









文章目录
1 Transformer背景介绍
1.1 Transformer诞生
Transformer是一种在自然语言处理领域中引起了革命性变革的模型架构。它首次被提出于2017年的论文《Attention is All You Need》中,由Google的研究团队提出。
这篇论文开创了一种全新的模型架构,成为了许多自然语言处理任务的基础,如机器翻译、文本摘要、对话生成等。随后许多基于Transformer的变种模型也相继涌现,例如BERT、GPT等,进一步推动了自然语言处理领域的发展。
2018年10月,Google发出一篇论文《BERT: Pre-training of Deep Bidirectional Transformers for Language
Understanding》, BERT模型横空出世, 并横扫NLP领域11项任务的最佳成绩!
-
《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》
-
BERT中发挥重要作用的结构就是Transformer, 之后相继出现XLNET,roBERT等模型击败了BERT,但核心没有变仍然是Transformer。
1.2 Transformer优点
相比之前占领市场的LSTM和GRU模型,Transformer有两个显著的优势:
- Transformer能够利用分布式GPU进行并行训练,提升模型训练效率
- 在分析预测更长的文本时, 捕捉间隔较长的语义关联效果更好
RNN、LSTM、Transformer对长文本提取事物特征效果对比
- RNN和LSTM文本长度20~30之间效果下降显著
- transformer超过句子长度40以后也能保持较好效果
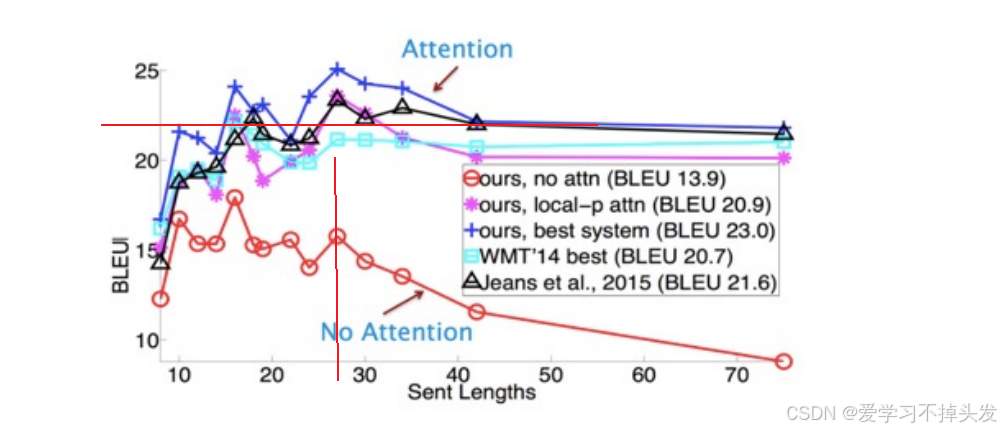
- 有关SOTA model:state-of-the-art model,并不是特指某个具体的模型,而是指在该项研究任务中,目前最好最先进的模型
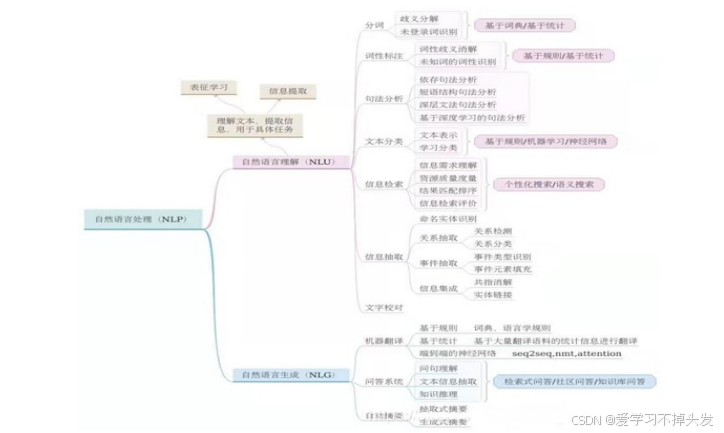
- NLP是人工智能的一个子域
- 2个核心任务:自然语言理解(Natural Language Understanding,NLU)和自然语言生成(Natural Language Generation,NLG)
- Bert模型用于自然语言理解,GPT用于自然语言生成
2 Transformer架构
2.1 Transformer结构作用
- 基于seq2seq架构的transformer模型可以完成NLP领域研究的典型任务,如机器翻译, 文本生成等;
- Encoder
- Decoder
- 中间语义张量C
- 又可构建预训练语言模型,用于不同任务的迁移学习
- 迁移学习: 可以简单理解为,调用别人已经训练好的模型,模型已经学习了很多知识。
2.2 Transformer总体架构图
任务需求:
- 假设使用Transformer模型架构,处理从一种语言文本到另一种语言文本的翻译工作
- 以这个案例为背景,介绍Transformer架构
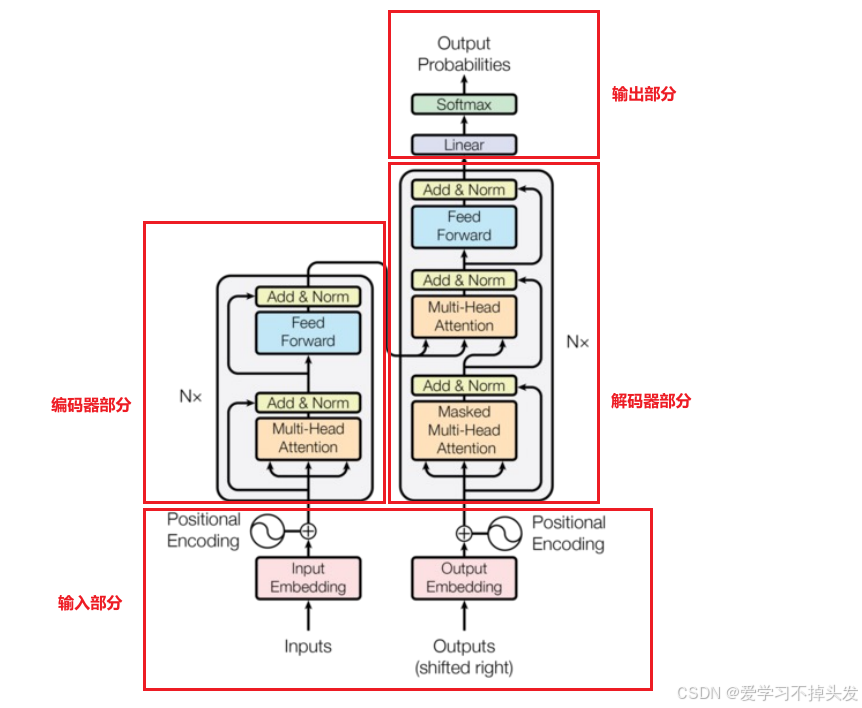
- 输入部分
- 源文本嵌入层及其位置编码器
- 目标文本嵌入层及其位置编码器
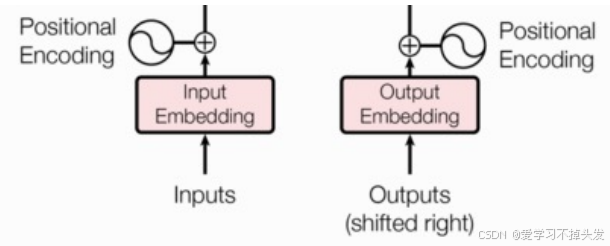
-
输出部分
- 线性层
- softmax层
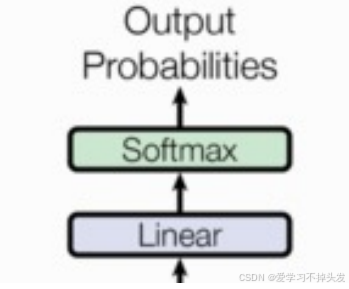
-
编码部分
- 由N个编码器层堆叠而成
- 每个编码器层由两个子层连接结构组成
- 第一个子层连接结构包括一个多头注意力子层和规范化层以及一个残差连接
- 第二个子层连接结构包括一个前馈全连接子层和规范化层以及一个残差连接
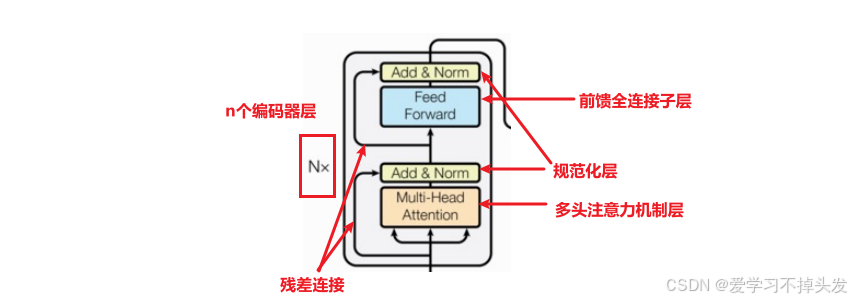
编码器部分层和层是如何连接:

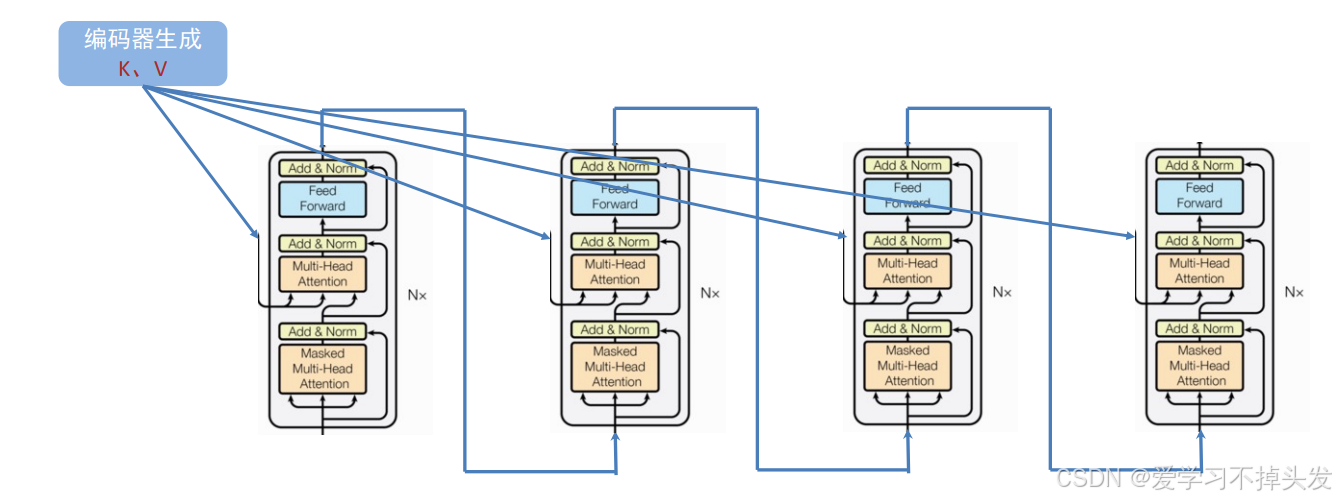
- 解码器部分
- 由N个解码器层堆叠而成
- 每个解码器层由三个子层连接结构组成
- 第一个子层连接结构包括一个多头自注意力子层和规范化层以及一个残差连接
- 第二个子层连接结构包括一个多头注意力子层和规范化层以及一个残差连接
- 第三个子层连接结构包括一个前馈全连接子层和规范化层以及一个残差连接
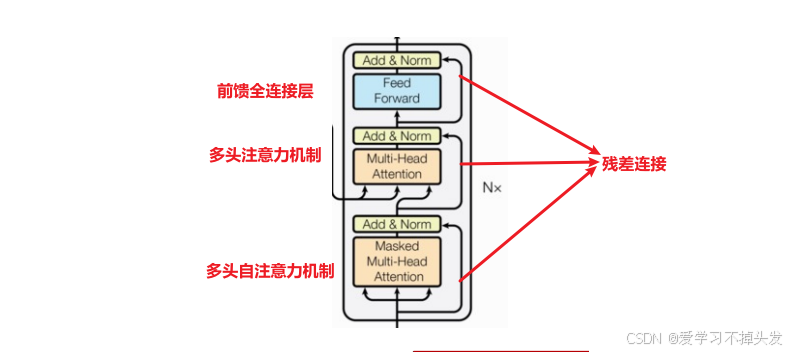
多个解码器层进行连接:

















 2878
2878

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









