1、代码实现
% clear
% clc
% load('data1.mat')
% % 数据集构建(列为特征,行为样本数目
% for i =1:7
% l(:,i) = feature_1.p1(:,i) ;
% l(:,i+7) = feature_1.p2(:,i);
% l(:,i+14) = feature_1.p3(:,i) ;
% l(:,i+21) = feature_1.p4(:,i) ;
% l(:,i+28) = feature_1.p5(:,i) ;
% l(:,i+35) = feature_1.p6(:,i) ;
% l(:,i+42) = feature_1.p7(:,i) ;
% l(:,i+49) = feature_1.p8(:,i) ;
% l(:,i+56) = feature_1.p9(:,i) ;
% l(:,i+63) = feature_1.p10(:,i) ;
% l(:,i+70) = feature_1.f1(:,i) ;
% l(:,i+77) = feature_1.f2(:,i) ;
% l(:,i+84) = feature_1.f3(:,i) ;
% l(:,i+91) = feature_1.f4(:,i) ;
% l(:,i+98) = feature_1.f5(:,i) ;
% l(:,i+105) = feature_1.s1(:,i) ;
% l(:,i+112) = feature_1.s2(:,i) ;
% l(:,i+119) = feature_1.s3(:,i) ;
% l(:,i+126) = feature_1.s4(:,i) ;
% l(:,i+135) = feature_1.t1(:,i) ;
% l(:,i+140) = feature_1.t2(:,i) ;
% l(:,i+147) = feature_1.t3(:,i) ;
% l(:,i+154) = feature_1.t4(:,i) ;
% l(:,i+161) = feature_1.t5(:,i) ;
% l(:,i+168) = feature_1.t6(:,i) ;
% l(:,i+175) = feature_1.t7(:,i) ;
% l(:,i+182) = feature_1.t8(:,i) ;
% end
%
%% 数据集降维提取 相关性较高的特征值。
% 加载数据
clear
clc
load('D.mat')
for f= 1:size(data,2)
Ti(:,f) = normalize(data(:,f));
d(1,f) = corr(life,Ti(:,f),'type','Spearman');
end
% 相关性系数
d = abs(d); % 将相关系数绝对值
[j main_feature] = find(d>=0.8);
% % ±0.80-±1.00 高度相关
M = length(main_feature);
for k = 1:M
p = main_feature(1,k);
Data1(:,k) = data1(:,p); % 提取降维特征
Data2(:,k) = data2(:,p);
Data3(:,k) = data3(:,p);
Data4(:,k) = data4(:,p);
Data5(:,k) = data5(:,p);
Data6(:,k) = data6(:,p);
end
%% 设置训练集及测试集
y = [life1;life1];
y = [y;life1];
x = [Data1;Data1];
x = [x;Data1];
[xnorm,xopt] = mapminmax(x',0,1);
[ynorm,yopt] = mapminmax(y',0,1);
x = x';
% 转换成2-D image
for i = 1:size(Data1,1)
Train_xNorm{i} = reshape(xnorm(:,i),M,1,1);
Train_yNorm(i) = ynorm(i);
end
Train_yNorm= Train_yNorm';
% 测试集设置
%% 测试集
ytest = life2;
xtest = Data2;
[xtestnorm] = mapminmax('apply', xtest',xopt);
[ytestnorm] = mapminmax('apply',ytest',yopt);
xtest = xtest';
% 转换成2-D image
for i = 1:315
Test_xNorm{i} = reshape(xtestnorm(:,i),M,1,1);
Test_yNorm(i) = ytestnorm(i);
Test_y(i) = ytest(i);
end
Test_yNorm = Test_yNorm';
%% 随机种子数
% % % % % % % % 设定随机种子数
w=1;
s=1;
% for w =1:100
% for s =1:10
% %寻找最优隐含层
rng('default');
% rand(27,1);
% LSTM 层设置,参数设置
inputSize = size(Train_xNorm{1},1); %数据输入x的特征维度
outputSize = 1; %数据输出y的维度
numhidden_units1=41;
numhidden_units2=20;
% numhidden_units3=8;
% numhidden_units4=5;
%
opts = trainingOptions('adam', ...
'MaxEpochs',20, ...
'GradientThreshold',1,...
'ExecutionEnvironment','cpu',...
'InitialLearnRate',0.00005, ...
'LearnRateSchedule','piecewise', ...
'LearnRateDropPeriod',10, ... %2个epoch后学习率更新
'LearnRateDropFactor',0.5, ...
'Shuffle','once',... % 时间序列长度
'MiniBatchSize',1,...
'Verbose',0,...
'Plots','training-progress' ); % 打印训练进度
%
layers = [ ...
sequenceInputLayer([inputSize,1,1],'name','input') %输入层设置
sequenceFoldingLayer('name','fold')
convolution2dLayer([1,1],16,'Stride',[1,1],'name','conv1')
batchNormalizationLayer('name','batchnorm1')
reluLayer('name','relu1')
maxPooling2dLayer([1,3],'Stride',1,'Padding','same','name','maxpool')
convolution2dLayer([2,1],10,'Stride',[1,1],'name','conv2')
batchNormalizationLayer('name','batchnorm2')
reluLayer('name','relu2')
maxPooling2dLayer([1,3],'Stride',1,'Padding','same','name','maxpoo2')
% convolution2dLayer([1,1],6,'Stride',[1,1],'name','conv3')
% batchNormalizationLayer('name','batchnorm3')
% reluLayer('name','relu3')
% maxPooling2dLayer([1,3],'Stride',1,'Padding','same','name','maxpoo3')
sequenceUnfoldingLayer('name','unfold')
flattenLayer('name','flatten')
gruLayer(numhidden_units1,'Outputmode','sequence','name','hidden1')
dropoutLayer(0.5,'name','dropout_1')
gruLayer(numhidden_units2,'Outputmode','last','name','hidden2')
dropoutLayer(0.5,'name','dropout_2')
% gruLayer(numhidden_units3,'Outputmode','last','name','hidden3')
% dropoutLayer(0.5,'name','dropout_3')
% gruLayer(numhidden_units4,'Outputmode','last','name','hidden4')
% dropoutLayer(0.5,'name','dropout_4')
fullyConnectedLayer(4,'name','fc1') % 全连接层设置(影响输出维度)(cell层出来的输出层) %
reluLayer('name','relu3')
fullyConnectedLayer(outputSize,'name','fc2') % 全连接层设置(影响输出维度)(cell层出来的输出层) %
tanhLayer('name','sm')
regressionLayer('name','output')];
lgraph = layerGraph(layers);
lgraph = connectLayers(lgraph,'fold/miniBatchSize','unfold/miniBatchSize');
%
% 网络训练
net = trainNetwork(Train_xNorm,Train_yNorm,lgraph,opts);
% 测试
close all
Predict_Ynorm{w,s} = net.predict(Test_xNorm,'MiniBatchSize',1); % 测试集
YPred = net.predict(Train_xNorm,'MiniBatchSize',1); % 训练集
% 反归一化
Predict_Y{w,s} = mapminmax('reverse',Predict_Ynorm{w,s}',yopt); % 训练集
Predict_Y1{w,s} = mapminmax('reverse',YPred,yopt); % 测试集
Predict_Y{w,s}= Predict_Y{w,s}';
Predict_Y1{w,s}= Predict_Y1{w,s}';
%计算均方根误差 (RMSE)。
rmse1(w,s) = sqrt(mean((Predict_Y{w,s}-Test_y').^2)); % 训练集
rmse2(w,s) = sqrt(mean((Predict_Y1{w,s}-life1').^2)); % 测试集
% end
% % end
% 可视化
plot(Predict_Y1{w,s})
hold on
plot(life1)
figure
plot(smooth(Predict_Y{1,1}))
hold on
plot(Test_y)
subplot(2,1,1)
plot(Predict_Y/100)
hold on
plot(Test_y/100,'r-')
hold on
plot(YPred{1,1}/100,'.-')
hold on
plot(YPred1{1,1}/100,'g')
subplot(2,1,2)
stem(Predict_Y-Test_y')
xlabel("日期")
ylabel("均方根误差")
title("RMSE = " + rmse1);
%
subplot(2,1,1)
subplot(2,1,2)
stem(Predict_Y-Test_y')
xlabel("日期")
ylabel("均方根误差")
figure
title("RMSE = " + rmse1);
as=Predict_Ynorm';
plot(as{1,1})
hold on
plot(ytestnorm(1,:),'r-');
%
% clearvars -except Predict_Y %清除除DATA外的所有变量
% for i=5
% end
2.预测结果(该数据的标签选择为刀具磨损量,不是寿命预测值)
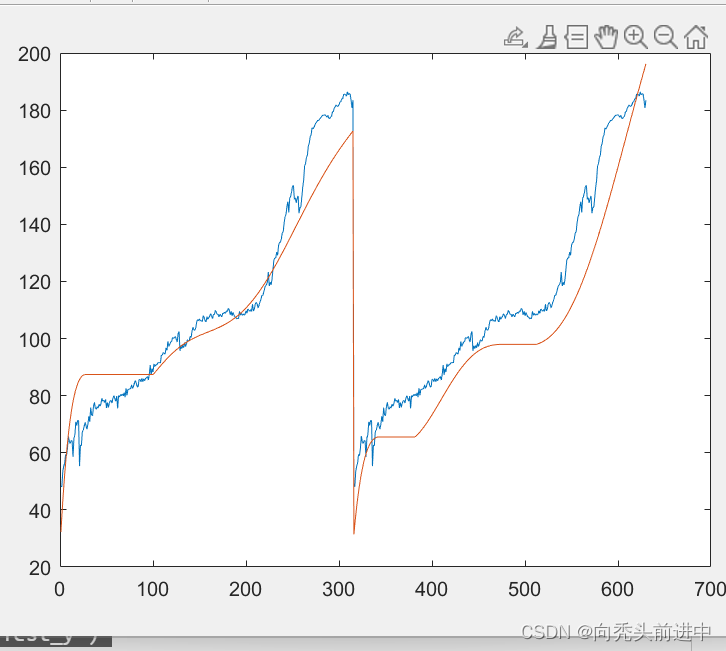
3.改一下循环神经网络的层数名称即可
(gruLayer改为——lstmLayer)






















 1329
1329











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









