







欢迎收藏Star我的Machine Learning Blog:https://github.com/purepisces/Wenqing-Machine_Learning_Blog。如果收藏star, 有问题可以随时与我交流, 谢谢大家!
广告点击预测
1. 问题描述
建立一个机器学习模型来预测广告是否会被点击。
为了简化,我们不会专注于广告技术中常用的级联分类器。
- 在继续之前,让我们了解一下广告投放的背景。广告请求会经过一个瀑布模型,在该模型中,出版商会尝试通过高 CPM(每千次展示成本)直接销售其库存。如果无法销售,出版商会将展示机会传递给其他网络,直到它被售出。
级联分类器涉及多个阶段,每个阶段都有自己的分类器,一个分类器的输出成为下一个分类器的输入。这可以帮助:
- 过滤:早期阶段过滤掉大多数负面案例(例如,不太可能被点击的情况),使后续阶段能够专注于更难分类的情况。
- 专业化:不同阶段可以专注于预测任务的不同方面,提高整体性能。
- 效率:通过逐步减少每个阶段需要考虑的案例数量,级联可以提高计算效率。
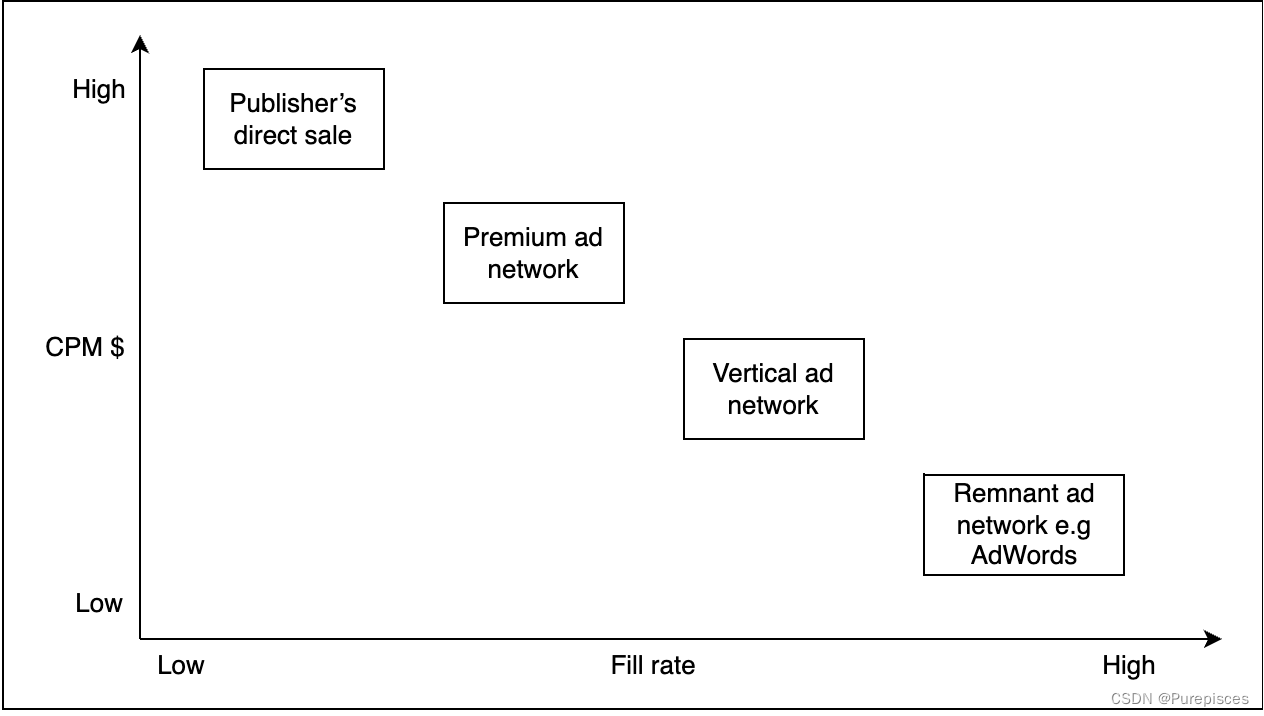
在瀑布模型中,出版商(例如《纽约时报》)首先会尝试直接将广告位卖给广告主,以获得高 CPM。如果失败,则会按顺序将机会传递给谷歌 AdSense、Facebook Audience Network 等广告网络,直到广告位被填满。
出版商直接销售:
场景:《纽约时报》直接与三星协商,在其主页上放置一个月的横幅广告,以获得高 CPM。高级广告网络:
场景:广告主使用谷歌营销平台在顶级网站(如 ESPN)上投放广告,确保其广告出现在信誉良好、流量高的网站上。垂直广告网络:
场景:旅行社使用旅行广告网络在与旅行相关的网站上投放广告,吸引对旅行感兴趣的受众。剩余广告网络:
场景:较小的广告主使用谷歌广告在谷歌网络中的剩余广告库存上竞价,使其广告以较低的成本出现在各种网站上。
出版商:出版商是创建和拥有可以展示广告的内容的实体(个人、组织或公司)。他们提供展示广告的平台。
广告网络:广告网络是一家将广告主与出版商连接起来的公司。它聚合多个出版商的广告库存并将其卖给广告主,促进广告的买卖。
展示:展示是广告在网页、应用程序或任何其他数字媒介上显示的一次实例。它是用来衡量广告被看到多少次的指标。
2. 指标设计和需求
指标
在训练阶段,我们可以专注于机器学习指标,而不是收入指标或点击率(CTR)指标。以下是两个指标:
离线指标
- 归一化交叉熵(NCE):NCE 是预测的对数损失除以背景 CTR 的交叉熵。这种方式使 NCE 对背景 CTR 不敏感。以下是 NCE 的公式:
N C E = − 1 N ∑ i = 1 n ( 1 + y i 2 log ( p i ) + 1 − y i 2 log ( 1 − p i ) ) − ( p log ( p ) + ( 1 − p ) log ( 1 − p ) ) NCE = \frac{-\frac{1}{N} \sum\limits_{i=1}^{n} \left( \frac{1 + y_i}{2} \log(p_i) + \frac{1 - y_i}{2} \log(1 - p_i) \right)}{- \left( p \log(p) + (1 - p) \log(1 - p) \right)} NCE=−(plog(p)+(1−p)log(1−p))−N1i=1∑n(21+yilog(pi)+21−yilog(1−p
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5475
5475

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









