







简介部分
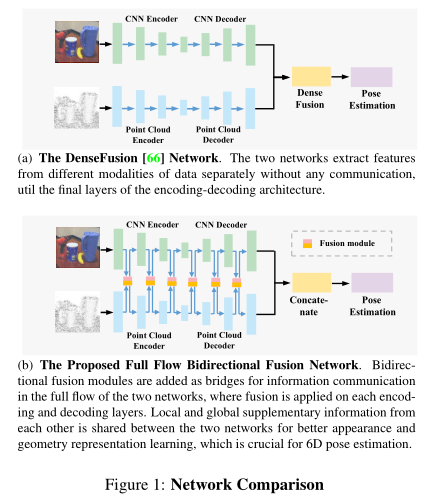
使用RGBD图像,融合RGB图像和深度图,是对DenseFusion的改进。
改进了融合模块,融合应用于每个编码和解码层
还提出了一种3D关键点选择方法,简化了关键点定位
作者认为先在RGB图像出估计初始位姿,再通过点云ICP(Posecnn)或multi-view hypothesis verification来优化非常耗时,而且使用不了端到端的RGB图像优化。
将RGB和点云分割开在某些情况下性能不佳,比如具有相似外观或具有反射表面的物体
孤立的CNN和PCN对这种情况都识别不出太好的结果,但是融合方法应该1+1>2,而不是1+1=2
提出一种全流双向融合网络,在每个编码层和解码层上执行融合,RGB中的外观信息和点云中的几何信息可以作为特征提取过程中的补充信息,相似图像的不同物体可以通过点云信息分辨,物体反射表面引起的深度缺失可以通过图像分辨。
因此,必须分别从RGB图像和点云进行特征提取,作者提出的融合机制则弥补了信息鸿沟
pipline沿用PVN3D,但是PVN3D仅考虑了3d keypoints之间的距离,一些选定的关键点可能会出现在不显著的区域,如没有显著纹理的光滑表面,很难去定位
PVN3D第一次使用key points来进行6D pose estimation
作者同时考虑了对象纹理和几何信息,提出了新的3d keypoints方法,便于网络定位,提高姿态估计性能。
作者对文献综述的表达:

其中:
端到端方法,直接从RGB图像输出姿势参数。受到旋转空间非线性的限制
密集对应方法,找到图像像素和网格顶点之间的对应关系,并以透视nPoint(PnP)方式恢复姿势。虽然对遮挡具有鲁棒性,但较大的输出空间限制了预测精度。
2D关键点方法,检测对象的2D关键点,以建立用于姿势估计的2D-3D对应关系。然而,由于透视投影导致的几何信息丢失限制了这些仅RGB方法的性能
基于点云的方法,点云的稀疏性和非纹理性限制了这些方法的性能,且具有反射表面的物体无法被深度传感器捕获
从RGB中提出初始姿态,再使用ICP/MCN使用点云进行refine,耗时,无法进行端到端的优化
分别使用CNN和点云网络从RGB图像和点云中提取特征,然后将它们融合,进行位姿估计,由于外观和几何特征是分开提取的,这两个网络无法通信和共享信息,从而限制了学习表示的表达能力
本文pipline
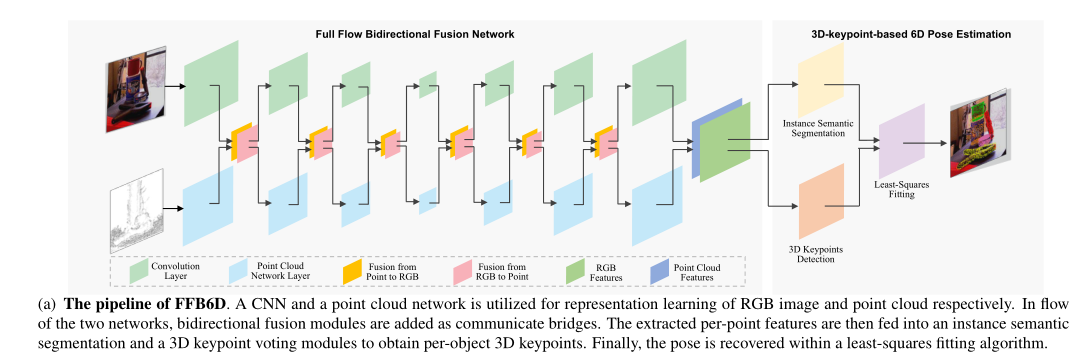
添加了双向融合模块作为通信桥。然后将提取的逐点特征输入到实例语义分割和三维关键点投票模块中,以获得每对象的三维关键点。最后,使用最小二乘拟合算法恢复姿势。
具体的融合操作:
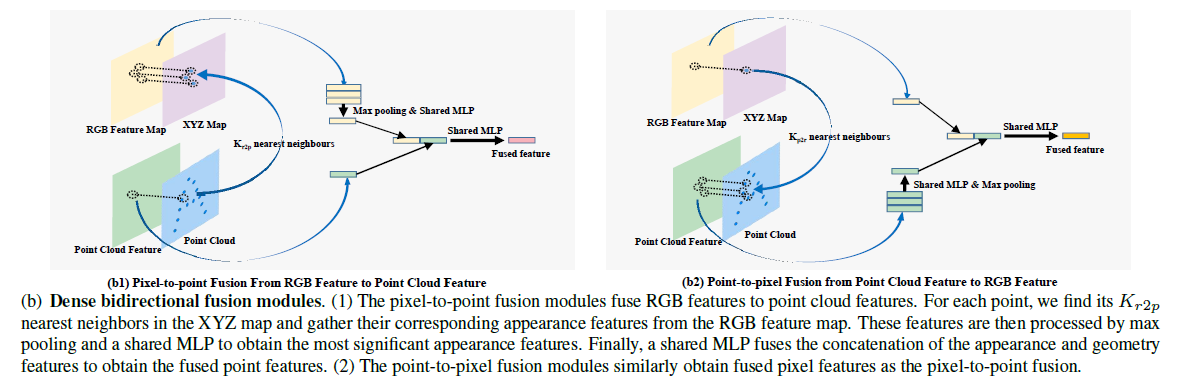
提出的模块
给定一个对齐的RGBD图像,我们首先将深度图像提升到具有相机固有本质矩阵的点云。深度图要转化成点云
从图像特征到点云特征:像素到点融合
一种原始的方法:从RGB图像中提取全局特征,拼接在每个点特征的后面
然而,由于场景中的大多数像素都是背景,并且场景中存在多个对象,因此对RGB特征图进行全局压缩会丢失大量的细节信息,并对后续的姿态估计模块造成损害。
本文提出的方法:
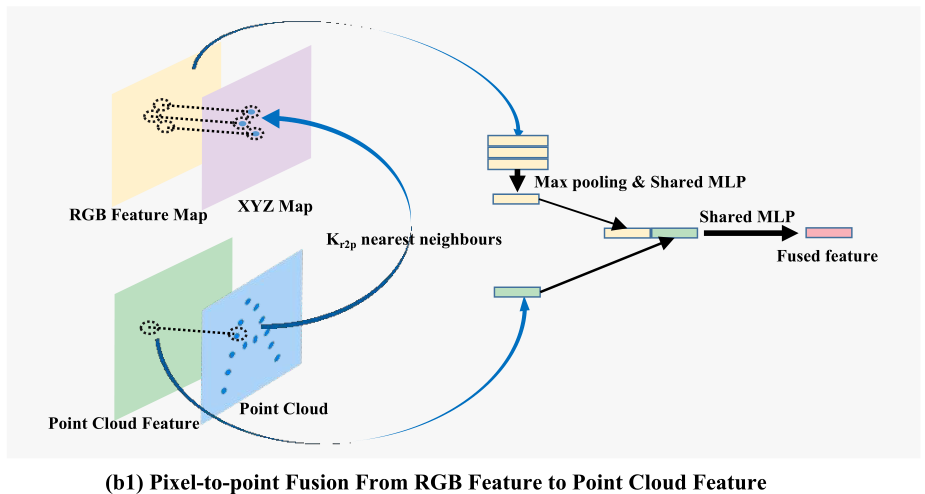
我们利用摄像机内参本质矩阵将每个像素的深度提升到其对应的3D点,得到XYZ地图
对于每个点特征及其三维点坐标,我们在XYZ地图中找到其Kr2p最近点,并从RGB特征图中收集其相应的外观特征。然后,我们使用max polling来集成这些相邻的外观特征,并应用共享多层感知器(MLP)将其压缩到与点云特征相同的通道大小。
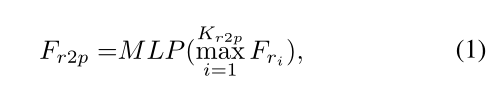

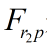
是融合后的像素特征
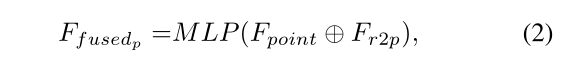
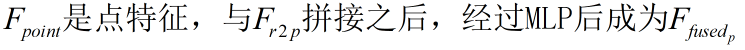
为了在每一层特征中都得到像素对应的3D坐标,需要进行一些变化。
由于特征映射的缩小是通过卷积核扫描原始特征映射生成的,因此核的中心成为特征映射的新坐标。
一种简单的方法是应用相同大小的核来计算其中XYZ的平均值,以生成像素的新XYZ坐标。
然而,由于深度在前景对象和背景的边界上变化剧烈,平均运算会产生噪声点。
更好的解决方案是用最近插值算法,将XYZ地图调整为与特征图相同的大小
从点云特征到图像特征:点到像素融合
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NolDCibY-1638191930259)(https://typora-yel.oss-cn-beijing.aliyuncs.com/2021_11_29[17.16.51].png)]
对于具有XYZ坐标的每个像素,我们从点云中找到其Kp2r最近点,并收集相应的点特征。我们将点特征压缩到与RGB特征相同的通道大小,然后使用max pooling来集成它们。然后将集成的点特征连接到相应的颜色特征,并通过共享MLP进行映射,以生成融合的点特征。
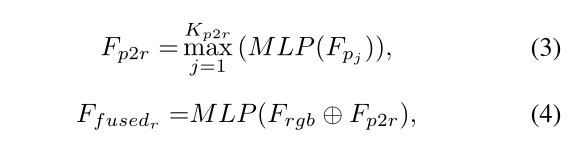
密集RGBD特征嵌入
从CNN分支获得表面纹理特征,从PCN分支获得几何特征。然后,我们通过使用相机本质矩阵将每个点投影到图像平面来找到它们之间的对应关系。根据对应关系,我们获得外观特征和几何特征对,并将它们连接在一起,形成提取的密集RGBD特征。在下一步中,这些特征被输入到一个实例语义分割模块和一个3D关键点检测模块中,用于物体姿态估计。
基于3D关键点的6D姿态估计
首先在场景中检测每个对象选择的3D关键点,然后利用最小二乘拟合算法恢复姿势参数
逐对象三维关键点检测
通过添加实例语义分割模块来区分不同的对象实例,并添加关键点投票模块来恢复三维关键点,从而获得每个对象的三维关键点。实例语义分割模块由语义分割模块和中心点投票模块组成,前者预测每点语义标签,后者学习每点到对象中心的偏移量,以区分不同的实例。对于每个对象实例,关键点投票模块学习到在MeanShift聚类方式内投票给3D关键点的选定关键点的逐点偏移。(PVN3D的方法)
由于FPS仅考虑欧几里德距离,因此所选点可能出现在非显著区域,例如没有明显纹理的平面。
提出了一种简单而有效的三维关键点选择算法SIFT-FPS
使用SIFT算法检测纹理图像中与众不同的2D关键点,然后将其提升到3D。然后应用FPS算法选择其中的前N 个关键点。这样,选定的关键点不仅均匀分布在物体表面,而且纹理独特,易于检测。
感觉就是很简单的加了 SIFT,可以考虑创新3D关键点检测
实验部分
各数据集介绍与表现
1. YCB-Video
和PVN3D进行了相同的操作,分割训练集和测试集,填补了深度图的空白
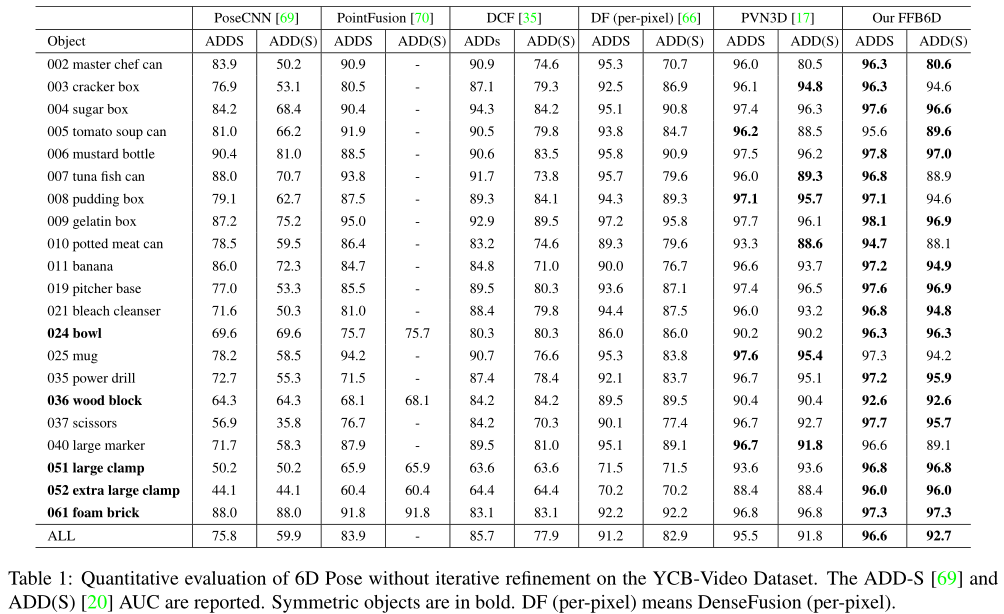
YCB - Video准确率
表1 显示了FFB6D在YCB视频数据集上的评估结果。本文将其与其他没有迭代求精的单视图方法进行了比较。
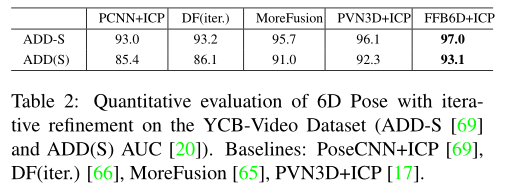
通过额外的迭代优化,本文的方法也实现了最佳性能,如表2所示。
FFB6D的效果在不使用ICP的情况下还优于PVN3D + ICP
对遮挡非常鲁棒
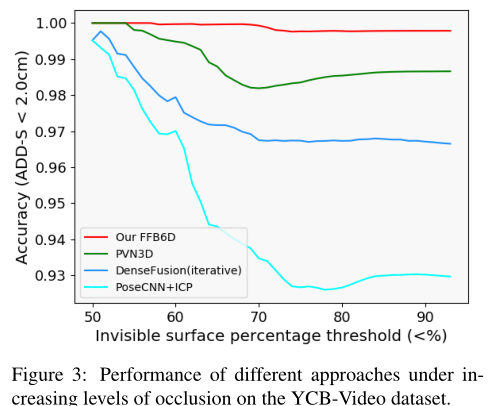
作者模仿PVN3D,报告了在YCB视频数据集上遮挡水平增长的情况下,ADD-S精度小于2cm的比例。如 图3 所示,以前的方法会随着遮挡的增加而降低。相比之下,FFB6D的性能没有下降。作者认为,全流双向融合机制充分利用了捕获数据中的纹理和几何信息,使作者的方法能够在高度遮挡的场景中定位3D关键点。
2. LineMOD
对数据集和PVN3D进行了相同的操作,分割数据集,增加合成图像等
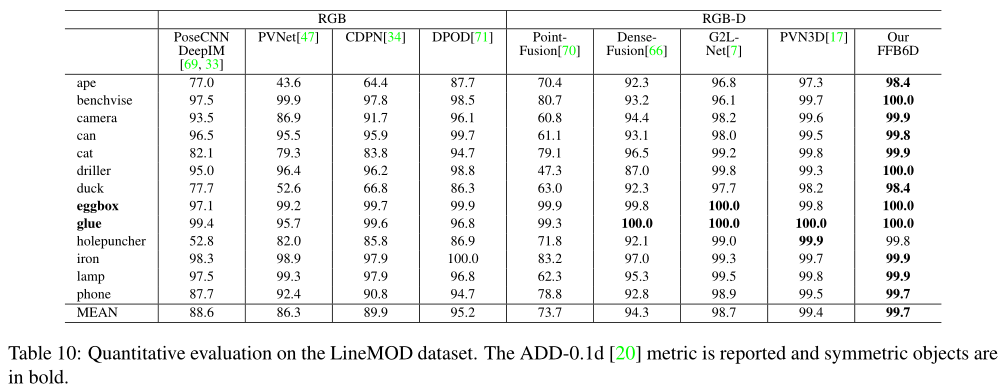
3. Occlusion LINEMOD(相比PVN3D增加的数据集)
从LineMOD数据集中选择并注释。该数据集中的每个场景都由多注释对象组成,这些对象被严重遮挡。严重遮挡的对象使数据集面临挑战。
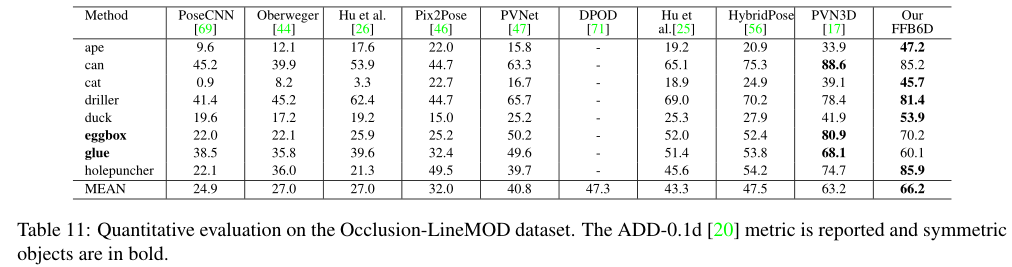
证明了对遮挡的鲁棒性
评估标准
YCB-Video数据集中还是普通的ADD和ADD-S,计算精度阈值曲线的面积
在LineMOD和Occlusion LineMOD数据集中,本文计算的距离精度小于物体直径的10%(ADD-0.1d)(和Pvnet相同的操作)
网络结构
RGB: 我们采用ImageNet预训练的ResNet34作为RGB图像的编码器,然后使用PSPNet作为解码器。
点云: 对于点云特征提取,从深度图像中随机抽取12288个点,并应用RandLA-Net进行表征学习。
在两个网络的编码层和解码层中,采用最大池和共享MLP构建双向融合模块。经过全流双向融合网络的处理,每个点都有一个C维度的特征向量。
然后将这些密集的RGBD 特征 输入具有共享MLP的 实例语义分割和关键点偏移学习模块中。
损失函数
语义分割模块由Focal Loss进行监督,中心点投票和3D关键点投票模块通过L1 Loss进行监督,为了联合优化这三项任务,在其中应用了多任务损失及其加权和。(与PVN3D相同)
烧蚀研究
验证融合效果
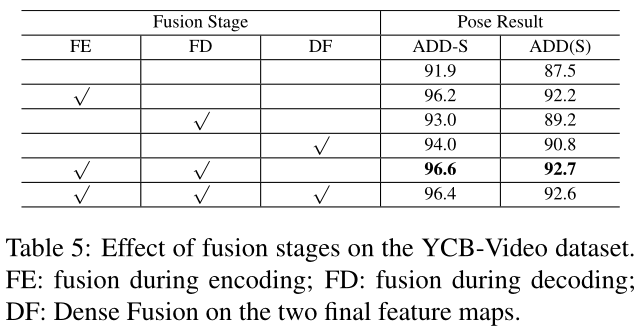
为了验证在两个模态网络之间以全流方式构建融合模块是否有帮助,我们在表5中消融了融合阶段。
与没有融合的机制相比,无论是在编码阶段、解码阶段,还是在最终的特征映射上添加融合模块,都可以提高性能。
在这三个阶段中,编码阶段的融合得到了最大的改进,作者认为,这是因为在早期编码阶段,提取的局部纹理和几何信息通过融合桥共享,而随着网络的深入,更多的全局特征被共享。
对于DF模块并没有优化作用,作者的解释是,最后添加额外的密度融合,由于两个嵌入件已完全融合,因此没有获得任何性能增益
验证双向效果
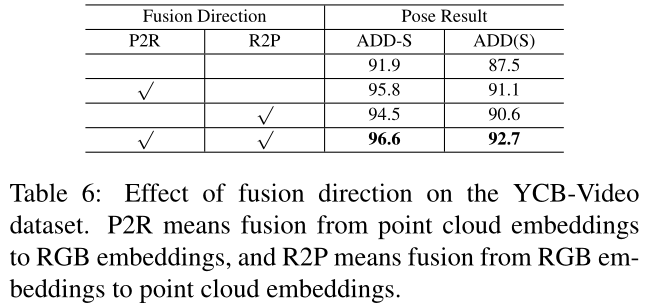
作者还消除了 表6 中的融合方向,以验证双向融合的帮助。与未融合相比,从RGB到点云的融合和反向方式都有利于更好的表示学习。将两者结合在一起可获得最佳结果。
一方面,从PCN的角度来看,作者认为从高分辨率RGB图像中获取的丰富纹理信息有助于语义识别。此外,高分辨率RGB功能为反射表面引起的深度传感器盲区提供了丰富的信息。它可以作为点云的补充,并提高姿势精度。
另一方面,从点云提取的几何体信息通过区分 具有相似颜色的 前景和背景 来帮助RGB分支。此外,从点云提取的形状大小信息有助于分割外观相似但大小不同的对象
表征学习框架的效果
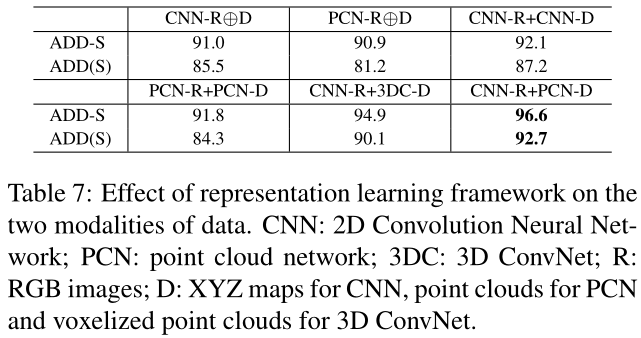
在RGB图像上应用CNN和在点云上应用PCN(CNN-R+PCN-D)可以获得最佳性能。作者认为网格状的图像数据是离散的,正则卷积核比连续PCN更适合于离散的图像数据。而深度图中的几何信息是在一个连续的向量空间中定义的,因此PCN可以学习更好的表示。
时间效率

速度快了2.5倍
2021.12.1更新
















 500
500











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











