







1. 合并与分割
1.1 合并
合并是指将多个张量在某个维度上合并为一个张量。以某学校班级成绩册数据为例,设张量A保存了某学校1-4号班级的成绩册,每个班级35个学生,共8门科目,则张量A的shape为:[4,35,8];同样的方式,张量B保存了剩下的6个班级的成绩册,shape为[6,35,8]。通过合并2个成绩册,便可得到学校所有班级的成绩册张量C,shape应为[10,35,8]。这就是张量合并的意义所在。张量合并可以使用拼接(Concatenate)和堆叠(Stack)操作实现,拼接不会产生新的维度,而堆叠会创建新维度。
拼接 在TensorFlow中,可以通过tf.concat(tensors, axis),其中tensors保存了所有需要合并的张量List,axis指定需要合并的维度。
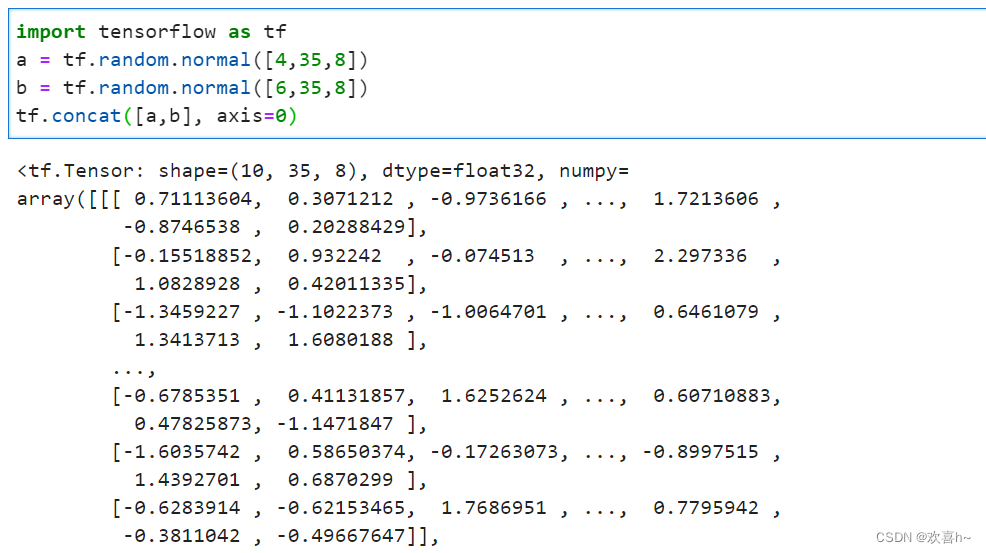
合并操作可以在任意的维度上进行,唯一的约束是非合并维度的长度必须一致。
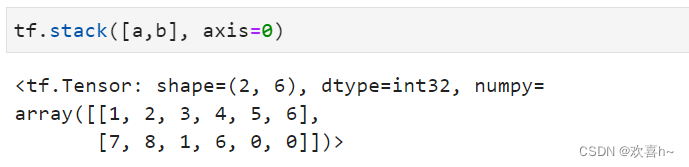
堆叠 tf.concat直接在现有维度上面合并数据,并不会创建新的维度。如果在合并数据时,希望创建一个新的维度,则需要使用tf.stack操作。考虑张量A保存了某个班级的成绩册,shape为[35,8],张量B保存了另一个班级的成绩册,shape为[35,8]。合并这2个班级的数据时,需要创建一个新维度,定义为班级维度,新维度可以选择放置在任意位置,一般根据大小维度的经验法则,将较大概念的班级维度放置在学生维度之前,则合并后的张量的新shape应为[2,35,8]。
使用tf.stack(tensors, axis)可以合并多个张量tensors,其中axis指定插入新维度的位置。
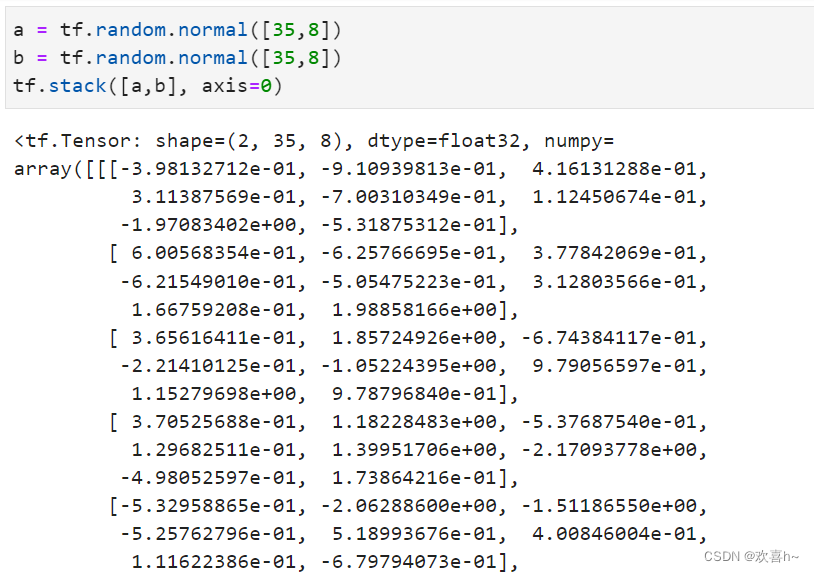
与tf.concat比较,tf.concat也可以顺利合并数据,但是在理解时,需要按着前35个学生来自第一个班级,后35个学生来自第二个班级的方式。
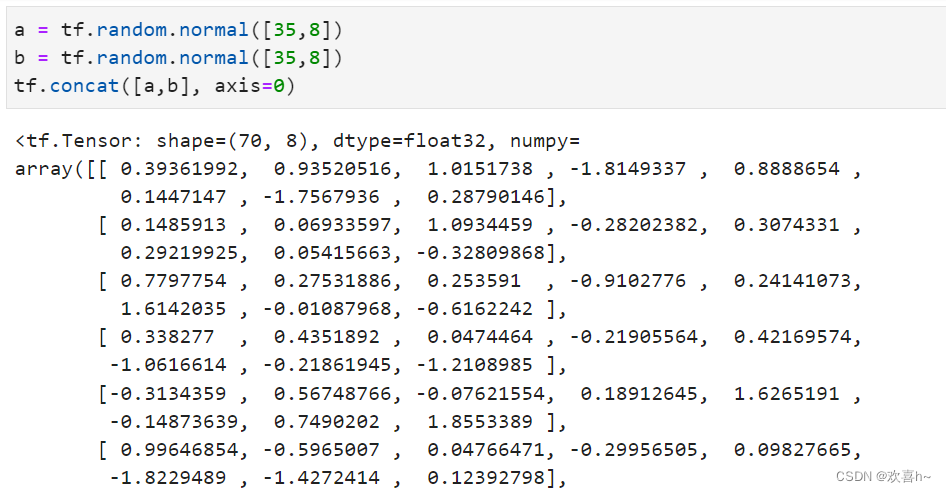
tf.stack也需要满足张量堆叠合并条件,它需要所有合并的张量shape完全一致才可合并。
1.2 分割
合并操作的逆过程就是分割,将一个张量分拆为多个张量。
tf.split(x, axis, num_or_size_splits)可以完成张量的分割操作。其中
- x:待分割张量
- axis:分割的维度索引号
- num_or_size_splits:切割方案。当为单个数值时,如10,表示切割为10份;当为List时,每个元素表示每份的长度,如[2,4,2,2]表示切割为4份,每份的长度分别问为2,4,2,2

可以查看切割后的某个张量的形状:
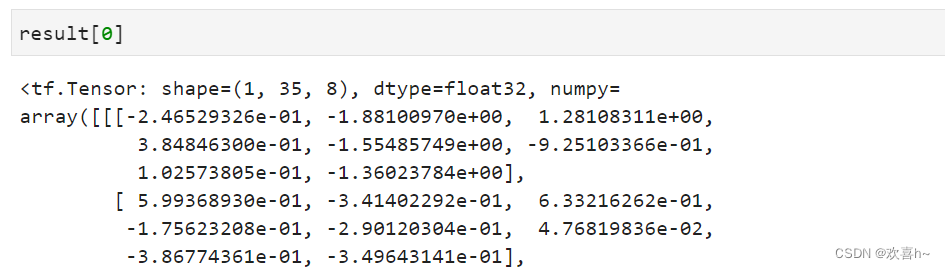
特别的,如果希望在某个维度上全部按长度为1的方式分割,还可以直接使用tf.unstack(x,axis)。
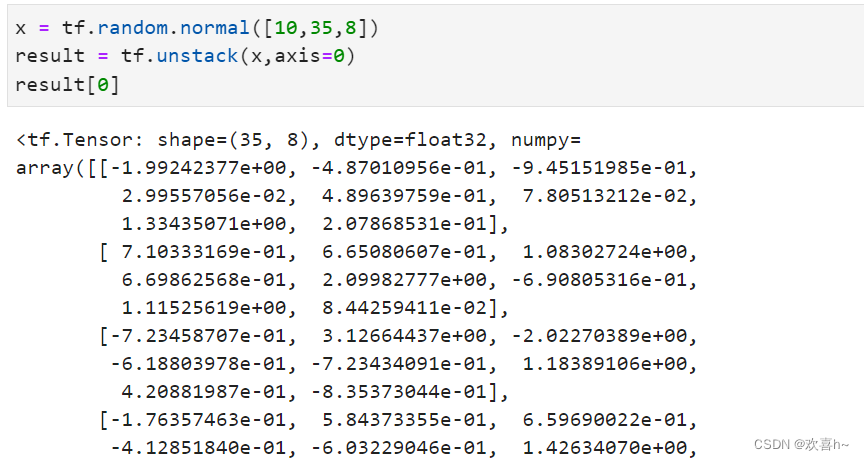
可以看到,通过tf.unstack切割后,shape变为[35,8],即班级维度消失了,这也是与split区别之处。
2. 数据统计
2.1 向量范数
向量范数是表征“长度”的一种度量方法,在神经网络中,常用来表示张量的权值大小,梯度大小等。
- L1范数,定义为向量x的所有元素绝对值之和
- L2范数,定义为向量x的所有元素的平方和,再开根号
- ∞-范数,定义为向量x的所有元素绝对值的最大值
对于矩阵、张量,同样可以利用向量范数的计算公式,等价于将矩阵、张量打平成向量后计算。
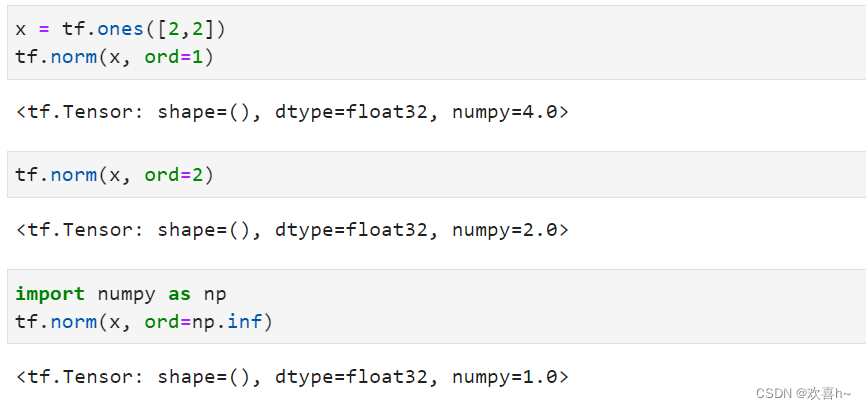
在TensorFlow中,可以通过tf.norm(x, ord)求解张量的L1, L2, ∞等范数,其中参数ord指定为1,2时计算L1, L2范数,指定为np.inf时计算∞-范数。
2.2 最大最小值、均值、和
通过tf.reduce_max, tf.reduce_min, tf.reduce_mean, tf.reduce_sum可以求解张量在某个维度上的最大、最小、均值、和,但不指定维度可以求全局最大、最小、均值、和。
通过tf.argmax(x, axis), tf.argmin(x, axis)可以求解在axis轴上,x的最大值、最小值所在的索引号。
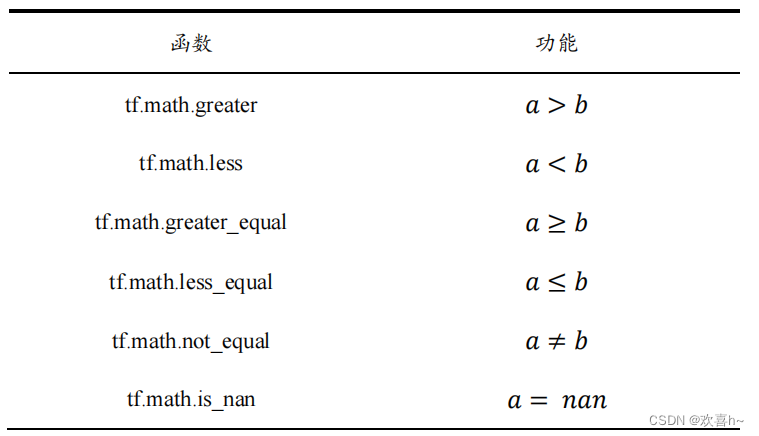
3. 张量比较
4. 填充与复制
4.1 填充
对于图片数据的高和宽、序列信号的长度,维度长度可能各不相同。为了方便网络的并行计算,需要将不同长度的数据扩张为相同长度,之前介绍过通过复制的方式可以添加数据的长度,但是重复数据数据会破坏原有的数据结构。通常的做法是,在需要补充长度的信号开始或结束处填充足够数量的特定数值,如0,使得填充后的长度满足系统要求。这种操作就叫做填充(Padding)。

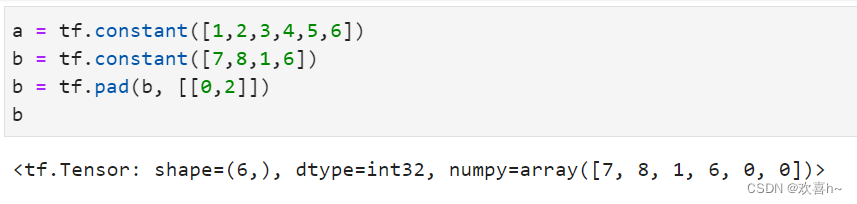
填充操作可以通过tf.pad(x, paddings)函数实现,paddings是包含了多个[Left Padding, Right Padding]的嵌套方案List,如[[0,0],[2,1],[1,2]]表示第一个维度不填充,第二个维度左边(起始处)填充两个单元,右边(结束处)填充一个单元,第三个维度左边填充一个单元,右边填充两个单元。
填充后句子张量形状一致,再将这2个句子stack在一起:
考虑对图片的高宽维度进行填充。以28×28大小的图片为例,如果网络层所接受的数据高宽为32×32,则必须将28×28大小填充到32×32,可以在上、下、左、右方向各填充2个单元。

上述填充方案可以表达为[[0,0],[2,2],[2,2],[0,0]]。
4.2 复制
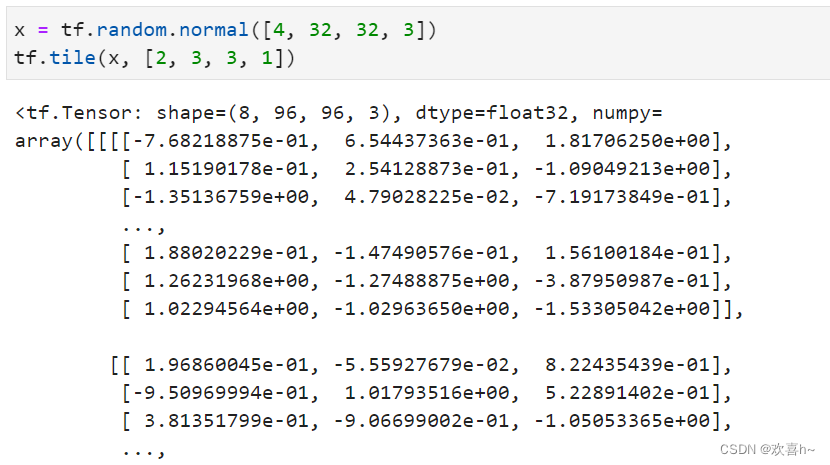
为介绍维度变换时,就通过tf.tile()函数实现长度为1的维度复制的功能。tf.tile函数除了可以对长度为1的维度进行复制若干份,还可以对任意长度的维度进行复制若干份,进行复制时会根据原来的数据次序重复复制。
如multiples=[2,3,3,1],即通道数据不复制,高宽方向分别复制2份,图片数再复制1份:
5. 数据限幅
在TensorFlow中,可以通过tf.maximum(x,a)实现数据的下限幅:x∈[a,+∞);可以通过tf.minimum(x,a)实现数据的上限幅:x∈(-∞,a]。

通过组合tf.maximum(x,a)和tf.minimum(x,b)可以实现同时对数据的上下边界限幅:x∈[a,b]。

更方便地,可以使用tf.clip_by_value实现上下限幅:

6. 高级操作
6.1 tf.gather
tf.gather可以实现根据索引号收集数据的目的。考虑班级成绩册的例子,共有4个班级,每个班级35个学生,8门科目,保存成绩册的张量shape为[4,35,8]。
现在需要收集第1-2个班级的成绩册,可以给定需要收集班级的索引号:[0,1],班级的维度axis=0:


6.2 tf.gather_nd
通过tf.gather_nd,可以通过指定每次采样的坐标来实现采样多个点的目的。

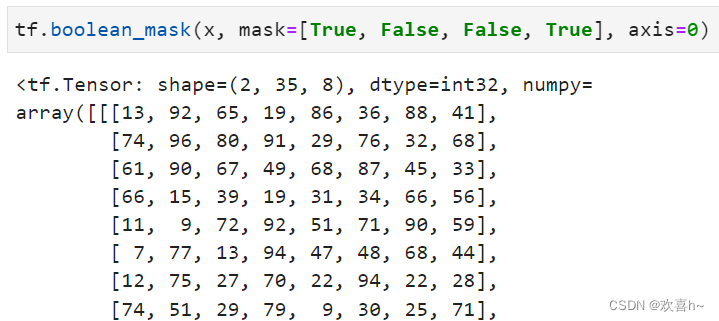
6.3 tf.boolean_mask
除了可以通过给定索引号的方式采样,还可以通过给定掩码(mask)的方式采样。
考虑在班级维度上进行采样,对这4个班级的采样方案的掩码为
mask = [True, False, False, True]
即采用第1和第4个班级,通过tf.boolean_mask(x, mask, axis)可以在axis轴上根据mask方案进行采样。
6.4 tf.where
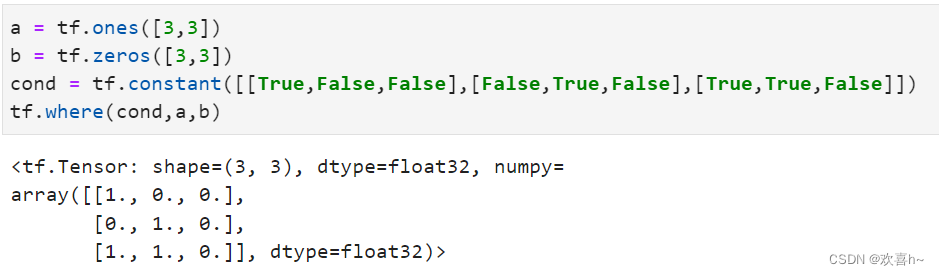
通过tf.where(cond,a,b)操作可以根据cond条件的真假从a或b中读取数据,条件判定规则如下:
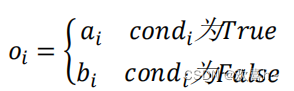
其中i为张量的索引,返回张量大小与a,b张量一致。
6.5 scatter_nd
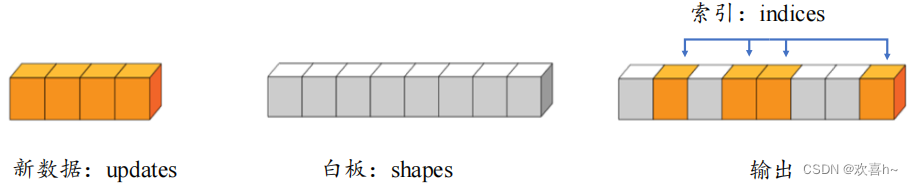
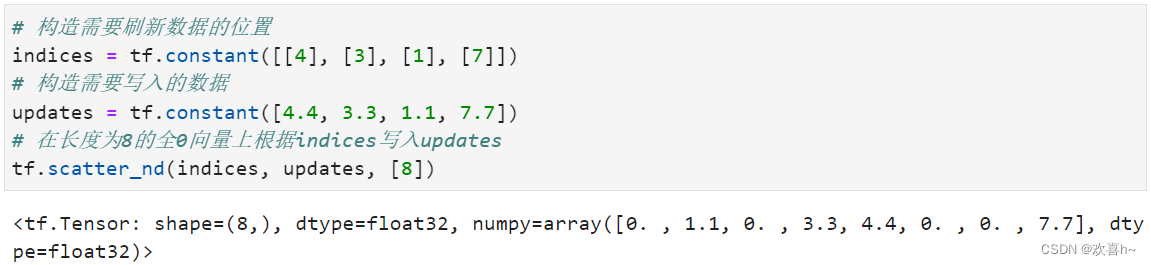
通过tf.scatter_nd(indices, updates, shape)可以高效地刷新张量的部分数据,但是只能在全0张量的白板上面刷新,因此可能需要结合其他操作来实现现有张量的数据刷新功能。如下图所示,演示了一维张量白板的刷新运算,白板的形状表示为shape参数,需要刷新的数据索引为indices,新数据为updates,其中每个需要刷新的数据对应在白板中的位置,根据indices给出的索引位置将updates中新的数据依次写入白板中,但返回更新后的白板张量。
6.6 meshgrid
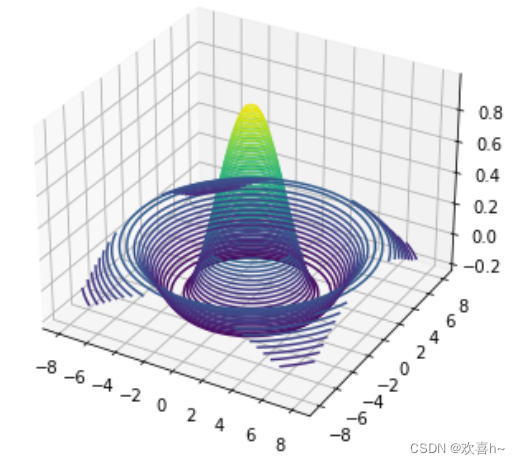
通过tf.meshgrid可以方便地生成二维网格采样点坐标,方便可视化等应用场合。考虑2个自变量x,y的Sinc函数表达式为:
如果需要绘制函数在x∈[-8,8], y∈[-8,8]区间的Sinc函数的3D曲面,首先需要生成x,y的网格点坐标{(x,y)},这样才能通过Sinc函数的表达式计算函数在每个(x,y)位置的输出值z。很明显这种方式串行计算效率极低。
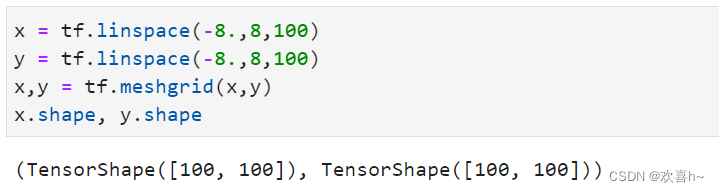
通过在x轴上进行采样100个数据点,y轴上采样100个数据点,然后通过tf.meshgrid(x,y)即可返回这10000个数据点的张量数据,shape为[100,100,2]。为了方便计算,tf.meshgrid会返回在axis=2维度切割后的2个张量a,b,其中张量a包含了所有点的x坐标,b包含了所有点的y坐标,shape都为[100,100]:
结果如下
7. 经典数据集加载
在TensorFlow中,keras.datasets模块提供了常用经典数据集的自动下载、管理、加载与转换功能,并且提供了tf.data.Dataset数据集对象,方便实现多线程,预处理,随机打散和批训练等常用数据集功能。
常用的数据集:
- Boston Housing 波士顿房价趋势数据集,用于回归模型训练与测试
- CIFAR10/100 真实图片数据集,应用于图片分类任务
- MNIST/Fashion_MNIST 手写数字图片数据集,用于图片分类任务
- IMDB 情感分类任务数据集
通过dataset.xxx.load_data()即可实现经典数据集的自动加载,其中xxx代表具体的数据集名称。TensorFlow会默认将数据缓存在用户目录下的.keras/datasets文件夹。
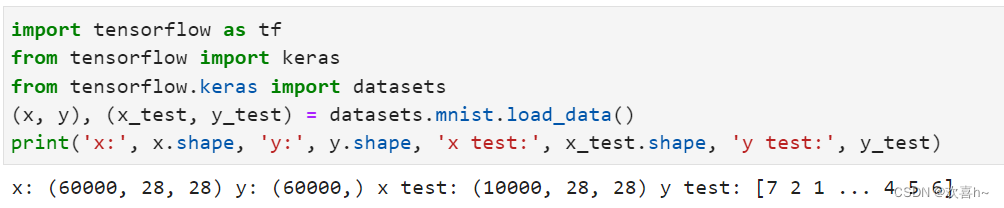
数据加载进入内存后,需要转换为Dataset对象,以利用TensorFlow提供的各种便捷功能。通过Dataset.from_tensor_slices可以将训练部分的数据图片x和标签y都转换成Dataset对象:
![]()
将数据转换成Dataset对象后,一般需要再添加一系列的数据集标准处理步骤,如随机打散、预处理,按批装载等。
7.1 随机打散
通过Dataset.shuffle(buffer_size)工具可以设置Dataset对象随机打散数据之间的顺序,防止每次训练时数据按固定的顺序产生,从而使得模型尝试“记忆”住标签信息:
![]()
其中buffer_size指定缓冲池的大小,一般设置为一个较大的参数即可。通过Dataset提供的这些工具函数会返回新的Dataset对象,可以通过
db = db.shuffle().step2().step3.()
方式完成所有的数据处理步骤,实现起来非常方便。
7.2 批训练
为了利用显卡的并行计算能力,一般在网络的计算过程中会同时计算多个样本,把这种训练方式叫做批训练,其中样本的数量叫做batch size。为了一次能够从Dataset中产生batch size数量的样本,需要设置Dataset为批训练方式:
![]()
其中128为batch size参数,即一次并行计算128个样本的数据。Batch size一般根据用户的GPU显存资源来设置,当显存不足时,可以适量减少batch size来减少算法的显存使用量。
7.3 预处理
从keras.datasets中加载的数据集的格式大部分情况都不能满足模型的输入要求,因此需要根据用户的逻辑自己实现预处理函数。Dataset对象通过提供map(func)工具函数可以非常方便地调用用户自定义的预处理逻辑,它实现在func函数里:

7.4 循环训练
对于Dataset对象,在使用时可以通过
for step, (x,y) in enumerate(train_db): # 迭代数据集对象,带step参数或
for x,y in train_bd: # 迭代数据集对象方式进行迭代,每次返回的x,y对象即为批量样本和标签,当对train_db的所有样本完成一次迭代后,for循环终止退出。一般把完成一个batch的数据训练,叫做一个step;通过多个step来完成整个训练集的一次迭代,叫做一个epoch。在实际训练时,通常需要对数据集迭代多个epoch才能取得较好地训练结果。
8. MNIST测试实战
库的调用
数据集处理

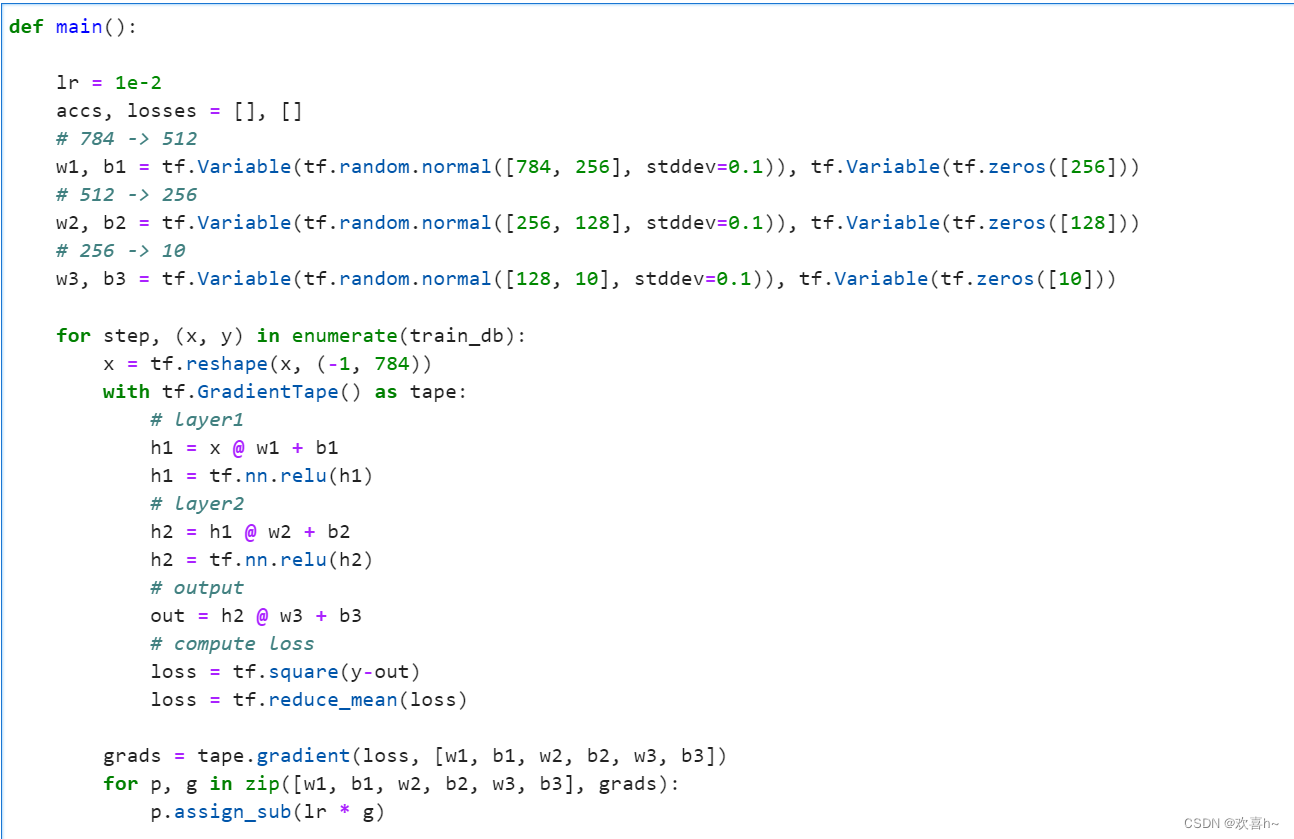
main函数定义训练过程
训练过程中打印准确率

绘图

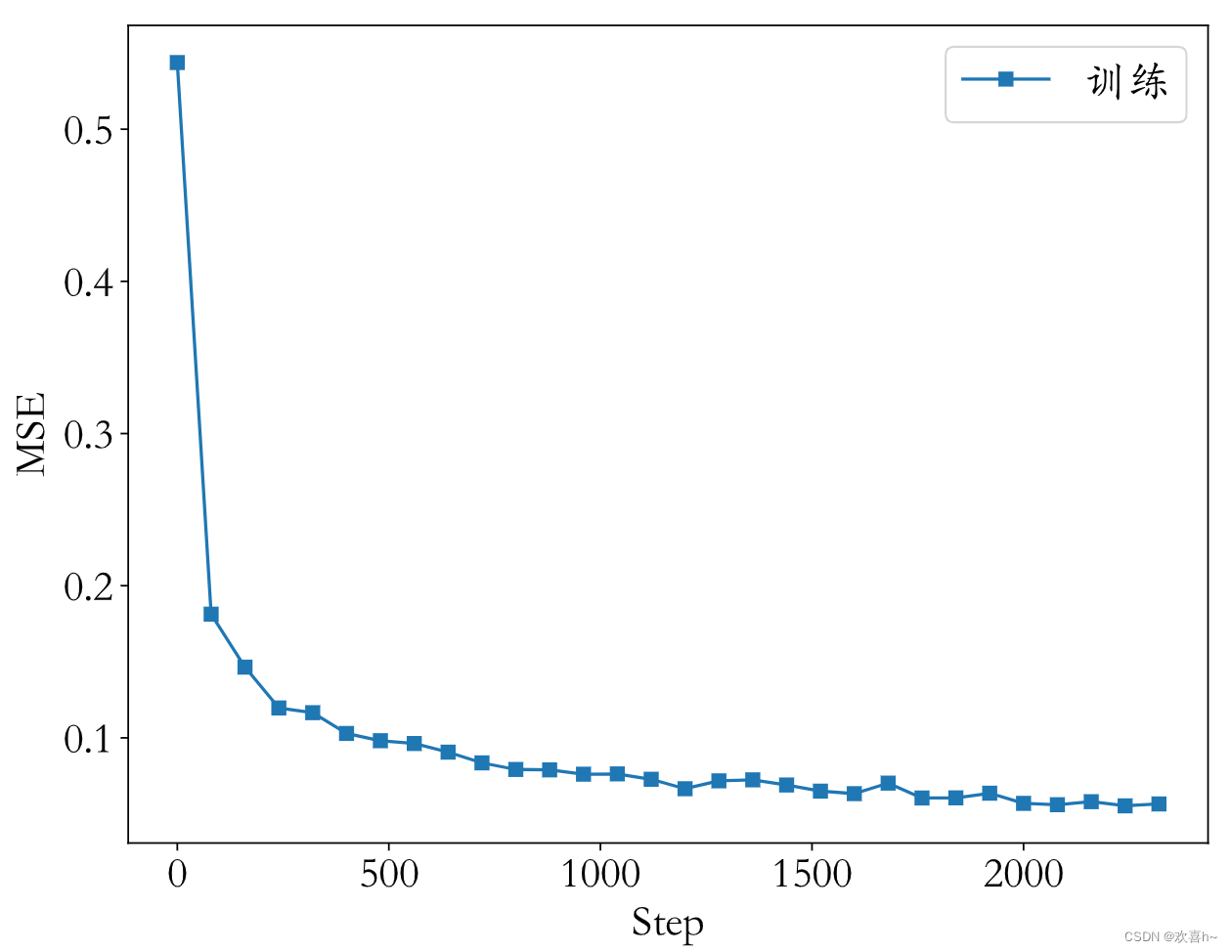
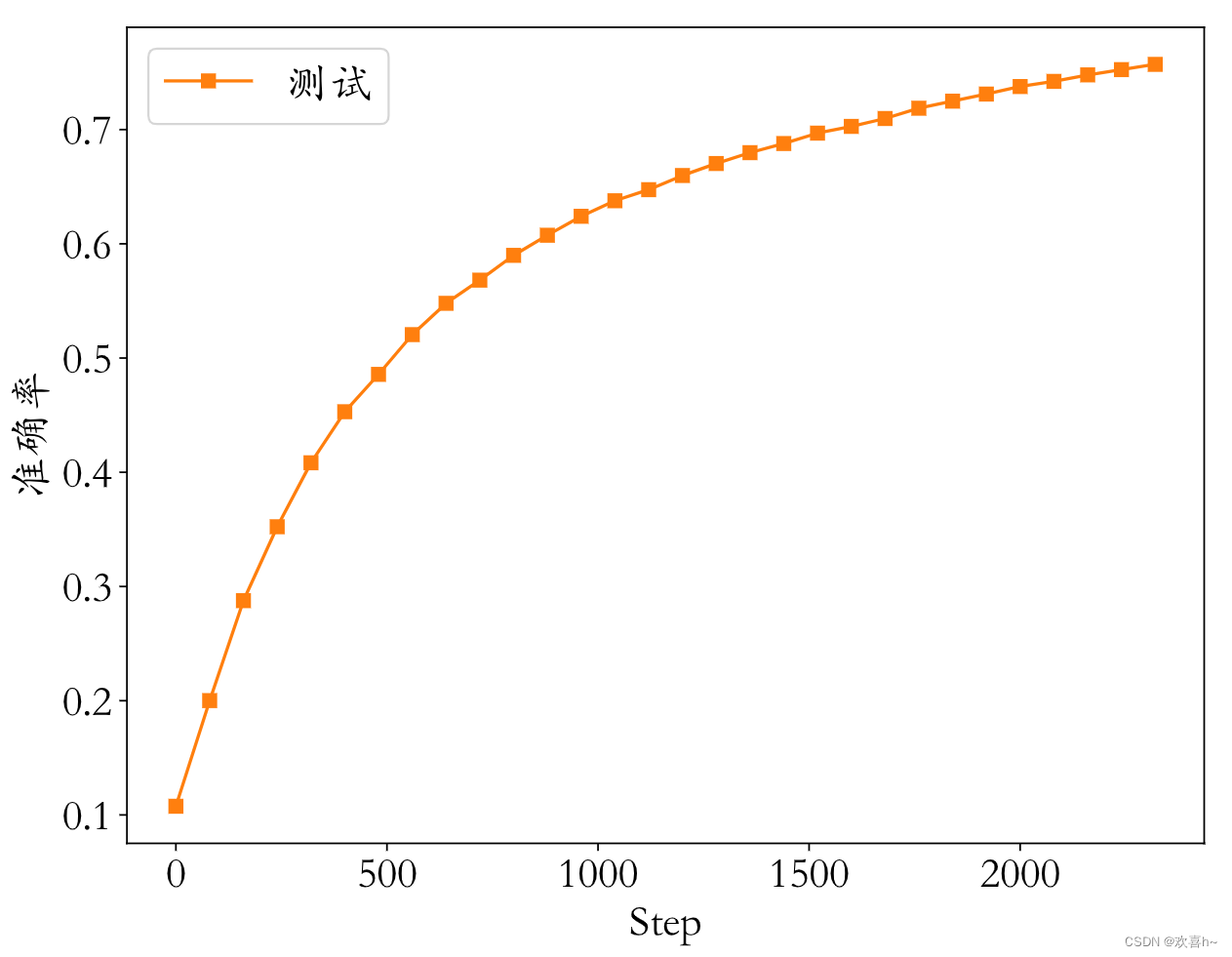
训练过程打印的信息如下:
0 loss: 0.5438116788864136 0 Evaluate Acc: 0.1076 80 loss: 0.18129126727581024 80 Evaluate Acc: 0.2001 160 loss: 0.14648392796516418 160 Evaluate Acc: 0.2876 240 loss: 0.11965350806713104 240 Evaluate Acc: 0.3523 320 loss: 0.1165451630949974 320 Evaluate Acc: 0.4083 400 loss: 0.10289990901947021 400 Evaluate Acc: 0.453 480 loss: 0.09813614934682846 480 Evaluate Acc: 0.4857 560 loss: 0.09628277271986008 560 Evaluate Acc: 0.5205 640 loss: 0.09061522036790848 640 Evaluate Acc: 0.5479 720 loss: 0.0835588276386261 720 Evaluate Acc: 0.5682 800 loss: 0.07922451198101044 800 Evaluate Acc: 0.5899 880 loss: 0.07896079868078232 880 Evaluate Acc: 0.6075 960 loss: 0.07612555474042892 960 Evaluate Acc: 0.6241 1040 loss: 0.07631582766771317 1040 Evaluate Acc: 0.6377 1120 loss: 0.07278357446193695 1120 Evaluate Acc: 0.6474 1200 loss: 0.0665632039308548 1200 Evaluate Acc: 0.6598 1280 loss: 0.07175104320049286 1280 Evaluate Acc: 0.6703 1360 loss: 0.07240866124629974 1360 Evaluate Acc: 0.6798 1440 loss: 0.06902817636728287 1440 Evaluate Acc: 0.6878 1520 loss: 0.06498271226882935 1520 Evaluate Acc: 0.6969 1600 loss: 0.06333114206790924 1600 Evaluate Acc: 0.7028 1680 loss: 0.07025714218616486 1680 Evaluate Acc: 0.7097 1760 loss: 0.06047321483492851 1760 Evaluate Acc: 0.7187 1840 loss: 0.06056402251124382 1840 Evaluate Acc: 0.7249 1920 loss: 0.0636252909898758 1920 Evaluate Acc: 0.7311 2000 loss: 0.0569530613720417 2000 Evaluate Acc: 0.7377 2080 loss: 0.05606473237276077 2080 Evaluate Acc: 0.7422 2160 loss: 0.05805633217096329 2160 Evaluate Acc: 0.7479 2240 loss: 0.05531547591090202 2240 Evaluate Acc: 0.7525 2320 loss: 0.05656725913286209 2320 Evaluate Acc: 0.7571
最后训练过程的MSE和测试的准确率如图所示:















 342
342











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









