






主流的芯片制造公司一直在尝试将不同种类的硅元件堆叠在一起。现在,三星显然准备推出一个重大的进步,将逻辑芯片与高带宽RAM集成在一起。

通过将高带宽内存(HBM)直接堆叠在CPU和GPU之上,以提高计算性能。这一策略旨在进一步提升芯片的运算能力和效率,满足人工智能和高性能计算(HPC)领域的需求。通过这种集成方式,数据传输速率将显著提高,延迟减少,有助于大幅提升系统整体性能。
三星在2024年的三星代工论坛上介绍了其最新和最先进的芯片封装技术和服务路线图。根据《韩国经济日报》引用的未具名行业消息人士以及三星自己的声明,这项新技术将在2025年推出的第四代高带宽内存中首次亮相。
三星的新堆叠解决方案代表了芯片设计的重大进步。这是全球最大的内存制造商正式推出的第一项3D封装技术,也是少数几家拥有生产此类先进芯片所需专业知识和工具的公司之一。当前的堆叠技术基于“2.5D”设计,其中HBM存储芯片通过硅中介层水平连接到底层逻辑芯片(主要是GPU)。
三星开发的3D封装技术似乎消除了对中介层的需求,实现了存储芯片和逻辑硅元件之间的“真正”垂直堆叠。然而,创建3D封装设计需要一个新的HBM存储器基础芯片,这将引入一个更加复杂的工艺技术。
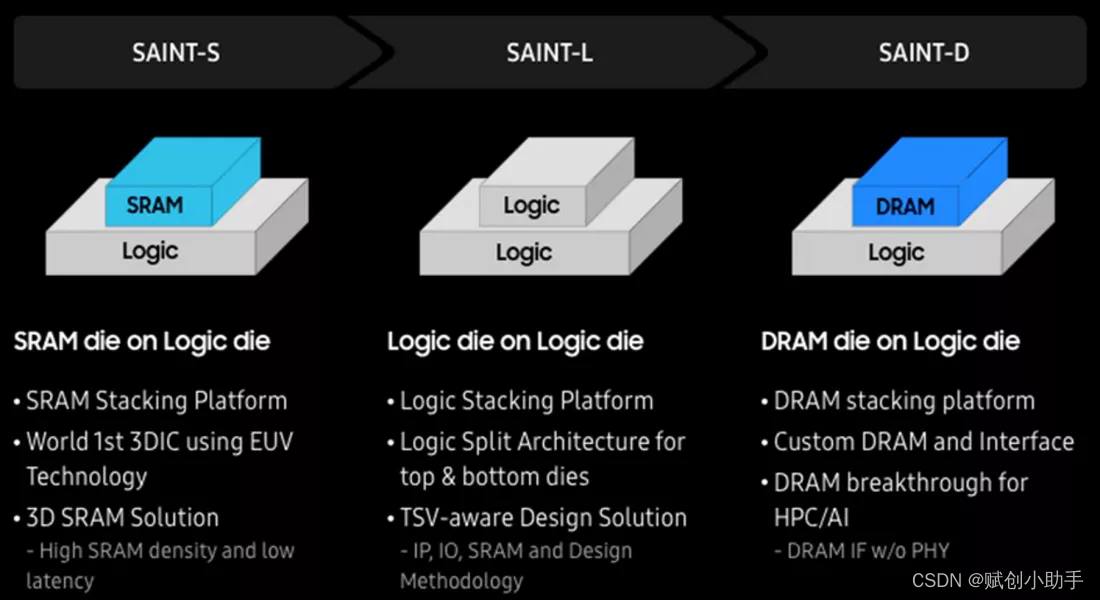
三星的3D封装解决方案基于一个名为SAINT的平台,即三星先进的互连技术。这项技术已经开发多年,包括针对不同类型的硅的不同方法。SAINT-S解决方案用于逻辑芯片上的SRAM芯片堆叠,SAINT-L用于逻辑芯片上的逻辑芯片堆叠,SAINT-D用于逻辑芯片上的DRAM芯片堆叠。
得益于3D封装,未来的GPU将提供更快的数据传输速率、更清晰的电信号、更低的功耗和更低的延迟水平。然而,3D封装解决方案的成本也会更高,三星显然有兴趣将其作为“交钥匙”服务提供给感兴趣的客户,以销售更多的HBM芯片。
预计将在今年完成SAINT-D工艺,HBM 4存储器技术将于明年推出。据《韩国日报》报道,开发人工智能加速器的公司,尤其是英伟达,是三星这项新技术的主要业务目标。然而,SAINT-D将需要重新设计芯片,目前还没有已知的公司正在进行这项工作。
通过上述创新,三星展示了其在高性能计算领域的技术领导力。未来,这一技术有望在更多高性能计算和AI应用中得到广泛应用,推动整个行业的发展。
赋创小助手,持续为您提供最前沿的科技资讯,如果您对服务器市场有进一步的问题或需要更详细的信息,请随时私信我们。

















 429
429

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









