







《AM-Thinking-v1: Advancing the Frontier of Reasoning at 32B Scale》论文解读
一、引言
过去半年,大型语言模型(LLMs)在推理领域(如数学问题求解和代码生成)取得了显著进展,扩大了其在现实场景中的应用范围。开源社区的能力也在不断增强,例如 DeepSeek-R1 的发布显示出开源模型能够与 OpenAI 的 o1、Google 的 Gemini 2.5 和 Anthropic 的 Claude 3.7 等专有系统相媲美。然而,许多近期的突破依赖于大规模的混合专家(MoE)架构,这带来了显著的基础设施负担,并使模型部署和微调变得复杂。
与之相对,中等规模(例如 32B)的稠密模型在效率和可部署性上更具优势,但在推理性能上往往落后于 MoE 模型。这引发了一个关键研究问题:是否可以通过精心设计的后训练流程,在不依赖私有数据或大规模 MoE 架构的情况下,释放 32B 级别稠密模型的推理潜力?
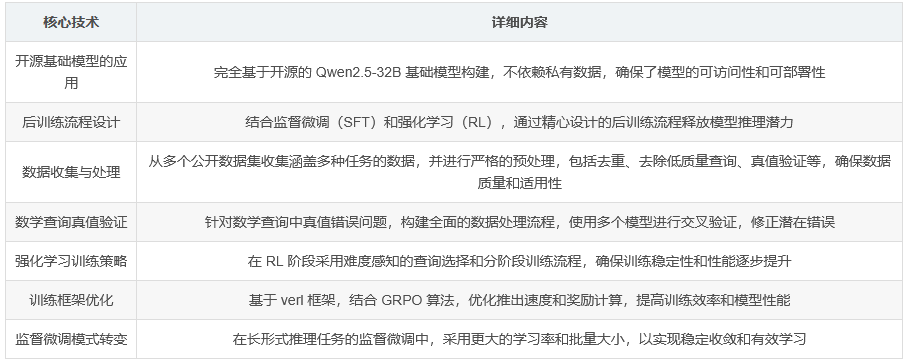
为此,研究者们提出了 AM-Thinking-v1,这是一个基于开源 Qwen2.5-32B 基础模型构建的推理优化语言模型。它在多个推理基准测试中实现了与开源模型相比的最先进性能,甚至超越了许多更大型的 MoE 模型。
二、数据
AM-Thinking-v1 的训练数据全部来自公开数据集,涵盖数学推理、代码生成、科学推理、指令遵循和通用聊天等任务。
(一)数据收集
-
数学推理 :确保每个数据点都包含可验证的真值,使用了 OpenR1-Math-220k、Big-Math-RL-Verified 等多个数据集。
-
代码生成 :保证所有收集的代码数据都包含可验证的测试用例,选用了 PRIME、DeepCoder、KodCode 等数据集。
-
科学推理 :包含自然科学(物理、化学等)和逻辑推理,主要是多项选择题,配对可靠的真值,包括 task_mmmlu、chemistryQA 等数据集。
-
指令遵循(IF) :选择了 Llama-Nemotron-PostTraining-Dataset、tulu-3-sft-mixture 两个指令遵循数据集。
-
通用聊天 :涵盖范围广泛的任务,包括开放式查询、通用知识和日常推理,支持单轮和多轮交互,选用了 evol、InfinityInstruct 等数据集。
(二)查询过滤
收集数据后,首先去除重复项,然后进行两项清理步骤:
-
去除包含 URL 的查询 :模型在训练期间无法访问外部链接,URL 的存在可能导致幻觉或误导性输出。
-
去除引用图像的查询 :由于模型是纯文本的,无法感知或处理任何视觉信息,因此排除这类查询。
最后,利用精确匹配和语义去重,从训练集中移除与评估集中相似的查询。
(三)数学查询过滤
在分析数学数据时,发现存在查询描述不清晰或不完整以及真值错误的问题。为此,使用大型语言模型(LLM)分析并过滤掉缺乏清晰或完整描述的查询,并实施严格的真值验证过程。
(四)合成响应过滤
在查询过滤后,应用三种方法过滤掉低质量的合成响应:
-
基于困惑度(Perplexity)的过滤 :使用之前训练的 32B 模型计算每个模型生成响应的困惑度(PPL),丢弃超过预设阈值的响应。
-
基于 N-gram 的过滤 :丢弃包含连续重复短语的模型响应。
-
基于结构的过滤 :对于多轮对话,确保最后一轮是助手的响应,并要求每个模型生成的回复包含完整的思考和回答部分。
三、方法
(一)监督微调(SFT)
-
数据 :使用大约 284 万个样本进行监督微调(SFT)训练,涵盖数学、代码、科学、指令遵循和通用聊天五大类别。
-
训练配置 :基于 Qwen2.5-32B 基础模型进行 SFT。采用较大的学习率和批量大小,确保稳定收敛和有效学习。使用 8e-5 的学习率、最大序列长度 32k(带序列打包),丢弃超过 32k 令牌的样本。全局批量大小设置为 64,训练 2 个周期,采用余弦热身策略,热身步数设置为总训练步数的 5%,之后学习率衰减至 0。对于多轮对话数据,仅使用包含推理过程的最终响应作为训练目标并贡献损失,专注于推理部分的学习。
(二)强化学习(RL)
-
训练查询的选择 :在强化学习(RL)阶段之前,根据 SFT 模型获得的数学和代码查询的通过率进行筛选,只保留通过率严格在 0 到 1 之间的查询,以确保训练数据足够具有挑战性,同时避免过于简单或过于困难的实例。
-
RL 流程 :RL 管道包括两个阶段,当模型在第一阶段的性能达到平稳时,进入第二阶段。在第二阶段,去除所有在第一阶段以 100% 准确率正确回答的数学和代码查询,并补充 15k 通用聊天和 5k 指令遵循数据,以提高更广泛的泛化能力。采用集团相对策略优化(GRPO)作为训练算法,经过一系列的配置和优化,以确保训练的稳定性和性能的提升。
(三)RL 框架
-
训练管道 :基于 verl 框架构建,使用 GRPO 进行强化学习。verl 是一个开源的 RL 框架,与 vLLM、FSDP 和 MegatronLM 集成,实现在 1000 多个 GPU 上的可扩展 RL 训练。
-
扩展和优化 :对 verl 进行了一系列扩展和优化,包括推出速度优化和奖励计算优化。
四、实验
(一)评估
-
基准测试 :在多个具有挑战性的基准上评估模型,包括美国数学邀请赛 2024(AIME2024)、美国数学邀请赛 2025(AIME2025)、LiveCodeBench(LCB)和 Arena-Hard。
-
评估方法 :保持所有基准的标准化评估条件,最大生成长度设置为 49,152 令牌。对于需要随机采样的基准,统一采用温度为 0.6 和 top-p 值为 0.95。
-
提示策略 :在所有评估中使用一致的系统提示,以引导模型的响应格式。根据基准的不同,对用户提示进行相应调整。
-
基线模型 :将 AM-Thinking-v1 与多个强大的基线模型进行比较,包括专有和开源系统,如 DeepSeek-R1、Qwen3-235B-A22B、OpenAI-o1 等。
(二)结果
AM-Thinking-v1 在多个推理基准测试中表现出色,在数学任务上,在 AIME2024 和 AIME2025 上分别获得 85.3 和 74.4 的分数,超越或接近 DeepSeek-R1 和 Qwen3-235B-A22B 等更大模型。在 LiveCodeBench 基准测试中,获得 70.3 的分数,显著优于 DeepSeek-R1、Qwen3-32B 和 Nemotron-Ultra253B 等模型。在通用聊天基准 Arena-Hard 上,获得 92.5 的分数,与 OpenAI-o1 和 o3-mini 等专有模型具有竞争力,但性能仍落后于 Qwen3-235B-A22B,表明在通用对话能力方面仍有提升空间。
五、结论与局限性
AM-Thinking-v1 作为一个 32B 级别的稠密语言模型,在开源模型中展现了最先进的推理能力,超越了 DeepSeek-R1,甚至接近 Qwen3-235B-A22B 和 Seed1.5-Thinking 等顶级混合专家(MoE)模型的性能。这得益于基于开源训练查询和基础模型精心设计的后训练流程,通过系统数据预处理、彻底的真值验证以及精心设计的 SFT 和 RL 框架,成功地从一个中等规模模型中激发了先进的推理能力。
然而,AM-Thinking-v1 也存在局限性。它不支持结构化函数调用、工具使用和多模态输入,限制了其在基于代理或跨模态场景中的应用。安全对齐还处于初步阶段,需要进一步的红队测试。此外,其性能在低资源语言和特定领域任务中可能会有所变化。
六、核心技术汇总表格

















 438
438

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









