






对于很多对基因进行记录的数据库而言,为了他们自己数据库记录的方便,对于每个基因都会进行自己数据库的唯一编号,这样就导致了一个基因形成了很多不同的编号(ID)。
EntrezID
是Entrez 基因数据库(属于NCBI子数据库)的编号系统,Entrez 基因数据库是一个整合了核酸、蛋白、基因组等生物信息的检索库。EntrezID格式为一串数字,是目前最权威的基因编号,GO分析和KEGG分析一般输入的基因名格式一般都是EntrezID。

SymbolID
Gene Symbol是用来表示基因的编码, 由大写字母构成, 或由大写字母和数字构成。如: GLA "galactosidase, alpha"; GLB "galactosidase, beta"。物种来源于人的,由HGNC(人类基因命名委员会)命名。
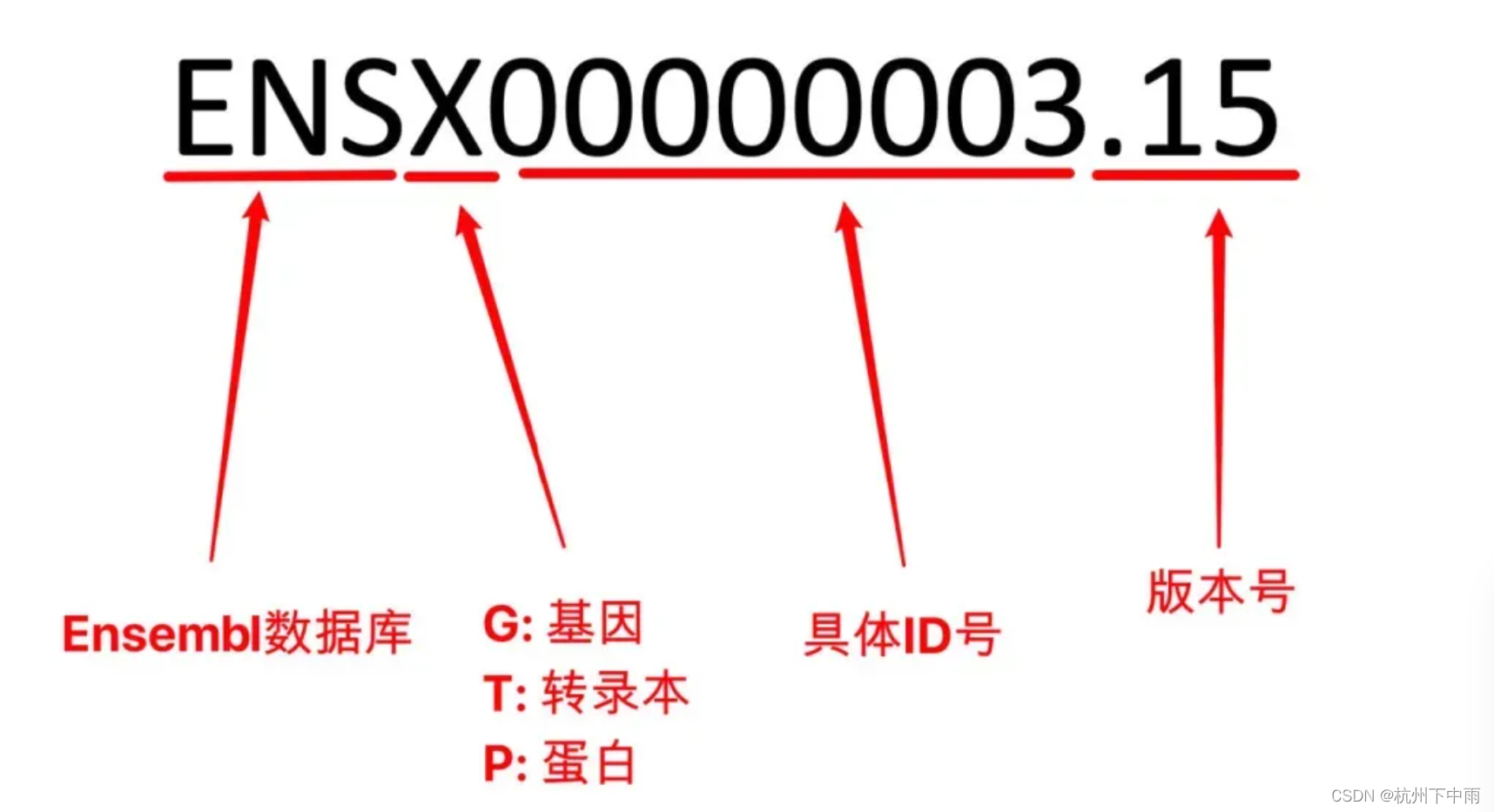
EnsemblID
EnsemblID的结构是根据不同物种设置的前缀, 加上数据所指的类型, 如基因蛋白质, 再加上一系列的数字. 有的时候可以有不同的版本, 则在 Ensembl ID 后面加上小数点和版本号。其命名规则包含五个部分,ENS前缀,提醒我们该命名来源于Ensembl ID,第二部分物种的前缀,第三部分Object type,G就是基因,P指蛋白,第四部分,identifier,是一段特定的数字,第五部分,版本号。
Uniprot ID
如果我们查找的是一个基因的蛋白的话,那么就有可能涉及到Uniprot这种专门注释蛋白的数据库。这种ID有时候会在蛋白组学当中看到。
R语言实现ID的转换(以simbolID转为EntrezID为例)
library(clusterProfiler)
library(org.Hs.eg.db)
geneID <- bitr(genes$genes, fromType = "SYMBOL",toType = c( "ENTREZID"),OrgDb = org.Hs.eg.db ,drop = T)














 5517
5517











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









