







II-Medical-8B 论文解析
一、模型概述
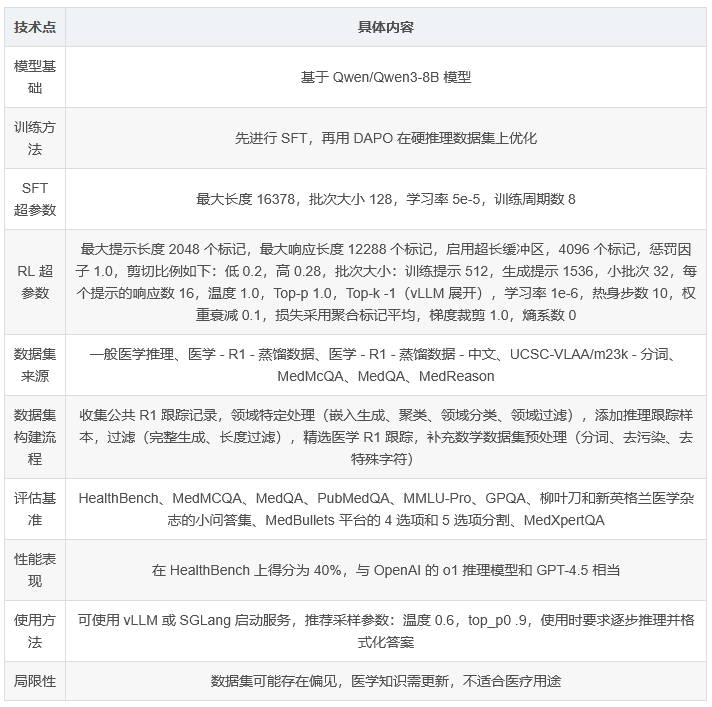
II-Medical-8B 是智能互联网公司新开发的先进大型语言模型,专为增强医疗推理的 AI 能力而设计。它在先前的 II-Medical-7B-Preview 基础上进行了重大改进,显著提升了医疗问答能力。该模型基于 Qwen/Qwen3-8B 模型,通过使用特定于医疗领域的推理数据集进行 SFT(监督微调)以及在硬推理数据集上训练 DAPO(一种可能的优化方法)来优化模型性能。
二、训练方法学
-
SFT 阶段 :最大长度为 16378,批次大小为 128,学习率为 5e-5,训练周期数为 8。
-
RL(强化学习)阶段 :最大提示长度为 2048 个标记,最大响应长度为 12288 个标记,启用超长缓冲区,4096 个标记,惩罚因子为 1.0。剪切比例如下:低 0.2,高 0.28。批次大小:训练提示为 512,生成提示为 1536,小批次为 32。每个提示的响应数为 16。温度为 1.0,Top-p 为 1.0,Top-k 为 -1(vLLM 展开)。学习率为 1e-6,热身步数为 10,权重衰减为 0.1。损失聚合采用标记平均,梯度裁剪为 1.0,熵系数为 0。
三、评估结果
II-Medical-8B 模型在 HealthBench 上得分为 40%,HealthBench 是一个全面的开源基准测试,用于评估大型语言模型在医疗保健领域的性能和安全性。这一表现与 OpenAI 的 o1 推理模型和 GPT-4.5 相当,而 GPT-4.5 是 OpenAI 目前最大、最先进的模型。论文还提供了与 ChatGPT 中可用模型的对比。此外,该模型在多个医疗问答基准测试中进行了评估,包括 MedMCQA、MedQA、PubMedQA、MMLU-Pro 和 GPQA 中的医学相关问题,以及来自柳叶刀和新英格兰医学杂志的小问答集,MedBullets 平台的 4 选项和 5 选项分割以及 MedXpertQA。
四、数据集构建
训练数据集包含 555000 个样本,来自以下来源:
-
一般医学推理:40544 个样本
-
医学 - R1 - 蒸馏数据:22000 个样本
-
医学 - R1 - 蒸馏数据 - 中文:17000 个样本
-
UCSC-VLAA/m23k - 分词:23487 个样本
-
来自已建立的医学数据集生成的样本:
-
MedMcQA(来自 openlifescienceai/medmcqa):183000 个样本
-
MedQA:10000 个样本
-
MedReason:32700 个样本
-
数据集构建流程如下:
-
收集所有公共 R1 跟踪记录,来源包括 PrimeIntellect/SYNTHETIC-1、GeneralReasoning/GeneralThought-430K、a-m-team/AM-DeepSeek-R1-Distilled-1.4M、open-thoughts/OpenThoughts2-1M、nvidia/Llama-Nemotron-Post-Training-Dataset(仅科学子集)以及其他资源。
-
对所有 R1 推理跟踪进行领域特定处理:
-
嵌入生成:使用 sentence-transformers/all - MiniLM-L6-v2 对提示进行嵌入。
-
聚类:执行 K 均值聚类,分为 50000 个聚类。
-
领域分类:对于每个聚类,选择距离聚类中心最近的 10 个提示。使用 Qwen2.5-32b-Instruct 对每个选定提示的领域进行分类,并根据分类提示的多数投票分配聚类的领域。
-
领域过滤:仅保留标记为医学或生物学的聚类,用于最终数据集。
-
-
添加来自 light-r1 的 15000 个推理跟踪样本,以增强模型的一般推理能力。
-
过滤以确保完整生成:仅保留生成输出完整的跟踪记录。
-
基于长度的过滤:最低阈值为保留提示超过 3 个单词的记录。
-
精选医学 R1 跟踪(338055 个样本)。
-
补充数学数据集:使用分词数据,并进行预处理,包括移除包含超过 47 次 “Wait” 出现的跟踪记录(97 百分位数阈值)。采用两步去污染方法:先按照 open-r1 项目使用 10 元组和评估数据集去污染,然后使用 s1k 方法的模糊去污染,阈值为 90%。
五、使用方法
II-Medical-8B 模型可以像 Qwen 或 Deepseek-R1 - Distill 模型一样使用。例如,可以使用 vLLM 或 SGLang 轻松启动服务。推荐的采样参数为温度 0.6,top_p 为 0.9。使用时,明确要求逐步推理,并将最终答案格式化在 \boxed{} 中(例如,“请逐步推理,并将你的最终答案放在 \boxed{} 中。”)
六、使用指南
此部分在原文中未详细展开,需根据实际使用情况和模型特点进行相应说明,如在何种环境下使用、如何调用接口、输入输出的格式要求等,以确保用户能够正确、有效地使用该模型。
七、局限性和考虑因素
数据集可能包含源材料的固有偏见,医学知识需要定期更新,并且需要注意该模型不适合用于医疗用途。

















 853
853

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









