






Swin Transformer v1模型具体实现:Swin Transformer模型具体代码实现-CSDN博客
一、分组卷积:
分组卷积是一种卷积操作的变体,它将输入通道分成多个组,然后在每个组内独立地进行卷积操作。如果将输入的数据分为head_num个组进行卷积,分组卷积可以在不同的组内学习到不同的特征,这与多头注意力机制在不同头中捕捉不同特征的能力有相似之处。那么在图像分类领域,可以使用MLP代替多头注意力机制,这样做的好处有:
- 减少参数和计算量:通过在每个组内进行卷积,分组卷积显著减少了模型的参数和计算量。
- 特征多样性:允许模型在不同的通道组中学习不同的特征,增加了模型的表达能力。
-
计算效率:分组卷积在计算上比多头注意力机制更高效,尤其是在处理高维特征时。多头注意力机制的计算复杂度通常是O(
)O(
-
简化模型结构:使用分组卷积可以简化模型结构,减少模型复杂度,同时保持或提高性能。这对于需要快速推理的应用场景(如实时处理)非常重要。
二、具体实现:
1、替换注意力模块完整代码:
class SwinMLPBlock(nn.Module):
def __init__(self,
dim,
input_resolution, #分辨率
num_heads,
window_size=7,
shift_size=0,
mlp_ratio=4.,
drop=0.,
drop_path=0.,
act_layer=nn.GELU,
norm_layer=nn.LayerNorm):
super().__init__()
self.dim = dim
self.input_resolution = input_resolution
self.num_heads = num_heads
self.window_size = window_size
self.shift_size = shift_size
self.mlp_ratio = mlp_ratio
if min(self.input_resolution) <= self.window_size:
# 当前分辨率比窗口小,不需要shift,同时窗口大小设置为最小分辨率
self.shift_size = 0
self.window_size = min(self.input_resolution)
assert 0 <= self.shift_size < self.window_size, "shift_size must in 0-window_size"
#进行移位操作需要的填充:左边填充,右边填充,上方填充,底部填充(因为移位操作是往右下方移动)
self.padding = [self.window_size - self.shift_size, self.shift_size,
self.window_size - self.shift_size, self.shift_size]
self.norm1 = norm_layer(dim)
# 分组卷积替代MSA:通道数为头数量*窗口大小,组数为头数量,这意味着每个头都有一个独立的卷积(类似多头注意力)
#在MSA中,数据数据形状为【B*num_windows,head,windows_size*windows_size,C//head】
self.spatial_mlp = nn.Conv1d(self.num_heads * self.window_size ** 2,
self.num_heads * self.window_size ** 2,
kernel_size=1,
groups=self.num_heads)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
def forward(self, x):
#H和W是输入特征的高和宽
H, W = self.input_resolution
# L是窗口数量=self.window_size ** 2
B, L, C = x.shape
assert L == H * W, "input feature has wrong size"
shortcut = x
x = self.norm1(x)
#x形状由【B, H*W, C】->【B, H, W, C】
x = x.view(B, H, W, C)
# 给四周填充0,为了进行移位操作
if self.shift_size > 0:
P_l, P_r, P_t, P_b = self.padding
shifted_x = F.pad(x, [0, 0, P_l, P_r, P_t, P_b], "constant", 0)
else:
shifted_x = x
#shifted_x形状由【B, H, W, C】->【B, H+window_size, W+window_size, C】
_, _H, _W, _ = shifted_x.shape
# 划分窗口
#x_windows形状由【B, H+window_size, W+window_size, C】->【nW*B, window_size, window_size, C】
#nW为窗口数量=(H+window_size)*(W+window_size)//window_size//window_size
x_windows = window_partition(shifted_x, self.window_size)
#形状变为【nW*B, window_size*window_size, C】
x_windows = x_windows.view(-1, self.window_size * self.window_size, C)
# 形状变为【nW*B, window_size*window_size, head, C//head】
x_windows_heads = x_windows.view(-1, self.window_size * self.window_size, self.num_heads, C // self.num_heads)
# 形状变为【nW*B, head, window_size*window_size, C//head】
x_windows_heads = x_windows_heads.transpose(1, 2)
# 形状变为【nW*B, head*window_size*window_size, C//head】
x_windows_heads = x_windows_heads.reshape(-1, self.num_heads * self.window_size * self.window_size,
C // self.num_heads)
# 进行分组卷积:每个头都有一个独立的卷积
spatial_mlp_windows = self.spatial_mlp(x_windows_heads)
# 形状变为【nW*B, window_size*window_size, head, C//head】
spatial_mlp_windows = spatial_mlp_windows.view(-1, self.num_heads, self.window_size * self.window_size,
C // self.num_heads).transpose(1, 2)
# 形状变为【nW*B, window_size*window_size, C】
spatial_mlp_windows = spatial_mlp_windows.reshape(-1, self.window_size * self.window_size, C)
# 合并窗口
#形状变为【nW*B, window_size, window_size, C】
spatial_mlp_windows = spatial_mlp_windows.reshape(-1, self.window_size, self.window_size, C)
#形状变为【B, H+window_size, W+window_size, C】
shifted_x = window_reverse(spatial_mlp_windows, self.window_size, _H, _W) # B H' W' C
# 恢复原始位置
if self.shift_size > 0:
P_l, P_r, P_t, P_b = self.padding
x = shifted_x[:, P_t:-P_b, P_l:-P_r, :].contiguous()
else:
x = shifted_x
x = x.view(B, H * W, C)
# 残差连接+前馈神经网络
x = shortcut + self.drop_path(x)
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
def extra_repr(self) -> str:
return f"dim={self.dim}, input_resolution={self.input_resolution}, num_heads={self.num_heads}, " \
f"window_size={self.window_size}, shift_size={self.shift_size}, mlp_ratio={self.mlp_ratio}"
def flops(self):
flops = 0
H, W = self.input_resolution
# norm1
flops += self.dim * H * W
# Window/Shifted-Window Spatial MLP
if self.shift_size > 0:
nW = (H / self.window_size + 1) * (W / self.window_size + 1)
else:
nW = H * W / self.window_size / self.window_size
flops += nW * self.dim * (self.window_size * self.window_size) * (self.window_size * self.window_size)
# mlp
flops += 2 * H * W * self.dim * self.dim * self.mlp_ratio
# norm2
flops += self.dim * H * W
return flops2、分组卷积具体实现:
第一节已经给出了block的完整的代码,这里来说明如何使用分组卷积代替多头注意力机制。
self.spatial_mlp = nn.Conv1d(self.num_heads * self.window_size ** 2,
self.num_heads * self.window_size ** 2,
kernel_size=1,
groups=self.num_heads)我们注意到,在v1模型中,输入注意力模块的数据形状为:【B*num_windows,head,windows_size*windows_size,C//head】,每个头负责处理windows_size*windows_size序列长度的C//head维向量,在mlp中,输入数据通道数为num_heads*windows_size*windows_size,分为num_heads组,那么每个组处理的通道数也为windows_size*windows_size,这就保证了二者在数据处理形状上的一致性,mlp模块的输出模块通道为num_heads*windows_size*windows_size,与输入数据的通道数一致,这一点也符合数据输入注意力模块输出形状不变的性质。
对于windows_size*windows_size序列长度的C//head维向量,mlp和注意力模块都可以学习特征,而且mlp效率更高。
3、窗口处理:
在v1模型中,我们在移动窗口之后会产生小窗口不便于进行注意力计算,这时候有两种方案,第一种是进行填充、第二种是保持原有形状不变加入掩码机制。在MLP版本中,我们使用第一种方案进行填充,之后学习特征。
self.padding = [self.window_size - self.shift_size, self.shift_size,
self.window_size - self.shift_size, self.shift_size] 填充的维度如上面的代码所示,分别为:左边填充、右边填充、上方填充、底部填充。我们知道,在窗口移动时,会向右下方移动shift_size个单位(向右、向下),所以我们对于左边界填充window_size-shift_size,这样填充位置和移动到该位置的原本右侧的数值就重新组成了一个完整的窗口,其他方向也是同理。
移动窗口:
if self.shift_size > 0:
P_l, P_r, P_t, P_b = self.padding
shifted_x = F.pad(x, [0, 0, P_l, P_r, P_t, P_b], "constant", 0)反向恢复窗口:
if self.shift_size > 0:
P_l, P_r, P_t, P_b = self.padding
x = shifted_x[:, P_t:-P_b, P_l:-P_r, :].contiguous()其他流程和v1版本一致,没有变化。
4、位置编码:
在v1版本中,使用了相对位置偏置,在这里,由于使用分组卷积,因此不需要进行位置编码,所欲删去位置编码即可。使用SwinMLPBlock替换掉v1版本中的SwinTransformerBlock,更改BasicLayer类中的调用模块就是MLP版本的Swin Transformer。
三、实现效果:
实验条件与参数设置均与v1版本一致,使用两个GPU,训练80轮,得到结果:
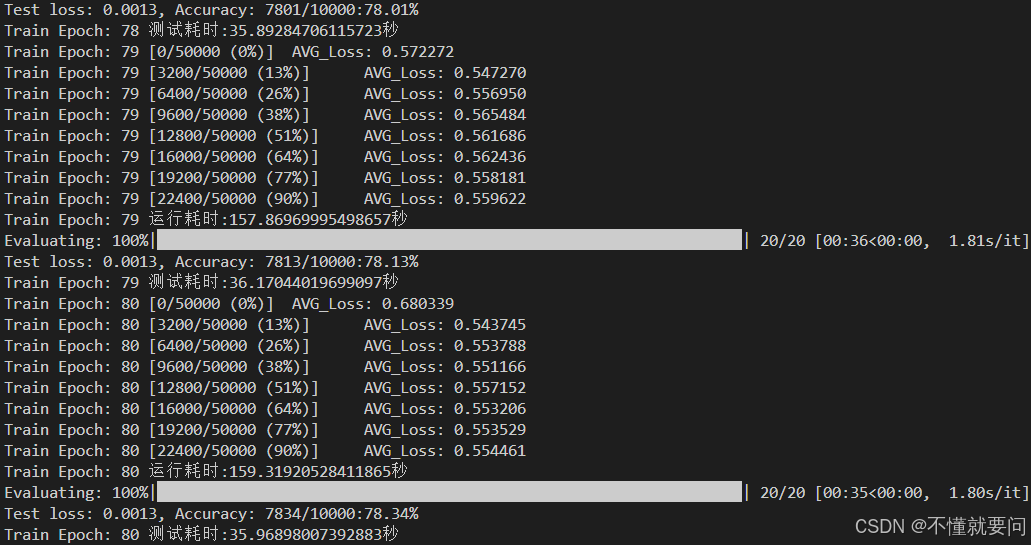
得到的最佳结果是准确率为78.34%,相较于v1版本的 78.01%还是有所进步的。

















 1196
1196

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









