






作为大模型微调的 “性价比之王”,LoRA(Low-Rank Adaptation)凭啥成为开源模型微调的标配?不用海量算力,不用动大模型的 “核心代码”,只需训练几个 “小插件”,就能实现接近全量微调的效果 —— 这篇入门文,用通俗比喻讲清核心原理,再用 step-by-step 实践教你上手,新手也能快速落地。
-----------------------------------------点赞关注,后续干货持续更新~-------------------------------------
一、为什么LoRA行?
想象一下,那个巨大的预训练模型已经读过整个互联网的数据,它非常聪明,大脑里有数十亿个神经元连接。这些连接已经非常完美地处于一种平衡状态。
当我们为了一个特定的小任务(比如让它学会写某种特定格式的邮件,或者画一种特定风格的画)去微调它时,研究人员发现了一个惊人的现象:
虽然模型的参数矩阵非常巨大,但是为了适应新任务,这些参数矩阵需要发生的“变化量”,其实并不复杂。
用术语来说,就是权重更新矩阵的“内在维度”很低。
二、LoRA 核心原理
基于这个洞察,LoRA 的发明者想:既然所需的变化量不复杂(低内在维度),那我们为什么要用一个和原模型一样巨大的矩阵来表示这个变化呢?这是巨大的浪费。
我们用一点点数学来表示。
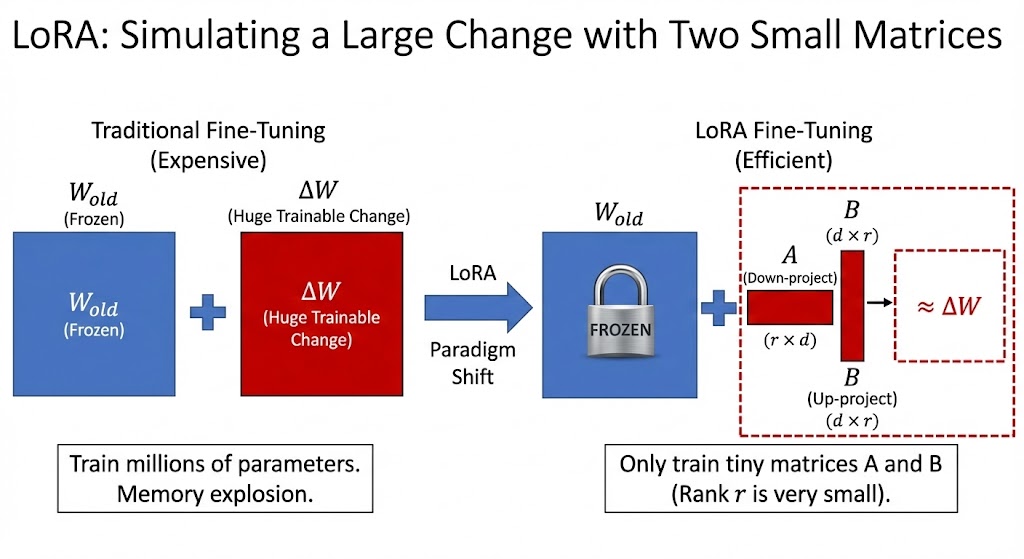
原来的样子: 模型的某一层有一个巨大的权重矩阵 W(比如大小是 1000×1000)。微调时,我们要学一个同样巨大的变化矩阵 △W(也是 1000×1000),然后把它们加起来:
W新 = W旧+△W。
LoRA 的做法: 既然△W的内在维度很低,我们就可以把它分解成两个非常小的“瘦子”矩阵相乘。
我们引入两个小矩阵:
-
一个瘦高的矩阵B(比如1000×8)
-
一个扁平的矩阵A(比如8×1000)
神奇的线性代数告诉我们,这两个小矩阵相乘 (B×A),结果竟然会得到一个1000×1000 的大矩阵!
LoRA 的核心公式就是:让 △W≈B×A。
这里的关键数字是中间那个8。这个数字叫做秩 (Rank),在 LoRA 中用r表示。这个r非常非常小(通常是 4, 8, 16, 32 等),而原模型的维度通常是几千。
为什么行?
因为我们相信,那个巨大的变化矩阵△W中真正包含的有效信息,其实只需要这r=8个维度的组合就能概括了。我们不需要训练1000×1000 = 1,000,000个参数,只需要训练(1000×8) + (8×1000) = 16,000个参数。
参数量瞬间减少了 98% 以上!这就是 LoRA 高效的根本原因。
三、代码入门实战
使用经典的 RoBERTa 模型 (比较小)进行一个 情感分析任务(判断评论是好评还是差评)。可以在 AutoDL https://www.autodl.com/的最基础显卡(如 RTX 3090 甚至 2080Ti)上轻松运行,全流程大约只需 5-10 分钟。
🛠️ 第一步:AutoDL 环境准备
-
租赁实例: 在 AutoDL 上租一个实例(推荐 PyTorch 2.0.0+, Python 3.8+, CUDA 11.8+ 的镜像)。
-
打开终端: 登录 JupyterLab 后,打开终端。
3. 开启学术加速,下载数据:
# 1. 开启学术加速
source /etc/network_turbo
# 2. 下载训练集 (保存为 train.parquet)
wget https://huggingface.co/datasets/imdb/resolve/main/plain_text/train-00000-of-00001.parquet -O train.parquet
# 3. 下载测试集 (保存为 test.parquet)
wget https://huggingface.co/datasets/imdb/resolve/main/plain_text/test-00000-of-00001.parquet -O test.parquet
4. 安装核心依赖:
pip install transformers peft datasets accelerate scikit-learn
💻 第二步:编写代码 (run_lora.py)
新建一个文件 run_lora.py,并将以下代码复制进去。
import torch
from datasets import load_dataset
from transformers import (
AutoTokenizer,
AutoModelForSequenceClassification,
TrainingArguments,
Trainer,
DataCollatorWithPadding
)
from peft import LoraConfig, get_peft_model, TaskType
import numpy as np
import os
# -------------------------------------------------------------------------
# 1. 准备配置与辅助函数
# -------------------------------------------------------------------------
MODEL_ID = "roberta-base" # 基础模型
LR = 1e-3 # 学习率 (LoRA通常可以使用比全量微调更大的学习率)
BATCH_SIZE = 16
def print_trainable_parameters(model):
"""
辅助函数:打印模型里有多少参数需要训练。
"""
trainable_params = 0
all_param = 0
for _, param in model.named_parameters():
all_param += param.numel()
if param.requires_grad:
trainable_params += param.numel()
print(f"\n=======================================================")
print(f"总参数量: {all_param:,}")
print(f"可训练参数 (Trainable): {trainable_params:,}")
print(f"参数占比: {100 * trainable_params / all_param:.2f}%")
print(f"=======================================================\n")
# -------------------------------------------------------------------------
# 2. 加载数据与预处理 (读取本地 Parquet 文件)
# -------------------------------------------------------------------------
print(">>> 正在加载本地数据文件...")
# 确保文件存在,否则报错提示
if not os.path.exists("train.parquet") or not os.path.exists("test.parquet"):
raise FileNotFoundError("请确保 train.parquet 和 test.parquet 都在当前目录下!")
# 使用 parquet 引擎加载本地文件
dataset = load_dataset(
"parquet",
data_files={
"train": "train.parquet",
"test": "test.parquet"
}
)
print(">>> 数据加载成功!正在预处理...")
# 为了演示速度,我们依然只取前 1000 条训练,前 500 条验证
# 注意:本地加载后,key 是我们在 data_files 里定义的 'train' 和 'test'
small_train_dataset = dataset["train"].shuffle(seed=42).select(range(1000))
small_eval_dataset = dataset["test"].shuffle(seed=42).select(range(500))
tokenizer = AutoTokenizer.from_pretrained(MODEL_ID)
def preprocess_function(examples):
# IMDB 数据集通常包含 'text' 和 'label' 两列
return tokenizer(examples["text"], truncation=True, padding=True, max_length=256)
tokenized_train = small_train_dataset.map(preprocess_function, batched=True)
tokenized_eval = small_eval_dataset.map(preprocess_function, batched=True)
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
# -------------------------------------------------------------------------
# 3. 加载原始模型 (冻结的大机器)
# -------------------------------------------------------------------------
print(f">>> 正在加载基础模型: {MODEL_ID}...")
# 这里会从 Hugging Face 下载模型权重,通常学术加速下没问题
model = AutoModelForSequenceClassification.from_pretrained(
MODEL_ID, num_labels=2, id2label={0: "NEGATIVE", 1: "POSITIVE"}, label2id={"NEGATIVE": 0, "POSITIVE": 1}
)
print("\n>>> [状态 1] 原始模型加载完毕。如果现在训练,是全量微调:")
print_trainable_parameters(model) # 此时应该是 100% 参数可训练
# -------------------------------------------------------------------------
# 4. 注入 LoRA (插入小旋钮) -- 核心步骤
# -------------------------------------------------------------------------
peft_config = LoraConfig(
task_type=TaskType.SEQ_CLS, # 任务类型:序列分类
inference_mode=False,
r=8, # 【重点】秩 Rank = 8
lora_alpha=32, # LoRA 的缩放系数
lora_dropout=0.1,
target_modules=["query", "value"] # RoBERTa 的注意力层
)
model = get_peft_model(model, peft_config)
print("\n>>> [状态 2] LoRA 注入完毕。现在看看还需要训练多少参数:")
print_trainable_parameters(model) # 期待看到 < 1% 的参数量
# -------------------------------------------------------------------------
# 5. 开始训练 (拧小旋钮)
# -------------------------------------------------------------------------
training_args = TrainingArguments(
output_dir="./lora_roberta_output",
learning_rate=LR,
per_device_train_batch_size=BATCH_SIZE,
per_device_eval_batch_size=BATCH_SIZE,
num_train_epochs=3,
weight_decay=0.01,
evaluation_strategy="epoch",
save_strategy="epoch",
load_best_model_at_end=True,
logging_steps=10,
report_to="none"
)
def compute_metrics(eval_pred):
predictions, labels = eval_pred
predictions = np.argmax(predictions, axis=1)
return {"accuracy": (predictions == labels).mean()}
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_train,
eval_dataset=tokenized_eval,
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics,
)
print("\n>>> 开始训练...")
trainer.train()
# -------------------------------------------------------------------------
# 6. 保存与测试
# -------------------------------------------------------------------------
print("\n>>> 训练完成,正在保存 LoRA 适配器...")
# 这里只会保存很小的 adapter 文件,而不是整个大模型
model.save_pretrained("./lora_roberta_final")
print(">>> 推理测试:")
text = "This movie is absolutely fantastic! The acting was superb."
inputs = tokenizer(text, return_tensors="pt").to(model.device)
# 确保模型在评估模式
model.eval()
with torch.no_grad():
logits = model(**inputs).logits
predicted_class_id = logits.argmax().item()
print(f"评论内容: {text}")
print(f"预测情感: {model.config.id2label[predicted_class_id]}")🚀 第三步:运行与观察
在终端中运行:
python run_lora.py
输出:

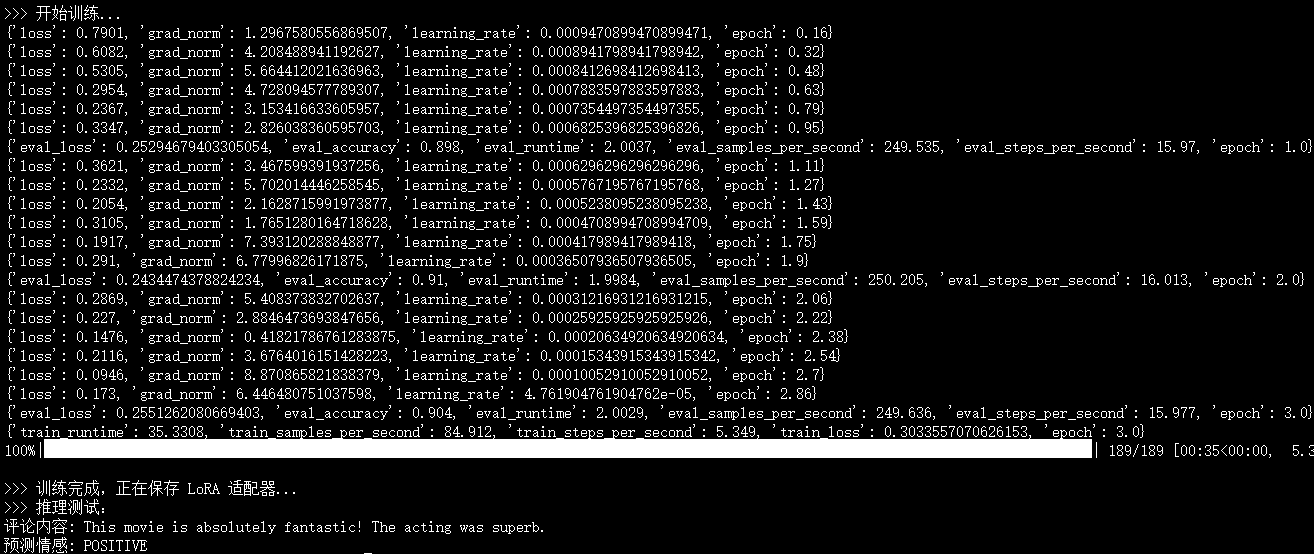
这就是 LoRA 的核心魅力:我们仅仅训练了原本 0.2% 的参数量,就让模型学会了分辨电影评论的情感。
📊 第四步:应用
训练完了模型,怎么把它拿出来用呢?
在 LoRA 的世界里,加载模型有一个独特的合体过程: 我们需要先加载那个原本的笨重的大模型(Base Model),然后再把我们训练好的轻量级 LoRA 适配器(Adapter)“挂载”上去。
新建一个文件 inference.py,然后粘贴以下代码:
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification
from peft import PeftModel, PeftConfig
# -------------------------------------------------------------------------
# 1. 路径设置
# -------------------------------------------------------------------------
# 这是我们之前训练代码中保存的文件夹路径
peft_model_id = "./lora_roberta_final"
# 基础模型名称(必须与训练时一致)
base_model_id = "roberta-base"
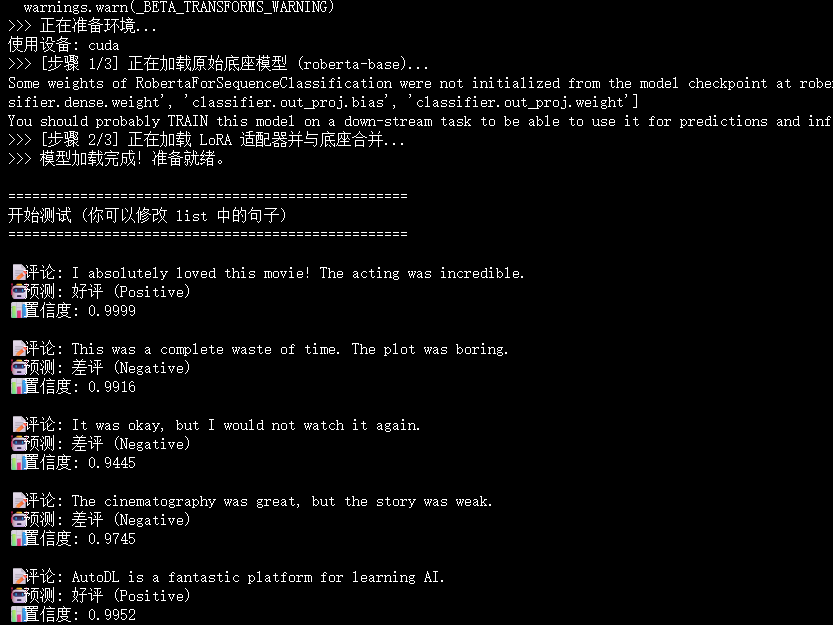
print(f">>> 正在准备环境...")
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"使用设备: {device}")
# -------------------------------------------------------------------------
# 2. 加载原始大模型
# -------------------------------------------------------------------------
print(f">>> [步骤 1/3] 正在加载原始底座模型 ({base_model_id})...")
# 注意:这里我们重新定义了 label 映射,确保输出不仅仅是数字
base_model = AutoModelForSequenceClassification.from_pretrained(
base_model_id,
num_labels=2,
id2label={0: "差评 (Negative)", 1: "好评 (Positive)"},
label2id={"差评 (Negative)": 0, "好评 (Positive)": 1}
)
tokenizer = AutoTokenizer.from_pretrained(base_model_id)
# -------------------------------------------------------------------------
# 3. 加载LoRA 适配器
# -------------------------------------------------------------------------
print(f">>> [步骤 2/3] 正在加载 LoRA 适配器并与底座合并...")
# PeftModel.from_pretrained 会自动把 save 好的 adapter 权重加到 base_model 上
model = PeftModel.from_pretrained(base_model, peft_model_id)
model.to(device)
model.eval() # 切换到评估模式
print(">>> 模型加载完成!准备就绪。")
# -------------------------------------------------------------------------
# 4. 定义推理函数
# -------------------------------------------------------------------------
def predict_sentiment(text):
# 1. 预处理文本
inputs = tokenizer(
text,
return_tensors="pt",
truncation=True,
padding=True,
max_length=256
).to(device)
# 2. 模型推理 (不计算梯度,节省显存)
with torch.no_grad():
outputs = model(**inputs)
# 3. 获取概率最大的类别
logits = outputs.logits
probabilities = torch.nn.functional.softmax(logits, dim=-1)
prediction_id = torch.argmax(logits, dim=-1).item()
prediction_label = model.config.id2label[prediction_id]
confidence = probabilities[0][prediction_id].item()
return prediction_label, confidence
# -------------------------------------------------------------------------
# 5. 测试一下
# -------------------------------------------------------------------------
print("\n" + "="*50)
print("开始测试 (你可以修改 list 中的句子)")
print("="*50)
test_sentences = [
"I absolutely loved this movie! The acting was incredible.", # 明显的褒义
"This was a complete waste of time. The plot was boring.", # 明显的贬义
"It was okay, but I would not watch it again.", # 中性偏贬义
"The cinematography was great, but the story was weak.", # 混合评价
"AutoDL is a fantastic platform for learning AI." # 域外测试
]
for text in test_sentences:
label, score = predict_sentiment(text)
print(f"\n📝 评论: {text}")
print(f"🤖 预测: {label}")
print(f"📊 置信度: {score:.4f}")
-
保存上述代码为
inference.py。 -
确保
lora_roberta_final文件夹在同一级目录下(这就是刚才run_lora.py生成的)。 -
在终端运行:
python inference.py
代码原理解析
这段代码最关键的一行是:
model = PeftModel.from_pretrained(base_model, peft_model_id)
这就是 LoRA 的精髓:
-
base_model是几百兆甚至几 G 的大文件。 -
peft_model_id指向的文件夹里,其实只有一个非常小的adapter_model.bin(可能只有几 MB)。 -
这一行代码在内存中动态地把那“几 MB 的小旋钮”装到了“几百 MB 的大机器”上,让它瞬间拥有了你训练出的能力。
------------------------------------------点赞关注,后续干货持续更新~---------------------------------------

















 9870
9870

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









