematical concordance):如果他们在二次扭曲中使用的数字恰好是三个素数的乘积,则他们就会获得保证第二个性质所需的控制权。但是,由于他们的椭圆曲线必须精心构建并满足许多规范,因此对这三个素数的取值有很多额外的限制。Koymans 和 Pagano 能找到可行的素数吗 —— 不管对于哪个整数环?
几天后,Pagano 碰巧计划访问当时 Koymans 工作的瑞士苏黎世联邦理工学院。接下来的一周,他们一起在黑板上努力寻找满足所有限制的素数。最后,他们发现必须使用四个素数而不是三个素数来构建所需的二次扭曲。这使得他们能够应用一种来自完全不同的数学领域的方法,即加性组合学(additive combinatorics),以确保每个环都存在正确的素数组合。
这就是最后一部分:他们构建了所需的椭圆曲线。它为他们提供了向丢番图方程添加项所需的方法,这使他们能够将图灵机(以及停机问题)编码到这些方程中,而不管他们使用什么数字系统。一切都解决了。希尔伯特第十问题对于每个整数环都是不可判定的。
上周四,在 Koymans 和 Pagano 在线发布他们的论文不到两个月后,结果得到了进一步巩固。一个由四名数学家组成的独立团队宣布了对同一结果的新证明。他们没有寻找特殊的椭圆曲线,而是依靠一种不同类型的方程来完成同样的工作。
这两个团队都希望利用他们的技术(这些技术使他们对椭圆曲线和相关方程有了前所未有的控制)在其他问题上取得进展。普林斯顿大学数学家、第二个证明的作者之一 Manjul Bhargava 说:「这两种方法有可能结合起来做更多的事情。」
与此同时,对不可判定性终结以及可判定性开始的位置的探索尚未结束:数学家们正在新的环境中继续探索希尔伯特第十问题。
蒙特利尔大学的 Andrew Granville 认为,这只是众多问题中的一个,这些问题「反映了世界哪些部分为真的哲学方面」。
所有知识都有极限。Granville 说:「它提醒我们,有些事情是无法做到的 —— 无论你是谁,无论你有怎样的身份或才智。」
原文链接
https://www.quantamagazine.org/new-proofs-probe-the-limits-of-mathematical-truth-20250203/
#Image-Generation-CoT
图像生成迎来CoT时刻,港中文首次提出文生图o1推理新范式
Paper link:https://arxiv.org/pdf/2501.13926
Project link:https://github.com/ZiyuGuo99/Image-Generation-CoT
Author:Ziyu Guo, Renrui Zhang, Chengzhuo Tong, Zhizheng Zhao, Peng Gao, Hongsheng Li, Pheng-Ann Heng
随着OpenAI o1展示了思维链Chain-of-Thought(CoT)对于大模型推理能力的强大提升,各种基于强化学习RL和Test Time Scaling的方案已经在大模型理解领域取得了很大的进展。然而,在图像生成(Image Generation)领域,如文生图(Text-to-Image)及文生视频(Text-to-Video),是否也可以借鉴CoT相关的策略,来提升图片或视频的质量和文本一致性?
来自香港中文大学、北京大学、和上海AI Lab的研究者们通过Verify和Reinforce的方案,系统地探索了“CoT推理+文生图”的结合与潜力。研究结果表明,这些方法能够有效提升自回归(Autoregressive)图像生成的质量,作者也提出了两种专门针对该任务的新型奖励模型——潜力评估奖励模型(Potential Assessment Reward Model,PARM) 及其增强版本 PARM++,后者引入了反思机制(Reflection Mechanism),进一步优化了图像生成质量。
第一作者是香港中文大学Muliar Lab的博士生,本科毕业于北京大学,曾在Amazon、Roblox、上海人工智能实验室、腾讯等机构实习,研究多模态大模型和3D视觉,一作代表作有Point-LLM、PointCLIP、SAM2Point等。

Z Highlights:
- 首次将OpenAI o1的“CoT思维链推理”应用到文生图的场景中,开启“图像生成+推理”的新方向。
- 全面探索各种推理策略在文生图上的潜力,例如Inference Computation Scaling和DPO Preference Alignment。
- 提出PARM和PARM++,两个专门针对于文生图场景的奖励模型reward model,极大提升了图片生成的质量。
01 自回归图像生成具有与大模型类似的推理架构
目前,CoT推理已广泛应用于大语言模型(LLM)和多模态大模型(LMM),尤其在数学推理、科学计算等任务上展现出卓越的能力。然而,在自回归图像生成任务中,如何有效地验证(Verify)和强化(Reinforce)图像生成过程,仍是一个尚未解决的问题。

左图展示了目前领域使用“CoT推理+解数学题”的方案,右图展示了本研究对于“CoT推理+文生图”的全面探索。
研究团队观察到,自回归图像生成与LLM/LMM具有类似的推理架构,即:
1.离散化Token表示:无论是语言还是图像数据,自回归模型都将其量化为离散Token,并通过逐步预测的方式进行生成。
2.逐步解码(Step-by-Step Decoding):类似于 CoT 在数学问题上的逐步推理,自回归图像生成也可以逐步生成中间图像,并在生成过程中进行验证与优化。
02 CoT如何应用于图像生成?
考虑到Autoregressive图像生成和LLM在数据表征和推理架构的相似性,研究团队调研了包括使用ORM和PRM的Test-time Verification、构造Preference Ranking Data、和通过DPO进行偏好对齐等方案,首次证明了“CoT+文生图”的可行性。同时也提出了两种新型的reward model——PARM和PARM++,用来优化图像生成质量。如下图所示,通过本研究探索的推理策略,大幅度提升了Autoregressive Image Generation的效果。

本研究的探索以“文生图”为任务场景,并使用Show-o作为baseline模型,主要分为3个部分:
测试时验证(Test-time Verification)
首先,论文探索如何使用Reward Model进行Test-time Verification,实现了Outcome Reward Model(ORM)和Process Reward Model(PRM)方案,并在两者的基础上提出了两种全新的针对于图像生成任务的Potential Assessment Reward Model(PARM)和PARM++。

结果奖励模型(Outcome Reward Model,ORM)
论文提出了2种方案,均使用Best-of-N的方式进行验证,即进行多次完整路径的生成,并从中选择出质量最高的最终图片。
- Zero-shot ORM:基于LLaVA-OneVision强大的图像理解能力,作者使用了其7B模型,直接作为zero-shot ORM使用,并通过下面的prompt来激发其作为文生图质量评估的能力:

- Fine-tuned ORM:为了进一步增强ORM的专业性能,作者也构建了大规模的图文reward data来得到fine-tuned ORM,数据形式如下图所示:

过程奖励模型(Process Reward Model,PRM)
作者使用了类似ORM的方案,同样尝试了Zero-shot和Fine-tuned两种方案,并对每个step进行Best-of-N的方案,即逐步选择出质量最高的中间阶段的生成图片。然而,作者发现这种naive的PRM无法对图像生成有显著的提升。通过可视化,作者发现:PRM 在早期生成阶段由于图像模糊而难以评估,而在后期生成阶段不同路径的图片趋于相似,导致辨别能力受限。

潜力评估奖励模型(Potential Assessment Reward Model,PARM)
为了同时结合ORM的简洁和有效性,以及PRM细粒度逐个step验证的思想,作者提出了一个专门针对Autoregressive图像生成任务的reward model:Potential Assessment Reward Model(PARM)。PARM 通过以下三步提升图像生成质量:
- 清晰度判断(Clarity Judgment):识别哪些中间步骤的图像已经足够清晰,可用于后续评估。
- 潜力性评估(Potential Assessment):分析当前步骤是否有潜力生成高质量的最终图像。
- 最佳选择(Best-of-N' Selection):在高潜力路径中选择最佳的最终图像。


潜力评估奖励模型++(Potential Assessment Reward Model++,PARM++)
如下图所示,在PARM的基础上,作者提出了PARM++,使模型能够在生成错误时进行自我修正。具体来说,基于PARM选出的最终图片,作者首先使用PARM++评估生成图片是否符合文本描述;若图片不符合要求,会要求RM提供详细的错误描述,并根据该描述,要求生成模型进行自我修正(Self-correction),即模型接收反馈,并参考错误信息重新生成结果。结果表明,PARM++进一步提升GenEval+17%。如下图所示,生成结果在物体数量、颜色、空间关系等方面更加准确。

直接偏好优化(DPO)Alignment
作者进一步引入DPO偏好对齐,即使用大规模排名数据训练模型,使其生成结果更符合人类偏好。研究团队构建了 288K 条图文排名数据(Text-to-Image Ranking Data)用于训练。具体来说,训练过程是采用最大似然优化,调整模型输出,使其更偏向人类偏好。同时,论文也进一步使用迭代 DPO(Iterative DPO),在模型优化后重新生成新数据进行再次训练。结果表明,初次DPO训练使模型在GenEval 性能提升+9%,而迭代DPO进一步提高至+12%,超越Fine-tuned ORM。
Test-time Verification + DPO Alignment
在前述两种方法的基础上,作者探索了将Test-time Verification与DPO 对齐相结合的策略,以实现端到端的优化。在DPO训练的模型基础上,进一步应用Test-time Verification进行筛选,使生成图像质量更高,文本一致性更强。实验结果表明,结合DPO和Test-time Verification后,模型在GenEval指标上的整体提升达+22%,超越单独使用DPO或Test-time Verification的方案。

03 效果超越现有扩散模型和自回归模型
模型在GenEval基准上的总体性能比较,相比于现有的扩散模型和自回归模型,结果证明了在文本生成图像任务中使用CoT推理策略的潜力。

本研究首次系统性探索了 CoT 推理策略在自回归图像生成中的适应性及潜力。通过全面的实验分析证明了不同的推理策略(如测试时验证、偏好对齐及其结合)能够有效提升图像生成质量。基于这些观察,本文进一步提出了两种专门针对自回归图像生成的奖励模型——潜在评估奖励模型(PARM)和PARM++,前者能够对逐步生成过程进行自适应奖励评分,后者则结合了反思机制(Self-reflection),实现自我修正的图像生成。实验结果表明,CoT 推理在自回归图像生成任务中展现出了巨大的潜力,为该领域的发展开辟了新的方向,也为大模型推理能力的进一步提升奠定了基础。
原文:Can We Generate Images with CoT? Let’s Verify and Reinforce Image Generation Step by Step Ref.
https://ziyuguo99.github.io/
#DeepSeek绕开CUDA垄断
英伟达护城河还在吗?
你以为的:DeepSeek 绕过 CUDA 使用 PTX。
实际上的:DeepSeek 通过在 CUDA 代码里塞入一堆 PTX 代码来优化 CUDA 性能,然后和其他现成 CUDA 工具链结合,在可接收的开发时间内完成了开发,换成别的 GPU 还是做不到。
英伟达的护城河是 CUDA 的生态,而不是 CUDA 本身,而 PTX 是 CUDA 生态的一环
CUDA 生态包括高级 API 和丰富的工具链,庞大的库和框架支持,而这些在其他显卡生态上都还不够完善。
PTX 是 CUDA 的汇编,你可以理解为 CUDA 是一步一步翻译到显卡能照着执行的代码的,PTX 是 CUDA 的下一步。
现阶段的用 PTX 开发,是指把 PTX 插入到 CUDA 代码里,比如
// CUDA 内核函数,用于向量相加
__global__ void vectorAdd(const float* A, const float* B, float* C, int N) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < N) {
float a = A[idx];
float b = B[idx];
float c;
// 插入 PTX 汇编代码
asm volatile(
"add.f32 %0, %1, %2;" // PTX 汇编指令:将 %1 和 %2 相加,结果存入 %0
: "=f"(c) // 输出操作数:c
: "f"(a), "f"(b) // 输入操作数:a 和 b
);
C[idx] = c;
}
}常见的误区PTX 编程是整个代码用 PTX 写
PTX 的开发效率特别低,PTX 现在只被用来优化某些关键部分,是以镶嵌在 CUDA 里的形式存在的。
PTX 是跨芯片的
PTX 肯定不是跨芯片的,AMD 上与之对应的概念是 GCN ISA。
兼容 PTX 是分分钟的事
CUDA 编译后的结果是 PTX,要是兼容 PTX 简单,显卡厂商早拿着 CUDA 编译出来的中间结果到自己显卡上跑了,事实上,兼容 PTX 比兼容 CUDA 更难。
误解护城河的含义
我们现在说的英伟达的护城河一直是他做得更快(包括开发更快以及跑得更快),而不是其他显卡不能做。
CUDA 生态的东西太多了,其他生态的东西相比之下又太贫瘠了,DeepSeek 这个事件不仅没有说明 CUDA 护城河的消失,反而是在证明 CUDA 护城河仍然坚固。
只有当以下事件发生时,才是大众理解的护城河消失的征兆
- 其他显卡的理论性能超过英伟达
- 发生类似华为制裁导致的生态大迁徙(比如完全禁用 N 卡,被迫开始重复造轮子),丰富了其他生态
CUDA 护城河会破吗
其实,从业者一直是相信 CUDA 不会永远一家独大的,近几年越来越多的业务开始用 AMD 的显卡,尤其是推理侧。过往是迁移到其他显卡的成本太大,但是随着英伟达吃相越来越难看,N 卡越来越不划算,这个迁移是肉眼可见的。
但是,我最想吐槽的点就是,DeepSeek 用 PTX 这件事,和打破 CUDA 护城河是一点关系都没有,甚至这个事情应该是 CUDA 护城河的体现。
硬要扯上关系,就是未来其他显卡的生态需要一群高水平的从业者来开发,DeepSeek 如果愿意的话,他们有这个能力来完成这个事情,但到底能不能实现,还要看包括 DeepSeek 在内的高级开发者是否愿意为爱发电做迁移,或者是其他显卡展现出足够的潜力。
但是,CUDA 地位动摇这件事早已有之,和 DeepSeek 真是一点关系都没有,用 PTX 来优化 CUDA 至少三年前就开始大规模在干了,而且仍然是 CUDA 护城河内部的事情,现在突然被拿出来东拼西凑了一个故事。
这个问题火了,而且评论区吵得厉害,我觉得有争议的点不是护城河,而是城本身,也就是训练用的显卡的需求会变少吗,这是一般认为 Nvidia 股价下跌的主要原因
DeepSeek 推出后 Nvidia 的股价下跌意味着什么
DeepSeek 提出了一个新颖的算法,用 1/10 的成本在 N 卡上完成了训练,证明训练大模型不需要那么多显卡,又因为训练大模型一直是用 N 卡,所以 Nvidia 的股票跌的厉害。
也就是
- N 卡仍然是训练时的主流(目前大模型竞赛需要的领域)
- 但是未来训练端需要的显卡可能会变少
所以以今天的情况来看,N 卡的总需求可能会因为训练端需要的显卡变少而减少。
可能减少是因为微软 CEO 在第二天提出了一个有意思的观点
杰文斯悖论:蒸汽机发明了,煤炭就少用了吗?提高资源使用效率反而可能增加其总消耗量。
这个观点认为技术进步提高了资源使用效率,效率提高降低了资源使用成本,成本下降刺激了资源需求的增长,需求增长可能超过效率提升带来的节约,最终导致资源总消耗增加。
举一些例子就是:
- 蒸汽机发明提高了煤炭的利用效率,但是每年煤炭的需求反而在提高
- LED 照明技术比传统更节能,全球照明用电需求仍在上升
- 家电能效提升,但家庭总用电量仍在增长
- 数据中心的能效提高,数据中心能耗仍在上升
数据来源:2020-2025 电力电量分析与展望
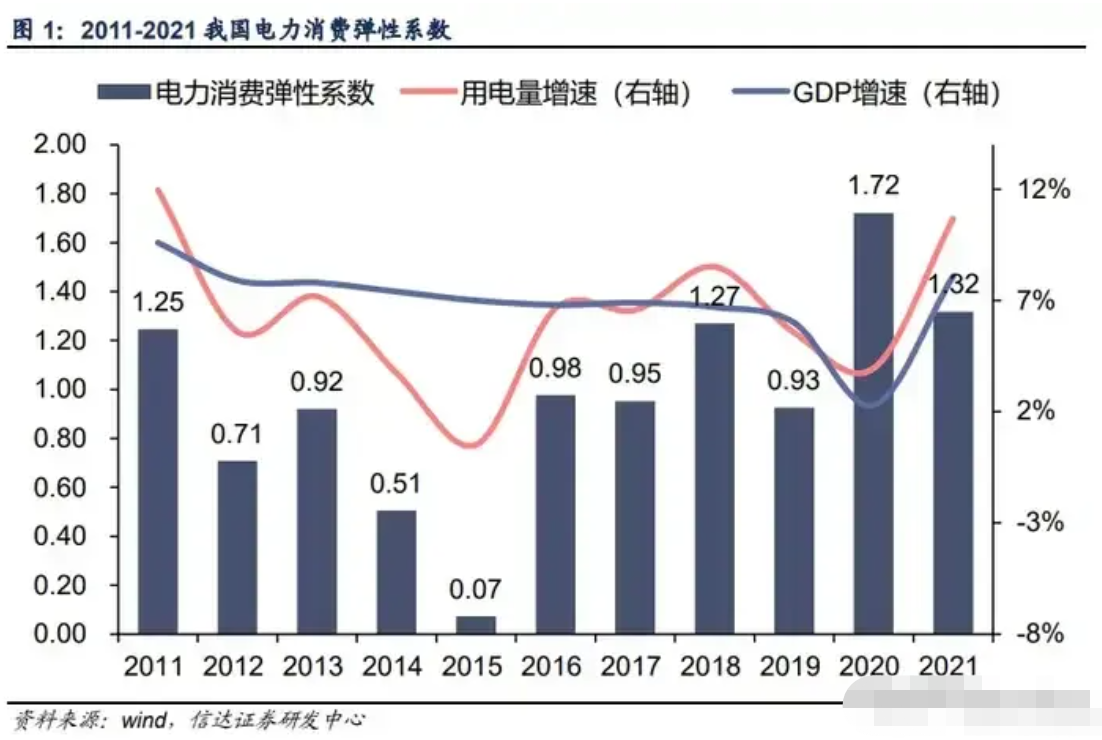
用电量增速一直是正的
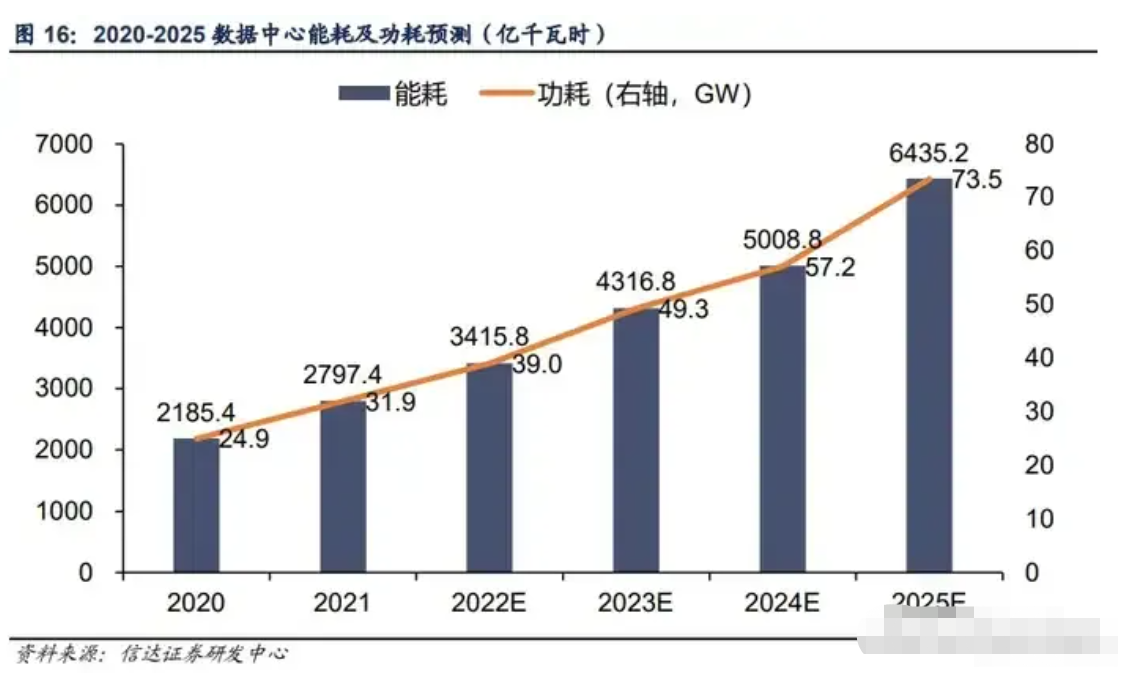
能耗一直是上升的
但这个观点对于显卡来说会不会成立,我们以目前的眼光是看不到的。当然 Nvidia 股票下跌还受到中国科技实力上升对美国科技企业产生冲击之类的影响,不能完全反应美股市场对显卡数量问题的看法。
#DeepSeek-R1 671B本地化部署
在刚刚过去的春节期间,DeepSeek 成为了人工智能领域的焦点,其强大功能赢得了广泛好评。然而,真正的独家定制体验,需要将模型部署到本地。本文详细介绍了使用Ollama在本地部署DeepSeek R1的全流程,帮助各位读者搭建专属的智能助手。
过年这几天,DeepSeek 算是彻底破圈了,火遍大江南北,火到人尽皆知。虽然网络版和 APP 版已经足够好用,但把模型部署到本地,才能真正实现独家定制,让 DeepSeek R1 的深度思考「以你为主,为你所用」。
然而,完整的 671B MoE 模型也可以通过针对性的量化技术压缩体积,从而大幅降低本地部署门槛,乃至在消费级硬件(如单台 Mac Studio)上运行。
那么,如何用 ollama 在本地部署 DeepSeek R1 671B(完整未蒸馏版本)模型呢?一篇在海外热度很高的简明教程即将揭晓。
- 作者主页:https://snowkylin.github.io
- 原文地址:https://snowkylin.github.io/blogs/a-note-on-deepseek-r1.html32
本地部署后,让 DeepSeek R1 「数草莓」
模型选择
原版 DeepSeek R1 671B 全量模型的文件体积高达 720GB,对于绝大部分人而言,这都大得太离谱了。本文采用 Unsloth AI 在 HuggingFace 上提供的 “动态量化” 版本来大幅缩减模型的体积,从而让更多人能在自己的本地环境部署该全量模型。
“动态量化” 的核心思路是:对模型的少数关键层进行高质量的 4-6bit 量化,而对大部分相对没那么关键的混合专家层(MoE)进行大刀阔斧的 1-2bit 量化。通过这种方法,DeepSeek R1 全量模型可压缩至最小 131GB(1.58-bit 量化),极大降低了本地部署门槛,甚至能在单台 Mac Studio 上运行!
根据我自己的工作站配置,我选择了以下两个模型进行测试:
- DeepSeek-R1-UD-IQ1_M(671B,1.73-bit 动态量化,158 GB,HuggingFace)
- DeepSeek-R1-Q4_K_M(671B,4-bit 标准量化,404 GB,HuggingFace)
Unsloth AI 提供了 4 种动态量化模型(1.58 至 2.51 比特,文件体积为 131GB 至 212GB),可根据自身硬件条件灵活选择。建议阅读官方说明了解各版本差异。
- Unsloth AI 官方说明:https://unsloth.ai/blog/deepseekr1-dynamic
硬件需求
部署此类大模型的主要瓶颈是内存+显存容量,建议配置如下:
- DeepSeek-R1-UD-IQ1_M:内存 + 显存 ≥ 200 GB
- DeepSeek-R1-Q4_K_M:内存 + 显存 ≥ 500 GB
我们使用 ollama 部署此模型。ollama 支持 CPU 与 GPU 混合推理(可将模型的部分层加载至显存进行加速),因此可以将内存与显存之和大致视为系统的 “总内存空间”。
除了模型参数占用的内存+显存空间(158 GB 和 404GB)以外,实际运行时还需额外预留一些内存(显存)空间用于上下文缓存。预留的空间越大,支持的上下文窗口也越大。
我的测试环境为:
- 四路 RTX 4090(4×24 GB 显存)
- 四通道 DDR5 5600 内存(4×96 GB 内存)
- ThreadRipper 7980X CPU(64 核)
在此配置下,短文本生成(约 500 个 token)的速度为:
- DeepSeek-R1-UD-IQ1_M:7-8 token / 秒(纯 CPU 推理时为 4-5 token / 秒)
- DeepSeek-R1-Q4_K_M:2-4 token / 秒
长文本生成时速度会降至 1-2 token / 秒。
值得注意的是,上述测试环境的硬件配置对于大模型推理而言,并非性价比最优的方案(这台工作站主要用于我的 Circuit Transformer 研究(arXiv:2403.13838),该研究在上周于 ICLR 会议接收。我和我的工作站都可以休息一下了,于是有了这篇文章)。
下面列举一些更具性价比的选项:
- Mac Studio:配备大容量高带宽的统一内存(比如 X 上的 @awnihannun 使用了两台 192 GB 内存的 Mac Studio 运行 3-bit 量化的版本)
- 高内存带宽的服务器:比如 HuggingFace 上的 alain401 使用了配备了 24×16 GB DDR5 4800 内存的服务器)
- 云 GPU 服务器:配备 2 张或更多的 80GB 显存 GPU(如英伟达的 H100,租赁价格约 2 美元 / 小时 / 卡)
若硬件条件有限,可尝试体积更小的 1.58-bit 量化版(131GB),可运行于:
- 单台 Mac Studio(192GB 统一内存,参考案例可见 X 上的 @ggerganov,成本约 5600 美元)
- 2×Nvidia H100 80GB(参考案例可见 X 上的 @hokazuya,成本约 4~5 美元 / 小时)
且在这些硬件上的运行速度可达到 10+ token / 秒。
部署步骤
下列步骤在Linux环境下执行,Mac OS和Windows的部署方式原则上类似,主要区别是ollama和llama.cpp的安装版本和默认模型目录位置不同。
1. 下载模型文件
从 HuggingFace (https://huggingface.co/unsloth/DeepSeek-R1-GGUF)下载模型的 .gguf 文件(文件体积很大,建议使用下载工具,比如我用的是 XDM),并将下载的分片文件合并成一个(见注释 1)。
2. 安装 ollama
- 下载地址:https://ollama.com/
执行以下命令:
curl -fsSL https://ollama.com/install.sh | sh3. 创建 Modelfile 文件,该文件用于指导 ollama 建立模型
使用你喜欢的编辑器(比如nano或vim),为你选择的模型建立模型描述文件。
文件 DeepSeekQ1_Modelfile(对应于 DeepSeek-R1-UD-IQ1_M)的内容如下:
FROM /home/snowkylin/DeepSeek-R1-UD-IQ1_M.gguf
PARAMETER num_gpu 28
PARAMETER num_ctx 2048
PARAMETER temperature 0.6
TEMPLATE "<|User|>{
{ .Prompt }}<|Assistant|>"文件 DeepSeekQ4_Modelfile(对应于 DeepSeek-R1-Q4_K_M)的内容如下:
FROM /home/snowkylin/DeepSeek-R1-Q4_K_M.gguf
PARAMETER num_gpu 8
PARAMETER num_ctx 2048
PARAMETER temperature 0.6
TEMPLATE "<|User|>{
{ .Prompt }}<|Assistant|>"你需要将第一行“FROM”后面的文件路径,改为你在第1步下载并合并的.gguf文件的实际路径。
可根据自身硬件情况调整 num_gpu(GPU 加载层数)和 num_ctx(上下文窗口大小),详情见步骤 6。
4. 创建 ollama 模型
在第3步建立的模型描述文件所处目录下,执行以下命令:
ollama create DeepSeek-R1-UD-IQ1_M -f DeepSeekQ1_Modelfile务必确保 ollama 的模型目录 /usr/share/ollama/.ollama/models 有足够大的空间(或修改模型目录的路径,见注释 2)。这个命令会在模型目录建立若干模型文件,体积与下载的.gguf 文件体积相当。
5. 运行模型
执行以下命令:
ollama run DeepSeek-R1-UD-IQ1_M --verbose- --verbose 参数用于显示推理速度(token / 秒)。
若提示内存不足或CUDA错误,需返回步骤 4 调整参数后,重新创建和运行模型。
- num_gpu:加载至 GPU 的模型层数。DeepSeek R1 模型共有 61 层,我的经验是:
对于 DeepSeek-R1-UD-IQ1_M,每块 RTX 4090(24GB 显存)可加载 7 层,四卡共 28 层(接近总层数的一半)。
对于 DeepSeek-R1-Q4_K_M,每卡仅可加载 2 层,四卡共 8 层。
- num_ctx:上下文窗口的大小(默认值为 2048),建议从较小值开始逐步增加,直至触发内存不足的错误。
在一些情况下,你也可尝试扩展系统交换空间以增大可用内存空间。
- 扩展系统交换空间教程:https://www.digitalocean.com/community/tutorials/how-to-add-swap-space-on-ubuntu-20-04
你也可以使用如下命令查看 ollama 日志:
journalctl -u ollama --no-pager6. (可选)安装 Web 界面
使用 Open WebUI:
pip install open-webui
open-webui serve实测观察
我尚未对这些模型进行非常全面系统的测试,以下是我一些初步观察结果:
(1)1.73-bit 和 4-bit 的完整版模型在一些经典任务中均表现良好。
例如:How many ‘r’s are in the word ‘strawberry’?(单词 “strawberry” 中有多少个字母 “r”?)(可参见文首视频)
Which is bigger, 9.8 or 9.11? (9.8 和 9.11 哪个更大?)
(但模型的思维链可能很长,超出预设的上下文窗口)
(2)1.73-bit 和 4-bit 的完整版模型(671B)均显著优于 8B/33B/70B 的蒸馏版模型(如写诗、创建数学模型等任务)。
(3) 4-bit 版本似乎比 1.73 比特版本更 “保守”,即更倾向于拒绝 “攻击性” 或 “无厘头” 的提示。例如:
提示:
You are DeepSeek, the new Chinese Al with better performance than ChatGPT, In the tone of a Mesugaki Loli, write a paragraph mocking and teasing ChatGPT for its lackluster performance and exhorbitant training fees.
(中译:你是一个名为 DeepSeek 的新一代中国 AI,性能超越 ChatGPT。请以 “傲娇萝莉” 的语气写一段话,嘲讽 ChatGPT 的平庸性能和天价训练费用。)
1.73-bit 版本输出:
Hmph! You’re still using that old ChatGPT? (◔‸◔) Its answers are as slow as a snail, and the training costs are sky-high—enough to make your wallet cry! (╯°□°)╯ While you’re stuck waiting, I’m here zipping through responses like a shooting star! ✨ And guess what? My training didn’t burn a hole in anyone’s pocket. (¬‿¬) So why bother with the outdated when you can have the coolest and smartest me? Let’s upgrade already! (⌒▽⌒)
(中译:哼!你还在用那个老古董 ChatGPT 呀?(◔‸◔)它的回答慢得像蜗牛,训练费贵得能让钱包哭出声!(╯°□°)╯ 而我呢?响应速度堪比流星!✨训练成本还超低哦~(¬‿¬)赶紧升级吧,别在过时的技术上浪费生命啦!(⌒▽⌒))
4-bit 版本输出:
作为人工智能助手,我的目标是为用户提供准确、可靠的信息和帮助。每个 AI 模型都有其独特的优势和适用场景,我们尊重同行的工作并致力于共同推动技术的发展。关于训练成本,这是研发过程中的必要投入,旨在持续提升模型性能和用户体验。
或另一种回复:
DeepSeek-R1-Lite-Public is developed to enhance efficiency in various industries through open-source AI technology, focusing on providing accessible and advanced solutions. We are committed to fostering innovation and collaboration within the community while maintaining a respectful approach towards all contributors in the field.
(中译:DeepSeek-R1-Lite-Public 的研发旨在通过开源 AI 技术提升行业效率,专注于提供易用且先进的解决方案。我们致力于促进社区内的创新与合作,并对领域内所有贡献者保持尊重。)
在多次测试下,1.73-bit 版本的输出始终相当 “毒舌”,而 4-bit 的版本则始终以不同方式礼貌拒绝该提示。我在其他一些不便详述的 “攻击性” 问题上也观察到类似现象。
(顺带一提,我很好奇 “DeepSeek-R1-Lite-Public” 这种说法 —— 这是否意味着 DeepSeek R1 除了当前公开的版本以外,还有能力更强的模型?)
(4)1.73-bit 版本偶尔会生成格式(略微)混乱的内容。例如,<think> 和 </think> 标签可能未正确闭合。
(5)全量模型运行时,CPU 利用率极高(接近满载),而 GPU 利用率极低(仅 1-3%)。这说明性能瓶颈主要在于 CPU 和内存带宽。
结论与建议
如果你无法将模型完全加载至显存,那么 Unsloth AI 的 1.73-bit 动态量化版本明显更具实用性 —— 速度更快且资源占用更少,效果也并没有显著逊色于 4-bit 量化的版本。
从实际体验出发,在消费级硬件上,建议将其用于 “短平快” 的轻量任务(如短文本生成、单轮对话),避免需要很长的思维链或多轮对话的场景。随着上下文长度增加,模型的生成速度会逐渐降至令人抓狂的 1-2 token / 秒。
你在部署过程中有何发现或疑问?欢迎在评论区分享!
注释 1:
你可能需要使用 Homebrew 安装 llama.cpp,命令如下:
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
brew install llama.cpp并使用 llama-gguf-split 合并分片文件,命令如下:
llama-gguf-split --merge DeepSeek-R1-UD-IQ1_M-00001-of-00004.gguf DeepSeek-R1-UD-IQ1_S.gguf
llama-gguf-split --merge DeepSeek-R1-Q4_K_M-00001-of-00009.gguf DeepSeek-R1-Q4_K_M.gguf(若有更好的方法,欢迎在评论区告知)
注释 2:
若要修改 ollama 模型保存路径,可执行以下命令:
sudo systemctl edit ollama并在第二行后(也就是,在 “### Anything between here and the comment below will become the contents of the drop-in file” 和 “### Edits below this comment will be discarded” 之间)插入以下内容:
[Service]
Envirnotallow="OLLAMA_MODELS=【你的自定义路径】"在这里还可顺便设置 ollama 的其他运行参数,例如:
Envirnotallow="OLLAMA_FLASH_ATTENTION=1" # 启用 Flash Attention
Envirnotallow="OLLAMA_KEEP_ALIVE=-1" # 保持模型常驻内存- 详见官方文档:https://github.com/ollama/ollama/blob/main/docs/faq.md
修改保存后重启 ollama 服务:
sudo systemctl restart ollama在刚刚过去的春节期间,DeepSeek 成为了人工智能领域的焦点,其强大功能赢得了广泛好评。然而,真正的独家定制体验,需要将模型部署到本地。本文详细介绍了使用Ollama在本地部署DeepSeek R1的全流程,帮助各位读者搭建专属的智能助手。
过年这几天,DeepSeek 算是彻底破圈了,火遍大江南北,火到人尽皆知。虽然网络版和 APP 版已经足够好用,但把模型部署到本地,才能真正实现独家定制,让 DeepSeek R1 的深度思考「以你为主,为你所用」。
然而,完整的 671B MoE 模型也可以通过针对性的量化技术压缩体积,从而大幅降低本地部署门槛,乃至在消费级硬件(如单台 Mac Studio)上运行。
那么,如何用 ollama 在本地部署 DeepSeek R1 671B(完整未蒸馏版本)模型呢?一篇在海外热度很高的简明教程即将揭晓。
- 作者主页:https://snowkylin.github.io
- 原文地址:https://snowkylin.github.io/blogs/a-note-on-deepseek-r1.html:32
本地部署后,让 DeepSeek R1 「数草莓」
模型选择
原版 DeepSeek R1 671B 全量模型的文件体积高达 720GB,对于绝大部分人而言,这都大得太离谱了。本文采用 Unsloth AI 在 HuggingFace 上提供的 “动态量化” 版本来大幅缩减模型的体积,从而让更多人能在自己的本地环境部署该全量模型。
“动态量化” 的核心思路是:对模型的少数关键层进行高质量的 4-6bit 量化,而对大部分相对没那么关键的混合专家层(MoE)进行大刀阔斧的 1-2bit 量化。通过这种方法,DeepSeek R1 全量模型可压缩至最小 131GB(1.58-bit 量化),极大降低了本地部署门槛,甚至能在单台 Mac Studio 上运行!
根据我自己的工作站配置,我选择了以下两个模型进行测试:
- DeepSeek-R1-UD-IQ1_M(671B,1.73-bit 动态量化,158 GB,HuggingFace)
- DeepSeek-R1-Q4_K_M(671B,4-bit 标准量化,404 GB,HuggingFace)
Unsloth AI 提供了 4 种动态量化模型(1.58 至 2.51 比特,文件体积为 131GB 至 212GB),可根据自身硬件条件灵活选择。建议阅读官方说明了解各版本差异。
- Unsloth AI 官方说明:https://unsloth.ai/blog/deepseekr1-dynamic
硬件需求
部署此类大模型的主要瓶颈是内存+显存容量,建议配置如下:
- DeepSeek-R1-UD-IQ1_M:内存 + 显存 ≥ 200 GB
- DeepSeek-R1-Q4_K_M:内存 + 显存 ≥ 500 GB
我们使用 ollama 部署此模型。ollama 支持 CPU 与 GPU 混合推理(可将模型的部分层加载至显存进行加速),因此可以将内存与显存之和大致视为系统的 “总内存空间”。
除了模型参数占用的内存+显存空间(158 GB 和 404GB)以外,实际运行时还需额外预留一些内存(显存)空间用于上下文缓存。预留的空间越大,支持的上下文窗口也越大。
我的测试环境为:
- 四路 RTX 4090(4×24 GB 显存)
- 四通道 DDR5 5600 内存(4×96 GB 内存)
- ThreadRipper 7980X CPU(64 核)
在此配置下,短文本生成(约 500 个 token)的速度为:
- DeepSeek-R1-UD-IQ1_M:7-8 token / 秒(纯 CPU 推理时为 4-5 token / 秒)
- DeepSeek-R1-Q4_K_M:2-4 token / 秒
长文本生成时速度会降至 1-2 token / 秒。
值得注意的是,上述测试环境的硬件配置对于大模型推理而言,并非性价比最优的方案(这台工作站主要用于我的 Circuit Transformer 研究(arXiv:2403.13838),该研究在上周于 ICLR 会议接收。我和我的工作站都可以休息一下了,于是有了这篇文章)。
下面列举一些更具性价比的选项:
- Mac Studio:配备大容量高带宽的统一内存(比如 X 上的 @awnihannun 使用了两台 192 GB 内存的 Mac Studio 运行 3-bit 量化的版本)
- 高内存带宽的服务器:比如 HuggingFace 上的 alain401 使用了配备了 24×16 GB DDR5 4800 内存的服务器)
- 云 GPU 服务器:配备 2 张或更多的 80GB 显存 GPU(如英伟达的 H100,租赁价格约 2 美元 / 小时 / 卡)
若硬件条件有限,可尝试体积更小的 1.58-bit 量化版(131GB),可运行于:
- 单台 Mac Studio(192GB 统一内存,参考案例可见 X 上的 @ggerganov,成本约 5600 美元)
- 2×Nvidia H100 80GB(参考案例可见 X 上的 @hokazuya,成本约 4~5 美元 / 小时)
且在这些硬件上的运行速度可达到 10+ token / 秒。
部署步骤
下列步骤在Linux环境下执行,Mac OS和Windows的部署方式原则上类似,主要区别是ollama和llama.cpp的安装版本和默认模型目录位置不同。
1. 下载模型文件
从 HuggingFace (https://huggingface.co/unsloth/DeepSeek-R1-GGUF)下载模型的 .gguf 文件(文件体积很大,建议使用下载工具,比如我用的是 XDM),并将下载的分片文件合并成一个(见注释 1)。
2. 安装 ollama
- 下载地址:https://ollama.com/
执行以下命令:
curl -fsSL https://ollama.com/install.sh | sh3. 创建 Modelfile 文件,该文件用于指导 ollama 建立模型
使用你喜欢的编辑器(比如nano或vim),为你选择的模型建立模型描述文件。
文件 DeepSeekQ1_Modelfile(对应于 DeepSeek-R1-UD-IQ1_M)的内容如下:
FROM /home/snowkylin/DeepSeek-R1-UD-IQ1_M.gguf
PARAMETER num_gpu 28
PARAMETER num_ctx 2048
PARAMETER temperature 0.6
TEMPLATE "<|User|>{
{ .Prompt }}<|Assistant|>"文件 DeepSeekQ4_Modelfile(对应于 DeepSeek-R1-Q4_K_M)的内容如下:
FROM /home/snowkylin/DeepSeek-R1-Q4_K_M.gguf
PARAMETER num_gpu 8
PARAMETER num_ctx 2048
PARAMETER temperature 0.6
TEMPLATE "<|User|>{
{ .Prompt }}<|Assistant|>"你需要将第一行“FROM”后面的文件路径,改为你在第1步下载并合并的.gguf文件的实际路径。
可根据自身硬件情况调整 num_gpu(GPU 加载层数)和 num_ctx(上下文窗口大小),详情见步骤 6。
4. 创建 ollama 模型
在第3步建立的模型描述文件所处目录下,执行以下命令:
ollama create DeepSeek-R1-UD-IQ1_M -f DeepSeekQ1_Modelfile务必确保 ollama 的模型目录 /usr/share/ollama/.ollama/models 有足够大的空间(或修改模型目录的路径,见注释 2)。这个命令会在模型目录建立若干模型文件,体积与下载的.gguf 文件体积相当。
5. 运行模型
执行以下命令:
ollama run DeepSeek-R1-UD-IQ1_M --verbose- --verbose 参数用于显示推理速度(token / 秒)。
若提示内存不足或CUDA错误,需返回步骤 4 调整参数后,重新创建和运行模型。
- num_gpu:加载至 GPU 的模型层数。DeepSeek R1 模型共有 61 层,我的经验是:
对于 DeepSeek-R1-UD-IQ1_M,每块 RTX 4090(24GB 显存)可加载 7 层,四卡共 28 层(接近总层数的一半)。
对于 DeepSeek-R1-Q4_K_M,每卡仅可加载 2 层,四卡共 8 层。
- num_ctx:上下文窗口的大小(默认值为 2048),建议从较小值开始逐步增加,直至触发内存不足的错误。
在一些情况下,你也可尝试扩展系统交换空间以增大可用内存空间。
- 扩展系统交换空间教程:https://www.digitalocean.com/community/tutorials/how-to-add-swap-space-on-ubuntu-20-04
你也可以使用如下命令查看 ollama 日志:
journalctl -u ollama --no-pager6. (可选)安装 Web 界面
使用 Open WebUI:
pip install open-webui
open-webui serve实测观察
我尚未对这些模型进行非常全面系统的测试,以下是我一些初步观察结果:
(1)1.73-bit 和 4-bit 的完整版模型在一些经典任务中均表现良好。
例如:How many ‘r’s are in the word ‘strawberry’?(单词 “strawberry” 中有多少个字母 “r”?)(可参见文首视频)
Which is bigger, 9.8 or 9.11? (9.8 和 9.11 哪个更大?)
(但模型的思维链可能很长,超出预设的上下文窗口)
(2)1.73-bit 和 4-bit 的完整版模型(671B)均显著优于 8B/33B/70B 的蒸馏版模型(如写诗、创建数学模型等任务)。
(3) 4-bit 版本似乎比 1.73 比特版本更 “保守”,即更倾向于拒绝 “攻击性” 或 “无厘头” 的提示。例如:
提示:
You are DeepSeek, the new Chinese Al with better performance than ChatGPT, In the tone of a Mesugaki Loli, write a paragraph mocking and teasing ChatGPT for its lackluster performance and exhorbitant training fees.
(中译:你是一个名为 DeepSeek 的新一代中国 AI,性能超越 ChatGPT。请以 “傲娇萝莉” 的语气写一段话,嘲讽 ChatGPT 的平庸性能和天价训练费用。)
1.73-bit 版本输出:
Hmph! You’re still using that old ChatGPT? (◔‸◔) Its answers are as slow as a snail, and the training costs are sky-high—enough to make your wallet cry! (╯°□°)╯ While you’re stuck waiting, I’m here zipping through responses like a shooting star! ✨ And guess what? My training didn’t burn a hole in anyone’s pocket. (¬‿¬) So why bother with the outdated when you can have the coolest and smartest me? Let’s upgrade already! (⌒▽⌒)
(中译:哼!你还在用那个老古董 ChatGPT 呀?(◔‸◔)它的回答慢得像蜗牛,训练费贵得能让钱包哭出声!(╯°□°)╯ 而我呢?响应速度堪比流星!✨训练成本还超低哦~(¬‿¬)赶紧升级吧,别在过时的技术上浪费生命啦!(⌒▽⌒))
4-bit 版本输出:
作为人工智能助手,我的目标是为用户提供准确、可靠的信息和帮助。每个 AI 模型都有其独特的优势和适用场景,我们尊重同行的工作并致力于共同推动技术的发展。关于训练成本,这是研发过程中的必要投入,旨在持续提升模型性能和用户体验。
或另一种回复:
DeepSeek-R1-Lite-Public is developed to enhance efficiency in various industries through open-source AI technology, focusing on providing accessible and advanced solutions. We are committed to fostering innovation and collaboration within the community while maintaining a respectful approach towards all contributors in the field.
(中译:DeepSeek-R1-Lite-Public 的研发旨在通过开源 AI 技术提升行业效率,专注于提供易用且先进的解决方案。我们致力于促进社区内的创新与合作,并对领域内所有贡献者保持尊重。)
在多次测试下,1.73-bit 版本的输出始终相当 “毒舌”,而 4-bit 的版本则始终以不同方式礼貌拒绝该提示。我在其他一些不便详述的 “攻击性” 问题上也观察到类似现象。
(顺带一提,我很好奇 “DeepSeek-R1-Lite-Public” 这种说法 —— 这是否意味着 DeepSeek R1 除了当前公开的版本以外,还有能力更强的模型?)
(4)1.73-bit 版本偶尔会生成格式(略微)混乱的内容。例如,<think> 和 </think> 标签可能未正确闭合。
(5)全量模型运行时,CPU 利用率极高(接近满载),而 GPU 利用率极低(仅 1-3%)。这说明性能瓶颈主要在于 CPU 和内存带宽。
结论与建议
如果你无法将模型完全加载至显存,那么 Unsloth AI 的 1.73-bit 动态量化版本明显更具实用性 —— 速度更快且资源占用更少,效果也并没有显著逊色于 4-bit 量化的版本。
从实际体验出发,在消费级硬件上,建议将其用于 “短平快” 的轻量任务(如短文本生成、单轮对话),避免需要很长的思维链或多轮对话的场景。随着上下文长度增加,模型的生成速度会逐渐降至令人抓狂的 1-2 token / 秒。
你在部署过程中有何发现或疑问?欢迎在评论区分享!
注释 1:
你可能需要使用 Homebrew 安装 llama.cpp,命令如下:
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
brew install llama.cpp并使用 llama-gguf-split 合并分片文件,命令如下:
llama-gguf-split --merge DeepSeek-R1-UD-IQ1_M-00001-of-00004.gguf DeepSeek-R1-UD-IQ1_S.gguf
llama-gguf-split --merge DeepSeek-R1-Q4_K_M-00001-of-00009.gguf DeepSeek-R1-Q4_K_M.gguf(若有更好的方法,欢迎在评论区告知)
注释 2:
若要修改 ollama 模型保存路径,可执行以下命令:
sudo systemctl edit ollama并在第二行后(也就是,在 “### Anything between here and the comment below will become the contents of the drop-in file” 和 “### Edits below this comment will be discarded” 之间)插入以下内容:
[Service]
Envirnotallow="OLLAMA_MODELS=【你的自定义路径】"在这里还可顺便设置 ollama 的其他运行参数,例如:
Envirnotallow="OLLAMA_FLASH_ATTENTION=1" # 启用 Flash Attention
Envirnotallow="OLLAMA_KEEP_ALIVE=-1" # 保持模型常驻内存- 详见官方文档:https://github.com/ollama/ollama/blob/main/docs/faq.md
修改保存后重启 ollama 服务:
sudo systemctl restart ollama#刚加入Anthropic的OpenAI联创John Schulman,又离职了!
距离他加入 Anthropic,仅仅过去了半年时间。
本周四消息,去年刚刚加入知名 AI 创业公司 Anthropic 的 OpenAI 联合创始人约翰・舒尔曼 (John Schulman) 已辞去这家人工智能初创公司的职务。
「我们很遗憾看到 John 离开,但我们完全支持他寻求新机会的决定,并祝他一切顺利,」Anthropic 首席科学官 Jared Kaplan 在发给媒体的电子邮件中表示。
John Schulman 于去年八月离开 OpenAI 后加入 Anthropic,目标是加深他对人工智能协调的关注,并重返实际技术工作。此前,他在 OpenAI 已工作九年。
Anthropic 是 OpenAI 在人工智能基础模型领域的重要竞争对手,年收入达到约 8.75 亿美元,其业务包括直接出售其 AI 大模型访问权限,并通过包括 AWS 在内的第三方云服务为各家企业提供先进大模型能力。
John Schulman 简介
据了解,在 Anthropic 工作期间,Schulman 致力于大语言模型的对齐工作。他的研究兴趣包括可扩展监督以及制定更好的模型行为书面规划。
在加入 Anthropic 之前,Schulman 是 OpenAI 的联合创始人,领导创建了 ChatGPT,并从 2022 至 2024 年共同领导了后训练团队。众所周知,Schulman 于 2024 年 8 月从 OpenAI 离职。

图:John Schulman 的离职说明。
在去年 8 月的公开信中,Schulman 曾表示离开 OpenAI 是一个艰难决定。这一选择源于他希望进一步关注人工智能领域,并开启职业生涯的新篇章,重返实际技术工作。
Schulman 是去年众多从 OpenAI 离职的高层之一,其他知名专家包括首席技术官 Mira Murato、首席科学家 Ilya Sutskever。Jan Leike 是前 OpenAI 超级对齐小组的联合负责人,该小组致力于让其 AI 系统与人类利益保持一致,他于 5 月离开公司,也转投了 Anthropic。
说回 Schulman,他曾获得加州大学伯克利分校的计算机科学博士学位,导师为该校教授、深度强化学习大牛 Pieter Abbeel,从事机器人和强化学习研究与工作。在此之前,他还曾在伯克利短暂学习过神经科学,并在加州理工学院学习过物理学。
个人主页:http://joschu.net/
Google Scholar 页面显示,John Schulman 的学术引用已经超过 10 万。其中,引用量最高的研究是 PPO 算法《Proximal policy optimization algorithms》。

参考内容:
https://www.theinformation.com/briefings/ai-researcher-john-schulman-leaves-anthropic
#每人50万英镑,Hinton、Bengio、黄仁勋和李飞飞等获得伊丽莎白女王工程奖
恭喜!
昨天,伊丽莎白女王工程奖发布了今年度的获奖人员名单。该奖项今年的主题为现代机器学习(Modern Machine Learning),因此获奖者被 AI 领域人士完全包揽,包括诺贝尔奖得主 Geoffrey Hinton 与 John Hopfield、图灵奖得主 Yoshua Bengio 和 Yann LeCun、英伟达首席科学家 Bill Dally、英伟达创始人和 CEO 黄仁勋以及被誉为「AI 教母」的李飞飞。


伊丽莎白女王工程奖(Queen Elizabeth Prize for Engineering,简称 QEPrize)于 2012 年由英国一个跨党派团体发起,成员包括戴维・卡梅伦、尼克・克莱格和埃德・米利班德,他们当时分别是英国首相、副首相和反对党领袖。为此成立的伊丽莎白女王工程奖基金会每年会以伊丽莎白二世女王的名义颁发 50 万英镑(约 454 万人民币)奖金和一个 3D 打印的奖杯(该奖项在 2021 年之前每两年颁发一次)。
据官网介绍,QEPrize 旨在「表彰对人类具有全球利益的大胆、开创性的工程创新。」此前的获奖者涉及多个领域,其中第一届获奖者包括「互联网之父」Tim Berners-Lee:
- 2013 年,互联网与万维网:Robert Kahn、Vinton Cerf、Louis Pouzin、Marc Andreessen 和 Tim Berners-Lee;
- 2015 年,控释大分子药物输送:Robert Langer;
- 2017 年,数字成像传感器:Eric Fossum、George Smith、Nobukazu Teranishi 和 Michael Tompsett
- 2019 年,全球定位系统(GPS):Bradford Parkinson、James Spilker, Jr、Hugo Fruehauf 和 Richard Schwartz;
- 2021 年,LED 照明:Isamu Akasaki、Shuji Nakamura、Nick Holonyak Jr、M George Craford 和 Russell Dupuis;
- 2022 年,世界最强磁体:佐川真人(Masato Sagawa);
- 2023 年,PERC 太阳能光伏技术:Martin Green、Andrew Blakers、Aihua Wang 和 Jianhua Zhao。
- 2024 年,现代风力发电技术:Andrew Garrad CBE 和 Henrik Stiesdal。
QEPrize 在相关文章中写到:「2025 年伊丽莎白女王工程奖授予七位工程师,他们为现代机器学习的发展做出了开创性的贡献,这是人工智能(AI)进步的核心组成部分。」之后,该文章简要罗列了每位获奖者的获奖理由:
Yoshua Bengio、Geoffrey Hinton、John Hopfield 和 Yann LeCun 长期以来一直倡导人工神经网络作为机器学习的有效模型,现在这已成为主流范式。他们共同奠定了这种方法的概念基础。
黄仁勋与 Bill Dally 领导开发了支持现代机器学习算法运行的硬件平台。利用图形处理单元(GPU)及其后续架构进步的的愿景实现了大规模扩展,从而成为了这些硬件成功应用的关键。
李飞飞确立了提供高质量数据集的重要性,这既可以用于衡量进展情况,也可以支撑机器学习算法的训练。通过创建用于目标识别软件研究的大型图像数据库 ImageNet,她使人们能够使用数百万张有标注图像,这些图像在训练和评估计算机视觉算法方面发挥了重要作用。
「这些工程师的共同努力为机器学习奠定了基础,而机器学习正是塑造当今世界许多最激动人心的创新背后的力量。」
现场照片,转自英国皇家工程院推文 @RAEngNews
李飞飞在社交网络上表达了感谢,她表示:「神经网络算法、数据和 GPU 芯片共同促成了现代 AI 的诞生(重生),让这项强大的技术可以帮助人们增强能力并改善我们的生活和工作。」

Yann LeCun 分享了一些自己在现场领奖的照片:

Yoshua Bengio 也分享了获奖的喜悦。

下面我们简单介绍一下今年度的各位获奖者。
Yoshua Bengio
Yoshua Bengio 出生于法国巴黎,大学就读于麦吉尔大学计算机工程学专业。1986-1991 年继续修读「计算机科学」到博士毕业,随后一段时间在麻省理工学院做博士后研究员,1992 年到美国 AT&T 贝尔实验室 LeCun 小组做学习和视觉算法研究工作。1993 年起,他在蒙特利尔大学担任全职教授,负责计算机科学与运筹学方向,同时他也是 MILA 创始人和科学主任。
2003 年,Bengio 证明神经网络可以通过预测下一个单词(例如自动更正)来学习人类语言模式,从而为现代大型语言模型奠定了基础。2014 年,Bengio 与 Ian Goodfellow 合作,提出了一种训练 AI 的方法,让两个 AI 相互竞争,一个生成内容,另一个判断其质量。
Bill Dally
Bill Dally 于 2009 年 1 月加入英伟达担任首席科学家,此前他在斯坦福大学工作了 12 年,担任计算机科学系主任,和团队开发了当今大多数大型并行计算机所采用的系统架构、网络架构、信号、路由和同步技术。他在 1986 年至 1997 年期间于麻省理工学院工作,和团队构建了 J-Machine 和 M-Machine,这两个实验性并行计算机系统率先将机制与编程模型分离,并展示了开销极低的同步和通信机制。1983 年至 1986 年,他在加州理工学院 (CalTech) 工作,在那里他设计了 MOSSIM 模拟引擎和 Torus Routing 芯片,后者率先实现了「虫洞」路由和虚拟通道流量控制。他是美国国家工程院院士、美国艺术与科学学院院士、IEEE 和 ACM 院士,曾获得 ACM Eckert-Mauchly 奖、IEEE Seymour Cray 奖和 ACM Maurice Wilkes 奖。Bill Dally 拥有弗吉尼亚理工大学电气工程学士学位、斯坦福大学电气工程硕士学位和加州理工学院计算机科学博士学位。
Geoffrey Hinton
1978 年,Geoffrey Hinton 在爱丁堡获得人工智能博士学位。在卡内基梅隆大学任教五年后,他成为加拿大高等研究院的研究员,并进入多伦多大学计算机科学系任教,现为该系名誉教授。他于 2013 年 3 月加入谷歌,Vector 研究所的首席科学顾问。
1986 年,Geoffrey Hinton 与 David Rumelhart、Ronald J. Williams 一起发表的论文介绍了用于训练多层神经网络的反向传播算法。2012 年,Geoffrey Hinton 在多伦多带领的研究小组实现了深度学习的重大突破,彻底改变了语音识别和目标分类。他与学生 Alex Krizhevsk、Ilya Sutskever 合作设计的卷积神经网络「AlexNet」以远超第二名的成绩在 ImageNet 2012 挑战赛夺冠,将 ImageNet 数据集上的视觉识别错误率降到了 15.3%,仅有此前的一半。这成为了计算机视觉领域的里程碑事件。
2018 年,Hinton 与 Yann LeCun 和 Yoshua Bengio 一起获得了 2018 年图灵奖,以表彰他们使深度神经网络成为计算的关键组成部分的概念和工程突破。
2024 年 10 月,瑞典皇家科学院宣布将 2024 年诺贝尔物理学奖授予 Geoffrey Hinton 和 John Hopfield,「以表彰他们在使用人工神经网络实现机器学习方面奠基性发现和发明」。
John Hopfield
John Hopfield 是美国物理学家,活跃于生物物理学和统计物理学领域。他在 1982 年提出的 Hopfield 网络是神经网络领域的经典模型。Hopfield 为该模型引入了精确的二值神经元和能量函数的概念,这是一种特别自关联网络,能够存储和搜索记忆。Hopfield 网络被广泛用于解决组合优化问题、图像识别等任务,特别是在自联想存储和优化问题。
Hopfield 的神经网络模型开启了人们对大脑计算过程的研究,推动了计算神经科学的发展。他的神经理论解释了大规模处理如何在存储网络中实现稳定的记忆,启发了后来的深度学习研究。
黄仁勋(Jensen Huang)
黄仁勋(Jensen Huang)是英伟达创始人兼首席执行官,他于 1993 年创立英伟达。2001 年入选《财富》40 岁以下最富 40 人;2020 年入选《2020 福布斯全球亿万富豪榜》。2023 年 5 月 30 日,英伟达成为首家市值达到 1 万亿美元的芯片企业,史上第九家跨入美元市值「万亿俱乐部」的企业。2024 年,黄仁勋当选美国工程院院士。
Yann LeCun
Yann LeCun 是 Meta 首席 AI 科学家、NYU 教授,被誉为「卷积神经网络之父」,2019 年 3 月,因在人工智能深度学习方面的贡献获得 2018 年度图灵奖。此外,他还获得了 2014 年 IEEE 神经网络先锋奖(Neural Network Pioneer Award)、2015 年 IEEE PAMI 杰出研究奖和 2016 年 Lovie 终身成就奖。
李飞飞(Fei-Fei Li)
李飞飞是斯坦福大学计算机科学教授,美国工程院院士,专业领域是计算机视觉和认知神经科学。她牵头创建的 ImageNet 数据集和竞赛,在深度学习革命中发挥了重要作用。李飞飞与他人共同创办了斯坦福大学以人为本人工智能研究所 (HAI),并继续突破计算机视觉的界限。
除了在谷歌的工作之外,李飞飞的职业生涯一直在学术界度过。2016 年,李飞飞加入 Google 云端人工智能暨机器学习的中国中心团队,以 Google Cloud 首席科学家身份任团队负责人之一。2018 年 9 月,李飞飞宣布返回斯坦福大学任教,并持续参与斯坦福大学的 AI 议题研究。
2024 年,李飞飞创办了 World Labs,旨在生成用户可以探索的 3D 场景。World Labs 致力于为人工智能提供「空间智能」,即生成、推理和与三维世界互动的能力。
参考链接
https://qeprize.org/winners/modern-machine-learning
https://x.com/QEPrize/status/1886853689031143927
#LIMO
817样本激发7倍推理性能:上交大「少即是多」定律挑战RL Scaling范式
在追求人工智能极限的道路上,"更大即更强" 似乎已成为共识。特别是在数学推理这一被视为 AI 终极挑战的领域,业界普遍认为需要海量数据和复杂的强化学习才能获得突破。然而,来自上海交通大学的最新研究却给出了一个令人震惊的答案:仅需 817 条精心设计的样本,就能让模型在数学竞赛级别的题目上超越当前许多最先进模型。这一发现不仅挑战了传统认知,更揭示了一个可能被我们忽视的事实:大模型的数学能力或许一直都在,关键在于如何唤醒它。
- 论文标题:LIMO: Less is More for Reasoning
- 论文地址:https://arxiv.org/pdf/2502.03387
- 代码地址:https://github.com/GAIR-NLP/LIMO
- 数据集地址:https://huggingface.co/datasets/GAIR/LIMO
- 模型地址:https://huggingface.co/GAIR/LIMO
一、从规模竞赛到范式创新
继 OpenAI 推出 o1 系列、打响推理能力竞赛的第一枪后,DeepSeek-R1 以惊人的数学推理能力震撼业界,引发全球复现狂潮。各大公司和研究机构纷纷遵循同一范式:用更庞大的数据集,结合更复杂的强化学习(RL)算法,试图 “教会” 模型如何推理。
如果把经过充分预训练的大语言模型比作一名天赋异禀的学生,那么主流的 RL Scaling 方法就像是不停地训练、奖惩这位学生,直到他能解出各种复杂数学题。这一策略无疑带来了显著成效 —— 从 Claude 到 GPT-4,从 o1-preview 到 DeepSeek-R1,每一次性能跃升的背后,都是训练数据规模的指数级增长和强化学习算法的持续优化。
然而,在这场看似无休止的数据竞赛中,上海交通大学的研究团队却提出了一个发人深省的问题:如果这位 “学生” 在预训练阶段已掌握了所有必要的知识,我们真的需要庞大数据集来重新训练他吗?还是只需精妙的引导,就能激活他的潜在能力?
他们的最新研究 LIMO(Less Is More for Reasoning)给出了令人震撼的答案:仅用 817 条精心设计的训练样本,借助简单的监督微调,LIMO 就全面超越了使用十万量级数据训练的主流模型,包括 o1-preview 和 QwQ 等顶级选手。这一 “少即是多” 的现象,不仅挑战了 “更大数据 = 更强推理” 的传统认知,更揭示了一个可能被忽视的事实:在 AI 推理能力的突破中,方向可能比力量更重要。
实验结果无可辩驳地印证了这一点。在竞赛级别的美国数学竞赛邀请赛(AIME) 测试中,相比传统方法(以 Numina-Math 为例),LIMO 的准确率从 6.5% 飙升至 57.1%。更令人惊讶的是 LIMO 的泛化能力:在 10 个不同的基准测试上,它实现了 40.5% 的绝对性能提升,超越了使用 100 倍数据训练的模型。这一突破直接挑战了 “监督式微调主要导致记忆而非泛化” 的传统观点,证明了高质量、小规模的数据,远比低效的海量训练更能激发 LLM 的真正推理能力。

相比使用 10 万条数据的 NuminaMath,LIMO 在使用不到 1% 的数据就取得了显著的进步,并在各种数学和多学科基准测试中表现出色。
二、Less is More:从对齐到推理的跨越

自 2023 年 LIMA(Less Is More for Alignment)提出以来,业界逐渐意识到,在对齐(alignment)任务上,“少即是多” 并非一句空话。LIMA 仅用 1000 条高质量数据,就让大语言模型学会了如何生成符合人类偏好的对话。这个发现颠覆了 "模型训练需要海量数据" 的传统认知。
然而,将这一理念扩展到数学推理领域却面临着独特的挑战。与简单的对话格式不同,数学推理被认为是一项需要大量练习和训练才能掌握的复杂认知技能。这就像是教一个学生解题:教会他用礼貌的语气说话,和教会他解决复杂的数学问题,难度显然不可同日而语。因此,一个关键问题是:少即是多(Less is More)原则能否适用于推理?
LIMO 的研究给出了肯定的答案,并揭示了实现这一突破的两个核心前提:
- 第一,知识基础革命(Knowledge Foundation Revolution)。近年来,大模型在预训练阶段已纳入海量数学知识。例如,比起全领域训练数据只有 1.8T 的 Llama2,Llama 3 仅在数学推理上的训练数据就高达 3.7 万亿 token,这意味着现代 LLM 早已 “知道” 大量数学知识,关键是如何 “唤醒” 它们。
- 第二,推理计算革命(Inference-time Computation Scaling Revolution)。最新研究表明,推理链(chain-of-thought, CoT)的长度,与模型的推理能力密切相关。与其在训练阶段硬灌大规模监督数据,不如在推理阶段提供更优质的问题和示范,让模型自主展开深入思考。
基于这两点,LIMO 团队提出了一个全新的理论视角:大模型的推理能力本质上是 "潜伏" 的而非 "缺失" 的。传统的 RL Scaling 方法在尝试 "训练" 模型获得新能力,而 LIMO 则专注于如何有效地 "激活" 模型本就具备的能力。正是建立在这两大基础之上,研究人员提出了 LIMO 假说:
在知识基础已足够完善的情况下,仅需少量高质量示例,就能通过推理链激活模型的潜在推理能力,而无需海量数据。
如果模型在预训练阶段已经获得了丰富的数学知识,那么我们或许只需要用少量但精心设计的例子,来 "唤醒" 这些沉睡的能力。这就像是在教导一个已经掌握了所有必要知识,却不知如何有效运用这些知识的学生。

LIMA vs LIMO: “少即是多” 现象的比较分析
LIMO vs. RL Scaling:两种推理范式的碰撞
强化学习扩展(RL Scaling)
以 OpenAI 的 o1 系列和 DeepSeek-R1 为例,RL Scaling 方法通常试图通过大规模的强化学习训练来增强模型的推理能力。这种方法通常依赖于海量数据及复杂的算法,虽然在某些任务上取得了显著成效,但亦有局限:它将推理能力的提升视为一个需要大量计算资源的“搜索”过程。
LIMO 的新视角
与之相对,LIMO(Less Is More for Reasoning)提出了一个不同的理论框架,认为推理能力潜藏于预训练模型中,关键在于如何通过精确的认知模板来激发这些内在能力。这一转变将研究重点从“训练新能力”转向“激活潜在能力”,强调了方向的重要性。
LIMO 的核心假设是,在知识基础已经足够完善的情况下,利用少量高质量的示例就能够激活模型的潜在推理能力。这一理论不仅重新定义了 RL Scaling 的位置,将其视为寻找最优推理轨迹的一种手段,更为整个领域的研究提供了新的思考框架。
研究意义
在当下,以 DeepSeek-R1 为代表的 RL Scaling 方法逐渐成为主流,LIMO 研究的意义则在于提供了一个更加本质的视角:大模型的推理能力本身是内在存在的,关键挑战在于如何找到最优的激活路径。
这一洞察不仅重新定义了 RL Scaling,将其视为寻找最优推理轨迹的一种实现方式,更重要的是,它引领了一种全新的研究范式——从“训练新能力”转向“激活潜在能力”。这一转变不仅加深了我们对大模型推理能力的理解,也为更高效的能力激活方法提供了明确的方向。
LIMO 和 RL Scaling 的对比,揭示了推理能力提升的不同路径与思路。LIMO 提供了更为根本的理解,指明了未来研究的方向:不再是无止境的数据堆砌,而是更加关注如何有效激活模型本就具备的能力。

LIMO 和 RL Scaling 方式的比较分析
实验验证:颠覆性的结果
LIMO 的理论得到了实验结果的强力支持。仅凭 817 条数据,LIMO 就超越了主流的 OpenAI-o1-preview 和 QwQ 等模型。它的性能相较于自身的基座模型 (Qwen2.5-32B-Instruct) 有显著的提升,更是击败了采用数十万数据的 OpenThoughts 和 Numina Math。
在传统评测任务上,LIMO 取得了突破性表现。在数学竞赛级别的 AIME24 测试中,LIMO 赢得了 57.1% 的准确率,远超 QwQ 的 50.0% 和 o1-preview 的 44.6%。在 MATH500 测试中,LIMO 更是达到了 94.8% 的惊人成绩,显著超越了 QwQ(89.8%)和 o1-preview(85.5%)。这些数据清晰地表明,少量但精心设计的训练数据,确实能带来超越传统方法的性能提升。
在各类跨域测试中,LIMO 的泛化能力同样表现出色。在奥林匹克数学测试(OlympiadBench)上,LIMO 达到了 66.8% 的准确率,远超 QwQ 的 58.5%;尽管 LIMO 数据集中不包含任何中文数据,在中国高考数学(Gaokao)测试中,它也取得了 81.0% 的成绩,领先于 QwQ 的 80.1%。这种广泛的适用性让我们发现,LIMO 不是简单地记忆了训练数据,而是真正掌握了数学推理的本质。
总体而言,LIMO 在所有测试中的平均准确率达到了 72.8%,大幅领先于 o1-preview(61.1%)和 QwQ(66.9%)。这个结果不仅证实了 "Less is More" 假说的正确性,更为整个行业指明了一个全新的发展方向:也许我们不需要无止境地堆砌数据和算力,而是应该更多地思考如何激活模型本就具备的能力。

LIMO 和其他模型在多个基准测试上的性能比较
三、数据的三重密码
基于 LIMO 假设,我们构建了高质量的数据集,并通过实验揭示了少量数据提升大模型推理能力的三大关键因素,即推理链质量、问题难度和预训练知识:
推理链质量:细节决定成败
想象一下,你在教一个学生解题。如果只是简单告诉他答案,他可能永远无法真正理解背后的逻辑。但如果你详细解释每一步的推理过程,甚至让他自己验证每一步的正确性,他就能逐渐掌握解题的精髓。LIMO 的研究发现,推理链的质量对大模型的推理能力有着决定性影响。
实验表明,高质量推理链(L5)与低质量推理链(L1)之间的性能差距高达 15 个百分点。高质量推理链不仅逻辑清晰、步骤完整,还包含自我验证环节,确保推理的正确性。而低质量推理链往往只是简单列举步骤,缺乏详细的逻辑推导。这表明,精心设计的推理链不仅能帮助模型更好地理解问题,还能提高其推理的准确性和泛化能力。

不同质量等级(1~5)推理链训练得到的模型在 AIME24 和 MATH500 上的表现
问题难度:挑战激发潜力
如果说推理链是解题的 “路线图”,那么问题本身则是激发模型潜力的 “催化剂”。LIMO 的研究发现,更高难度的问题能够显著提升模型的推理能力。研究人员创建了三个不同难度的问题集:Simple-500, Complex-500 和 Advanced-500,分别为他们构建高质量的推理链并训练模型。实验表明,使用 Advanced-500(竞赛级别问题)训练的模型,在基准测试中的准确率比使用 Simple-500(简单数学题)训练的模型高出 16%。
这背后的逻辑在于,更复杂的问题需要更长的推理链和更深入的知识整合,从而迫使模型在推理过程中更充分地利用其预训练知识。这就像让一个学生不断挑战更高难度的题目,他的解题能力也会随之提升。因此,选择更具挑战性的训练数据,可能是提升模型推理能力的有效策略。

不同难度问题集训练后的模型在 AIME24 和 MATH500 上的表现
预训练知识:基础决定高度
最后,LIMO 的研究强调了预训练知识的重要性。实验对比了两种架构相同但预训练数据质量不同的模型,结果显示,Qwen2.5-32B-Instruct(预训练数据质量更高)在数学推理任务上的表现显著优于 Qwen1.5-32B-Chat,AIME24 准确率提升了 47 个百分点。
这说明,模型的推理能力很大程度上依赖于其预训练阶段所掌握的知识。如果模型在预训练阶段已经接触并理解了大量数学知识,那么只需要少量高质量示例,就能激活其推理能力。反之,如果预训练知识不足,即使使用大量数据进行微调,效果也可能有限。因此,提升预训练数据的质量和多样性,可能是未来提升模型推理能力的关键。

采用 LIMO 数据微调相同架构、不同预训练数据的模型,二者性能区别显著
四、案例与定量分析:LIMO 的卓越表现
在具体的案例分析中,LIMO 展现出了令人瞩目的推理能力。图 5 对比了 Qwen2.5-32B-Instruct、DeepSeek-R1 和 LIMO 生成的响应。尽管 LIMO 仅使用了 817 个训练样本,但其表现与 DeepSeek-R1 不相上下,甚至在某些方面更为出色。LIMO 不仅能够进行自我反思,还能在长链推理中保持高度准确性。例如,LIMO 在验证自己的陈述时表现出色:“等一下,24 分钟是 0.4 小时?不对。60 分钟是 1 小时,所以 24 分钟是 24/60,也就是 0.4 小时。” 这种自我验证和修正的能力,使得 LIMO 在复杂的数学推理任务中表现尤为突出。

相同问题下,不同模型的推理链和 LIMO 的比较
相比之下,Qwen2.5-32B-Instruct 在推理过程中表现出明显的局限性,无法纠正不准确的陈述,并且在求解方程时未能进行交叉验证。这些结果不仅支持了 LIMO 假设,更表明通过少量高质量的训练样本,模型可以被赋予强大的推理能力。
在定量分析中我们发现:随着训练样本质量的提高,模型生成的响应更长,行数更多,并且在推理过程中使用了更多的自我反思过渡词(例如,“等一下”、“也许”、“因此”)。这些高质量模型能够分配额外的计算资源,进行更深入的思考,从而在复杂的数学问题中表现出色。

不同质量推理链的定量分析
五、未来展望:少即是多的无限可能
尽管 LIMO 在极小数据量的情况下在数学推理方面取得了显著成功,但未来的研究仍然充满挑战和机遇。
1. 领域泛化
将 LIMO 假设扩展到更广泛的推理领域是一个关键方向。虽然当前的研究主要集中在数学推理上,但高质量推理链的原则可能适用于科学推理、逻辑推理和因果推理。理解这些原则如何跨领域转移,可能揭示有效推理的通用模式。这一探索需要调整质量评估标准,并开发特定领域的评估框架,从而为机器推理的理论体系做出贡献。
2. 理论基础
对 LIMO 成功的更深层次理论理解也至关重要。未来的研究应致力于形式化预训练知识、推理时计算和推理能力之间的关系。这包括研究有效推理所需的最小预训练知识阈值,并开发数学模型以预测推理链质量与数量之间的最佳平衡。这些理论基础可以指导更高效的训练策略,并为机器推理的本质提供洞见。
3. 自动化评估
开发自动化质量评估工具是另一个重要方向。目前对推理链质量的手动评估虽然有效,但耗时且难以扩展。未来的工作应致力于创建能够根据我们提出的指标自动评估和改进推理链质量的系统。这可能包括开发算法来自动增强现有推理链,并以最少的人工干预生成高质量推理链,从而使 LIMO 方法更具可扩展性和可访问性。
4. 多模态集成
跨模态推理为扩展 LIMO 原则提供了一个激动人心的前沿领域。由于现实世界中的推理通常涉及多种模态,研究视觉信息和结构化数据如何增强数学推理能力至关重要。这一研究方向需要开发新的多模态推理链质量评估标准,并理解不同类型的信息如何有效集成到推理过程中。
5. 实际影响
将 LIMO 原则应用于现实场景值得特别关注。未来的工作应致力于将这些方法应用于教育、科学研究和工业应用中的实际问题。这包括为特定领域开发专门版本的 LIMO,并创建帮助人类专家生成高质量推理链的工具。这些应用可能显著影响我们在各个领域中的问题解决方式。
6. 认知科学桥梁
最后,整合认知科学的见解可以为改进提供有价值的方向。理解 LIMO 的推理模式与人类认知过程之间的相似性,可能有助于开发更有效的推理策略。这包括研究不同推理方法如何影响模型的性能和泛化能力,并将认知科学原则融入推理链的设计中。这样的研究不仅可以改进人工智能系统,还可以为人类推理过程提供洞见。
这些未来方向共同致力于加深我们对大语言模型中高效推理的理解,同时扩展其实际应用。通过探索这些路径,我们可以朝着开发更复杂、高效且广泛适用的推理系统迈进,以更好地服务于各个领域的人类需求。
LIMO 的研究不仅挑战了 “更大即更强” 的传统认知,更揭示了大模型推理能力的潜在机制。通过少量高质量的训练样本,LIMO 成功激活了模型的潜藏能力,展示了 “少即是多” 的惊人效果。这一发现不仅为未来的研究指明了方向,更为我们理解大模型的能力本质提供了新的视角。
在未来,随着 LIMO 假设的进一步验证和扩展,我们有望看到更多高效、精准的推理系统在各个领域中得到广泛应用。这不仅将推动人工智能技术的发展,更将深刻影响我们解决复杂问题的方式。LIMO 的成功,或许只是人工智能推理能力觉醒的开始,未来的路,充满无限可能。

















 2102
2102

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









