







如何调用LLM大模型进行对话
环境准备
安装LangChain库:
pip install langchain langchain_openai

获取OpenAI API密钥(官网申请),并设置为环境变量:
Linux系统:(执行以下命令):
export OPENAI_API_KEY="你的密钥"
如果你想使用国内的大模型厂商,例如deepseek,kimi,阿里百炼,腾讯等,这些都支持openai的调用,只需要再设置多一个环境变量
export base_url="大模型厂商api的url"
Windows系统:
set OPENAI_API_KEY=你的密钥
使用echo命令来验证openai_api_key环境变量是否设置成功

如果你想使用国内的大模型厂商,例如deepseek,kimi,阿里百炼,腾讯等,这些都支持openai的调用,只需要再设置多一个环境变量
set base_url=大模型厂商api的url
使用echo命令来验证base_url环境变量是否设置成功

如果你对于在不同系统设置环境变量有疑问的话,可以查看这两篇文章
Windows 系统如何设置临时环境变量(命令行方式)
Linux中的export 设置的环境变量是临时的吗?如何永久生效?
新建一个llm_use.py文件
开始使用langchain来编写一个简单调用LLM大模型的python代码:
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
import os
#获取环境变量
url = os.environ.get('base_url')
api_key = os.environ.get('OPENAI_API_KEY')
#初始化模型
llm = ChatOpenAI(openai_api_key=api_key,model="deepseek-v3",base_url=url)
#根据message创建一个提示模版 system消息是告诉模型扮演什么角色,user消息是代表用户输入的问题
prompt = ChatPromptTemplate.from_messages([
("system","你是一名Langchain使用专家"),
("user","{input}")
])
#基于LCEL表达式构建LLM链,该表达式类似于linux的pieline语法,从左到右按顺序执行
#首先执行prompt完成提示词模版填充,再将提示词去调用大模型
chain = prompt | llm
#调用链
# invoke将调用参数传递到prompt提示模版,然后开始按照chain定义的步骤运行
response =chain.invoke({"input":"使用langchain,需要安装哪些包"})
#大模型返回的结果
print(response.content)
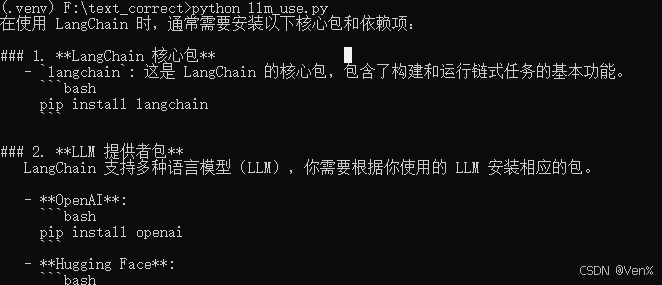
运行.py文件
python llm_use.py
输出示例:


















 50
50

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











