 DBSCAN聚类实战
DBSCAN聚类实战





DBSCAN全称为“Density-Based Spatial Clustering of Applications with Noise”。我们可以利用sklearn在python中实现DBSCAN。
首先,import相关的Library。
import numpy as np
import pandas as pd
import math
import matplotlib.pyplot as plt
import matplotlib
from sklearn.cluster import DBSCAN
from sklearn.neighbors import NearestNeighbors
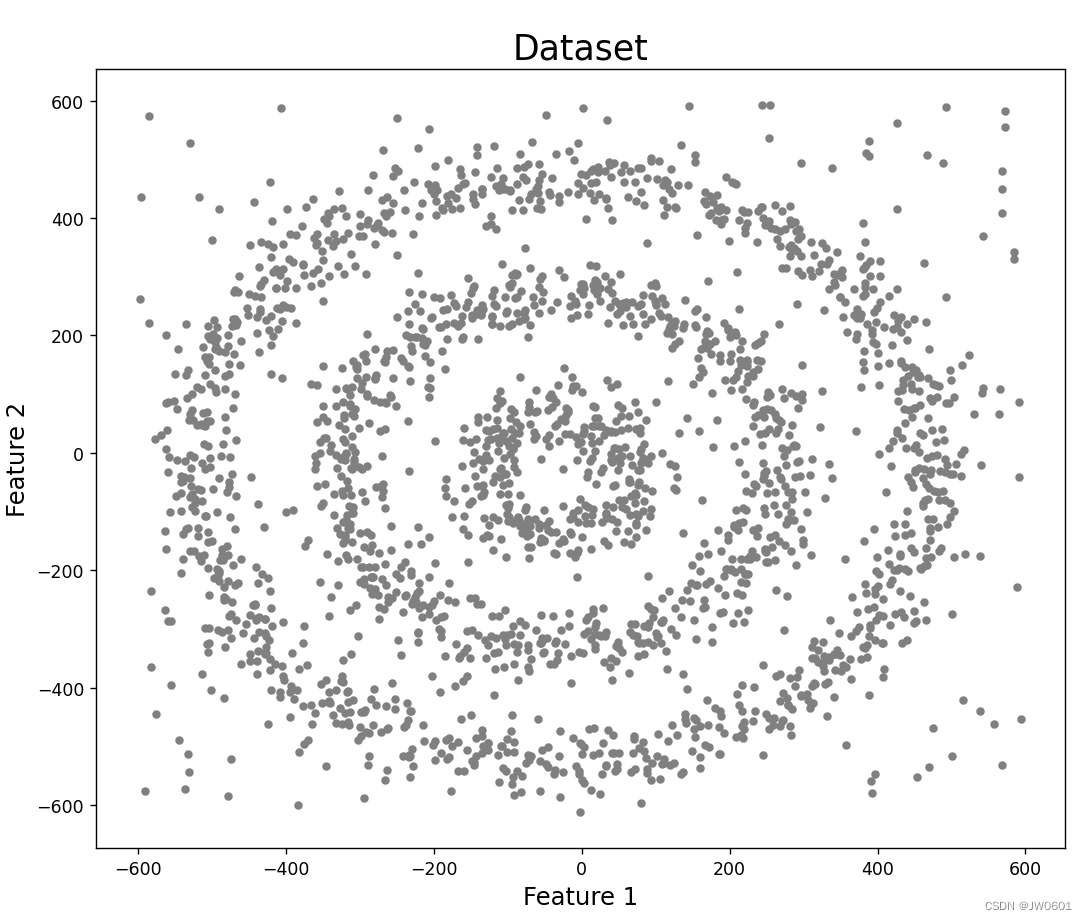
我们首先定义一个function来创建我们需要的数据集,数据集的dimension为2。下图为我们将要创建的数据集的可视化。这个数据集由三个圆圈组成。在我们定义的function中,r代表半径,n代表点的数量。
np.random.seed(42)
def PointsInCircum(r,n=100):
return [(math.cos(2*math.pi/n*x)*r+np.random.normal(-30,30),math.sin(2*math.pi/n*x)*r+np.random.normal(-30,30)) for x in range(1,n+1)]
我们把创建的三个圆圈数据放在各自的dataframe里面,再制造一个noise数据集用来测试DBSCAN。
df1=pd.DataFrame(PointsInCircum(500 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1227
1227

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









