







YCB-VIDEO DATASET
提供物体姿势和分割真值标记以物体为中心的数据集通常因为是人工标注的,所以数据量很小。例如常用的LINEMOD数据集提供大约1000图像的手工标记为数据集中的15个对象。虽然这样的数据集对于评估基于模型的姿态估计技术很有用, 它比用于训练最先进的深度神经网络的典型数据集小了好几个数量级。解决这个问题的一个办法是用合成图像来增加数据。然而,必须注意确保性能在真实场景和渲染场景之间的通用性。
- A. 6D位姿标记
为了避免手动注释所有的视频帧,我们只在第一帧中手动指定物体的姿势。利用每个物体的有符号距离函数(SDF)表示,我们在第一个深度帧中细化每个物体的姿势。接下来,通过固定物体的相对位置并通过深度视频跟踪物体的配置,初始化摄像机的轨迹。最后,在全局优化步骤中完善相机轨迹和相对物体的姿势。
符号距离函数(sign distance function),简称SDF,又可以称为定向距离函数(oriented distance function),在空间中的一个有限区域上fixing确fixing定一个点到区域边界的距离并同时对距离的符号进行定义:点在区域边界内部为正,外部为负,位于边界上时为0。

- B. Dataset Characteristics
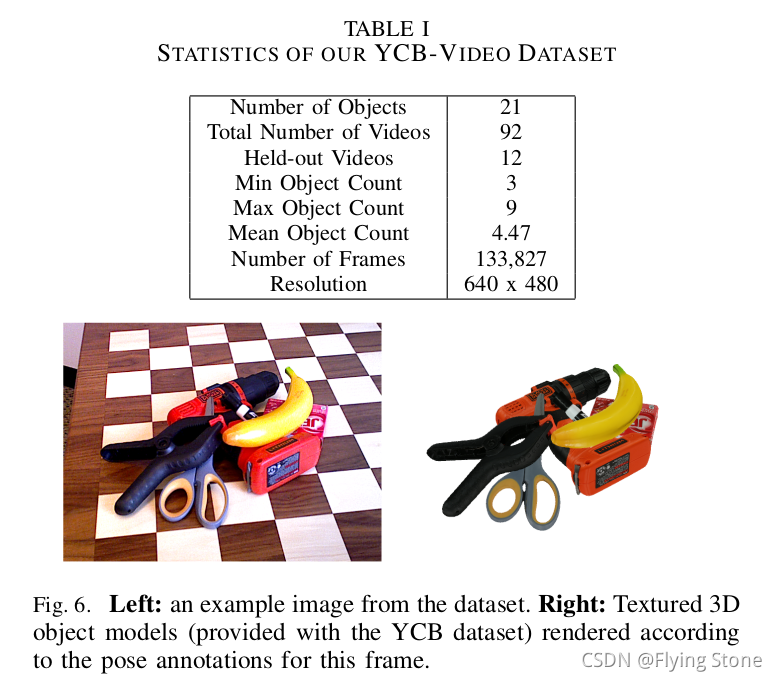
我们使用的物体是图5所示的21个YCB物体的一个子集,由于高质量的三维模型和良好的深度可见度而被选中。视频的采集是使用一个华硕Xtion Pro Live RGB-D相机在快速剪裁模式下采集的。它提供了分辨率为640x480的RGB图像,速度为30FPS,在设备上捕获1280x960的图像,然后通过USB传输中心区域。这导致了 更高的RGB图像的有效分辨率,但代价是较低的FOV,但鉴于深度传感器的最小范围 这是一个可以接受的折衷方案。完整的数据集包括 133,827张图片,比起 LINEMOD数据集。有关该数据集的更多统计数据。见表一。图6显示了我们数据集中的一个注释例子 其中,我们根据注释的 地面真实姿态。。请注意,我们的注释准确性受到了 误差的几个来源,包括RGB传感器的滚动快门包括RGB传感器的滚动快门、物体模型的不准确、RGB和深度的轻微不同步。RGB和深度传感器之间的轻微不同步,以及本征和外征的不确定性。相机的内在和外在参数的不确定性。
- 模型文件举例

















 3088
3088

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









