一、脑图

二、文字
2D视觉和3D视觉在人类的视觉系统中扮演着不同的角色。2D视觉主要关注于平面图像的信息处理,而3D视觉则涉及到对深度信息的理解和处理【4】。人类的大脑能够将2D视网膜图像转换成物体的3D形状,这一过程虽然在数学上看似不可能,但却是我们日常生活中不可或缺的一部分【4】。这表明,尽管2D和3D视觉在信息处理的方式上有所不同,但它们之间存在着紧密的联系。
2D视觉和3D视觉在技术实现上也有所不同。例如,2D转3D技术的研究表明,通过特定的技术手段可以将普通的2D图像/视频内容转化为3D内容【17】。这种技术的发展不仅缓解了3D片源不足的问题,也为经典的影视作品提供了以3D形式重新呈现的可能性。此外,基于2D信息的3D物体检测研究进一步证明了2D视觉数据对于理解和处理3D空间信息的重要性【18】。
然而,2D视觉和3D视觉之间的关系并非总是线性的或直接的。例如,研究表明,2D合成图像的存在可以显著改善在3D搜索中的信号检测率和定位精度【5】。这说明,在某些情况下,2D视觉信息可以有效地辅助3D视觉任务的完成。
此外,2D视觉和3D视觉在实际应用中的融合也是一个重要的研究方向。例如,融合2D与3D图像的三维重建系统实现了高精度的三维重建,同时满足了实时性的要求【11】。这种融合方法不仅提高了三维重建的精度,也为汽车自动驾驶、人机交互、虚拟现实等领域提供了重要的技术支持。
总之,2D视觉和3D视觉之间存在着复杂而深刻的关系。它们在人类的视觉系统中各司其职,但在技术实现和实际应用中又紧密相连。通过对这两种视觉模式的深入研究,我们可以更好地理解人类视觉系统的复杂性,同时也为相关领域的技术发展提供了重要的理论基础和技术支持。
2D转3D技术的最新进展是什么?
2D转3D技术的最新进展主要集中在提高转换效率、精度以及用户体验方面。从搜索到的资料中,我们可以看到几个关键的技术进步和研究方向:
-
深度估计和视觉舒适度改善:深度估计是2D转3D技术中的关键技术之一,通过深度估计得到的深度图的精确与否直接影响合成的3D影像的好坏。此外,视觉舒适度改善也是2D转3D的关键技术,它能使人们观看立体影像时降低视觉疲劳【32】。这表明了对深度信息提取和处理技术的不断优化,以及对用户体验的重视。
-
基于机器学习算法(MLAs)的深度图生成:传统的手动转换技术耗时且成本高昂。近年来,基于机器学习算法的深度图生成技术得到了发展,这种方法可以实时生成立体或多组立体图像,同时保持2D兼容性,并且具有较高的压缩率【31】。这一进步显著提高了2D转3D转换的效率和质量。
-
自然场景统计模型的应用:利用自然场景统计模型(NSSs)来开发3D内容创建算法,这些算法能够将单目2D视频转换为统计上自然的3D视频。这种方法首先通过人工标注获取关键帧的准确深度信息,然后估计前后运动矢量并比较以确定初始深度值,最后通过最小化目标函数来优化与输入2D视频帧相关的最终深度图【36】。这种方法在生成3D视频的质量评估中表现出了优越性。
-
数字立体影像的新技术应用:基于Roto-Tracking及图像边缘处理等技术的数字立体影像2D转制3D新技术方式逐渐进入到数字立体影像的工作流程中。这种技术在处理画面细节较为复杂部分的深度信息时显示出高效率和较好的精度保障【35】。这表明了在2D转3D技术中引入新的技术和方法,以提高转换过程中的细节处理能力和整体质量。
-
自动2D-to-3D视频系统的发展:自动2D-to-3D视频系统的研究表明,这种系统可以快速且低成本地将二维图像转换成双目立体图像,具有很好的发展前景【39】。这种系统的开发进一步降低了3D内容制作的门槛,使得更多的用户能够享受到3D视觉体验。
2D转3D技术的最新进展主要体现在深度估计和视觉舒适度改善、基于机器学习算法的深度图生成、自然场景统计模型的应用、数字立体影像的新技术应用以及自动2D-to-3D视频系统的发展等方面。这些进展不仅提高了转换的效率和质量,也极大地丰富了用户的3D观看体验。
如何通过2D视觉数据提高3D物体检测的准确性?
通过2D视觉数据提高3D物体检测的准确性是一个复杂但可行的任务,涉及到多个方面的技术和方法。我们可以总结出几种主要的方法和策略。
深度残差网络(Deep Residual Learning)为图像识别任务带来了显著的性能提升,尤其是在处理非常深的网络时【41】。这种技术通过学习残差函数而不是直接学习函数本身来简化训练过程,从而使得网络能够达到更深的层次而不损失性能。在COCO对象检测数据集上,仅由于深度表示的极大增加,就获得了28%的相对改进【41】。这表明,将深度残差学习应用于3D物体检测可能有助于提高准确性。
数据增强是提高CNN基于图像识别任务性能的关键组成部分【42】。尽管对于3D对象检测的数据增强相对较少探索,但通过对2D数据进行增强并适应3D几何形状的变化,可以在不需要新视图合成的情况下提高3D检测的准确性【42】。例如,在KITTI汽车检测数据集上,通过应用两种新颖的数据增强方法,可以实现对汽车类别在3D平均精度(AP)@IoU=0.7上约4%的持续改进【42】。
第三,利用大量的2D(伪)标签进行混合训练框架的学习,即使没有3D注释也能有效学习视觉3D对象检测器【45】。通过探索时间上的2D监督,即通过时间上的2D变换桥接3D预测与时间上的2D标签,可以突破2D线索的信息瓶颈【45】。这种方法在nuScenes数据集上的实验显示了强大的结果,几乎达到了其完全监督性能的90%,而只需25%的3D注释【45】。
此外,通过利用3D CAD模型数据库来改进检测性能的方法也值得关注【46】。这种方法通过从3D模型的渲染视图中提取特征并去相关空间依赖性来合成区分性模板,从而快速为3D模型的任意连续检测视点产生检测器【46】。这种方法的优点在于它能够在不进行昂贵的数据集依赖训练或模板存储的情况下,快速生成适用于任意视点的检测器【46】。
通过深度残差学习、数据增强、混合训练框架以及利用3D CAD模型数据库等方法,可以有效地通过2D视觉数据提高3D物体检测的准确性。这些方法各有侧重,但共同目标是通过利用2D数据的优势来弥补3D数据获取和处理的限制,从而提高3D物体检测的性能。
2D合成图像在3D搜索中的应用有哪些具体案例?
2D合成图像在3D搜索中的应用主要体现在以下几个具体案例:
-
医学成像:在医学领域,尤其是在数字乳腺断层合成(Digital Breast Tomosynthesis)中,3D体积数据通常与从相应的3D体积生成的合成2D图像(2D-S)配对使用。这种图像配对方式能够指导观察者的眼动到可疑位置,从而改善观察者在3D空间中找到小信号的能力。研究表明,2D-S作为3D数据的补充,能够有效减少搜索错误,提高定位和检测小信号的准确性【51】。
-
3D对象检索:在艺术、考古和地理定位等多个实际应用中,2D照片或草图可以通过一个完整的“2D摄影到3D对象”的检索框架转换为数据库中的相似3D模型。这种方法不仅丰富了2D图像数据集的视图,还克服了遮挡问题,提高了检索效率和准确性【53】。
-
自动驾驶车辆中的3D对象检测:DETR3D框架通过从多摄像头图像中提取2D特征,并使用稀疏的3D对象查询索引这些2D特征,实现了从多视角图像到3D空间的直接操作。这种方法避免了深度预测模型引入的复合误差,提高了检测速度和准确性,适用于自动驾驶等应用场景【54】。
-
基于2D场景图像的3D场景检索:这一研究领域允许用户通过2D场景图像来搜索相关3D场景,支持自动3D内容生成、机器人视觉、消费电子产品应用开发等领域。通过构建基准测试和评估指标,该领域的研究有助于推动2D场景图像基础的3D场景检索技术的发展【56】。
-
基于形状分布的3D模型检索:通过计算任意(可能退化)3D多边形模型的形状分布,将形状匹配问题简化为概率分布的比较。这种方法能够在存在任意平移、旋转、缩放、镜像、镶嵌、简化和模型退化的情况下,有效地区分不同类别的对象,如汽车与飞机之间的区分。这表明2D合成图像可以作为预分类器,在完整的基于形状的检索或分析系统中发挥作用【58】。
这些案例展示了2D合成图像在3D搜索中的多样化应用,从医学成像到自动驾驶,再到艺术和考古领域的3D对象检索,2D合成图像都发挥着至关重要的作用。
融合2D与3D图像的三维重建系统是如何实现高精度和实时性的?
融合2D与3D图像的三维重建系统实现高精度和实时性的关键在于采用先进的技术和方法,以及对现有技术的有效整合。以下是基于搜索到的资料,对如何实现这一目标的详细分析。
-
采用先进的3D成像和形状测量技术:一种方法是使用基于条纹投影轮廓术的系统,该系统通过组合相移条纹图案、外部触发的系统组件同步、通用系统设置、超快相位解包裹算法、灵活的系统校准方法、稳健的伽马校正方案、多线程计算处理和基于图形处理单元的图像显示等高级方法来解决快速速度和高精度性能之间的平衡问题【61】。
-
动态对象的高质量重建:通过使用2D-3D相机设置并结合运动轨迹的分割,计算精确的运动参数,并将多个稀疏点云进行配准以增加密度,从而开发出平滑且具有纹理的表面,这依赖于在两个稀疏点云之间进行准确运动估计的优化框架【62】。
-
高分辨率网格基实时三维重建:通过多尺度内存管理和细节层次(LOD)方案,实现在尽可能高的几何保真度下创建和维护表面重建,同时保持全传感器分辨率的颜色化或表面纹理,这对于小尺度(如物体)和大尺度(如房间或建筑)的详细重建都是可行的【63】。
-
结合点基和体素融合的实时3D重建:通过使用深度和RGB信息增强相机跟踪的稳定性,并应用GPU基于区域生长的方法来准确分割前景移动对象,同时设计点基和体素表示的组合以分别重建移动对象和静态场景,从而提高实时3D重建的性能【65】。
-
利用深度相机进行密集点三维重建:在复杂场景下,通过捕获彩色-深度图像序列并使用这些序列中的密集像素信息进行对齐来获得相机位姿,进而将像素融合到三维模型中形成对场景的三维重建。此外,通过加入惯性传感器改进三维重建的相机定位,并使用随机蕨编码的图像信息进行重定位检测,以应对相机追踪失败的情况【68】。
-
融合纹理的三维图像重建:通过对不同视角的深度图像进行手动粗配准、ICP算法精配准以及全局配准,得到这些深度图像的旋转平移矩阵,然后使用vrippack进行三维重建,并用TextureStitcher进行纹理映射,从而实现融合纹理的三维图像的快速重建【69】。
-
结构光基础的高度密集和鲁棒的3D重建:通过结合灰码和区域偏移图案,将区域偏移图案转换为梯形和三角波偏移图案,并估计梯形波偏移图案的边界以及三角波偏移图案的峰值和相位,从而提高了空间分辨率约三倍,使得3D点的重建分辨率远高于相机图像分辨率【70】。
通过综合运用上述技术和方法,融合2D与3D图像的三维重建系统能够实现高精度和实时性的目标。这些方法的有效整合不仅提高了重建的质量和速度,而且增强了系统的鲁棒性和适用性。
在汽车自动驾驶、人机交互、虚拟现实等领域,2D视觉和3D视觉融合技术的应用情况如何?
在汽车自动驾驶、人机交互、虚拟现实等领域,2D视觉和3D视觉融合技术的应用情况表现为多方面的进展和挑战。从搜索到的资料中,我们可以看到这一领域的技术和方法正在不断发展和完善。
在自动驾驶领域,3D视觉技术通过点云数据的处理和分析,为自动驾驶车辆提供了精确的环境感知能力。VoxelNet的研究展示了如何通过将点云数据转换为统一的特征表示,来实现端到端的3D对象检测【71】。此外,nuScenes数据集的推出,为基于摄像头和雷达等传感器的数据融合提供了丰富的资源,这对于训练和评估自动驾驶系统的3D检测和跟踪能力至关重要【72】。这些进展表明,3D视觉技术在自动驾驶领域的应用正在不断深化。
同时,新的3D视觉方法探索了不依赖于完整或无模型的世界3D模型的可能性,这为人工智能、自动驾驶车辆以及虚拟现实和增强现实中的人类感知提供了新的视角【73】。这些新方法挑战了传统的3D视觉假设,为相关领域的发展开辟了新的道路。
在人机交互方面,3D视觉系统能够提供车辆周围场景的3D表示,从而帮助驾驶员更好地理解驾驶或停车情况【75】。这种技术的应用不仅限于自动驾驶,还扩展到了提高车辆导航系统的路径引导效率80。
在虚拟现实领域,3D视觉技术的应用同样显示出其重要性。例如,通过结合雷达和图像信息,可以有效地实现车辆的定位与识别【78】。此外,CRUW3D数据集的引入,展示了如何通过融合摄像头和雷达信息来提高3D对象感知的准确性和鲁棒性【79】。
然而,尽管取得了显著进展,但在3D视觉融合技术的应用中仍存在一些挑战。例如,3D对象检测面临的挑战包括不同物体尺度的变化、有限的3D传感器数据以及遮挡问题【74】。此外,为了确保自动驾驶车辆的可靠运行,需要装备多种传感器以增强感知系统的性能【74】。
2D视觉和3D视觉融合技术在汽车自动驾驶、人机交互、虚拟现实等领域已经取得了显著的进展。这些技术的发展不仅推动了相关领域的技术创新,也为解决实际应用中的挑战提供了新的思路和方法。未来的研究将继续探索更高效的数据融合技术和算法,以进一步提高这些系统的性能和可靠性。
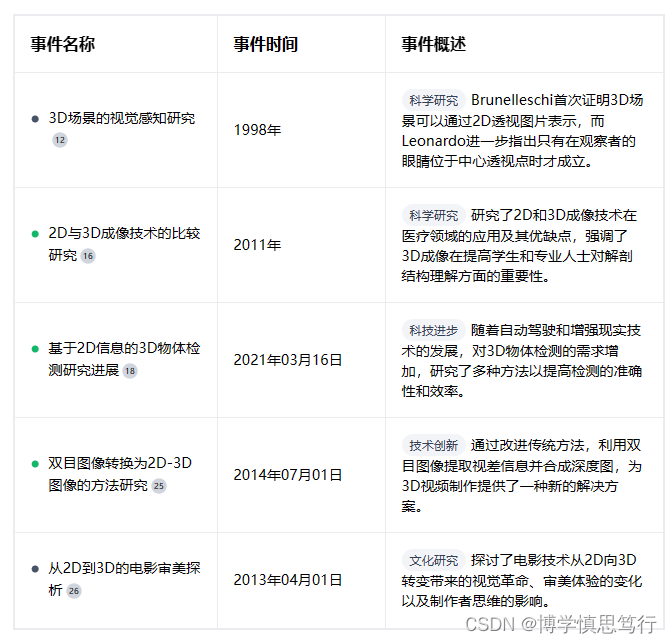
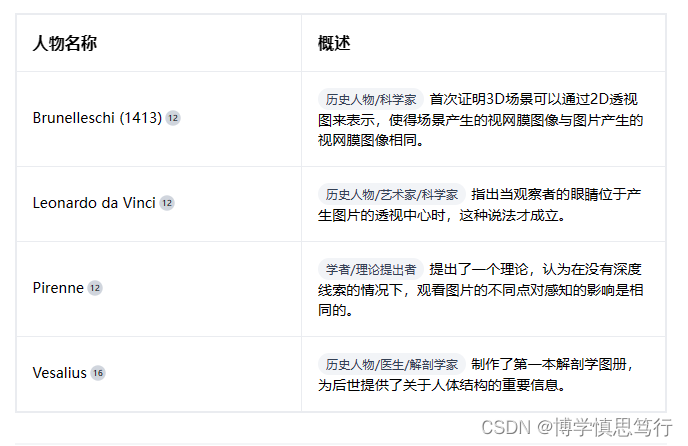
三、相关事件及人物
四、参考文献
1. Jia-Shun Hong, R. Hnatyshyn et al. “A Survey of Designs for Combined 2D+3D Visual Representations.” arXiv.org (2024).
2. N. Finlayson, Xiaoli Zhang et al. “The representation and perception of 3D space: Interactions between 2D location and depth.” (2015). 832 - 836.
3. 余淮. 2D-2D/3D视觉特征匹配及其应用研究[D].武汉大学,2020.
4. R. Fleming and Manish Singh. “Visual perception of 3D shape.” International Conference on Computer Graphics and Interactive Techniques (2009).
5. Devi S. Klein, M. Lago et al. “The perceptual influence of 2D synthesized images on 3D search.” Medical Imaging (2021).
6. Melanie Tory, M. S. Atkins et al. “Eyegaze analysis of displays with combined 2D and 3D views.” VIS 05. IEEE Visualization, 2005. (2005). 519-526.
7. M. Flinders. “2D vision in a 3D system.” SPIE Optics East (2001).
8. L. Krauze, Māra Delesa-Vēliņa et al. “Why 2D layout in 3D images matters: evidence from visual search and eyetracking.” Journal of Eye Movement Research (2023).
9. Zonglin Tian, Xiaorui Zhai et al. “Quantitative and Qualitative Comparison of 2D and 3D Projection Techniques for High-Dimensional Data.” Inf. (2021). 239.
10. 郭瑶. 基于2D图像的3D化研究与应用[D].东华大学,2013.
11. 贾保柱. 融合2D与3D图像的三维重建系统实现[D].合肥工业大学,2012.
12. Z. Pizlo and M. R. Scheessele. “Perception of 3D scenes from pictures.” Electronic imaging (1998).
13. 余洪山,赵科,王耀南等.融合2D/3D摄像机的方法与获取高精度三维视觉信息的装置[J].控制理论与应用,2014,31(10):1383-1392.
14. 袁红星,吴少群,朱仁祥等.融合对象性和视觉显著度的单目图像2D转3D[J].中国图象图形学报,2013,18(11):1478-1485.
15. Zicong Mai, M. Pourazad et al. “Contrast effect on 3D and 2D video perception.” 2011 Third International Workshop on Quality of Multimedia Experience (2011). 173-176.
16. L. Ballantyne. “Comparing 2D and 3D Imaging.” Journal of Visual Communication in Medicine (2011). 138 - 141.
17. 张翠翠. 2D转3D关键技术研究[D].天津大学,2016.
18. 基于2D信息的3D物体检测研究 [2021-03-16]
19. N. N. Krasil'nikov and O. I. Krasil’nikova. “Study of the perception of 3D objects by the human visual system in order to develop methods for converting 2D images into stereoscopic images.” (2015). 649-654.
20. I. Heynderickx and R. Kaptein. “Perception of detail in 3D images.” Electronic imaging (2009).
21. Sarah Ting, T. Tan et al. “Quantitative assessment of 2D versus 3D visualisation modalities.” Visual Communications and Image Processing (2011). 1-4.
22. V. Čok, D. Vlah et al. “An Investigation into 2D and 3D Shapes Perception.” (2020). 37-45.
23. Mingzhe Ruan. “The Survey of Vision-based 3D Modeling Techniques.” (2017).
24. 张地. 3D显示视觉感知特性研究[D].北京邮电大学,2017.
25. 基于双目图像的2D-3D图像转换方法研究 [2014-07-01]
26. 付茜茜. 从2D到3D:视觉文化时代电影之审美探析[D].上海师范大学,2013.
27. 杨帆,王媛媛,蔡建奇等.观看2D/3D电视对人眼视觉质量的影响[J].中华眼视光学与视觉科学杂志,2016,18(09):525-528.
28. 钮圣虓. 平面3D游戏、2D视频转立体3D技术研究[D].复旦大学,2011.
29. 欧阳习彪. 2D到3D视频转换技术研究[D].重庆大学,2015.
30. M. John, M. Cowen et al. “The Use of 2D and 3D Displays for Shape-Understanding versus Relative-Position Tasks.” Hum. Factors (2001). 79 - 98.
31. P. Harman, J. Flack et al. “Rapid 2D-to-3D conversion.” IS&T/SPIE Electronic Imaging (2002).
32. 谭迎春. 基于DIBR的2D转3D关键技术研究[D].重庆大学,2014.
33. Li Sisi, Wang Fei et al. “The overview of 2D to 3D conversion system.” 2010 IEEE 11th International Conference on Computer-Aided Industrial Design & Conceptual Design 1 (2010). 1388-1392.
34. Shweta R. Patil and Priya Charles. “Review on 2D-to-3D Image and Video Conversion Methods.” International Conference on Computing Communication Control and automation (2015). 728-732.
35. 金晟,周令非.数字立体影像2D转制3D新技术应用研究[J].现代电影技术,2015,No.449(12):19-27+56.
36. Weicheng Huang, Xun Cao et al. “Toward Naturalistic 2D-to-3D Conversion.” IEEE Transactions on Image Processing (2015). 724-733.
37. 胡泉. 2D转3D视频的关键技术及系统设计[D].北京邮电大学,2013.
38. 李明星. 基于深度提取的2D转3D的实现[D].南京理工大学,2014.
39. 杨宇,李鉴增.自动2D-to-3D视频转换技术研究[J].中国传媒大学学报(自然科学版),2012,19(02):16-21.
40. 鲁天安. 基于插值的2D转3D关键技术研究[D].中国海洋大学,2012.
41. Kaiming He, X. Zhang et al. “Deep Residual Learning for Image Recognition.” Computer Vision and Pattern Recognition(2015).
42. K. Santhakumar, B. R. Kiran et al. “Exploring 2D Data Augmentation for 3D Monocular Object Detection.” arXiv.org (2021).
43. Xiaoke Shen. “A survey of Object Classification and Detection based on 2D/3D data.” arXiv.org (2019).
44. A. Krizhevsky, I. Sutskever et al. “ImageNet classification with deep convolutional neural networks.” Communications of the ACM(2012).
45. Jinrong Yang, Tiancai Wang et al. “Towards 3D Object Detection with 2D Supervision.” arXiv.org (2022).
46. C. Choy, Michael Stark et al. “Enriching object detection with 2D-3D registration and continuous viewpoint estimation.” Computer Vision and Pattern Recognition (2015). 2512-2520.
47. D. Rother and G. Sapiro. “Seeing 3D objects in a single 2D image.” IEEE International Conference on Computer Vision (2009). 1819-1826.
48. Shaoqing Ren, Kaiming He et al. “Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks.” IEEE Transactions on Pattern Analysis and Machine Intelligence(2015).
49. W. Grimson, D. Huttenlocher et al. “Recognizing 3D objects from 2D images: an error analysis.” Proceedings 1992 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (1992). 316-321.
50. Jia Deng, Wei Dong et al. “ImageNet: A large-scale hierarchical image database.” 2009 IEEE Conference on Computer Vision and Pattern Recognition(2009).
51. Devi S. Klein, M. Lago et al. “A 2D Synthesized Image Improves the 3D Search for Foveated Visual Systems.” IEEE Transactions on Medical Imaging (2023). 2176-2188.
52. J. Canny. “A Computational Approach to Edge Detection.” IEEE Transactions on Pattern Analysis and Machine Intelligence(1986).
53. T. Napoléon and H. Sahbi. “From 2D Silhouettes to 3D Object Retrieval: Contributions and Benchmarking.” EURASIP Journal on Image and Video Processing (2010). 1-17.
54. Yue Wang, V. Guizilini et al. “DETR3D: 3D Object Detection from Multi-view Images via 3D-to-2D Queries.” Conference on Robot Learning (2021).
55. Hang Su, Subhransu Maji et al. “Multi-view Convolutional Neural Networks for 3D Shape Recognition.” IEEE International Conference on Computer Vision(2015).
56. H. Abdul-Rashid, Juefei Yuan et al. “2D Image-Based 3D Scene Retrieval.” 3DOR@Eurographics (2018).
57. T. Funkhouser, P. Min et al. “A search engine for 3D models.” TOGS(2003).
58. R. Osada, T. Funkhouser et al. “Shape distributions.” TOGS(2002).
59. Ding-Yun Chen, Xiao-Pei Tian et al. “On Visual Similarity Based 3D Model Retrieval.” Computer graphics forum (Print)(2003).
60. Philip Shilane, P. Min et al. “The Princeton Shape Benchmark.” Proceedings Shape Modeling Applications, 2004.(2004).
61. Hieu Nguyen, Dung A. Nguyen et al. “Real-time, high-accuracy 3D imaging and shape measurement..” Applied Optics (2015). A9-17 .
62. Cansen Jiang, Dennis Christie et al. “High quality reconstruction of dynamic objects using 2D-3D camera fusion.” International Conference on Information Photonics (2017). 2209-2213.
63. Simon Schreiberhuber, J. Prankl et al. “ScalableFusion: High-resolution Mesh-based Real-time 3D Reconstruction.” IEEE International Conference on Robotics and Automation (2019). 140-146.
64. Yangming Li. “3 Dimensional Dense Reconstruction: A Review of Algorithms and Dataset.” arXiv.org (2023).
65. Zhengyu Xia, Joohee Kim et al. “Real-time 3D Reconstruction Using a Combination of Point-Based and Volumetric Fusion.” IEEE/RJS International Conference on Intelligent RObots and Systems (2018). 8449-8455.
66. Andreas Geiger, Julius Ziegler et al. “StereoScan: Dense 3d reconstruction in real-time.” 2011 IEEE Intelligent Vehicles Symposium (IV) (2011). 963-968.
67. Jong Wan Silva, L. Gomes et al. “Real-time acquisition and super-resolution techniques on 3D reconstruction.” 2013 IEEE International Conference on Image Processing (2013). 2135-2139.
68. 黄伟杰. 复杂场景下基于深度相机的密集点三维重建[D].天津大学,2018.
69. 李水平,吴雨.一种融合纹理的三维图像重建快速实现方法[J].计算机技术与发展,2014,24(05):138-141.
70. DaeSik Kim and Sukhan Lee. “Structured-light-based highly dense and robust 3D reconstruction..” Journal of The Optical Society of America A-optics Image Science and Vision (2013). 403-17 .
71. Yin Zhou, Oncel Tuzel. “VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection.” 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition(2017).
72. Holger Caesar, Varun Bankiti et al. “nuScenes: A Multimodal Dataset for Autonomous Driving.” Computer Vision and Pattern Recognition(2019).
73. P. Linton, M. Morgan et al. “New Approaches to 3D Vision.” Philosophical Transactions of the Royal Society of London. Biological Sciences (2022).
74. S. Y. Alaba, Ali C. Gurbuz et al. “Emerging Trends in Autonomous Vehicle Perception: Multimodal Fusion for 3D Object Detection.” World Electric Vehicle Journal (2024).
75. K. Fintzel, R. Bendahan et al. “3D vision system for vehicles.” IEEE IV2003 Intelligent Vehicles Symposium. Proceedings (Cat. No.03TH8683) (2003). 174-179.
76. Alexandru-Raul Boglut and C. Căleanu. “A Brief Overview on 3D Perception using Deep Neural Networks for Automotive.” International Symposium on Electronics and Telecommunications (2022). 1-5.
77. Christoph Stiller and Julius Ziegler. “3D perception and planning for self-driving and cooperative automobiles.” International Multi-Conference on Systems, Sygnals & Devices (2012). 1-7.
78. 陈莹,韩崇昭.基于雷达和图像融合的3D车辆定位与识别[J].电子学报,2005(06):1105-1108.
79. Yizhou Wang, Jen-Hao Cheng et al. “Vision meets mmWave Radar: 3D Object Perception Benchmark for Autonomous Driving.” arXiv.org (2023).
80. 谷正气,容哲,杨易等.三维虚拟场景在车辆导航系统中的应用[J].计算机仿真,2007(05):245-248.
————其它————
对比区分3D机器视觉和2D机器视觉,以最优解决方案赋能“智”造 - 掘金 (juejin.cn)
机器视觉2D和3D技术 (qq.com)
2D相机和3D相机,到底怎么划分? - 知乎 (zhihu.com)
全面解读|一文了解3D视觉和2D视觉的区别_视觉识别 3d 2d id-CSDN博客
end







 本文探讨2D视觉和3D视觉的关系、技术进展及应用。介绍了2D转3D技术的最新进展,如深度估计和机器学习算法的应用;阐述了通过2D视觉数据提高3D物体检测准确性的方法;列举了2D合成图像在3D搜索中的应用案例;还说明了三维重建系统实现高精度和实时性的方式,以及该融合技术在自动驾驶等领域的应用情况。
本文探讨2D视觉和3D视觉的关系、技术进展及应用。介绍了2D转3D技术的最新进展,如深度估计和机器学习算法的应用;阐述了通过2D视觉数据提高3D物体检测准确性的方法;列举了2D合成图像在3D搜索中的应用案例;还说明了三维重建系统实现高精度和实时性的方式,以及该融合技术在自动驾驶等领域的应用情况。

















 407
407

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









