





原文:Zhang H, Li F, Liu S, et al. Dino: Detr with improved denoising anchor boxes for end-to-end object detection[J]. arXiv preprint arXiv:2203.03605, 2022.
源码:https://github.com/IDEACVR/DINO
我们提出了一种新的端到端目标检测器DINO,它在性能和效率上均优于以往的DETR类模型,主要得益于以下三点:对比去噪训练、用于锚框初始化的混合query选择、用于边框预测的look forward twice方案。DINO使用ResNet-50和多尺度特征在COCO上实现了49.4 AP(12轮)和51.3 AP(24轮)的成绩,与之前最好的DETR类模型DN-DETR相比,分别涨点6.0 AP和2.7 AP。DINO在模型大小和数据大小方面都具有良好的可扩展性。在不使用花哨技巧的情况下,DINO使用Swin-L骨干网络在Objects365数据集上进行预训练后,在COCO val2017和test-dev数据集上获得了最佳结果,分别是63.2 AP和63.3 AP。与目标检测排行榜上的其他模型相比,DINO在获得更好结果的同时,显著减小了模型大小和预训练数据大小。
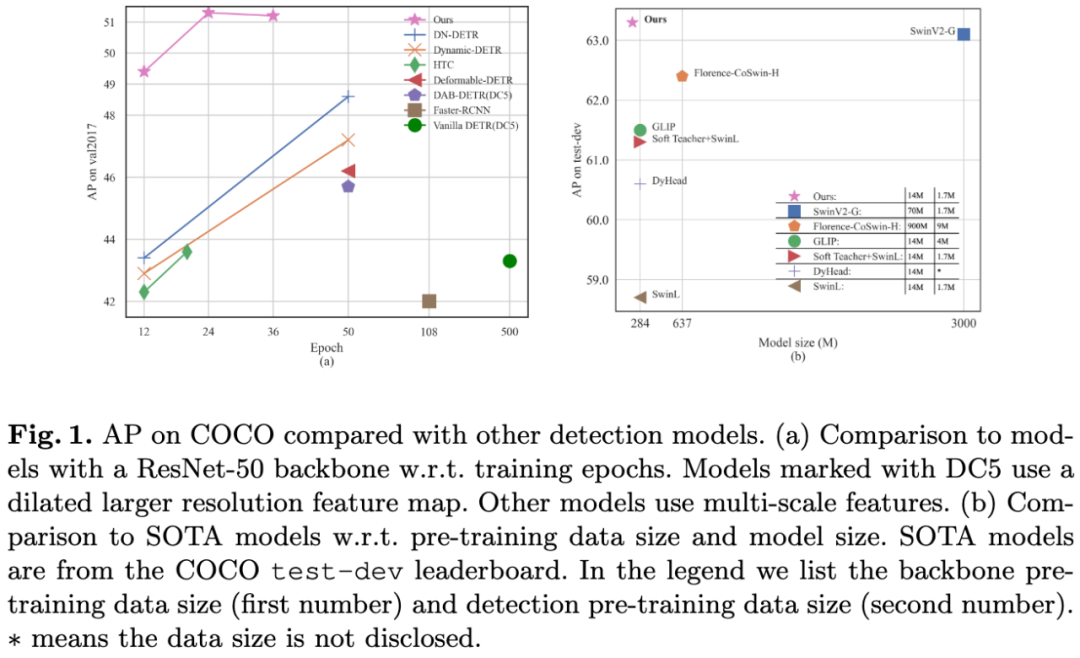
图1:在COCO数据集上,DINO与其他模型结果的比较。
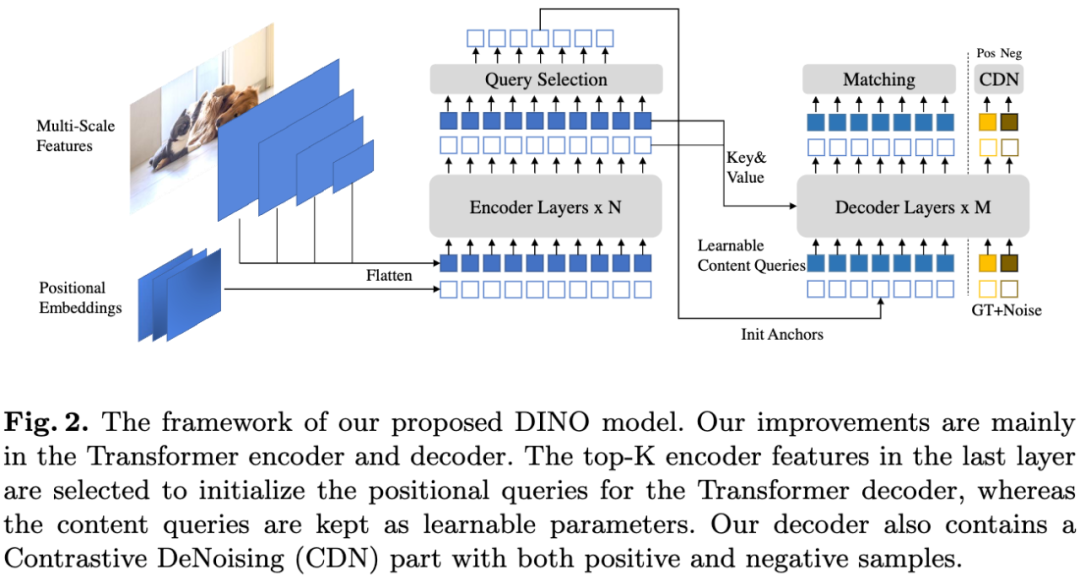
图2:DINO模型的框架。我们的改进主要在Transformer编码器和解码器方面。我们选择最后一层中的top-K编码器特征来初始化Transformer解码器的位置queries,而内容queries保持为可学习的参数。我们的解码器还包含一个对比去噪(CDN)部分。
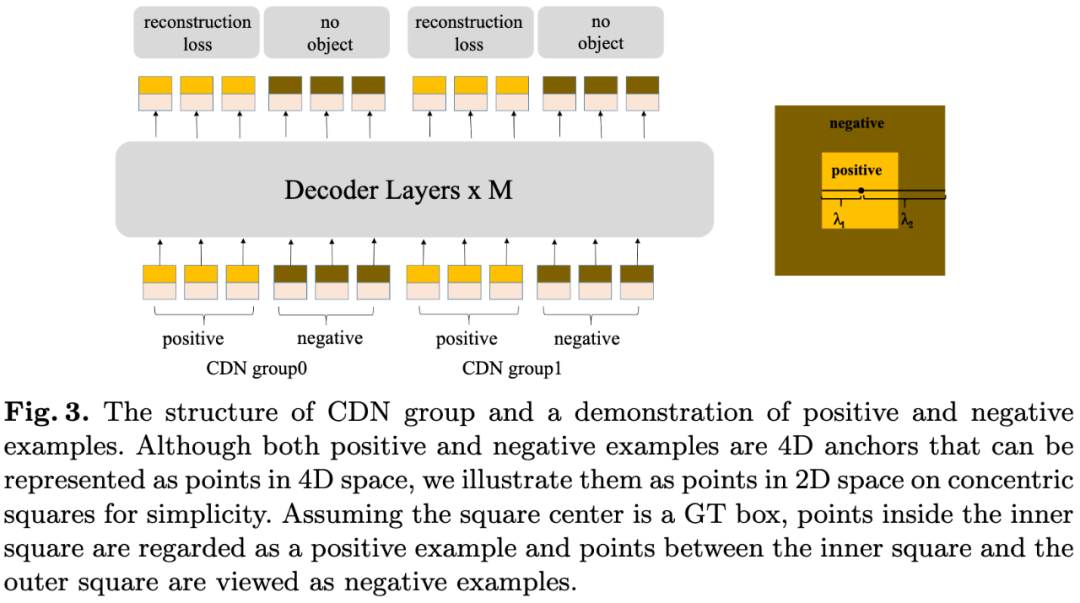
图3:CDN group的结构和正负例的演示。
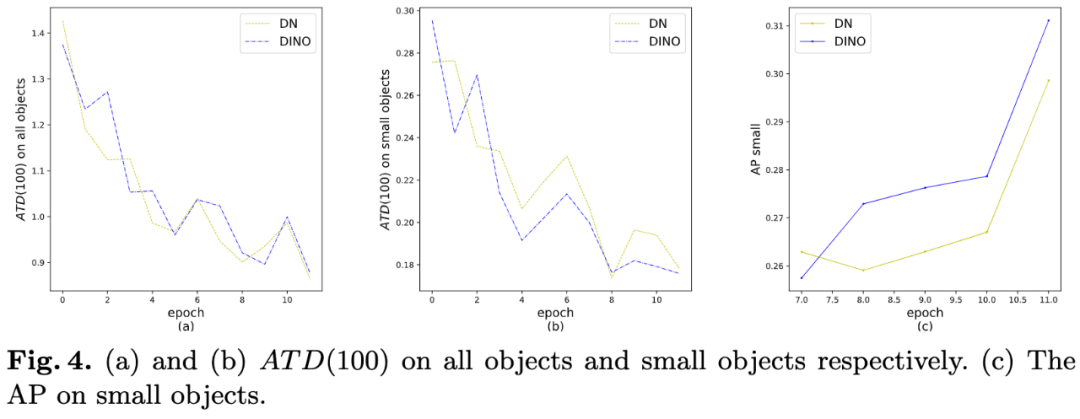
图4:(a)和(b)分别是全部物体和小物体上的ATD(100)值。(c)是小物体上的AP值。
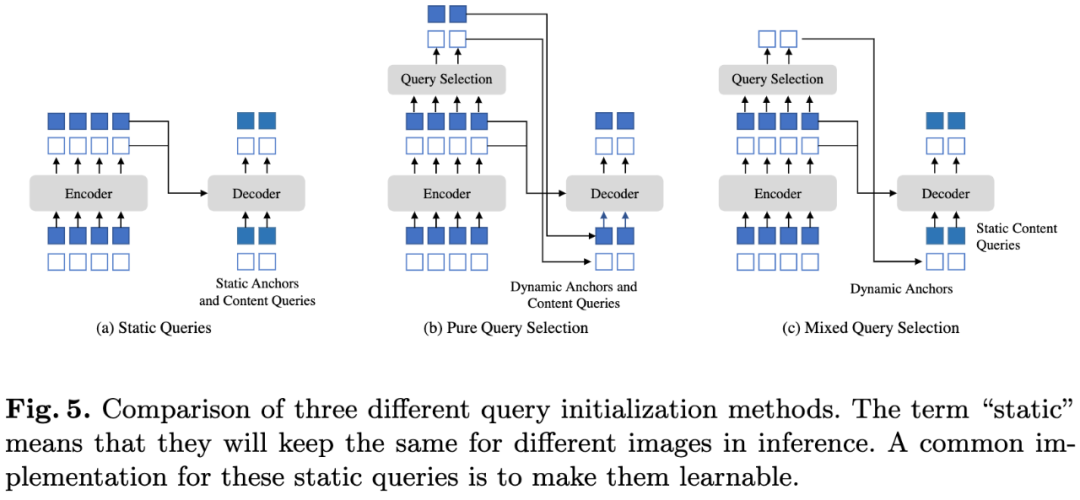
图5:三种query初始化方法的比较。
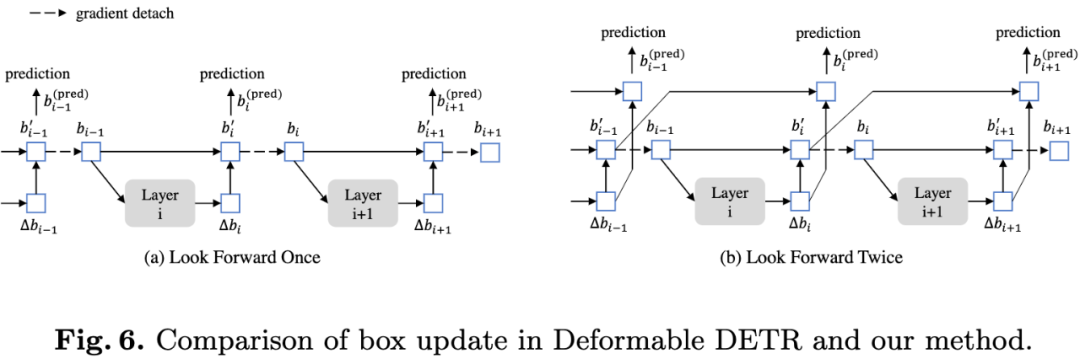
图6:Deformable DETR和DINO边框更新方法的比较。
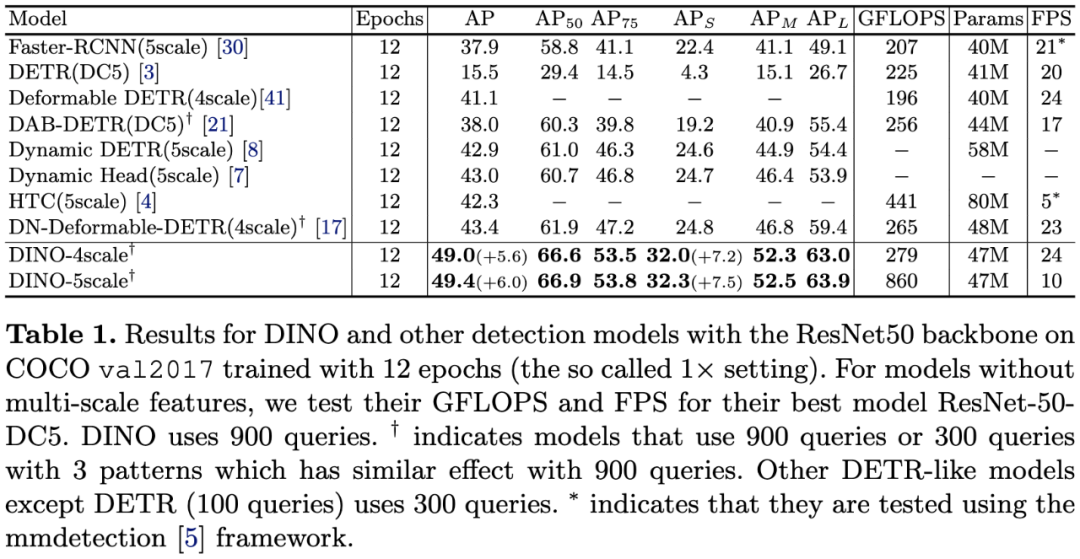
表1:在COCO val2017数据集上,DINO和其他检测模型结果的比较(使用ResNet-50骨干网络,训练12轮)。
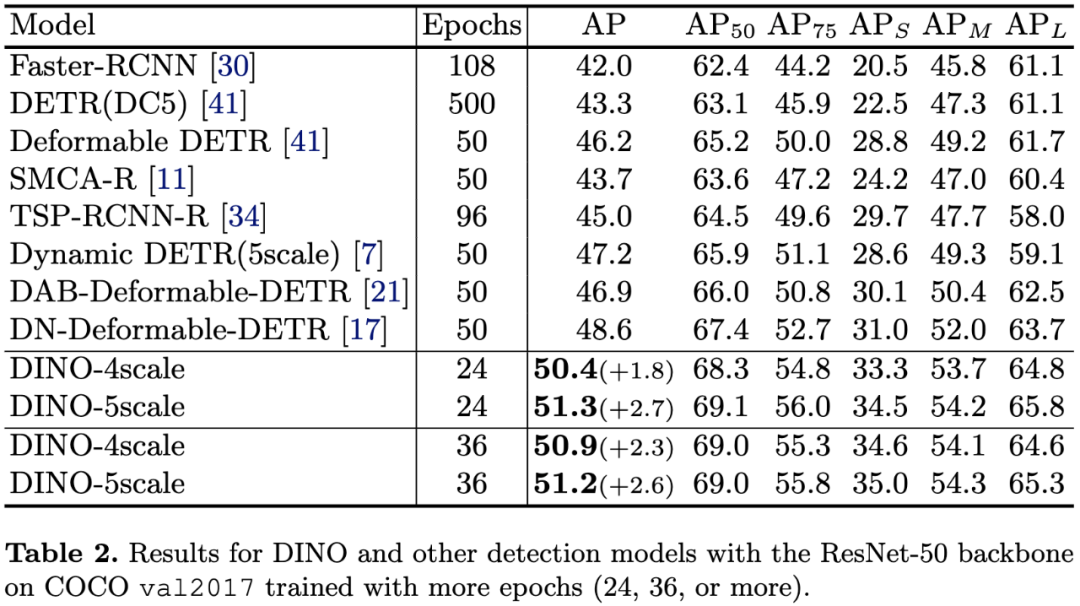
表2:在COCO val2017数据集上,DINO和其他检测模型结果的比较(使用ResNet-50骨干网络,训练更多轮)。
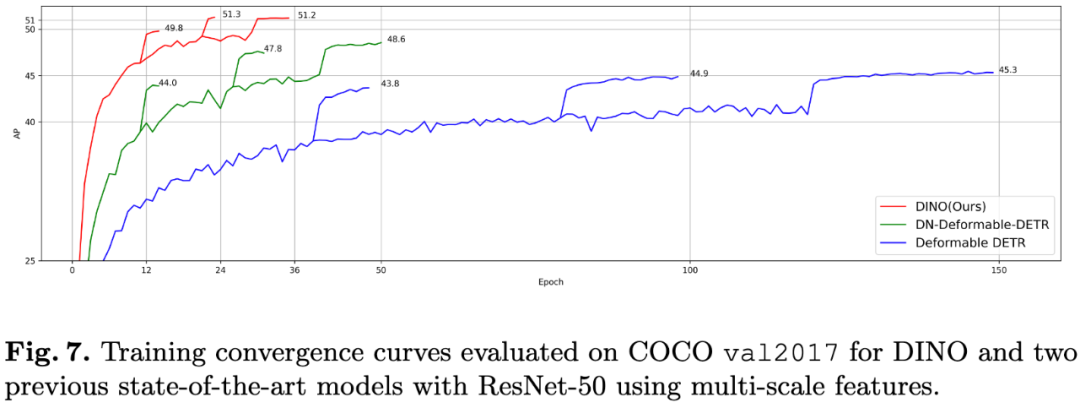
图7:在COCO val2017数据集上,DINO和其他两个检测模型的训练收敛曲线(使用ResNet-50骨干网络和多尺度特征)。

表3:MS-COCO上最佳检测模型的比较。
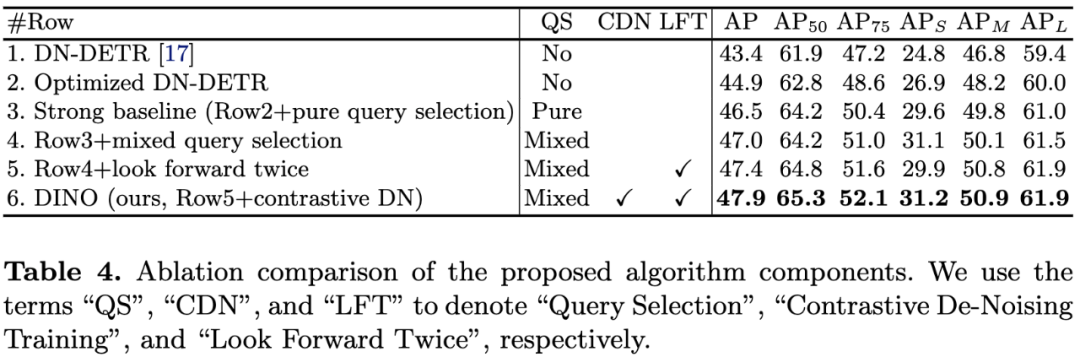
表4:算法组件的消融研究。QS、CDN、LFT分别表示Query Selection、Contrastive De-Noising Training、Look Forward Twice。

图8:左图是使用DN queries训练的模型的检测结果,右图是DINO的结果。在左图中,箭头所指的男孩有3个重复的边框。
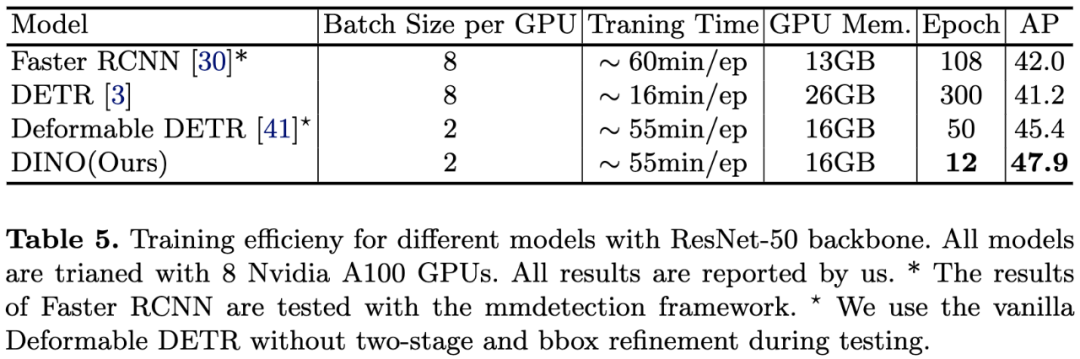
表5:不同模型的训练效率(使用ResNet-50骨干网络)。所有模型均使用8块Nvidia A100 GPU进行测试。

表6:编码器/解码器层数的消融研究。

表7:去噪queries数量的消融研究。
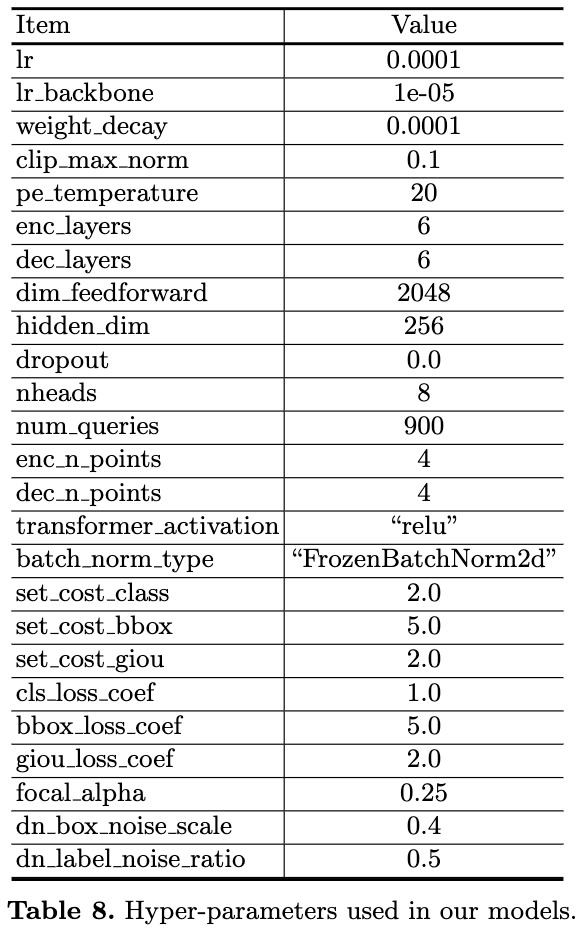
表8:DINO模型中使用的超参数。
在本文中,我们提出了一种强大的端到端Transformer检测器DINO,借助contrastive denoising training、mixed query selection、look forward twice方法,大大提高了模型的训练效率和检测性能。我们进一步尝试在更大的数据集上用更强的骨干网络训练DINO,并在COCO 2017 test-dev数据集上达到了新的SOTA水平,63.3 AP。
多模态人工智能
为人类文明进步而努力奋斗^_^↑
欢迎关注“多模态人工智能”公众号^_^↑

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









