






 本文介绍了SharedMLP的概念,它是传统MLP在点云网络中的变体,通过共享卷积参数减少参数量,适用于处理无序输入。对比了传统MLP中每个样本独立的参数与SharedMLP的参数共享机制,展示了CNN参数共享对点云处理的优势。
本文介绍了SharedMLP的概念,它是传统MLP在点云网络中的变体,通过共享卷积参数减少参数量,适用于处理无序输入。对比了传统MLP中每个样本独立的参数与SharedMLP的参数共享机制,展示了CNN参数共享对点云处理的优势。
一、引言
在很多 point-based 的模型论文中,都出现了 Shared MLP 字眼。起初我也觉得很疑惑,为什么要加shared字眼,和MLP有什么区别?
要理清这个概念,就先需要复习一下传统MLP的概念。
二、传统MLP(多层感知机,全连接层)
以经典图像识别为例
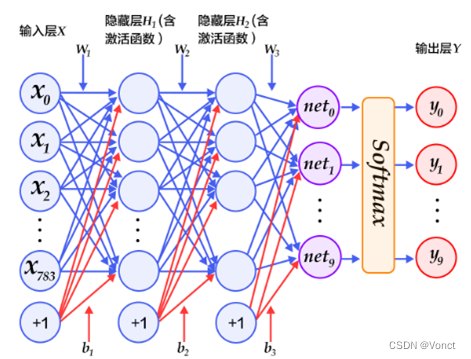
网络的输入(x0, x1, x2, …)是由2D图像展成(flatten)的一维向量,而每一个箭头都是一组参数(权重w&偏置b)。
对于每一个样本(每一个x)其矩阵地表示如下图:
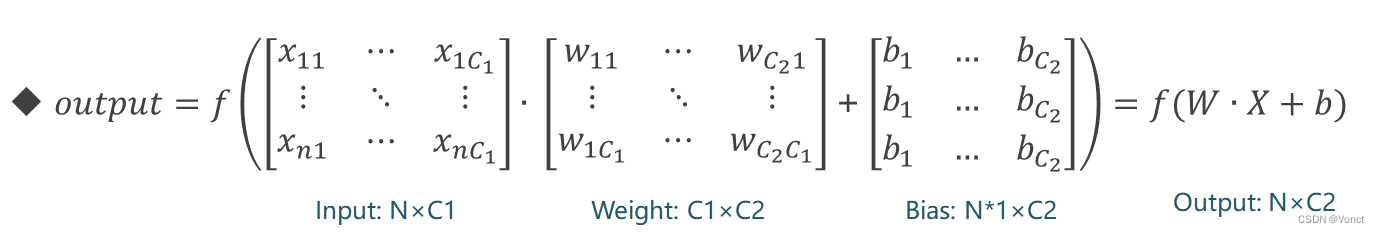
(图源:https://cloud.tencent.com/developer/article/2030055)
模型的输入输出为:
Input_size: (N, C1)
Output_size: (N, C2)
总参数量: N * C1 * N* C2
在传统的MLP中,每个样本都有自己的独立的MLP网络,这意味着每个样本都有自己的权重和偏置。
但其实现在的MLP一般也指的是样本之间共用一组线性层参数了。
三、Shared MLP
以经典的PointNet为例

Shared MLP往往是通过conv1d或conv2d(取决于输入维度,或希望的点云特征融合区域,比如PointNet++中就是conv2d)来实现的。
在PointNet的源码中,我们可以发现这一步的对应的代码为
#point_cloud.size = (B, C = 3, N)
self.conv1 = torch.nn.Conv1d(channel, 64, 1)
out1 = F.relu(self.bn1(self.conv1(point_cloud))) #3 -> 64 (B, 64, N)
对应的卷积示意图为
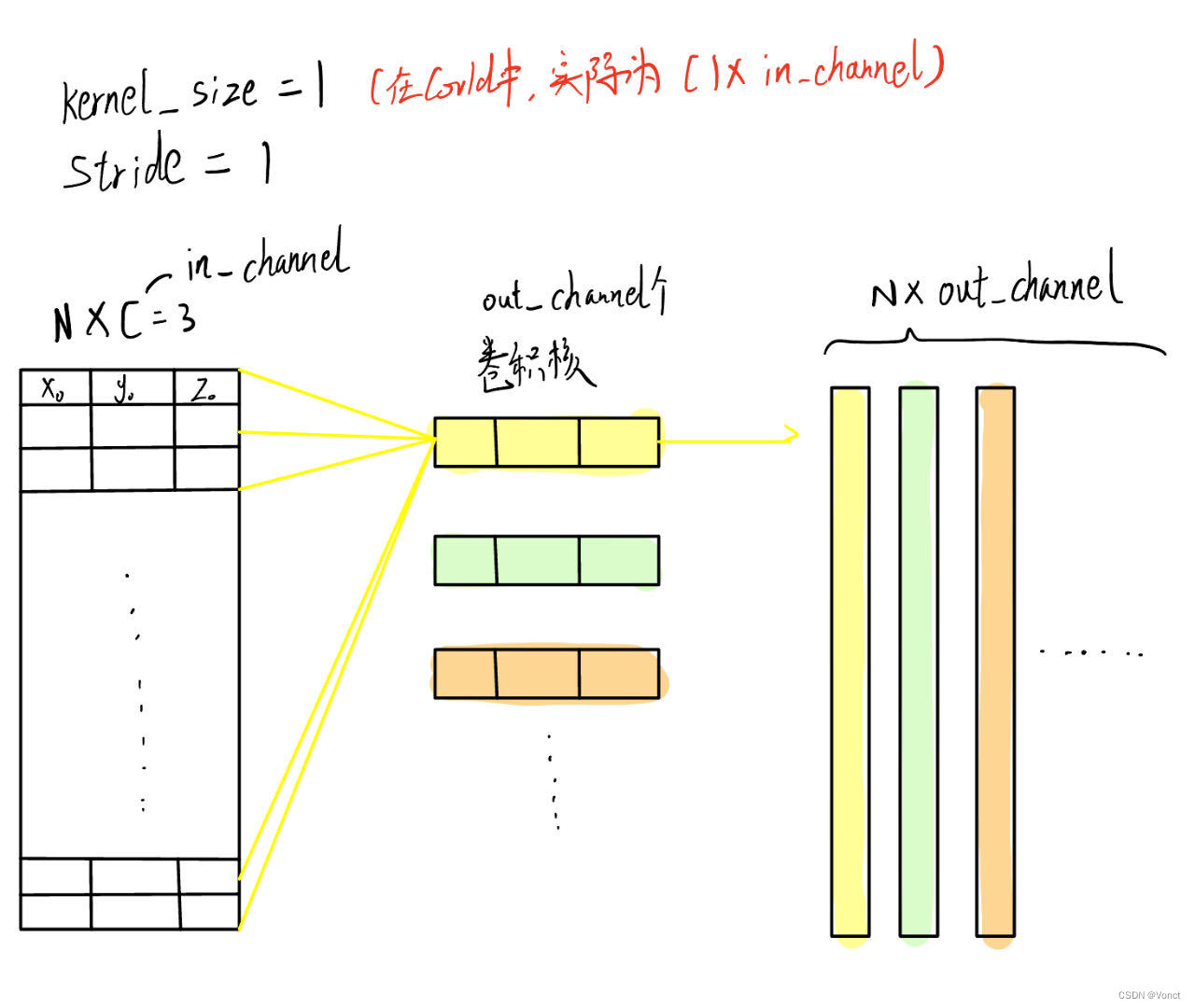
可以看到,每个样本(点云)在计算得出每一维特征(右边的每一条列向量)时,都是与同一个卷积核进行了对应点乘。这就是共享参数的体现了。
此时MLP的输入输出为:
Input_size: (B, N, C1)
Output_size: (B, N,C2)
模型参数量:B * C1 * C2
这里的B,也就是样本数,相当于上面的N
四、总结
通过两者对比,就能比较容易理解Shared MLP中shared的意思了。即在点云网络中,强调每个点云都共享同一组参数。
这也是为什么要用卷积来进行MLP实现的原因,因为CNN很大的一个特点是
在CNN中,卷积层的滤波器参数是共享的,即它们在整个输入上使用相同的权重和偏置。这种参数共享的机制大大减少了模型的参数量,使得CNN具有更好的泛化能力,并能够有效地处理大规模数据
这样的特性使得模型能能适应点云的 unorder input 特性。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









