







简介
主页:https://free-view-video.github.io/

将一个单目视频作为输入(a)。视频中的每一帧都是以一个独特的时间步和不同的视图(例如,黄色和蓝色帧)拍摄的。目标是在任意相机视点和时间步(红帧)下合成动态场景的逼真新颖视图。该系统可实现自由视点视频,为用户提供沉浸式、近乎逼真的观看体验。
贡献点
- 提出了一种通过联合训练时不变模型和时变模型来建模动态辐射场的方法,并学习了如何以无监督的方式混合结果。
- 设计了正则化损耗来解决动态辐射场学习时的模糊性
- 与动态场景数据集上最先进的算法相比,我们的模型得到了良好的结果
实现流程
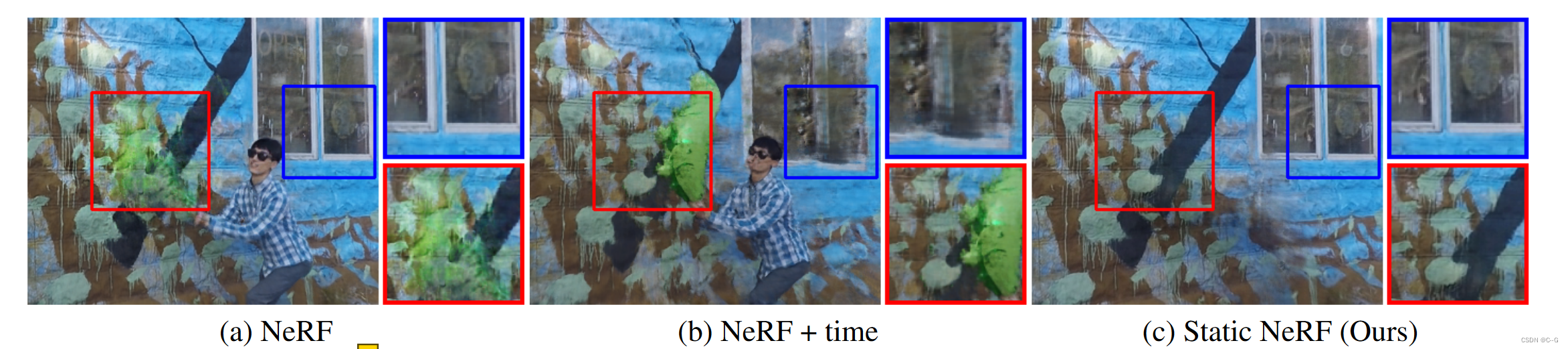
NeRF假设场景是完全静态的。(a)在动态场景上直接训练NeRF模型不可避免地会导致模糊重建(即使是场景的静态区域)。(b)一个直接的扩展是把时间作为一个额外的输入维度(NeRF +时间)。然而,这种方法存在模糊性,因为输入视频既可以用时变几何形状解释,也可以用时变外观解释,或者两者都可以解释。该表示可以很好地重建输入帧,但在新视图下产生视觉假象。©为了解决这个问题,使用静态NeRF对场景的静态组件建模,从训练模型中排除了所有标记为“动态”的像素。能够准确地重建背景的结构和外观,而不会与移动的物体发生冲突。
方法总览
输入: N 帧的单目视频和 每帧前景对象的二进制掩码M(M=0表示静态),掩模可以通过分割或运动分割算法自动获得,也可以通过交互方法(如旋转定标)半自动获得
目标:学习在任意视图和输入时间步上促进自由视点渲染的全局表示
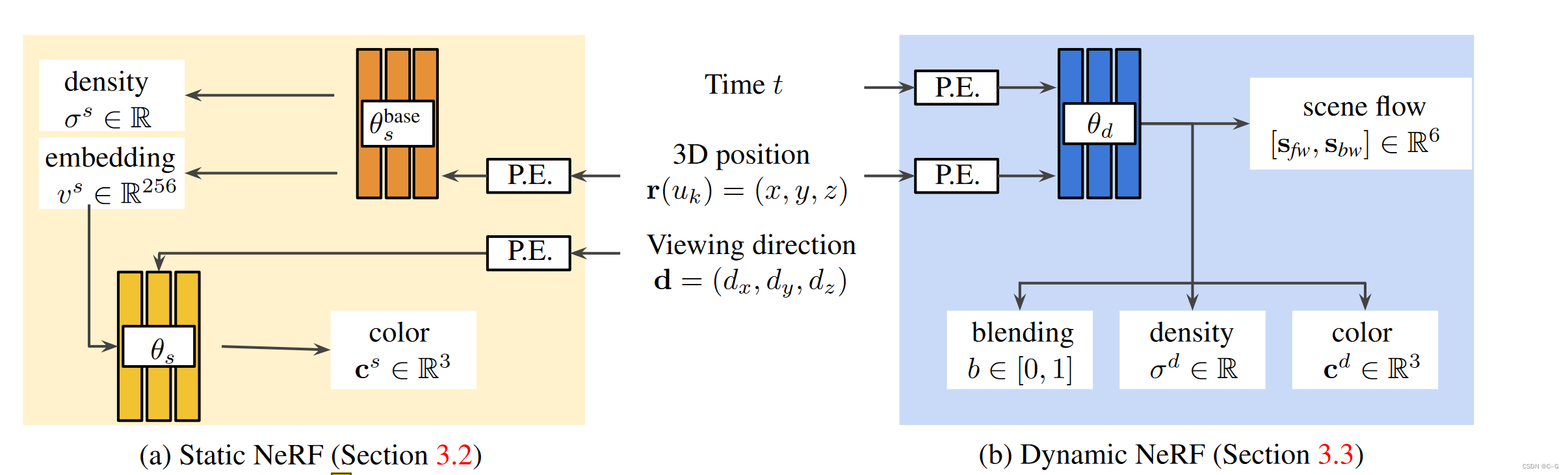
使用两种不同的模型来表示(a)静态和(b)动态场景组件。(a)静态NeRF:对于静态组件,训练一个NeRF模型,但在训练模型时排除了所有标记为动态的像素。这允许重建背景的结构和外观,而不冲突的移动对象。(b)动态NeRF:从单个视频建模动态场景是高度病态的。为了解决模糊性,利用多视图约束如下:动态NeRF将 r(
u
k
u_k
uk) 和 t 作为输入,预测时间 t 到 t + 1 (
s
f
w
s_{fw}
sfw)和时间 t 到 t−1 (
s
b
w
s_{bw}
sbw)的3D场景流。使用预测的场景流,可以通过对相邻时间实例建模的亮度场重新采样来创建一个扭曲的亮度场,并应用时间一致性。因此,在每个实例中,可以有与不同时间 t 相关联的多个视图来训练模型
Static NeRF
将3D位置
r
(
u
k
)
r(u_k)
r(uk) 和观看方向 d 映射为体积密度
σ
s
σ^s
σs 和颜色
c
s
c^s
cs
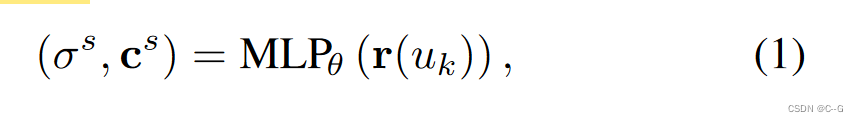
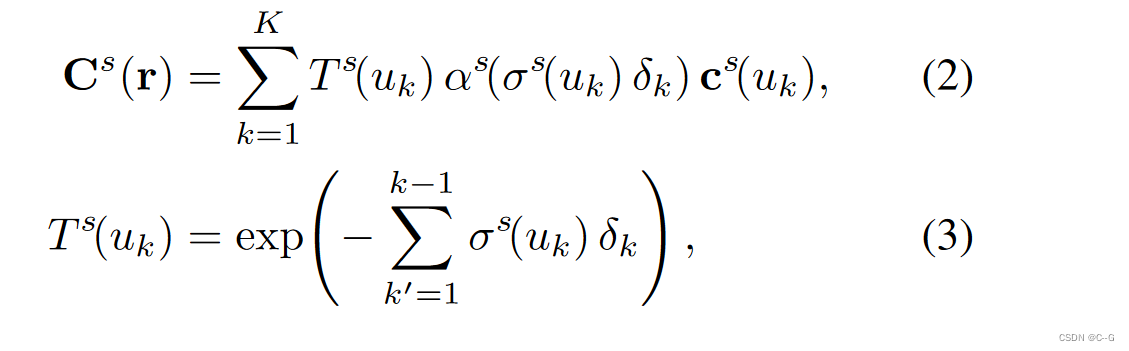
Static rendering photometric loss
为了训练静态NeRF模型的权重
θ
s
θ_s
θs,首先使用所有视频帧的所有像素构建相机射线(使用每帧的相关内在和外在相机姿势),用
r
i
j
(
u
)
=
o
i
+
(
u
)
d
i
j
r_{ij}(u) = o_i+(u)d_{ij}
rij(u)=oi+(u)dij 表示通过图像 i 上像素j的射线,通过最小化坐标系 i∈{0,…,N-1} 中所有颜色像素
C
(
r
i
j
)
C(r_{ij})
C(rij) 的静态渲染光度损失来优化
θ
s
θ^s
θs,在这里,
M
(
r
i
j
)
M(r_{ij})
M(rij) = 0

Dynamic NeRF

由于训练目标是最小化输入视频帧上的图像重建损失,NeRF +时间可以很好地解释输入帧。然而,有无限多的解决方案可以正确渲染给定的输入视频,但其中只有一个是物理上正确的生成逼真的新视图。NeRF + time试图将视图从时间中分离出来,使用时间作为额外的输入。然而,这个问题变得缺乏约束,并导致静态和动态区域中的工件。动态NeRF为移动物体生成了合理的视图合成结果。
在每个时间实例t下只有一个二维图像观测,因此训练缺乏多视图约束
预测了正向和向后场景流,并通过对 t + 1 和 t−1 时刻隐式建模的亮度场重新采样,使用它们创建一个扭曲的亮度场
对于时刻 t 的每个3D位置,最多有三个2D图像观测
以一个4d元组
(
r
(
u
k
)
,
t
)
(r(u_k), t)
(r(uk),t)为输入,预测3D场景流向量
s
f
w
,
s
b
w
s_{fw}, s_{bw}
sfw,sbw,体积密度
σ
d
σ^d
σd,颜色
c
d
c^d
cd 和混合权重 b

利用预测的场景流
s
f
w
s_{fw}
sfw 和
s
b
w
s_{bw}
sbw,得到了场景流邻域
(
r
(
u
k
)
+
s
f
w
(r(u_k)+ s_{fw}
(r(uk)+sfw 和(r(u_k)+ s_{bw}$,使用预测的场景流来将辐射场从邻近的时间实例弯曲到当前时间, t 时刻的每个3D位置,通过查询
r
(
u
k
)
+
s
r(u_k) + s
r(uk)+s 处的相同MLP模型,得到占用率
σ
d
σ^d
σd 和 颜色
c
d
c^d
cd
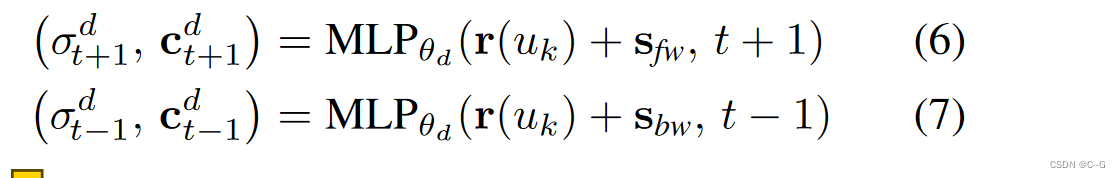
计算 t '时刻动态像素的颜色
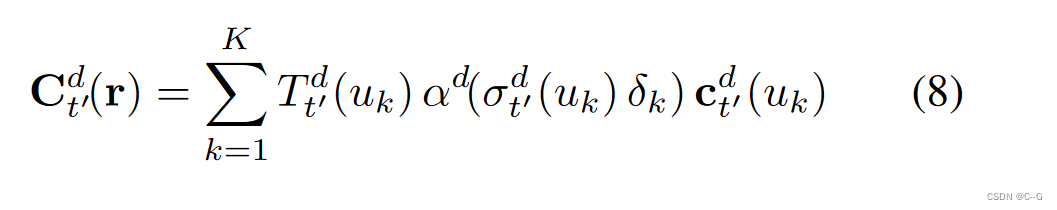
与静态损失类似,动态损失为
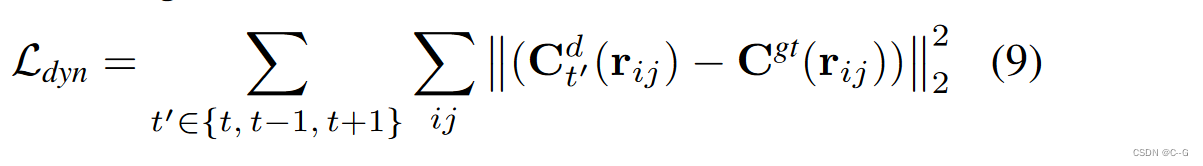
Regularization Losses for Dynamic NeRF
虽然利用动态NeRF模型中的多视图约束减少了模糊量,但如果没有适当的正则化,模型训练仍然是病态的。为此,设计了几个正则化损耗来约束动态NeRF。
Motion matching loss
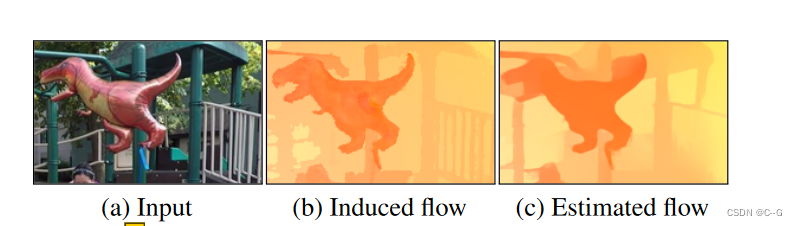
通过最小化估计光流和场景流诱导光流之间的端点误差来监督预测的场景流。由于联合使用光度损失和运动匹配损失来训练模型,学到的体积密度有助于渲染比估计的流量更精确的流量(例如,右侧围栏的复杂结构)。
由于没有从运动MLP模型预测的场景流的直接3D监督,使用2D光流(从输入图像对估计)作为间接监督。对于时刻 t 的每个3D点,首先利用估计的场景流得到参考帧中对应的3D点。然后将这个3D点投射到参考相机上,这样就可以计算场景流诱导光流,并使其与估计的光流匹配(图5)。由于联合训练了光度损失和运动匹配损失的模型,学习到的体积密度有助于渲染比估计的流更精确的流。因此,不会遭受不准确的光流监测
Motion regularization
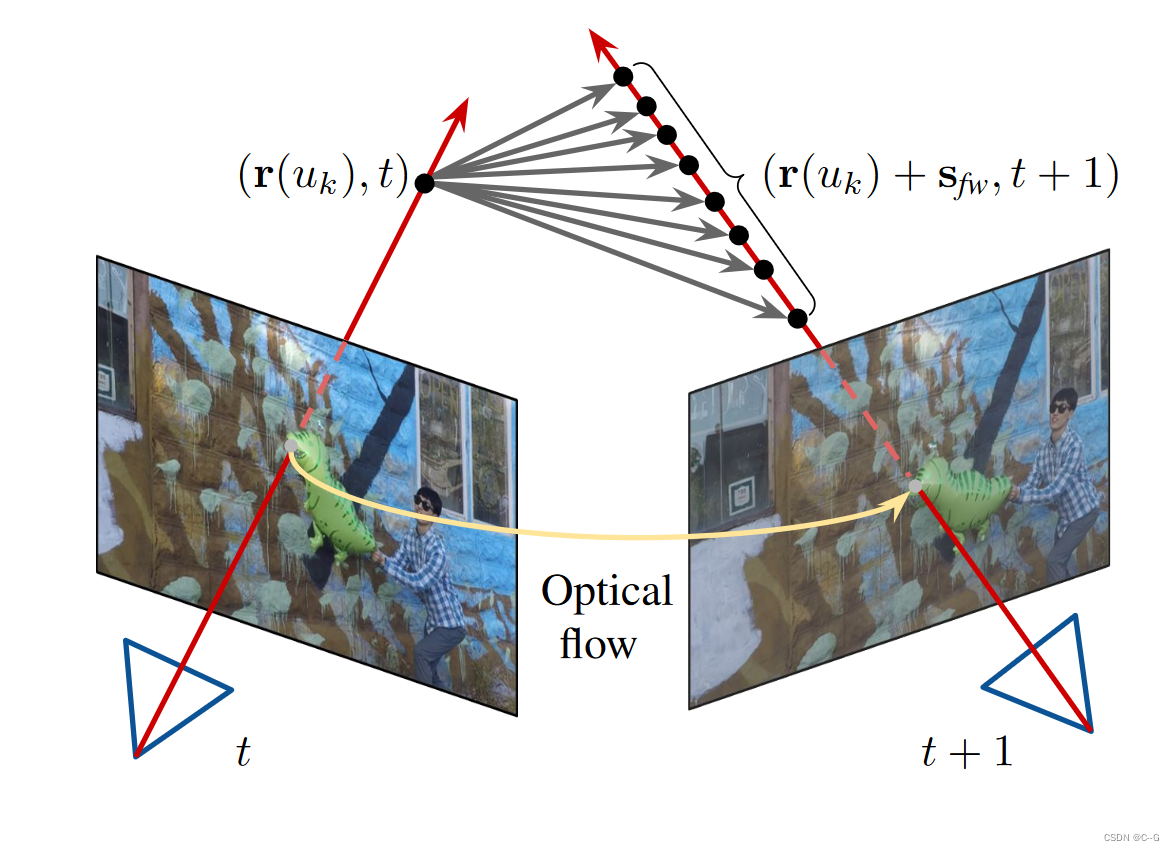
不幸的是,与2d光学匹配场景呈现流流并不完全解决所有模棱两可,1 dfamily of scene flow vectors产生相同的2 d光学流。规范现场流缓慢而暂时平滑
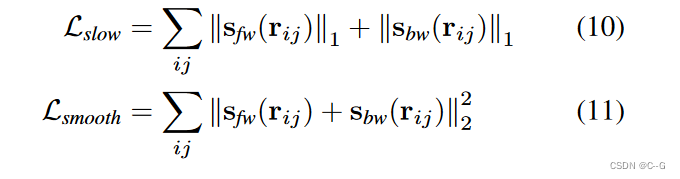
通过最小化相邻3D点之间的场景流差异,使场景流在空间上平滑
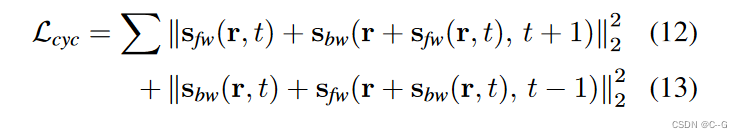
Sparsity regularization
使用经典体绘制的原理来渲染颜色。如果粒子是部分透明的,就可以透过它看到它。然而,人们不能通过场景流看到场景流,因为场景流不是一种固有属性(不像颜色)。因此,沿着每条射线最小化渲染权值 T d α d T^dα^d Tdαd的熵,以便少数样本主导渲染。
Depth order loss
对于一个移动的物体,可以将其解释为一个靠近相机的物体缓慢移动,也可以解释为一个远处的物体快速移动
为了解决模糊性问题,利用最先进的单幅图像深度估计方法来估计输入深度,由于深度估计与位移和比例有关,不能直接使用它们来监督模型,使用鲁棒损失来约束动态NeRF
由于监督仍然取决于转移和规模,进一步用静态NeRF约束动态NeRF,由于多视图约束,静态NeRF为静态区域估计了精确的深度。此外,对于静态区域中的所有像素(其中
M
(
r
i
j
)
=
0
M(r_{ij}) = 0
M(rij)=0),我们将
D
s
D^s
Ds和
D
d
D^d
Dd之间的L2差最小化:
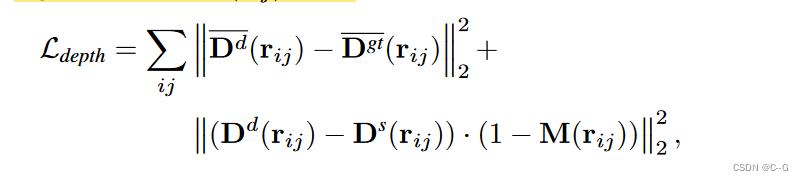
D
ˉ
\bar{D}
Dˉ 为归一化深度
3D temporal consistency loss
3D时间一致性丢失。如果物体静止不动一段时间,网络无法学习到当前被遮挡背景的正确体积密度和颜色,因为在体绘制时省略了这些3D位置。在绘制新视图时,模型可能会对遮挡区域产生孔洞。为了解决这个问题,提出在渲染前的3D时间一致性损失。具体来说,加强每个3D位置的体积密度和颜色来匹配它的场景流邻居。正确的体积密度和颜色将跨越时间步进行传播。
Rigidity regularization of the scene flow
场景流的刚性正则化。如果该位置没有运动,该模型倾向于通过静态NeRF来解释3D位置。对于静态位置,我们希望混合权重b接近于1。对于非刚性位置,混合权重b应为0。这种习得的混合权值可以进一步约束预测场景流的刚度,取预测场景流与(1−b)的乘积。如果一个3D位置没有运动,场景流被强制为零。
Combined model
使用静态和动态NeRF模型,可以很容易地使用预测的混合权重 b 将它们组合成一个完整的模型,并在新的视图和时间渲染全彩色帧
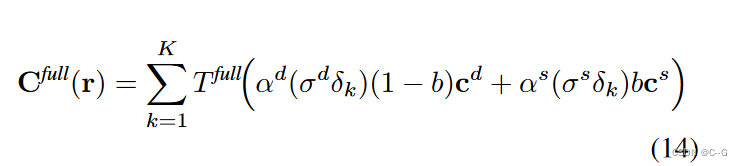
使用动态NeRF来预测混合权重
b
d
b_d
bd,以加强时间依赖性,使用混合权重,还可以呈现静态区域是透明的动态组件框架
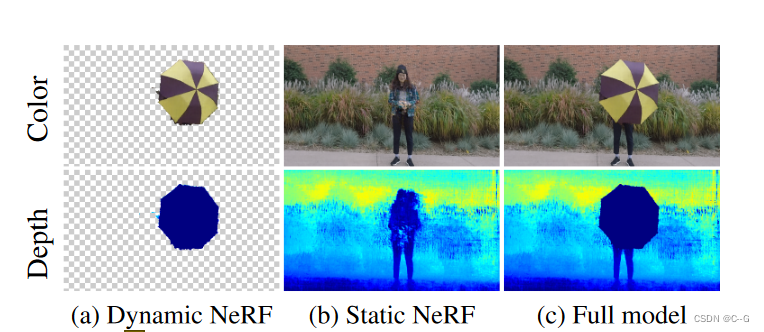
将(a)动态和(b)静态NeRF模型组合到©完整模型中,并以新的视点和时间步呈现完整帧。
Full rendering photometric loss
对合成结果应用重构损失来联合训练两个NeRF模型
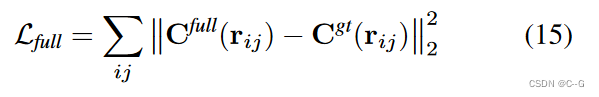
效果


















 2193
2193

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









