







1. DWA算法简介
DWA算法全称为dynamic window approach,其原理主要是在速度空间 ( v , w ) (v, w) (v,w)中采样多组速度,并模拟在这些速度下一定时间内的运动轨迹。在得到多组轨迹以后,通过一个评价函数对这些轨迹进行评价,选出最优轨迹对应的速度来驱动机器人运动。该算法突出点在于动态窗口这个名词,它的含义是依据移动机器人的加减速性能限定速度采样空间在一个可行的动态范围内。
2. 速度空间
速度空间 ( v , w ) (v,w) (v,w),即机器人的速度范围,机器人的速度受到各种因素的限制
- 移动机器人受自身最大速度和最小速度的限制
- 移动机器人受电机性能的影响:
由于电机力矩有限,存在最大的加减速度限制。因此移动机器人轨迹前向模拟的周期内,存在一个动态窗口,在该窗口内的速度是机器人能够实际到达的速度。 - 移动机器人受障碍物的影响:
基于移动机器人安全考虑,为了能够在碰撞障碍物前停下来,因此在最大减速度条件下,速度有一个范围。
在上述三个约束条件下,速度空间 ( v , w ) (v,w) (v,w)会有一定的范围,注意速度空间不是固定不变的,而是时变的, t t t时刻的速度与 t + δ t t+\delta_t t+δt时刻的速度空间是不同的,故将其成为动态窗口。
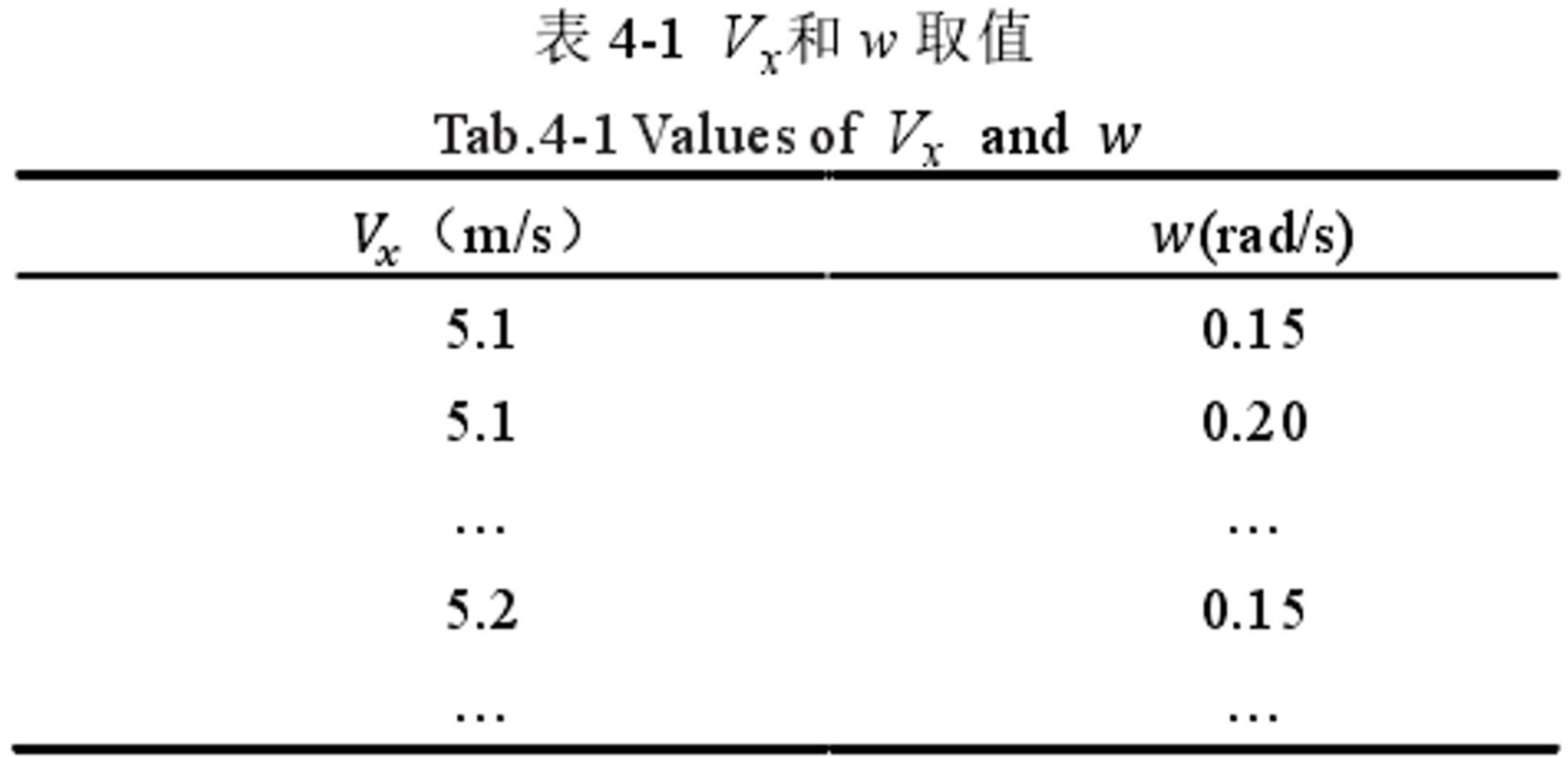
3. 速度采样
得到 t 时刻的速度空间 ( v , w ) (v,w) (v,w)后,以一定的分辨率对速度 v v v和角速度 w w w进行采样:
设 t 时刻小车 x 轴线速度取值范围 5~20m/s,为简化数学模型,设 y 轴线速度为 0m/s,小车的角度速取值范围 0.1~1rad/s,小车的线速度的速度分辨率为0.1m/s,角速度的速度分辨率为0.05rad/s。
4. 机器人的运动学模型
在动态窗口算法中,要模拟机器人的轨迹,需要知道机器人的运动模型。这里举例两种常见的机器人模型:非全向移动和全向移动。
4.1 非全向移动机器人模型
差速运动模型,只能纵向和旋转运动
(
v
t
,
w
t
)
(v_t, w_t)
(vt,wt)。计算机器人轨迹时,先考虑两个相邻时刻,如下图所示。为简单起见,由于机器人相邻时刻(一般码盘采样周期ms计)内,运动距离短,因此可以将两相邻点之间的运动轨迹看成直线,即沿机器人坐标系x轴移动了
v
t
∗
Δ
t
v_t*\Delta_t
vt∗Δt。只需将该段距离分别投影在世界坐标系x轴和y轴上就能得到
t
+
1
t+1
t+1时刻机器人在世界坐标系中坐标移动的位移
Δ
t
和
Δ
y
\Delta_t和\Delta_y
Δt和Δy。
Δ
x
=
v
Δ
t
c
o
s
(
θ
t
)
Δ
y
=
v
Δ
t
s
i
n
(
θ
t
)
\Delta_x = v\Delta_t cos(\theta_t) \\ \Delta_y = v\Delta_t sin(\theta_t)
Δx=vΔtcos(θt)Δy=vΔtsin(θt)
以此类推,如果你想推算一段时间内的轨迹,只需要将这段时间内的位移增量累计求和就行了:
x
=
x
+
v
Δ
t
c
o
s
(
θ
t
)
y
=
y
+
v
Δ
t
s
i
n
(
θ
t
)
θ
t
=
θ
t
+
w
Δ
t
x = x + v\Delta_t cos(\theta_t) \\ y = y + v\Delta_t sin(\theta_t)\\ \theta_t = \theta_t + w\Delta_t
x=x+vΔtcos(θt)y=y+vΔtsin(θt)θt=θt+wΔt
4.2 全向移动机器人
如果机器人是全向运动,有y轴速度,只需将机器人在机器人世界坐标y轴移动的距离投影到世界坐标系即可:
Δ
x
=
v
y
Δ
t
c
o
s
(
θ
t
+
π
2
)
=
−
v
y
Δ
t
s
i
n
(
θ
t
)
Δ
y
=
v
y
Δ
t
s
i
n
(
θ
t
+
π
2
)
=
v
y
Δ
t
c
o
s
(
θ
t
)
\Delta_x = v_y\Delta_t cos(\theta_t + \frac{\pi}{2}) = -v_y\Delta_t sin(\theta_t)\\ \Delta_y = v_y\Delta_t sin(\theta_t + \frac{\pi}{2}) = v_y\Delta_t cos(\theta_t)
Δx=vyΔtcos(θt+2π)=−vyΔtsin(θt)Δy=vyΔtsin(θt+2π)=vyΔtcos(θt)
此时的轨迹推演只需要将y轴移动的距离叠加在之前的计算公式上即可:
x
=
x
+
v
Δ
t
c
o
s
(
θ
t
)
−
v
y
Δ
t
s
i
n
(
θ
t
)
y
=
y
+
v
Δ
t
s
i
n
(
θ
t
)
+
v
y
Δ
t
c
o
s
(
θ
t
)
θ
t
=
θ
t
+
w
Δ
t
x = x + v\Delta_t cos(\theta_t) -v_y\Delta_t sin(\theta_t) \\ y = y + v\Delta_t sin(\theta_t) + v_y\Delta_t cos(\theta_t)\\ \theta_t = \theta_t + w\Delta_t
x=x+vΔtcos(θt)−vyΔtsin(θt)y=y+vΔtsin(θt)+vyΔtcos(θt)θt=θt+wΔt
机器人的轨迹运动模型有了,根据速度就可以推算出轨迹,因此只需采样很多速度,推算轨迹,然后评价这些轨迹好不好就行了。
5. 轨迹预测
在确定机器人的采样速度和运动模型后,可以对机器人的状态进行预测和更新
- 机器人下一时刻位移距离
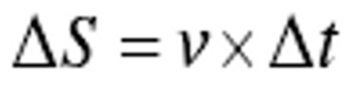
- 机器人下一时刻坐标变化

- 采样时刻机器人坐标与坐标变化就和,得到下一时刻机器人坐标
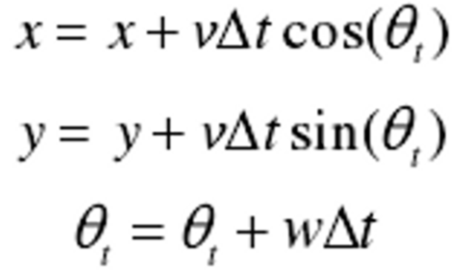
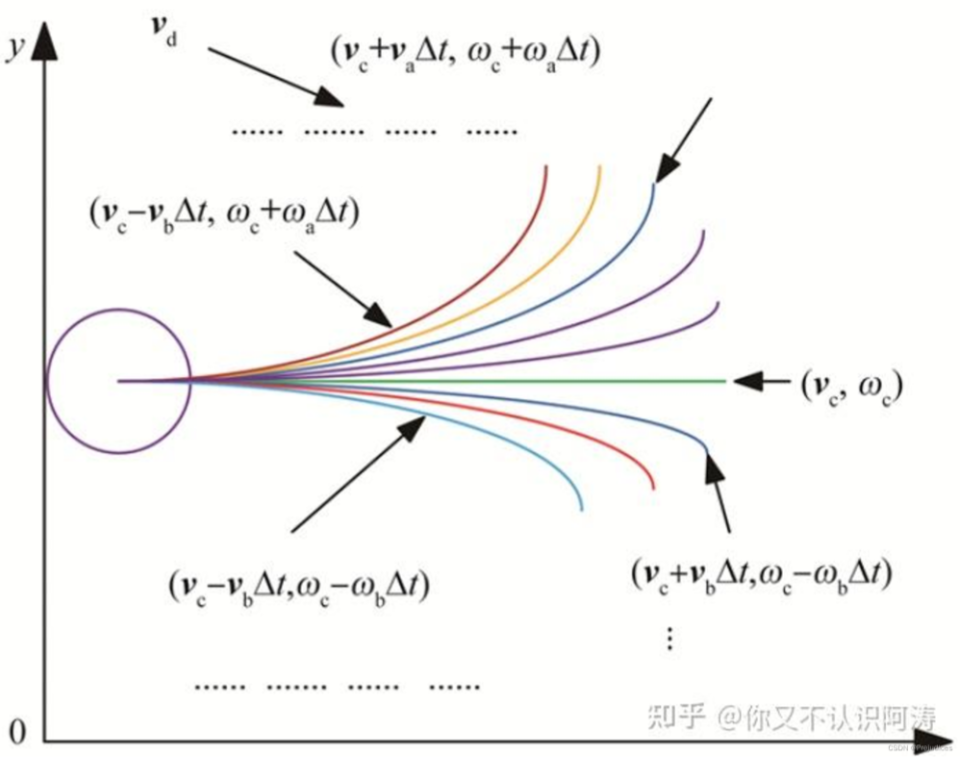
设 Δ t \Delta_t Δt为0.1s,实际上预测机器人前向几秒内的所有状态,假设前向预测时间为3s,则会预测t~t+3 s 内的所有状态,即 t ∼ t + Δ t , t ∼ t + 2 ∗ Δ t , t ∼ t + 3 ∗ Δ t , . . . , t ∼ t + 3 t \sim t + \Delta_t, t \sim t +2* \Delta_t,t \sim t + 3*\Delta_t,...,t \sim t + 3 t∼t+Δt,t∼t+2∗Δt,t∼t+3∗Δt,...,t∼t+3,相对于会预测出 t 时刻位置前30个点的位置,如下图所示。
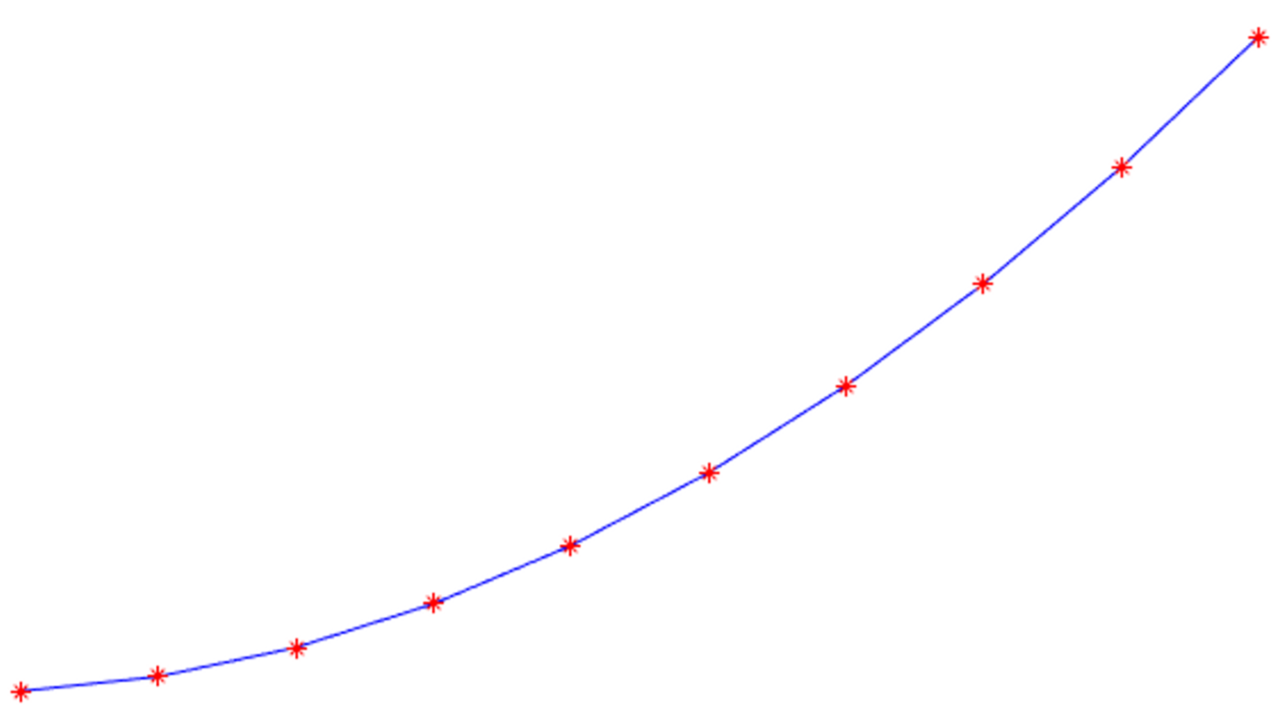
6.评价函数
对速度空间进行采样后,根据机器人运动学模型能够预测出多条轨迹,需要对这些轨迹进行评价,选取最优的轨迹,机器人根据最优轨迹对应的速度进行运动。
DWA算法对轨迹的评价函数一般如下:
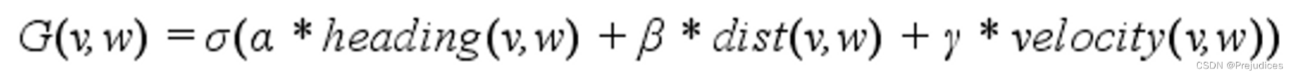
- h e a d i n g ( v , w ) heading(v,w) heading(v,w)为方位角评价函数:评价机器人在当前的设定的速度下,预测轨迹末端朝向于目标点之间的角度差距;
- d i s t ( v , w ) dist(v,w) dist(v,w)主要意义为机器人处于预测轨迹末端点位置时与地图上最近障碍物的距离,对于靠近障碍物的采样点进行惩罚,确保机器人的避障能力,降低机器人与障碍物发生碰撞的概率;
- v e l o c i t y ( v , w ) velocity(v,w) velocity(v,w)为当前机器人速度的线速度,为了促进机器人快速到达目标;
- α , β , γ , δ \alpha,\beta,\gamma,\delta α,β,γ,δ为权重系数。
评价函数的目标:
- 希望前进方向对准目标点;
- 希望不发生碰撞;
- 希望速度尽可能快;
- 除此之外,还要保证最短刹车距离是安全的。
原文中提到方位角评价函数对轨迹规划的影响较大,太大容易陷入局部最优解,太小能更好地避障,但路径有点长,效率比较低。当然也可以对评价函数进行优化,添加更多的评价函数指标。
DWA算法的完整流程图
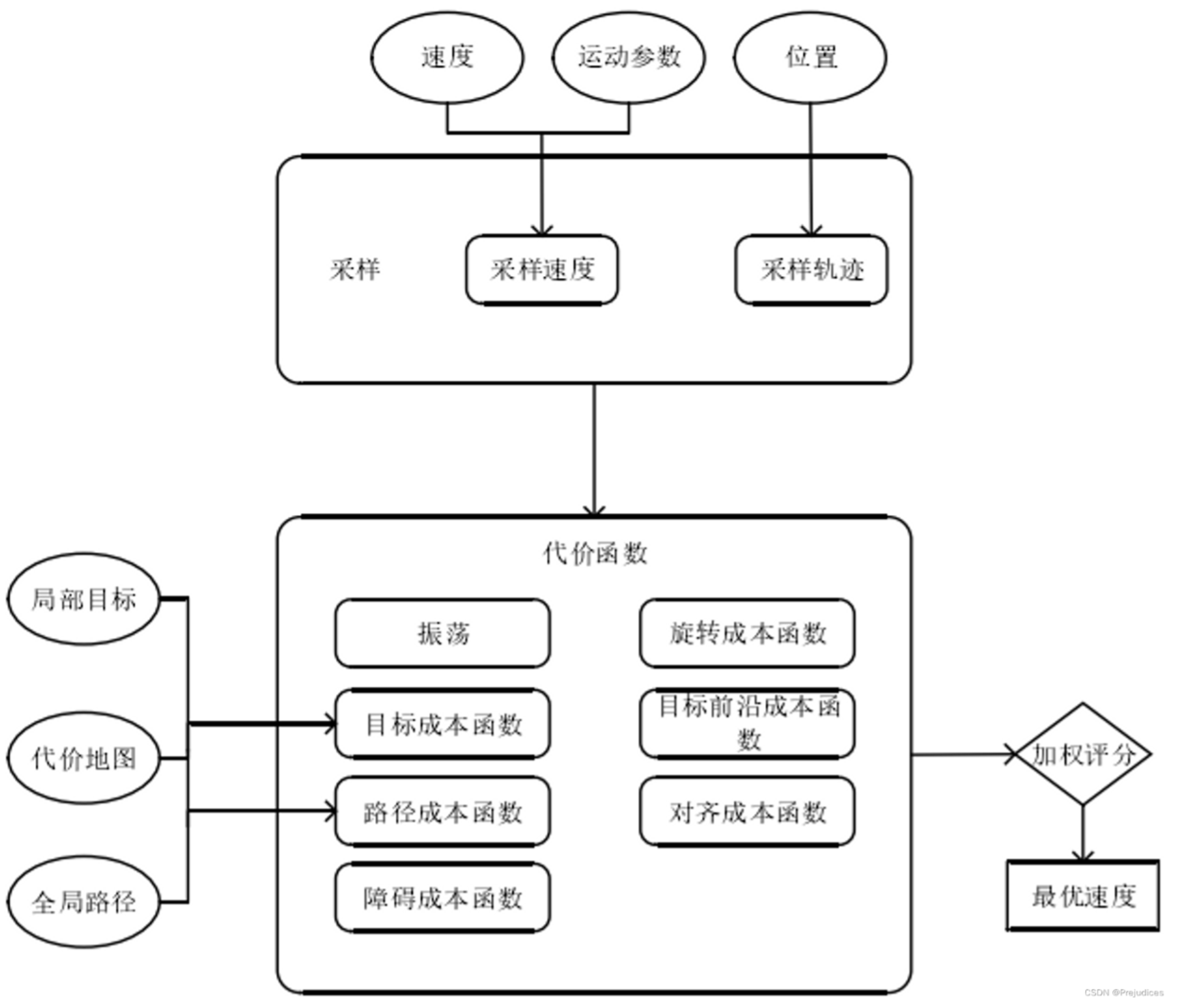
7. 优缺点
7.1 优点
- 计算效率高,实现简单,适用于资源有限的系统
7.2 缺点
- 可能陷入局部最小值,依赖对周边环境的感知能力,需要经过精细调整,才能在不同场景下达到最佳性能,且在高度动态环境时有局限性;
- 避障效率不高;
- 动态避障能力弱;
- 遇到稠密障碍物区外侧绕行;
- 易困于C型(凹形)障碍物。
参考
-
基于DAV_DWA算法的农业机器人局部路径规划研究


















 4214
4214

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











