







Bertopic主题模型原理详解 – 潘登同学的NLP笔记
文章目录
Bertopic主题建模
BERTopic 是一种主题建模技术,它利用 Transformer 和 c-TF-IDF 来创建密集的集群,允许轻松解释主题,同时在主题描述中保留重要词。

该算法包含3个阶段
- Embed documents: 使用 BERT 或任何其他嵌入技术提取文档嵌入向量
- Cluster Documents:
- 使用UMAP对向量降维(同时保留位置信息)
- 使用HDBSCAN算法去聚类
- Create topic representation(得到主题表示)
- 使用 c-TF-IDF 提取主题词和减少主题数量
- 使用最大边际相关性提高单词的连贯性和多样性
相关的算法都在下面列举了详细步骤,最重要的是把这些东西串起来
- 先将整篇文档输入bert中,得到一篇文档的词向量
- 对这些词向量运用UMAP进行降维,得到低维词向量
- 对低维词向量进行聚类,得到聚好类的文档
- 对聚好类的文档采用 c − T F − I D F c-TF-IDF c−TF−IDF得到各个主题的主题词
- 对这些主题词进行采用最大边际相关性算法进行筛选
Nearest-Neighbor-Descent (构建K近邻图)
暴力构建K近邻图的时间复杂度为 O ( n 2 ) O(n^2) O(n2)(分别计算点的两两之间的距离),为了能更高效的构建K近邻图,现存的工作扩展性都不太好,而且一般都特定于具体的相似性度量;
有效的K近邻图构建仍然是一个开放的问题,解决该问题的已知方案中没有一个是通用、有效和可扩展的,因此提出了NN-Descent方法,该方法具有以下优点:
- 通用。适用于任意的相似性度量准则。
- 可扩展。随着数据集尺寸的增加,Recall仅有很小的下降。由于对每一个数据点的局部信息进行操作,因此适用于分布式计算环境
- 节省空间。整个构建过程仅涉及到一种数据结构——近邻图。
- 快速、精确。百分之几的相似性比较便可实现90%以上的召回率。
算法详解
理论推导
先声明一些概念:
- V V V表示数据集,数据集的尺寸为 N = ∣ V ∣ N=|V| N=∣V∣,相似性度量 σ : V × V → R \sigma: V \times V \to R σ:V×V→R;
- ∀ v ∈ V , B K ( v ) \forall v \in V, B_K(v) ∀v∈V,BK(v)表示 v v v的 K K K个最近邻, R K ( v ) = { u ∈ V ∣ v ∈ B K ( u ) } R_K(v)=\{u\in V|v \in B_K(u)\} RK(v)={u∈V∣v∈BK(u)}表示 v v v的反向 K K K个最近邻。
- B [ v ] B[v] B[v]和 R [ v ] R[v] R[v]分别表示 B K ( v ) B_K(v) BK(v)和 R K ( v ) R_K(v) RK(v)的近似, B ˉ [ v ] = B [ v ] ∪ R [ v ] \bar{B}[v] = B[v] \cup R[v] Bˉ[v]=B[v]∪R[v]表示 v v v的一般邻居;
当
V
V
V在度量方式为距离度量时,即
d
:
V
×
V
→
[
0
,
+
∞
]
d: V \times V \to [0, +\infty]
d:V×V→[0,+∞],
∀
r
∈
[
0
,
+
∞
]
\forall r \in [0, +\infty]
∀r∈[0,+∞],以
v
v
v为球心的r-球定义为:
B
r
(
v
)
=
{
u
∈
V
∣
d
(
u
,
v
)
≤
r
}
B_r(v) = \{u \in V|d(u,v)\leq r\}
Br(v)={u∈V∣d(u,v)≤r}; 如果存在常量
c
c
c,使得
∣
B
2
r
(
v
)
∣
≤
c
∣
B
r
(
v
)
∣
|B_{2r}(v)| \leq c|B_{r}(v)|
∣B2r(v)∣≤c∣Br(v)∣
则称度量空间
V
V
V增长受限,
c
c
c是增长常量
基本思想:邻居的邻居更可能是邻居。
理论推导
我们可以从 V V V中每一个点的现有的近似K近邻出发,通过探索该点邻居的邻居(在当前近似K近邻中)而不断完善该点的K近邻。换句话说,可从粗略的K近邻图出发通过改进而不断完善它。对这一观点的量化表达如下:
- 令 K = C 3 K = C^3 K=C3(后面公式推导要用到, K K K这样取值是为了方便), 假定已有的近似K近邻图为 B B B(可以是随机给每个点选邻居构建的)
- ∀ v ∈ V , B ′ [ v ] = ∪ v ′ ∈ B [ v ] B [ v ′ ] \forall v \in V, B'[v] = \cup_{v'\in B[v]}B[v'] ∀v∈V,B′[v]=∪v′∈B[v]B[v′]表示 v v v所有邻居的邻居集合,它也是在完善 v v v的K近邻的时候的选点集。
- 当 B B B的精度比较高时(迭代完善了一定次数或通过更好的方法初始化 B B B),高到什么程度呢? 就是给定一个固定的半径r,对 ∀ v ∈ V \forall v \in V ∀v∈V, B [ v ] B[v] B[v]包含的K的邻居均匀的分布在 B r ( v ) B_r(v) Br(v)中。 这样的话,当各事件相互独立且 K < < ∣ B r / 2 ( v ) ∣ K << |{B_{r/2}(v)}| K<<∣Br/2(v)∣时, B ′ [ v ] B'[v] B′[v]很可能包含在 B r / 2 ( v ) B_{r/2}(v) Br/2(v)中的K个邻居中。 换句话说,对 ∀ v ∈ V \forall v \in V ∀v∈V,通过搜索 B ′ [ v ] B'[v] B′[v]来使 v v v到它的近似K近邻的距离减半。
对 B r / 2 ( v ) B_{r/2}(v) Br/2(v)中的一点 u u u,要从 B ′ [ v ] B'[v] B′[v]中找到,则至少存在一点 v ′ v' v′,使得 v ′ ∈ B [ v ] v'\in B[v] v′∈B[v],且 u ∈ B [ v ′ ] u\in B[v'] u∈B[v′]。 接下来我们只需要找到满足上述条件的 v ′ v' v′即可。而若 v ′ ∈ B r / 2 ( v ) v'\in B_{r/2}(v) v′∈Br/2(v),则有以下几个不等式成立:
- v ′ ∈ B r / 2 ( v ) v'\in B_{r/2}(v) v′∈Br/2(v),因此有, P { v ′ ∈ B [ v ] } ≥ K ∣ B r ( v ) ∣ P\{v'\in B[v]\}\geq \frac{K}{|B_r(v)|} P{v′∈B[v]}≥∣Br(v)∣K (解释: 因为 v ′ ∈ B r / 2 ( v ) v'\in B_{r/2}(v) v′∈Br/2(v),则 v ′ ∈ B r ( v ) v' \in B_r(v) v′∈Br(v)必然成立。 若 v v v的 K K K个邻居都在 B r ( v ) B_r(v) Br(v)中取的话,则一共有 C B r ( v ) K C_{B_r(v)}^K CBr(v)K种情况,而 B r ( v ) B_r(v) Br(v)中的一点不是 v v v的邻居的情况有 C ∣ B r ( v ) ∣ − 1 K C_{|B_r(v)|-1}^K C∣Br(v)∣−1K种; 因此 B r ( v ) B_r(v) Br(v)中的一点是 v v v的邻居的概率为 1 − C B r ( v ) K C ∣ B r ( v ) ∣ − 1 K 1-\frac{C_{B_r(v)}^K}{C_{|B_r(v)|-1}^K} 1−C∣Br(v)∣−1KCBr(v)K,即为 K ∣ B r ( v ) ∣ \frac{K}{|B_r(v)|} ∣Br(v)∣K。 B r / 2 ( v ) B_{r/2}(v) Br/2(v)中的一点更可能是 v v v的邻居,故 v ′ v' v′是 v v v的邻居的概率大于等于 K ∣ B r ( v ) ∣ \frac{K}{|B_r(v)|} ∣Br(v)∣K)
- d ( u , v ′ ) ≤ d ( u , v ) + d ( v , v ′ ) ≤ r d(u,v') \leq d(u,v) + d(v,v') \leq r d(u,v′)≤d(u,v)+d(v,v′)≤r,因此, P { u ∈ B [ v ′ ] } ≥ K ∣ B r ( v ′ ) ∣ P\{u\in B[v']\}\geq \frac{K}{|B_r(v')|} P{u∈B[v′]}≥∣Br(v′)∣K (解释: 由第一条推论可知, B r ( v ‘ ) B_r(v‘) Br(v‘)中的一点是 v ’ v’ v’的邻居的概率为 K ∣ B r ( v ‘ ) ∣ \frac{K}{|B_r(v‘)|} ∣Br(v‘)∣K,而 u 与 v ′ u与v' u与v′的距离小于 r r r,故 u u u是 v ′ v' v′的邻居的概率大于等于 K ∣ B r ( v ‘ ) ∣ \frac{K}{|B_r(v‘)|} ∣Br(v‘)∣K)
- ∣ B r ( v ) ∣ ≤ c ∣ B r / 2 ( v ) ∣ |B_{r}(v)| \leq c|B_{r/2}(v)| ∣Br(v)∣≤c∣Br/2(v)∣,且 ∣ B r ( v ′ ) ∣ ≤ c ∣ B r / 2 ( v ′ ) ∣ ≤ c ∣ B r ( v ) ∣ ≤ c 2 ∣ B r / 2 ( v ) ∣ |B_{r}(v')| \leq c|B_{r/2}(v')| \leq c|B_{r}(v)| \leq c^2|B_{r/2}(v)| ∣Br(v′)∣≤c∣Br/2(v′)∣≤c∣Br(v)∣≤c2∣Br/2(v)∣(解释: 重点是 ∣ B r / 2 ( v ′ ) ∣ ≤ ∣ B r ( v ) ∣ |B_{r/2}(v')| \leq |B_{r}(v)| ∣Br/2(v′)∣≤∣Br(v)∣,这个不等式可以根据下图来理解,由于 v ′ v' v′在 v v v的 r / 2 r/2 r/2-球中, v ′ v' v′的 r / 2 r/2 r/2-球一定包含于 v v v的 r r r-球中)
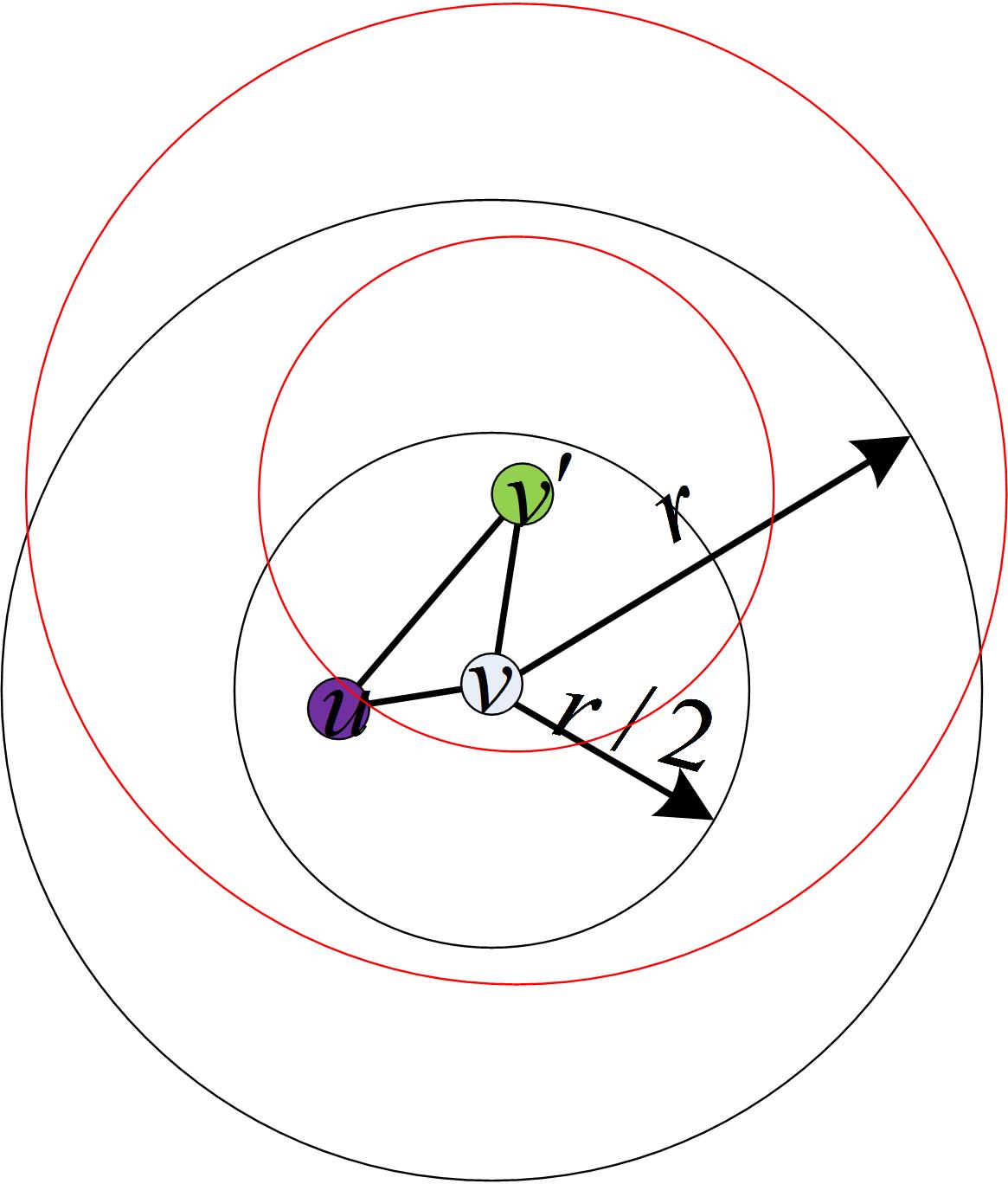
由以上3个不等式
- P { v ′ ∈ B [ v ] } ≥ K ∣ B r ( v ) ∣ P\{v'\in B[v]\}\geq \frac{K}{|B_r(v)|} P{v′∈B[v]}≥∣Br(v)∣K
- P { u ∈ B [ v ′ ] } ≥ K ∣ B r ( v ′ ) ∣ P\{u \in B[v']\}\geq \frac{K}{|B_r(v')|} P{u∈B[v′]}≥∣Br(v′)∣K
- ∣ B r ( v ) ∣ ≤ c ∣ B r / 2 ( v ) ∣ |B_{r}(v)| \leq c|B_{r/2}(v)| ∣Br(v)∣≤c∣Br/2(v)∣ ∣ B r ( v ′ ) ∣ ≤ c 2 ∣ B r / 2 ( v ) ∣ |B_{r}(v')| \leq c^2|B_{r/2}(v)| ∣Br(v′)∣≤c2∣Br/2(v)∣
假定的各个事件独立性可得:
P
{
v
′
∈
B
[
v
]
∧
u
∈
B
[
v
′
]
}
≥
K
2
∣
B
r
(
v
)
∣
∣
B
r
(
v
′
)
∣
≥
K
2
∣
B
r
(
v
)
∣
∣
B
r
(
v
′
)
∣
≥
K
2
c
∣
B
r
/
2
(
v
)
∣
c
2
∣
B
r
/
2
(
v
)
∣
=
K
∣
B
r
/
2
(
v
)
∣
2
P\{v'\in B[v] \land u \in B[v'] \} \geq \frac{K^2}{|B_r(v)||B_r(v')|} \geq \frac{K^2}{|B_r(v)||B_r(v')|} \geq \frac{K^2}{c|B_{r/2}(v)|c^2|B_{r/2}(v)|} = \frac{K}{|B_{r/2}(v)|^2}
P{v′∈B[v]∧u∈B[v′]}≥∣Br(v)∣∣Br(v′)∣K2≥∣Br(v)∣∣Br(v′)∣K2≥c∣Br/2(v)∣c2∣Br/2(v)∣K2=∣Br/2(v)∣2K
(因为前面假设了
K
=
c
3
K=c^3
K=c3)
上式的意义就是,对于 B r / 2 [ v ] B_{r/2}[v] Br/2[v]中确定的点 v ′ v' v′,它既是 v v v的邻居又是 u u u的反向邻居的概率大于等于 K ∣ B r / 2 ( v ) ∣ 2 \frac{K}{|B_{r/2}(v)|^2} ∣Br/2(v)∣2K。
因此,当
v
v
v的邻居从
B
r
/
2
(
v
)
B_{r/2}(v)
Br/2(v)中取时,在
B
r
/
2
(
v
)
B_{r/2}(v)
Br/2(v)中的一点
u
u
u属于
v
v
v的邻居的邻居的概率为
P
{
u
∈
B
[
v
′
]
}
≥
1
−
(
1
−
K
∣
B
r
/
2
(
v
)
∣
2
)
∣
B
r
/
2
(
v
)
∣
≈
K
∣
B
r
/
2
(
v
)
∣
(
∗
)
P\{u \in B[v'] \} \geq 1 - (1-\frac{K}{|B_{r/2}(v)|^2})^{|B_{r/2}(v)|} \approx \frac{K}{|B_{r/2}(v)|} \qquad (*)
P{u∈B[v′]}≥1−(1−∣Br/2(v)∣2K)∣Br/2(v)∣≈∣Br/2(v)∣K(∗)
解释: 先考虑
u
u
u不是
v
v
v的邻居的概率,此时,从
B
r
/
2
(
v
)
B_{r/2}(v)
Br/2(v)中取出一点设为
x
x
x,
x
x
x不是
v
v
v的邻居或者
u
u
u不是
x
x
x的邻居,发生这种情况的概率(根据上上式)为
1
−
K
∣
B
r
/
2
(
v
)
∣
2
1-\frac{K}{|B_{r/2}(v)|^2}
1−∣Br/2(v)∣2K,而
B
r
/
2
(
v
)
B_{r/2}(v)
Br/2(v)中一共有
∣
B
r
/
2
(
v
)
∣
|B_{r/2}(v)|
∣Br/2(v)∣个点,它们都不满足上述情况的概率为
(
1
−
K
∣
B
r
/
2
(
v
)
∣
2
)
∣
B
r
/
2
(
v
)
∣
(1-\frac{K}{|B_{r/2}(v)|^2})^{|B_{r/2}(v)|}
(1−∣Br/2(v)∣2K)∣Br/2(v)∣,这就是
u
u
u不是
v
v
v的邻居的邻居的概率,从而
u
u
u是
v
v
v的邻居的邻居的概率为
1
−
(
1
−
K
∣
B
r
/
2
(
v
)
∣
2
)
∣
B
r
/
2
(
v
)
∣
1-(1-\frac{K}{|B_{r/2}(v)|^2})^{|B_{r/2}(v)|}
1−(1−∣Br/2(v)∣2K)∣Br/2(v)∣;
接着,因为
K
<
<
∣
B
r
/
2
(
v
)
∣
K<<|B_{r/2}(v)|
K<<∣Br/2(v)∣,因此
K
∣
B
r
/
2
(
v
)
∣
2
\frac{K}{|B_{r/2}(v)|^2}
∣Br/2(v)∣2K是无穷小,根据
lim
x
→
∞
(
1
−
1
x
)
x
=
1
e
lim
x
→
0
e
x
−
1
∼
x
\lim_{x\to\infty}(1-\frac{1}{x})^x = \frac{1}{e} \\ \lim_{x\to 0}e^x -1 \sim x
x→∞lim(1−x1)x=e1x→0limex−1∼x
因为这东西不是严格的求极限,所以写的不是那么严谨,但要是好奇的话,带两组数据进去验证一下也可以
lim
K
∣
B
r
/
2
(
v
)
∣
2
→
0
1
−
(
1
−
K
∣
B
r
/
2
(
v
)
∣
2
)
∣
B
r
/
2
(
v
)
∣
=
lim
K
∣
B
r
/
2
(
v
)
∣
2
→
0
1
−
(
1
−
K
∣
B
r
/
2
(
v
)
∣
2
)
∣
B
r
/
2
(
v
)
∣
2
K
⋅
K
∣
B
r
/
2
(
v
)
∣
=
lim
K
∣
B
r
/
2
(
v
)
∣
2
→
0
1
−
(
1
e
)
K
∣
B
r
/
2
(
v
)
∣
=
lim
K
∣
B
r
/
2
(
v
)
∣
2
→
0
1
−
e
−
K
∣
B
r
/
2
(
v
)
∣
=
lim
K
∣
B
r
/
2
(
v
)
∣
2
→
0
−
(
e
−
K
∣
B
r
/
2
(
v
)
∣
−
1
)
=
lim
K
∣
B
r
/
2
(
v
)
∣
2
→
0
K
∣
B
r
/
2
(
v
)
∣
\begin{aligned} & \lim_{\frac{K}{|B_{r/2}(v)|^2}\to 0} 1 - (1-\frac{K}{|B_{r/2}(v)|^2})^{|B_{r/2}(v)|} \\ =& \lim_{\frac{K}{|B_{r/2}(v)|^2}\to 0} 1 - (1-\frac{K}{|B_{r/2}(v)|^2})^{\frac{|B_{r/2}(v)|^2}{K} \cdot \frac{K}{|B_{r/2}(v)|}} \\ =& \lim_{\frac{K}{|B_{r/2}(v)|^2}\to 0} 1 - (\frac{1}{e})^{\frac{K}{|B_{r/2}(v)|}} \\ =& \lim_{\frac{K}{|B_{r/2}(v)|^2}\to 0} 1 - e^{-\frac{K}{|B_{r/2}(v)|}} \\ =& \lim_{\frac{K}{|B_{r/2}(v)|^2}\to 0} - (e^{-\frac{K}{|B_{r/2}(v)|}} -1 )\\ =& \lim_{\frac{K}{|B_{r/2}(v)|^2}\to 0} \frac{K}{|B_{r/2}(v)|}\\ \end{aligned}
=====∣Br/2(v)∣2K→0lim1−(1−∣Br/2(v)∣2K)∣Br/2(v)∣∣Br/2(v)∣2K→0lim1−(1−∣Br/2(v)∣2K)K∣Br/2(v)∣2⋅∣Br/2(v)∣K∣Br/2(v)∣2K→0lim1−(e1)∣Br/2(v)∣K∣Br/2(v)∣2K→0lim1−e−∣Br/2(v)∣K∣Br/2(v)∣2K→0lim−(e−∣Br/2(v)∣K−1)∣Br/2(v)∣2K→0lim∣Br/2(v)∣K
算法步骤
将整个数据集的直径设为 △ \triangle △, ( ∗ ) (*) (∗)表明,只要我们取一个足够大的K(取决于增长因子 c c c)即使我们从一个随机的K近邻图开始,通过探索每一个对象邻居的邻居,便可找到该对象的处于半径为 △ 2 \frac{\triangle}{2} 2△的范围的 K K K个近邻。 不断迭代这一过程,每个对象的邻居距离该对象的距离会不断收缩,最终,构建一个高质量近似K紧邻图

其中,(1)处为更新统计,如果某一个对象的K近邻列表更新了, c c c就会加1。算法1的终止条件为自然终止,即没有更新时( c = 0 c=0 c=0)终止。
该算法还有改进的版本,有四个改进(局部连接;增量搜索;采样;提前终止),比较复杂,我这里不打算继续推导了,万一以后有需要,去看 王同学的解读 或者 原论文

UMAP降维算法原理
降维不仅仅是为了数据可视化。它还可以识别高维空间中的关键结构并将它们保存在低维嵌入中来克服“维度诅咒”
UMAP描述为: 一种降维技术,假设可用数据样本均匀(Uniform)分布在拓扑空间(Manifold)中,可以从这些有限数据样本中近似(Approximation)并映射(Projection)到低维空间。
各个名词解释
- Projection: 通过投影点在平面、曲面或线上再现空间对象的过程或技术。也可以将其视为对象从高维空间到低维空间的映射。
- Approximation: 算法假设我们只有一组有限的数据样本(点),而不是构成流形的整个集合。因此,我们需要根据可用数据来近似流形。
- Manifold: 流形是一个拓扑空间,在每个点附近局部类似于欧几里得空间。一维流形包括线和圆,但不包括类似数字8的形状。二维流形(又名曲面)包括平面、球体、环面等。
- Uniform: 均匀性假设告诉我们我们的数据样本均匀(均匀)分布在流形上。但是,在现实世界中,这种情况很少发生。因此这个假设引出了在流形上距离是变化的概念。即,空间本身是扭曲的:空间根据数据显得更稀疏或更密集的位置进行拉伸或收缩。
我们可以将UMAP分为两个主要步骤:
- 学习高维空间中的流形结构
- 找到该流形的低维表示
学习高维空间中的流形结构
在我们将数据映射到低维之前,肯定首先需要弄清楚它在高维空间中的样子。
寻找最近的邻居
UMAP 首先使用 Nearest-Neighbor-Descent 算法(构建K近邻图)找到最近的邻居。我们可以通过调整 UMAP 的 n_neighbors 超参数来指定我们想要使用多少个近邻点。
试验 n_neighbors 的数量很重要,因为它控制 UMAP 如何平衡数据中的局部和全局结构。它通过在尝试学习流形结构时限制局部邻域的大小来实现。
本质上,一个小的n_neighbors 值意味着我们需要一个非常局部的解释,准确地捕捉结构的细节。而较大的 n_neighbors 值意味着我们的估计将基于更大的区域,因此在整个流形中更广泛地准确。
UMAP的高维表示
UNAP采用概率(联合概率)的形式构建高维样本的两两关系,对于某一个点
i
i
i的K个近邻点
j
j
j
p
i
∣
j
=
e
−
d
(
x
i
,
x
j
)
−
ρ
i
σ
i
p_{i|j} = e ^{-\frac{d(x_i,x_j)-\rho_i}{\sigma_i}}
pi∣j=e−σid(xi,xj)−ρi
此处的
ρ
i
\rho_i
ρi是一个重要参数,代表第
i
i
i个数据点到其地一个最近邻居的距离。这样可以确保图的连通性(如果有一个点距离他的K个近邻点都很远,上面的概率就会趋于0,那么图就不连通了),而对于
σ
i
\sigma_i
σi则采用二分法对其进行搜索,满足的等式为
K
=
2
∑
j
p
i
,
j
K = 2^{\sum_j p_{i,j}}
K=2∑jpi,j
高维概率表示必须要保证对称性,所以有:
p
i
j
=
p
i
∣
j
+
p
j
∣
i
−
p
i
∣
j
p
j
∣
i
p_{ij} = p_{i|j} + p_{j|i} - p_{i|j}p_{j|i}
pij=pi∣j+pj∣i−pi∣jpj∣i
为什么要这样做呢,因为前面的K近邻算法,只是选取一个点最近的K个邻居,A的K近邻包含了B,但是B的K近邻可能不一定包含A,于是就有了这样的图

UMAP的低维表示
UMAP使用曲线族
1
1
+
a
⋅
y
(
2
b
)
\frac{1}{1+a\cdot y^(2b)}
1+a⋅y(2b)1来建模低维距离概率,在低维中
q
i
,
j
=
(
1
+
a
(
y
i
−
y
j
)
2
b
)
−
1
q_{i,j} = (1 + a(y_i - y_j)^{2b})^{-1}
qi,j=(1+a(yi−yj)2b)−1
之所以选择这样的函数,是为了拟合一个分段函数
{
1
if
y
i
−
y
j
≤
min dist
e
−
(
y
i
−
y
j
)
−
m
i
n
d
i
s
t
if
y
i
−
y
j
>
min dist
\begin{cases} 1 & \text{if }y_i-y_j \leq \text{ min dist } \\ e^{-(y_i-y_j)-min dist} & \text{if }y_i-y_j > \text{ min dist } \\ \end{cases}
{1e−(yi−yj)−mindistif yi−yj≤ min dist if yi−yj> min dist
注意,这里引入了min-dist,是因为我们不希望在低维空间表示中改变距离。相反,我们希望流形上的距离是相对于全局坐标系的标准欧几里得距离。
从可变距离到标准距离的转换的转换也会影响与最近邻居的距离。因此,我们必须传递另一个名为 min_dist(默认值=0.1)的超参数来定义嵌入点之间的最小距离。
构造Loss使得高维表示与低维表示相近
UMAP使用交叉熵作为loss函数
C
E
(
X
,
Y
)
=
∑
i
∑
j
[
p
i
j
(
X
)
log
(
p
i
,
j
(
X
)
q
i
j
(
Y
)
)
+
(
1
−
p
i
j
(
X
)
)
log
(
1
−
p
i
j
(
X
)
1
−
q
i
j
(
Y
)
)
]
CE(X,Y) = \sum_i\sum_j[p_{ij}(X)\log(\frac{p_{i,j}(X)}{q_{ij}(Y)}) + (1-p_{ij}(X))\log(\frac{1-p_{ij}(X)}{1-q_{ij}(Y)})]
CE(X,Y)=i∑j∑[pij(X)log(qij(Y)pi,j(X))+(1−pij(X))log(1−qij(Y)1−pij(X))]
其中,
X
X
X表示高维表示,是已知的(相当于ground truth),而
Y
Y
Y则是低维表示,是我们想让算法学到的;
可以将这个loss函数与t-sne的loss函数做一个比较,t-sne也是一个降维算法,其loss函数为
C
=
K
L
(
P
∣
Q
)
=
∑
i
∑
j
p
i
j
log
p
i
j
q
i
j
C = KL(P|Q) = \sum_i\sum_j p_{ij} \log{\frac{p_{ij}}{q_{ij}}}
C=KL(P∣Q)=i∑j∑pijlogqijpij
将其画出则是:

只需要关注当X比较大,Y比较小的时候(左下角处),我们想让Y变大,但是此时的Loss函数的梯度很小,不便于调整(但是在X比较小,Y比较大的时候梯度还是不错的)
而UMAP的Loss函数则是:

无论是在X比较大,Y比较小;还是X比较小,Y比较大的时候,梯度都很大,有利于收敛…
总结UMAP算法
- 对高维数据做NN-Desent算法构造K近邻图
- 求每个点的参数 ρ i \rho_i ρi: 距离点 i i i最近的点的距离
- σ i \sigma_i σi: 利用 K = 2 ∑ j p i j K = 2^{\sum_j p_{ij}} K=2∑jpij通过二值搜索得到
- 计算条件概率 p i ∣ j = e − d ( x i , x j ) − ρ i σ i p_{i|j} = e ^{-\frac{d(x_i,x_j)-\rho_i}{\sigma_i}} pi∣j=e−σid(xi,xj)−ρi,并得到联合概率 p i j = p i ∣ j + p j ∣ i − p i ∣ j p j ∣ i p_{ij} = p_{i|j} + p_{j|i} - p_{i|j}p_{j|i} pij=pi∣j+pj∣i−pi∣jpj∣i
- 给定min-dist,利用曲线拟合的方法求超参数 a , b a,b a,b
- 初始化低维表示图(或者矩阵)
- 最小化loss,得到高维数据的低维表示
TF-IDF算法
TF-IDF(term frequency–inverse document frequency,词频-逆向文件频率)是一种用于信息检索(information retrieval)与文本挖掘(text mining)的常用加权技术。
TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降
TF-IDF的主要思想是:如果某个单词在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
TF是词频
词频(TF)表示词条(关键字)在文本中出现的频率,这个数字通常会被归一化(一般是词频除以文章总词数), 以防止它偏向长的文件。
t
f
i
j
=
n
i
,
j
∑
k
n
l
,
j
tf_{ij} = \frac{n_{i,j}}{\sum_k n_{l,j}}
tfij=∑knl,jni,j
其中,i表示某个词,j表示某篇文章,k表示该篇文章的总词数;所以上式就是用某一文档中词
w
w
w出现的次数除以总词数,说白了就是该词出现的概率…
IDF是逆向文件频率
逆向文件频率 (IDF) :某一特定词语的IDF,可以由总文件数目除以包含该词语的文件的数目,再将得到的商取对数得到。如果包含词条t的文档越少, IDF越大,则说明词条具有很好的类别区分能力。
I
D
F
i
=
log
(
∣
D
∣
∣
{
j
:
t
i
∈
d
j
}
∣
)
IDF_i = \log(\frac{|D|}{|\{j:t_i\in d_j\}|})
IDFi=log(∣{j:ti∈dj}∣∣D∣)
其中,下标i代表某个词,
∣
D
∣
|D|
∣D∣是语料库中的文件总数,
∣
{
j
:
t
i
∈
d
j
}
∣
|\{j:t_i\in d_j\}|
∣{j:ti∈dj}∣表示包含词语
t
i
t_i
ti的文件数目;如果该词不在语料库中,就可能会导致分母为0,所以一般会加一个1;
I
D
F
w
=
log
(
总
文
档
数
包
含
词
w
的
文
档
数
+
1
)
IDF_w = \log(\frac{总文档数}{包含词w的文档数+1})
IDFw=log(包含词w的文档数+1总文档数)
TF-IDF实际上是:TF * IDF
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
T F − I D F = T F ∗ I D F TF-IDF = TF * IDF TF−IDF=TF∗IDF
注意 TF-IDF算法非常容易理解,并且很容易实现,但是其简单结构并没有考虑词语的语义信息,无法处理一词多义与一义多词的情况。
Sklearn实现TF-IDF算法
数据集来源于machine translation的中文数据集,数据集下载地址 http://www.statmt.org/wmt17/translation-task.html#download 选择 New Commentary v12进行下载即可
CountVectorizer
CountVectorizer是属于常见的特征数值计算类,是一个文本特征提取方法。对于每一个训练文本,它只考虑每种词汇在该训练文本中出现的频率。
CountVectorizer会将文本中的词语转换为词频矩阵,它通过fit_transform函数计算各个词语出现的次数。
CountVectorizer类的参数很多,分为三个处理步骤:preprocessing、tokenizing、n-grams generation.
也可以直接当作词典来用
| 属性or方法 | 作用 |
|---|---|
| vocabulary_ | 词汇表;字典型,key是词,value是频率 |
| get_feature_names() | 所有文本的词汇;列表型 |
| stop_words_ | 返回停用词表(可以在初始化类的时候传一个停用词列表进去,不传的话sklearn好像自己有默认的停用词表) |
| fit_transform(x) | 训练并返回文本矩阵 |
用数据输入形式为列表,列表元素为代表文章的字符串,一个字符串代表一篇文章,字符串是已经分割好的。CountVectorizer同样适用于中文;

运行结果:

TF-IDF算法的不足
TF-IDF 采用文本逆频率 IDF 对 TF 值加权取权值大的作为关键词,但 IDF 的简单结构并不能有效地反映单词的重要程度和特征词的分布情况,使其无法很好地完成对权值调整的功能,所以 TF-IDF 算法的精度并不是很高,尤其是当文本集已经分类的情况下。
在本质上 IDF 是一种试图抑制噪音的加权,并且单纯地认为文本频率小的单词就越重要,文本频率大的单词就越无用。这对于大部分文本信息,并不是完全正确的。IDF 的简单结构并不能使提取的关键词, 十分有效地反映单词的重要程度和特征词的分布情 况,使其无法很好地完成对权值调整的功能。尤其是在同类语料库中,这一方法有很大弊端,往往一些同类文本的关键词被盖。
概括起来,有以下不足
- 没有考虑特征词的位置因素对文本的区分度,词条出现在文档的不同位置时,对区分度的贡献大小是不一样的。
- 按照传统TF-IDF,往往一些生僻词的IDF(反文档频率)会比较高、因此这些生僻词常会被误认为是文档关键词。
- 传统TF-IDF中的IDF部分只考虑了特征词与它出现的文本数之间的关系,而忽略了特征项在一个类别中不同的类别间的分布情况。
- 对于文档中出现次数较少的重要人名、地名信息提取效果不佳。
c-TF-ICF创建文本表示
为了对每个分类作出表示,Bertopic修改了TF-IDF模型,使得c-TF-ICF基于的是分类好的文本,而不是整个语料得到关键词

其中x表示某个词, t f x , c tf_{x,c} tfx,c表示词x在类别c中出现的频率, f x f_x fx表示词x在所有类别中出现的频率, A A A表示每个类别的平均词数, W x , c W_{x,c} Wx,c就是词x在c类别中的重要得分; f x f_x fx之所以放到分母上,我的理解是: 如果 f x f_x fx越大,越倾向于说明他是一个常用词而不是能指代某一个类别的词
MMR 算法
最大边界相关法(Maximal Marginal Relevance Coherence)是一种重新确定文档序值的方法;
设计之初是用来计算Query语句与被搜索文档之间的相似度,从而对文档进行rank排序的算法。
具体公式如下:
M
M
R
(
Q
,
C
,
R
)
=
arg max
d
i
∈
C
k
[
λ
s
i
m
(
Q
,
d
i
)
−
(
1
−
λ
)
max
d
j
∈
R
(
s
i
m
(
d
i
,
d
j
)
)
]
MMR(Q,C,R) = \argmax^k_{d_i \in C}[\lambda sim(Q,d_i) - (1-\lambda)\max_{d_j \in R}(sim(d_i,d_j))]
MMR(Q,C,R)=di∈Cargmaxk[λsim(Q,di)−(1−λ)dj∈Rmax(sim(di,dj))]
- Q: 查询语句
- C: 所有文档的集合
- R: 已得到的一个以相关度为基础的初始集合
- arg max k [ ∗ ] \argmax^k[*] argmaxk[∗]: 给出集合 K K K个最大元素的索引
- s i m ( Q , d i ) sim(Q,di) sim(Q,di): 代表的是 d i 与 Q d_i与Q di与Q的相关性
- s i m ( d i , d j ) sim(d_i,d_j) sim(di,dj): 则表示的是 d i d_i di的冗余性
而MMR的核心,即在权衡这两种性质,即redundancy=cost,relevance=benefit
具体算法如下:
- 用其他常用的信息检索方法(IR),如普通法,分段法,追溯法等,这样得到起始的K个文档,即总的文档集;
- 再从中选择Query最接近的一篇文章标记为第一个文档,然后从其他 K K K个文档中去掉,作为有序集合,即 R R R
- 反复这一步骤,重新得到文档的顺序
而对于Bertopic来说,C可能就是C-TF-IDF得到的主题词,然后Q是这个主题的文章,然后执行MMR算法,设定一个阈值,最终筛出主题词;
最后,因为模型太大,下载模型要好多流量,月末了流量不够用,下个月再跑模型吧…
引用参考
UMAP降维算法原理详解和应用示例 https://zhuanlan.zhihu.com/p/432805218
[译]理解 UMAP(1):UMAP是如何工作的 & UMAP 与 tSNE的原理对比 https://zhuanlan.zhihu.com/p/150788883
最大边界相关法(Maximal Marginal Relevance)的总结 https://blog.csdn.net/eliza1130/article/details/24033161
sklearn中使用CountVectorizer和TfidfTransformer计算TF-IDF https://blog.csdn.net/qq_36134437/article/details/103057909
TF-IDF算法介绍及实现 https://blog.csdn.net/asialee_bird/article/details/81486700
官方算法说明 https://maartengr.github.io/BERTopic/algorithm/algorithm.html
官方模型 https://maartengr.github.io/BERTopic/index.html


















 1825
1825

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











