






本文全部内容来自对2020.6发布在计算机集成制造系统的移动边缘计算中基于能耗优化的深度神经网络计算任务卸载策略的总结。
文章目录
文章传达的核心思想:
深度神经网络的数据分析功能十分强大,因此常常应用于移动智能应用之中。而考虑到计算任务的复杂性,如果将深度神经网络中的计算任务完全卸载到云端,则会产生较高的数据传输时延。移动边缘计算的提出能够很大程度上解决深度神经网络的时延和能耗问题。在保证用户时间约束的同时,充分优化终端设备能耗,建立移动边缘计算环境中深度神经网络计算任务卸载策略。
该策略主要以神经网络层为单位,将深度神经网络中的计算任务进行拆分,在卸载时,对移动边缘计算环境中的多重计算资源进行综合考虑,提出粒子群调度算法(MRPSO)优化下的DNNs,在满足时延约束下,使得设备的能耗降到最低。
· 应用到DNNs的原因:
1、DNNs往往具有多层结构(多个隐藏层),因此能够以神经网络为单位对DNNs的计算任务进行拆分。
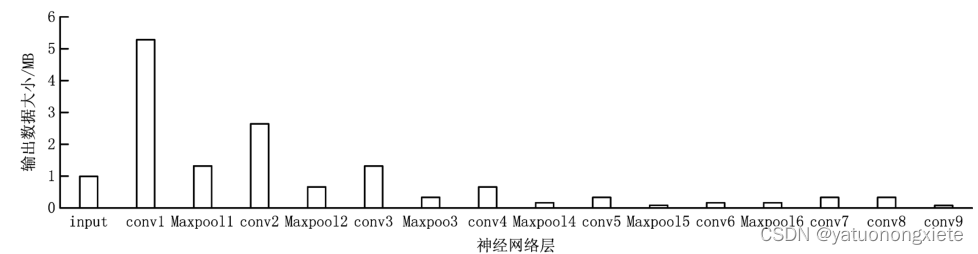
2、快速卸载数据的思想:DNNs的执行过程实际是信息提取的过程,在提取到足够的信息之前,每个神经网络可以快速缩小数据大小。如下图所示例如在Tiny YOLOv2的输入数据大小为0.99MB,而在中间层Maxpool5的输出大小为0.08MB,减少了约91%。快速卸载能够减少终端设备的能耗和传输时间。
具体过程:部署DNNs模型到移动边缘计算环境中的各种计算资源后,只在终端设备或边缘服务器上执行部分DNNs计算任务后,将提取特征后减少的中间值传输到云上,而云得到的中间值可以从任何断点恢复计算,并执行余下的计算任务。在数据安全方面,通过边缘服务器的预处理,能够避免将原始用户的数据直接发送给远程服务提供商,从而保证数据的安全性。
模型的建立
· 基于DNNs结构的计算任务模型(对计算任务之间的依赖关系进行描述)
将任务之间的依赖关系(任务的先后顺序,需要根据依赖关系的顺序进行调度和执行)用一个有向无环图(DAG)来进行表示,那么不同的顶点表示不同神经网络层的计算任务,要注意的是各神经网络层的计算任务是不可分割的,只能在同一个计算资源上处理。该无向图可以表示为 G = ( V ∪ { v e n t r y , v e x i t } , E ) G=(V\cup\{v_{entry},v_{exit}\},E) G=(V∪{ventry,vexit},E) 其中 V = ( v 1 , v 2 , . . . , v N t ) V=(v_1,v_2,...,v_{N_t}) V=(v1,v2,...,vNt)代表顶点集合, N t N_t Nt代表DNNs层的总数。 E E E代表有向边的集合,每条边 e i j = ( v i , v j ) ∈ E ( i , j = 1 , 2 , 3 , . . . , N t ; i ≠ j ) e_{ij}=(v_i,v_j)\in E(i,j=1,2,3,...,N_t;i\not=j) eij=(vi,vj)∈E(i,j=1,2,3,...,Nt;i=j)代表各DNNs层计算任务的依赖关系。 v i v_i vi必须在 v j v_j vj之前执行, v i v_i vi的输出作为 v j v_j vj的输入。
以下为四种常用的DNNs的DAG实例:(注意图中模型需要重新绘制)
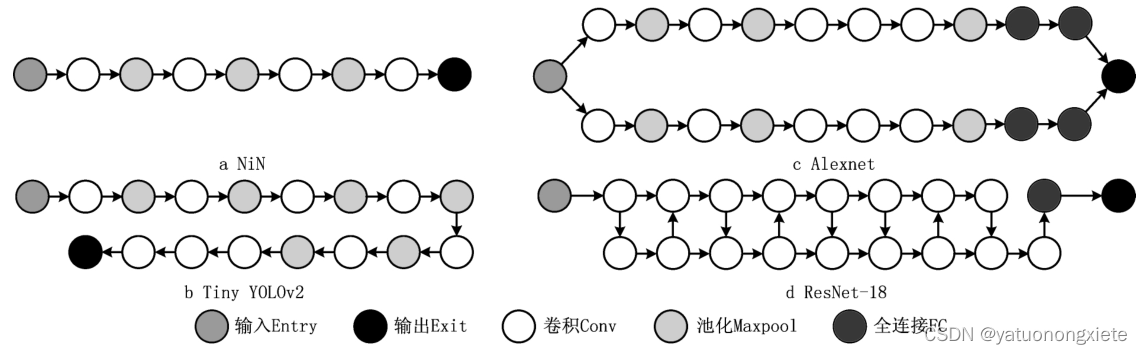
· NiN(Network in Network使用DAG表示法来构建网络。采用两个 3 ∗ 3 3*3 3∗3卷积操作响应地代替一个 5 ∗ 5 5*5 5∗5卷积,来增加网络的非线性表示能力。使用1*1卷积层来实现全连接层的效果。因此NiN常具有更小的计算负载和更少的参数,能够提高深度网络的训练和推理效率。
· Tiny YOLOv2多用来在嵌入式和移动设备上实现实时的目标检测。网络结构包含多个卷积层、池化层、全连接层以及锚框和网格单元等其他技术,主要通过这些技术来减少参数数量和计算负载,来提高效率,例如使用1x1卷积层和批次标准化技术来减少卷积层的计算负载。
· Alexnet由5个卷积层,三个池化层以及两个全连接层构成,使用卷积层、ReLU激活函数以及池化层来处理输入的图像,然后通过全连接层将输入传递到softmax分类器中。整个网络采用Dropout技术来避免过拟合的现象。
· ResNet-18是一种深度残差神经网络,包含18层网络,其中包括16个卷积层和两个全连接层(一个由平均池化层连接而成)。主要利用残差块(Residual Block)来训练深层网络,通过将每个残差块的输入和输出相加,并通过增加网络深度和使用残差块连接,来解决深层网络训练中出现的梯度消失问题。
· 负载模型
对于一个确定的神经网络结构,我们能够估计出其执行时间在不实际执行神经网络的前提下。使用浮点运算次数(FLOPs)来表示 v i v_i vi虽然会忽略其他操作的运算花费时间,但其能够作为执行时间计算的主要指标。在神经网络中最常用且计算密集的两种深度网络层是卷积和全连接层,其负载的计算公式如下:
卷积层的负载计算如下所示:
W
i
=
(
2
∗
C
i
n
∗
K
2
[
−
1
]
)
∗
H
o
u
t
∗
W
o
u
t
∗
C
o
u
t
W_i=(2*Cin*K^2[-1])*Hout*Wout*Cout
Wi=(2∗Cin∗K2[−1])∗Hout∗Wout∗Cout
对于式1,
H
o
u
t
、
W
o
u
t
、
C
o
u
t
Hout、Wout、Cout
Hout、Wout、Cout分别表示输出特征图的高、宽和通道数量;
K
K
K是卷积核的宽,
C
i
n
Cin
Cin是输入特征图通道数量;
全连接层的负载计算如下所示:
W
i
=
(
2
∗
I
[
−
1
]
)
∗
O
W_i=(2*I[-1])*O
Wi=(2∗I[−1])∗O
对于式2,
I
,
O
I,O
I,O分别是输入神经元的数目和输出神经元的数目;括号内的-1是需要考虑偏置时候需要添加的。
任务负载时间与能耗模型
评价基于多重资源任务卸载的粒子群调度算法主要从DNNs执行的总时间以及终端设备的总能耗两个评价指标进行评价,需要建立相应的卸载时间和能耗评价模型。
任务卸载时间模型:
主要由两个部分构成:计算任务 v i v_i vi的计算时间和边缘计算环境中**各层资源间的数据传输时间(通信时间)**两个部分。用 R R R来表示计算资源集合,我们根据移动边缘计算环境中不同的任务卸载策略可将计算资源分为:终端设备 R e n d R_{end} Rend、边缘服务器 R e d g e R_{edge} Redge和云服务器 R c l o u d R_{cloud} Rcloud。其中 r e n d 、 r i e d g e 和 r i c l o u d r^{end}、r_i^{edge}和\ r_i^{cloud} rend、riedge和 ricloud分别表示终端设备、边缘服务器和云服务器对应的计算任务处理速度。
· 计算时间
负载/处理速度,计算负载除以任务的处理速度得到的是平均响应时间或平均处理延迟也就是计算时间。那么当任务
v
i
v_i
vi分配给资源
R
i
R_i
Ri时,
v
i
v_i
vi的计算时间
T
i
c
o
m
p
(
R
i
)
T^{comp}_i(R_i)
Ticomp(Ri)如下所示:
T
i
c
o
m
p
(
R
i
)
=
{
W
i
/
r
i
e
d
g
e
R
i
∈
R
e
d
g
e
W
i
/
r
i
c
l
o
u
d
R
i
∈
R
c
l
o
u
d
W
i
/
r
e
n
d
R
i
∈
R
e
n
d
T_i^{comp}(R_i)=\left\{\begin{matrix}W_i/r_i^{edge}\ R_i\in R_{edge}\\W_i/r_i^{cloud}\ R_i\in R_{cloud}\\W_i/r^{end} R_i\in R_{end}\end{matrix}\right.
Ticomp(Ri)=⎩
⎨
⎧Wi/riedge Ri∈RedgeWi/ricloud Ri∈RcloudWi/rendRi∈Rend
任务
v
i
v_i
vi的负载
W
i
W_i
Wi和处理速度
r
i
r_i
ri有关,因此需要根据
v
i
v_i
vi来判断其任务卸载策略所分配的计算资源类型,从而得出任务计算时间。
· 通信时间
任务
v
i
v_i
vi作为
v
j
v_j
vj前置DNNs层的计算任务。当任务卸载到边缘服务器,终端和云服务器的时候,因为其各自的通信带宽不同(边缘服务器之间使用速度较快的LAN进行通信,云服务器之间使用速度较慢的WAN进行通信)因此任务
v
i
v_i
vi和
v
j
v_j
vj间的通信时间会根据前置任务卸载到不同的计算资源而不同。
T
i
j
o
m
m
(
R
i
,
R
j
)
=
{
0
R
i
,
R
j
∈
R
end
Out
i
/
B
L
R
i
∈
R
end
,
R
j
∈
R
elge
Out
i
/
B
W
R
i
∈
R
end
,
R
j
∈
R
doud
,
T
i
j
o
m
m
(
R
i
,
R
j
)
=
{
Out
i
/
B
L
R
i
∈
R
edge
,
R
j
∈
R
end
Out
i
/
B
L
R
i
,
R
j
∈
R
edge
,
R
i
≠
R
j
0
R
i
,
R
j
∈
R
edge
,
R
i
=
R
j
Out
i
/
B
W
R
i
∈
R
edge
,
R
j
∈
R
doud
,
T
i
j
o
m
m
(
R
i
,
R
j
)
=
{
Out
i
/
B
W
R
i
∈
R
doud
,
R
j
∈
R
end
Out
i
/
B
W
R
i
∈
R
doud
,
R
j
∈
R
edge
Out
i
/
B
W
R
i
,
R
j
∈
R
doud
,
R
i
≠
R
j
0
R
i
,
R
j
∈
R
doud
,
R
i
=
R
j
\begin{array}{l} T_{i j}^{o m m}\left(R_{i}, R_{j}\right)= \\ \left\{\begin{array}{ll} 0 & R_{i}, R_{j} \in R_{\text {end }} \\ \text { Out }_{i} / B_{L} & R_{i} \in R_{\text {end }}, R_{j} \in R_{\text {elge }} \\ \text { Out }_{i} / B_{W} & R_{i} \in R_{\text {end }}, R_{j} \in R_{\text {doud }} \end{array},\right. \\ T_{i j}^{o m m}\left(R_{i}, R_{j}\right)= \\ \left\{\begin{array}{ll} \text { Out }_{i} / B_{L} & R_{i} \in R_{\text {edge }}, R_{j} \in R_{\text {end }} \\ \text { Out }_{i} / B_{L} & R_{i}, R_{j} \in R_{\text {edge }}, R_{i} \neq R_{j} \\ 0 & R_{i}, R_{j} \in R_{\text {edge }}, R_{i}=R_{j} \\ \text { Out }_{i} / B_{W} & R_{i} \in R_{\text {edge }}, R_{j} \in R_{\text {doud }} \end{array},\right. \\ T_{i j}^{o m m}\left(R_{i}, R_{j}\right)= \\ \left\{\begin{array}{ll} \text { Out }_{i} / B_{W} & R_{i} \in R_{\text {doud }}, R_{j} \in R_{\text {end }} \\ \text { Out }_{i} / B_{W} & R_{i} \in R_{\text {doud }}, R_{j} \in R_{\text {edge }} \\ \text { Out }_{i} / B_{W} & R_{i}, R_{j} \in R_{\text {doud }}, R_{i} \neq R_{j} \\ 0 & R_{i}, R_{j} \in R_{\text {doud }}, R_{i}=R_{j} \end{array}\right. \\ \end{array}
Tijomm(Ri,Rj)=⎩
⎨
⎧0 Out i/BL Out i/BWRi,Rj∈Rend Ri∈Rend ,Rj∈Relge Ri∈Rend ,Rj∈Rdoud ,Tijomm(Ri,Rj)=⎩
⎨
⎧ Out i/BL Out i/BL0 Out i/BWRi∈Redge ,Rj∈Rend Ri,Rj∈Redge ,Ri=RjRi,Rj∈Redge ,Ri=RjRi∈Redge ,Rj∈Rdoud ,Tijomm(Ri,Rj)=⎩
⎨
⎧ Out i/BW Out i/BW Out i/BW0Ri∈Rdoud ,Rj∈Rend Ri∈Rdoud ,Rj∈Redge Ri,Rj∈Rdoud ,Ri=RjRi,Rj∈Rdoud ,Ri=Rj
B
L
B_L
BL和
B
w
B_w
Bw分别代表LAN和WAN的带宽,
O
u
t
i
Out_i
Outi为前置DNNs层计算任务
v
i
v_i
vi的输出数据,同样也是任务
v
j
v_j
vj的输入数据,当
v
i
v_i
vi和
v
j
v_j
vj分配到相同的计算资源时,任务之间的传输时间为0。这里终端设备设置的数量为1,因此当相邻的DNNs层计算任务的写在决策均为终端设备时,任务的传输时间为0
· DNN运行总时间
DNNs中存在并行结构,因此可能一个任务有多个前驱任务
v
p
v_p
vp,需要等到所有的所有的
v
p
v_p
vp执行完毕之后
v
i
v_i
vi才开始执行,因此执行完成时刻需要取最大值。
这里当任务
v
i
v_i
vi的完成时刻
F
T
(
v
i
)
FT(v_i)
FT(vi)是
v
i
v_i
vi的开始时刻和计算时间之和,而当任务
v
i
v_i
vi的前驱任务为
v
e
n
t
r
y
v_{entry}
ventry时,则
F
T
(
v
e
n
t
r
y
)
=
0
FT(v_{entry})=0
FT(ventry)=0。任务
v
i
v_i
vi的后继任务是输出任务
v
e
x
i
t
v_{exit}
vexit时,其累计时间定义为DNNs运行时间总时间T(W)。
任务卸载能耗模型
能耗部分的计算主要包括任务在终端设备的执行能耗、任务数据发送到云服务器或边缘服务器的数据发送能耗以及任务执行完成后结果数据回传终端设备的数据接受能耗三个部分组成。具体计算方式如下:
E
e
n
d
=
P
e
n
d
∗
T
e
n
d
+
P
u
p
∗
T
u
p
+
P
d
o
w
n
∗
T
d
o
w
n
E_{end}=P_{end}*T_{end}+P_{up}*T_{up}+P_{down}*T_{down}
Eend=Pend∗Tend+Pup∗Tup+Pdown∗Tdown
其中
P
e
n
d
、
P
u
p
、
P
d
o
w
n
P_{end}、P_{up}、P_{down}
Pend、Pup、Pdown分别表示终端执行的功率、终端的上传功率、终端接收功率;
T
e
n
d
、
T
u
p
、
T
d
o
w
n
T_{end}、T_{up}、T_{down}
Tend、Tup、Tdown分别表示终端执行时间、终端上传时间、终端接收时间。
需要注意的是:当任务不卸载时其能耗就为任务在终端上的执行能耗,不用考虑上传于云所带来的数据的发送能耗与接受能耗。
基于多重资源任务卸载的粒子群调度算法 MRPSO
设计出了满足时间约束下的评价终端设备能耗的适应度计算函数,然后提出了移动边缘计算环境中基于多重资源任务卸载的粒子群调度算法。将DNNs层上的计算任务分配给合适的计算资源,从而得到合适的调度方案,来解决在时间约束下的终端设备能耗优化问题。
· 适应度函数
适应度函数常用来评估粒子群算法中粒子所对应调度方案的优劣。
我们用 E e n d E_{end} Eend来表示终端设备的总能耗,用 T ( W ) T(W) T(W)来表示移动边缘计算环境DNNs运行的总时间, T d e a d l i n e T_{deadline} Tdeadline来表示DNNs执行的时间约束。
适应度函数主要由两个部分组成:
1、DNNs运行的总时间小于时间约束时(
f
1
=
1
,
f
2
=
0
f_1=1,f_2=0
f1=1,f2=0),适应度值为调度方案终端设备能耗。
2、DNNs运行总时间大于时间约束之时(
f
1
=
0
,
f
2
=
1
f_1=0,f_2=1
f1=0,f2=1),适应度值为能耗和超过时间约束比之积。
具体如下:
f
i
t
n
e
s
s
=
(
f
1
∗
E
e
n
d
)
+
(
f
2
∗
10
∗
E
e
n
d
∗
T
(
W
)
T
d
e
a
d
l
i
n
e
)
fitness=(f_1*E_{end})+(f_2*10*E_{end}*\frac{T(W)}{T_{deadline}})
fitness=(f1∗Eend)+(f2∗10∗Eend∗TdeadlineT(W))
可以看到适应度值函数是用能耗来进行表达,因此最终适应度值越低,表明对应的终端设备的能耗越低;反之,适应度值越高,则表明所需终端设备能耗越高。
· 算法描述
(粒子群优化算法中根据搜索速度由粒子群位置更新是指:在算法中,每个粒子都存储了一组解,其位置表示解的位置,速度表示更新解时的搜索方向和强度。在粒子群优化算法中,每个粒子在当前的位置上评估适应度函数值。在每次更新之后,粒子会检查其适应度函数值是否有所改善,并记录下当前的最优解,再根据每个离子和当前最优解的距离,来更新每个粒子的速度和位置。)
input:
算法迭代的次数
I
t
e
r
a
t
i
o
n
Iteration
Iteration,云服务器
C
l
o
u
d
s
Clouds
Clouds,边缘服务器
E
d
g
e
s
Edges
Edges,边缘设备
E
n
d
End
End,粒子的个数
p
N
u
m
pNum
pNum,响应的时间
T
d
e
a
d
l
i
n
e
T_{deadline}
Tdeadline,和深度神经网络
G
G
G;
output:能耗优化和任务卸载决策 D e n e r g y − b e s t D_{energy-best} Denergy−best与调度方案 S e n e r g y − b e s t S_{energy-best} Senergy−best。
for j=1 to pNum do
随机初始化调度方案S_j,搜索速度v_j及其卸载决策d_j;
计算此粒子对应的卸载决策d_j与调度方案S_j的总时间
计算此粒子对应的卸载决策d_j与调度方案S_j的总能耗
计算此粒子对应的卸载决策d_j与调度方案S_j的适应度
end for
for k=1 to Iteration do
根据搜索速度更新所有粒子对应卸载决策d_j与调度方案S_j;
for j=1 to pNum do
计算此粒子对应的卸载决策d_j与调度方案S_j的总时间
计算此粒子对应的卸载决策d_j与调度方案S_j的总能耗
计算此粒子对应的卸载决策d_j与调度方案S_j的适应度(重复上述过程)
if计算所得到的适应度要比之前计算所得到的适应度值小then
更新该粒子当前最优的适应度值、总时间以及总能耗
end if
end for
找出适应度最小的那个粒子,即此迭代全局最优任务卸载决策D_global-best与调度方案S_global-best
更新每个粒子对应任务卸载决策d_j与调度方案S_j的搜索速度
end for
return最终得到的最优任务卸载决策与调度方案D_energy-best与S_energy-best。
简单概括就是:
1、初始化调度方案、粒子搜索速度以及任务卸载决策,计算每个粒子对应的初始调度方案的总时间、总能耗和适应度值。
2、在进入算法迭代后,首先根据搜索速度由粒子群位置更新公式,更新所有粒子对应任务卸载决策与调度方案。
3、对于其中的每一个卸载决策与调度方案,计算任务执行的总时间、总能耗以及适应度值,后判断适应度值是否比原来的要小,若是则更新此例子当前最优的适应度值、总时间以及总能耗,从粒子群中找到适应度值最小的粒子所对应的任务卸载决策与调度方案,来作为本次迭代的全局最优任务卸载策略与调度方案。
实验结果与分析:
实验的数据来源:根据Tiny YOLOv2结构生成DAG图,并随机生成不同的输入数据的大小。
本节从适应度值、终端设备能耗和DNN任务完成时间3个方面来对基于4种任务卸载策略的粒子群调度算法进行对比。这里的4种任务卸载策略为:基于终端设备的不卸载(LOPSO)、基于云服务器的完全卸载(FOCPSO)、基于端云的部分卸载(POPSO)以及本文提出的基于端-边-云的多重资源卸载(MRPSO)。
适应度值:
卸载到单一设备的两种资源卸载策略LOPSO和FOCPSO算法,MRPSO的平均适应度值要低70%80%,而对于基于端云的部分卸载,MRPSO算法平均适应度值要低40%50%。

能耗与时间方面:


如图所示,FOCPSO对应的是右侧的坐标轴,因此其对应的能耗最小,是因为DNNs层的所有计算任务全都卸载到了云端,终端设备不再存在执行的能耗,只有很少的发送能耗。 从下图中可以进一步看出,由于FOCPSO的传输时间过多,其平均完成时间是MRPSO的2倍左右,因此无法满足时间约束,从而导致适应度要低于MRPSO,而在完成时间上LOPSO对应的平均完成时间要最小(在终端设备上完成任务仅耗费计算时间,不存在传输时间),但相应地,其能耗会最大。
综上所述,与基于现有的3种任务卸载策略所对应地粒子群调度算法相比,MRPSO在权衡时间与能耗后所表现出的性能是最优的,对于DNNs结构下的任务处理效率要优于其他几种算法,且充分地降低了终端设备的能耗。
总结:
在边缘计算环境中,基于DNNs结构特征建立了计算任务卸载时间和能耗的评价模型,后在该模型的基础上提出了移动边缘环境中基于能耗优化的DNNs计算任务的卸载策略。并设计出满足用户时间约束下优化终端设备能耗的适应度函数。并提出了移动边缘计算环境中基于多重任务资源任务卸载的粒子群调度算法来对DNNS结构的计算任务进行合理分配执行。
通过与三种任务卸载策略所对应的调度算法相比,MRPSO的算法适应度最优,能够在时间约束下满足能耗要求,并获得最佳性能。
展望
在实际中计算速度和网络带宽都会有一定的波动,DNNs的执行时间也会受到多种因素的影响,看是否能将其放入真实的智能应用场景之中,并对其性能进行考量。
参考文献
- [1]高寒,李学俊,周博文,刘晓,徐佳.移动边缘计算环境中基于能耗优化的深度神经网络计算任务卸载策略[J].计算机集成制造系统,2020,26(06):1607-1615.DOI:10.13196/j.cims.2020.06.017.
- [2]Mao Y, You C, Zhang J, et al. A survey on mobile edge computing: The communication perspective[J]. IEEE communications surveys & tutorials, 2017, 19(4): 2322-2358.
- [3]Redmon J, Farhadi A. YOLO9000: better, faster, stronger[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 7263-7271.
- [4]Koulinas G, Kotsikas L, Anagnostopoulos K. A particle swarm optimization based hyper-heuristic algorithm for the classic resource constrained project scheduling problem[J]. Information Sciences, 2014, 277: 680-693.

















 2311
2311

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









