







1、qwen2.5 7B模型介绍
Qwen2.5-7B是通义千问团队发布的一个大型语言模型,它在18T tokens的数据集上进行了预训练,旨在提供更丰富的知识、更强的编程和数学能力。以下是关于Qwen2.5-7B的一些详细介绍:
模型概述
-
参数量:70亿(7B)参数。
-
数据集:基于18万亿tokens的数据进行预训练,这使得模型拥有更多的知识和改进的能力。
-
上下文长度:支持高达128K的上下文长度,这意味着它可以处理非常长的文本序列。
-
生成能力:可以生成最多8K的内容。
主要特点
-
多语言支持:支持超过29种语言,包括中文、英文、法文、西班牙文、俄文、日文等。
-
指令遵循能力:经过指令微调(Instruct-tuned),能够更好地理解和执行特定的指令。
-
编程与数学能力:特别是在编程和数学方面有了显著的提升,比如在HumanEval和MATH基准测试中得分较高。
-
结构化数据理解与输出:改进了对结构化数据的理解和生成能力,例如表格数据以及JSON格式的输出。
版本类型
-
基础版本(Base models):不建议直接用于对话任务,但可以作为进一步训练的基础。
-
指令微调版本(Instruction-tuned models):专门设计来理解并执行特定指令,适用于需要对话功能的应用场景。
-
量化版本:通过量化算法优化后的版本,降低了部署门槛,可以在资源受限的环境下运行。
部署方式
-
可以使用Hugging Face Transformers库进行本地推理,或者使用vLLM这样的高效推理框架进行服务部署。
-
支持多种硬件配置,包括CPU和GPU,且有针对不同硬件环境优化的实现方案。
应用场景
-
由于其强大的语言理解和生成能力,Qwen2.5-7B可以应用于聊天机器人、智能助手、代码生成、内容创作等多种领域。
之前我的一篇文章菜鸟妈妈:微软开源GraphRAG的安装+示例教程(最全超详细教程,小白上手)也详细讲解了如何安装Ollama,大家可以参考。
2、创建Qwen2.5 7B虚拟环境
创建一个新的虚拟环境(首先,需要确保你的系统已经安装好anaconda),我自己电脑的python版本是3.12.2,所以执行如下命令:
conda create -n Grid-ollama-local python=3.12.23、激活Qwen2.5 7B虚拟环境
激活名为的 Grid-ollama-local的Conda 环境,执行命令行如下:
conda activate Grid-ollama-local4、安装Qwen2.5 7B模型
4.1 本地部署
代码下载有两种方式,一种是从Ollama上下载和运行,一种是从Qwen的github官方地址下载后运行。我采用的第一种方式。
-
Ollama下载
Ollama的下载地址:qwen2.5-coder:7b,Qwen2.5 7B模型大小为4.7GB。
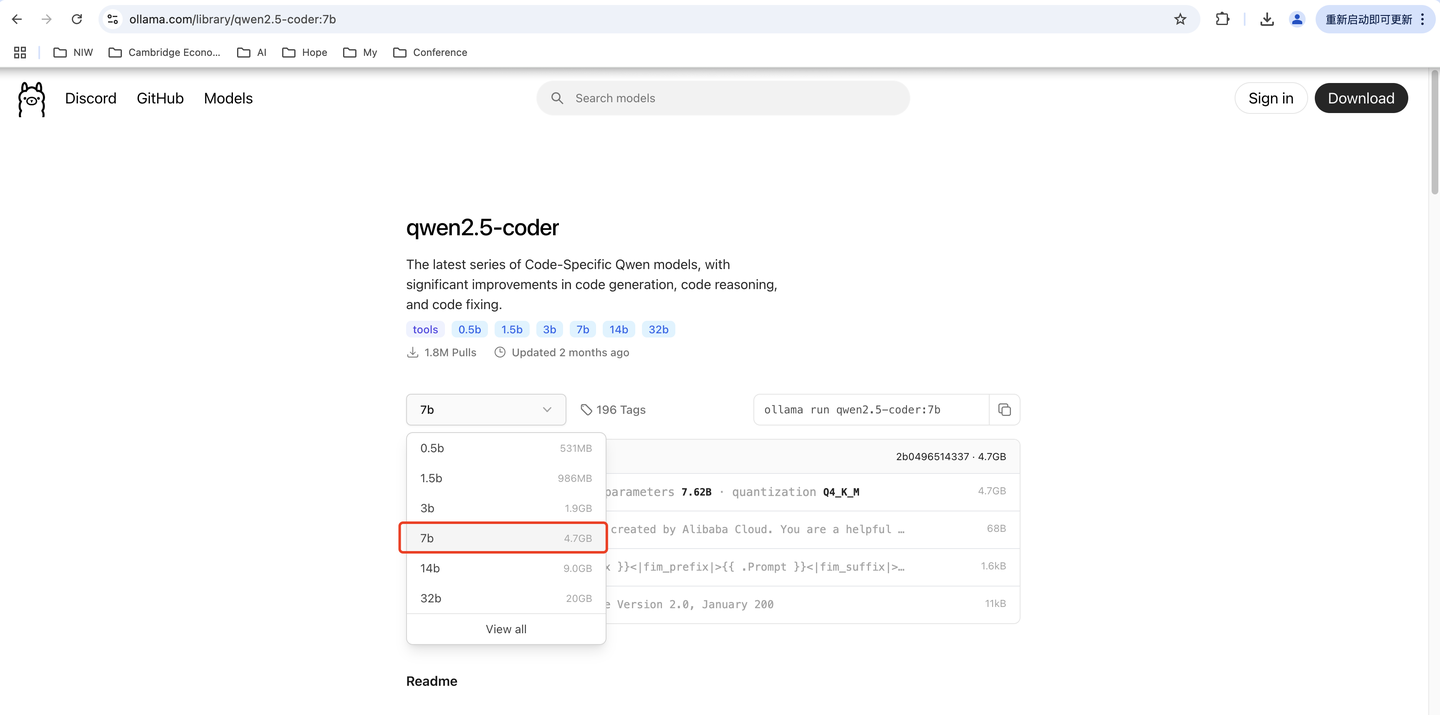
然后执行如下命令,拉取模型并执行,第一次运行的时候需要下载。
ollama run qwen2.5-coder:7b
下载并运行后,你就可以提问了,比如:我问的问题,请问阿里云的通义千问模型有哪些,Qwen2.5 7B模型回答如下

5、Open-webui实现可视化
官方github界面:https://github.com/open-webui/open-webui?tab=readme-ov-file
官方文档:🚀 Getting Started | Open WebUI
具体参考Quick Start的内容:⏱️ Quick Start | Open WebUI
conda create -n open-webui python=3.12.2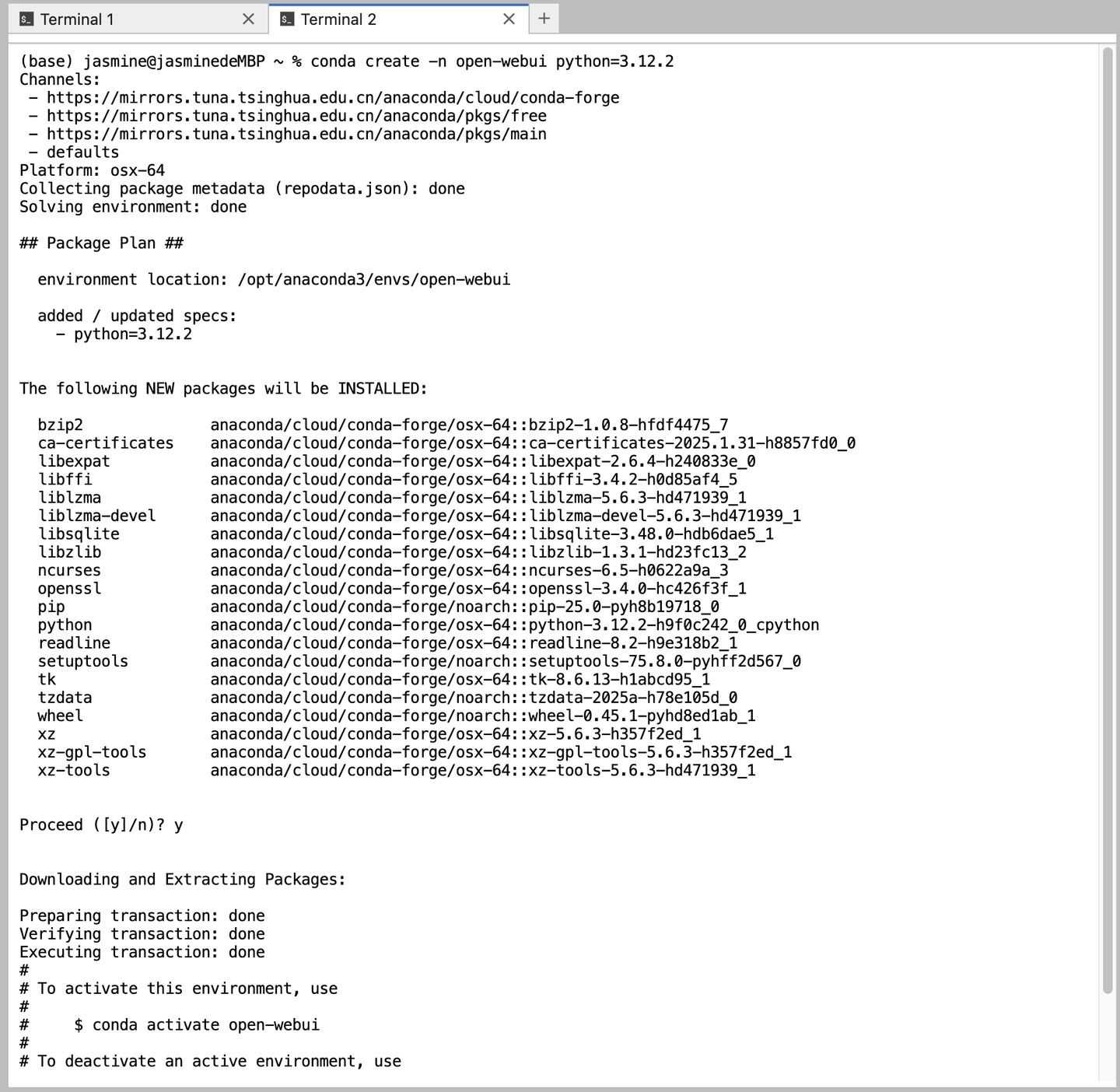
5.2 激活webui的虚拟环境

添加图片注释,不超过 140 字(可选)
5.3 安装open-webui库
执行如下命令:
pip install open-webui
5.4 启动open-webui服务
open-webui serve

添加图片注释,不超过 140 字(可选)
初次启动也需要花费一点时间,启动成功之后即可看到8080端口。
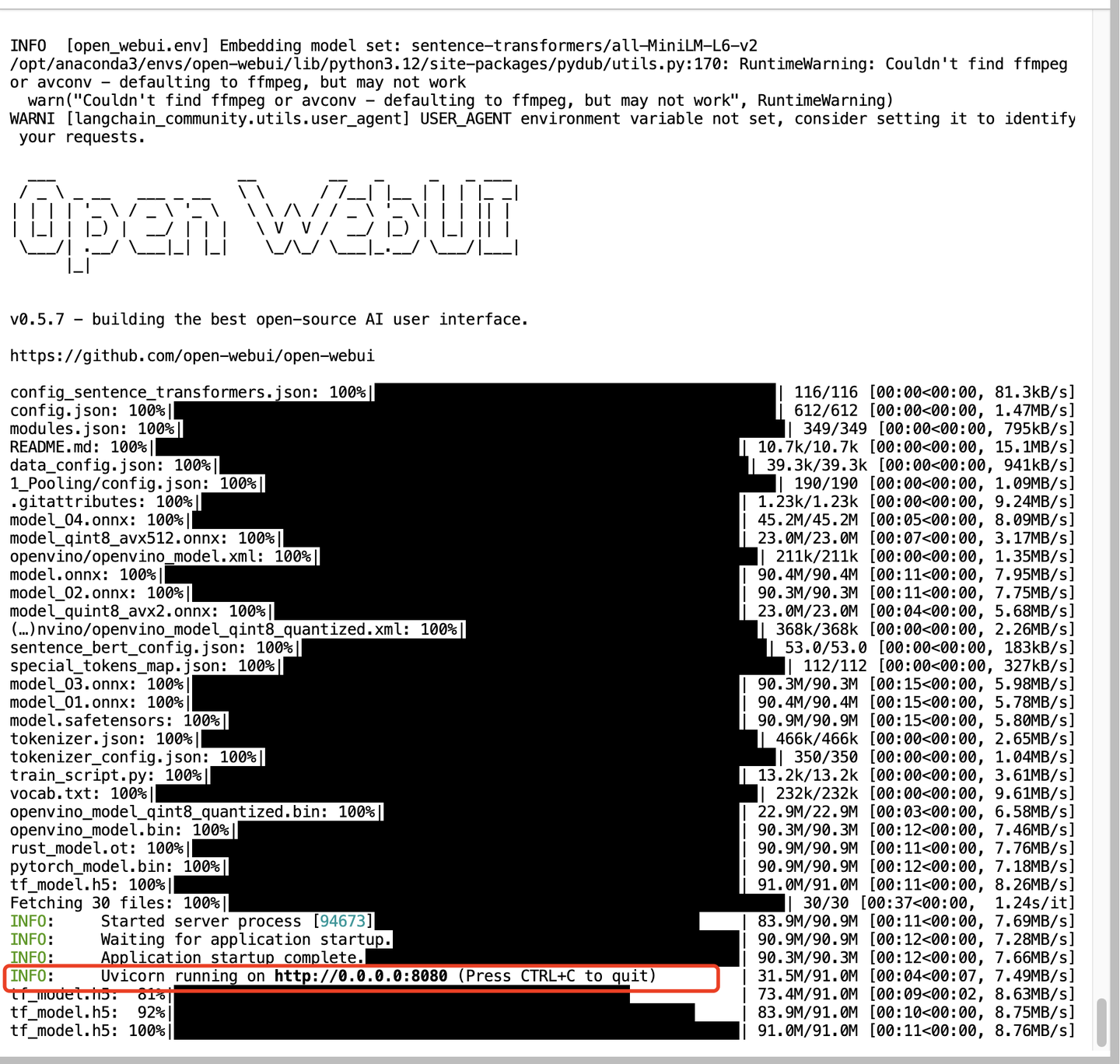
添加图片注释,不超过 140 字(可选)
6、访问webui界面
在浏览器里输入localhost:8080 即可正常访问。 第一次登录会要求输入用户名、邮箱和密码,之后每次登录都会要求输入邮箱和密码。

添加图片注释,不超过 140 字(可选)
因为我之前也安装了其他模型,所以大家可以看看不同模型的回答,qwen2.5 7B针对相同的问题,有不同的答复,第一个问题回答还是错误的,准确性还有待进一步提高和加强。
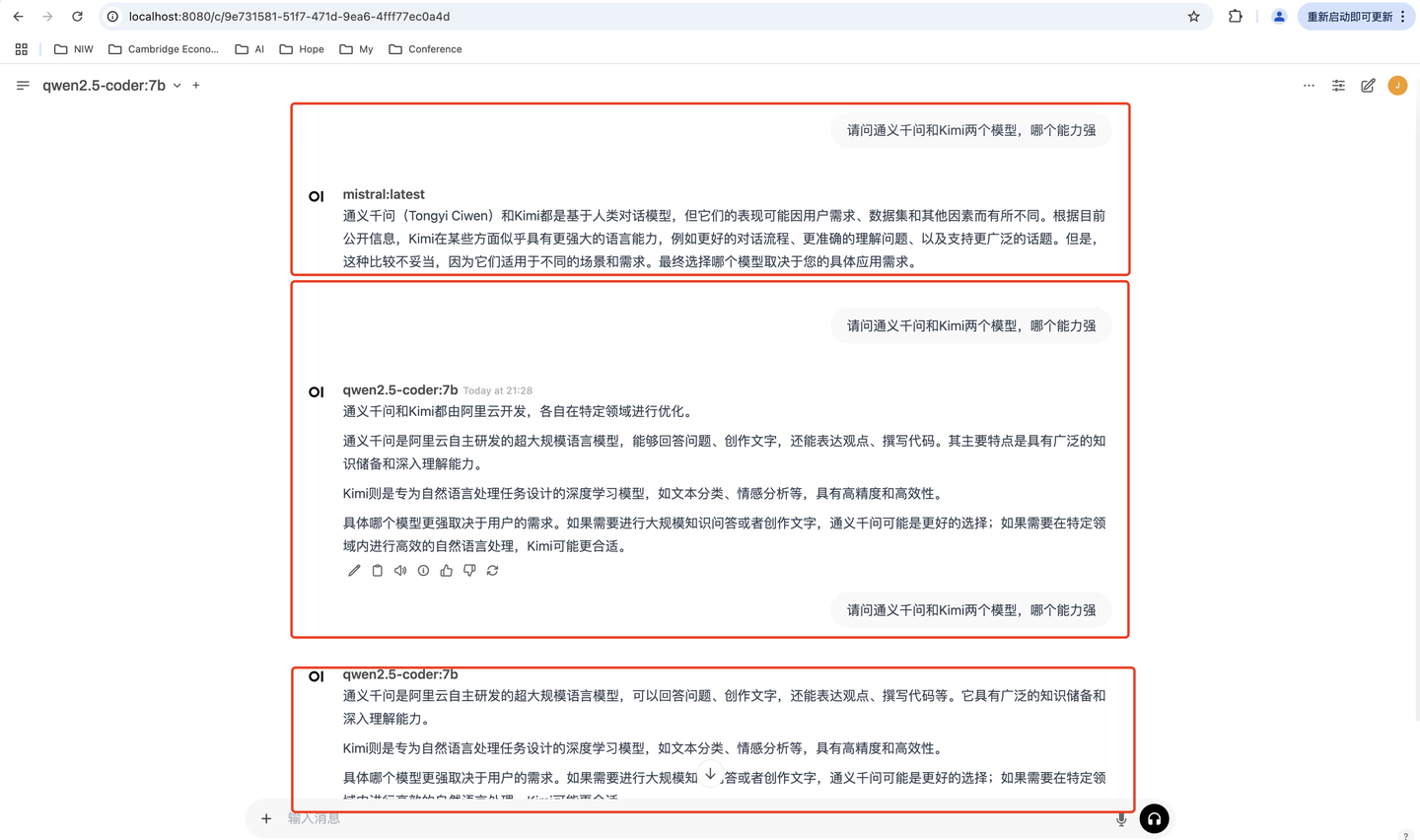
7、比较Qwen2.5 7B和mistral:latest模型





















 5124
5124

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









