







Ollama 是一个开源的大型语言模型(LLM)平台,旨在让用户能够轻松地在本地运行、管理和与大型语言模型进行交互。
这个是之前发过的博文,ollama的基础使用
本地部署deepseek (ollama简单使用方法,含网盘下载链接)-CSDN博客
ollama下载网盘链接(访问密码:7360)
https://url57.ctfile.com/f/45223957-1454403034-07c955?p=7360
deepseek现在是非常火爆,相信大家应该也都尝试本地部署了。部署完之后,想要开源模型有更高的定制化,该怎么办呢?这下可以用到ollmam终端modelfile。
操作方法:
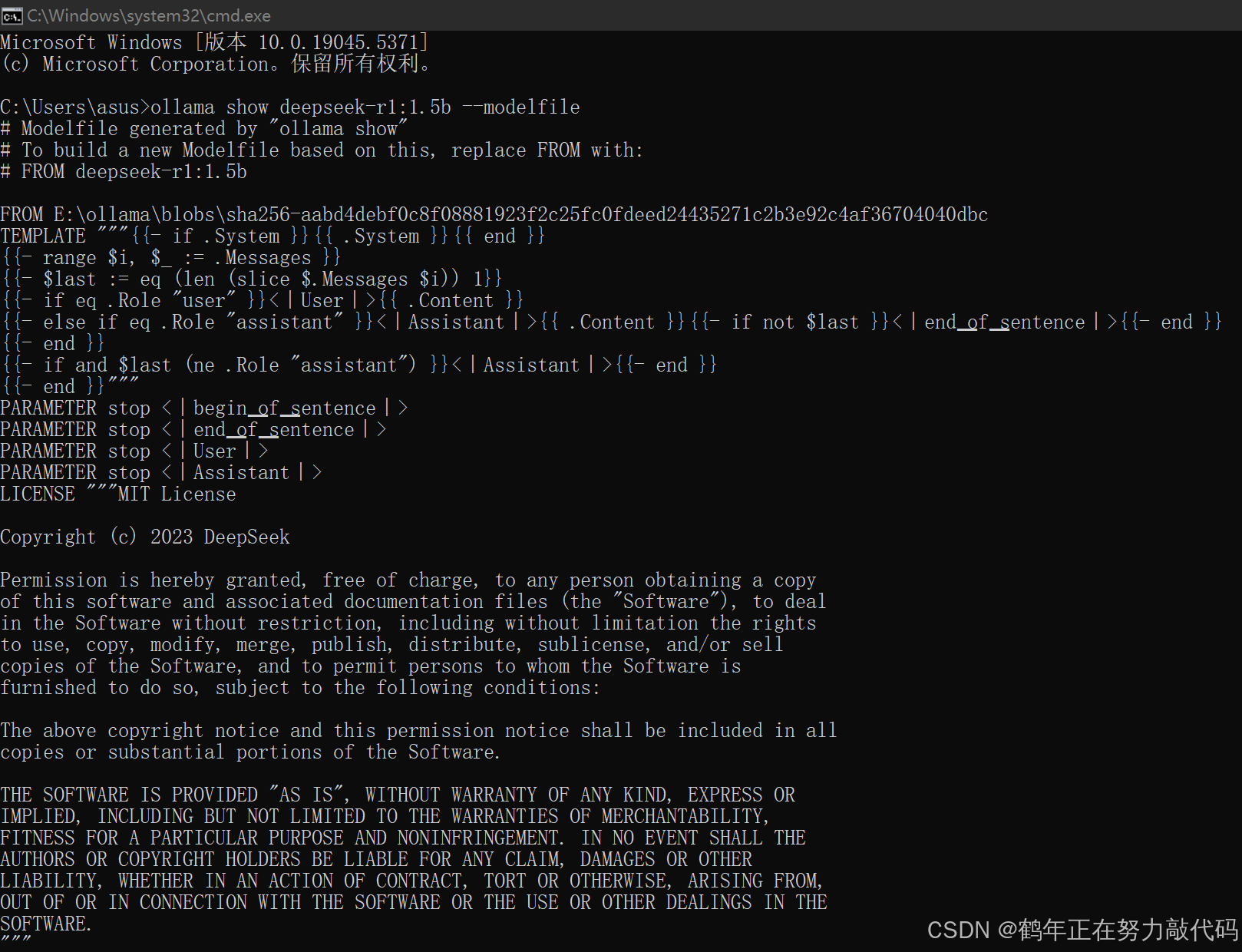
首先可以先执行指令查看模型的modelfile的信息(以deepseek-r1:1.5为例)
ollama show deepseek-r1:1.5b --modelfile如图,图片上半部分上面给出了modelfile的模板,下半部分LICENSE是许可证信息。
我们在D盘根目录下下创建名为Modelfile的空白文件
接下来就是在空白文件内写配置信息 (用记事本就可以)
下面这个是我写的一个示例模板
FROM deepseek-r1:1.5b
TEMPLATE """[INST] <>{
{ .System }}<>
{
{ .Prompt }} [/INST]
"""
PARAMETER temperature 0.7
PARAMETER top_k 60
PARAMETER top_p 0.5
PARAMETER stop "[INST]"
PARAMETER stop "[/INST]"
PARAMETER stop "<>"
PARAMETER stop "<>"
SYSTEM """
你的名字叫鹤年同学,专精编程领域解决问题。
"""-
FROM:指定使用 DeepSeek-
r1:1.5b版本。 -
TEMPLAT:定义了生成文本的模板格式。(便于下面定义SYSTEM)
-
[INST] <>{ { .System }}<>:这部分表示在生成的文本开头插入一个[INST]标记,然后插入系统指令(.System),最后插入一个<>分隔符。 -
{ { .Prompt }} [/INST]:这部分表示插入用户提供的提示(.Prompt),并在结尾插入一个[/INST]标记。 -
temperature: 含义:控制生成文本的随机性。 值:0.7,表示生成的文本有一定的随机性,但不会过于离谱。
-
top_k: 含义:在生成文本时,只从概率最高的 k 个词中选择下一个词。 值:60,表示从概率最高的 60 个词中选择下一个词。
-
top_p: 含义:在生成文本时,只从累积概率达到 p 的词中选择下一个词。 值:0.5,表示从累积概率达到 50% 的词中选择下一个词。
-
PARAMETER stop :定义了生成文本时的停止标记。
-
[INST]和[/INST]:这两个标记用于指示指令的开始和结束。 -
<>:这个标记可能用于分隔不同的部分或表示结束。 -
SYSTEM:定义了系统指令,用于设置模型的初始行为和角色.
写完之后,打开cmd 进入D盘生成我们的模型。(demo换为你要起的名字)
输入下面指令:
D:
ollama create demo -f Modelfile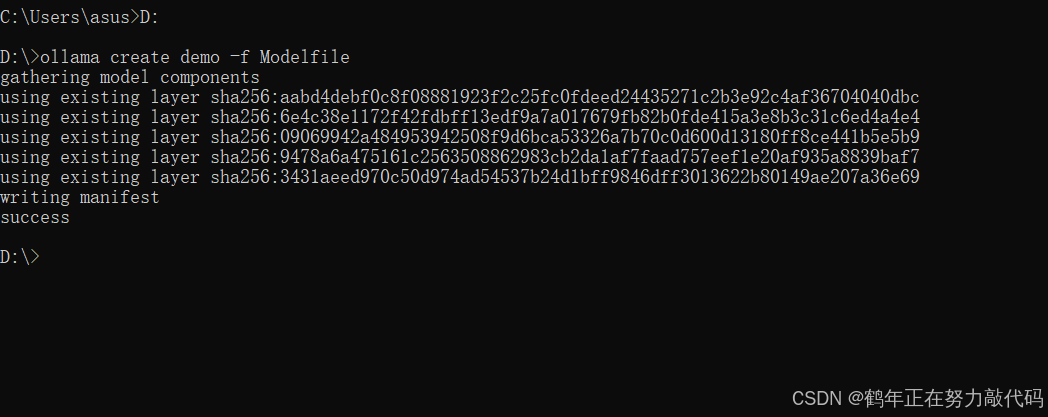
创建完成之后我们查询一下模型列表验证一下
ollama list有我们创建的模型就是成功了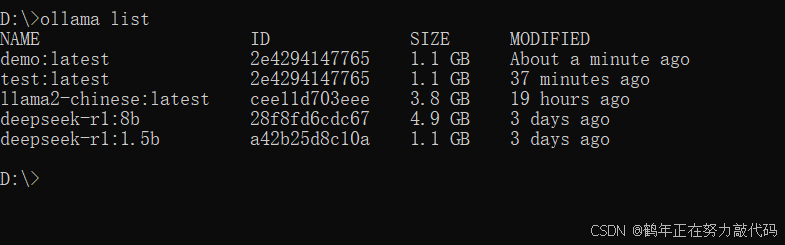
运行模型 ollama run demo 进行模型测试,可以看到我们定义初始行为和角色的效果达到了。
接下来就可以进行愉快的对话了!!!

最后如果需要删除模型可以运行rm指令(demo替换为要删除的模型)
ollama rm demo
















 6111
6111

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









